键值对Map-05

1.LinkedHashMap 简介
LinkedHashMap 是 HashMap 的一个子类。它继承了 HashMap 的所有特性,同时还具有一些额外的功能,位于 java.util 包下。
与 HashMap 不同的是,LinkedHashMap 会保持元素插入的顺序,因此它是有序的。具体来说,LinkedHashMap 使用一个双向链表来维护插入顺序,而 HashMap 则不保证元素的遍历顺序。这使得 LinkedHashMap 可以按照元素插入的顺序进行迭代,并且这个迭代顺序不会随着时间的推移而改变。
2.LinkedHashMap 特点
LinkedHashMap的主要特性包括:
- 有序性:维护元素插入的顺序,可以按照插入顺序进行迭代。
- 基于 HashMap 实现:LinkedHashMap 底层使用 HashMap 来存储键值对,因此具有 HashMap 的高效查找和插入操作。
- 可以选择按插入顺序或访问顺序排序:在构造 LinkedHashMap 对象时,可以选择按照插入顺序或者访问顺序(最近访问的元素放在最后)来排序。
- 线程不安全:和 HashMap 一样,LinkedHashMap 也不是线程安全的。如果在多线程环境中使用,需要考虑同步措施。
默认情况下,LinkedHashMap 按照插入顺序进行排序。如果希望按照访问顺序进行排序,可以使用带有 accessOrder 参数的构造方法:
LinkedHashMap<K, V> linkedHashMap = new LinkedHashMap<>(initialCapacity, loadFactor, true);
在此构造方法中,accessOrder 为 true 表示按访问顺序排序,为 false 表示按插入顺序排序。
3.LinkedHashMap 双向链表?
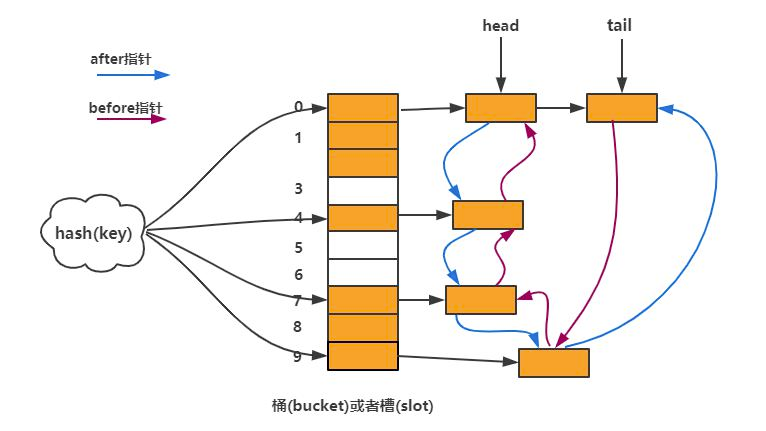
数据结构:数组+单向链表+双向链表
每一个节点都是双向链表的节点,维持插入顺序。head 指向第一个插入的节点,tail 指向最后一个节点。
数组+单向链表是 HashMap 的结构,用于记录数据。
双向链表保存的是插入顺序,顺序访问。
next 是用于维护数据位置的,before 和 after 是用于维护插入顺序的。
// Entry继承HashMap的Node
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
/**
* The head (eldest) of the doubly linked list.
*/
// 旧数据放在head节点
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
// 新数据放在tail节点
transient LinkedHashMap.Entry<K,V> tail;
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
// false-按插入顺序存储数据 true-按访问顺序存储数据
final boolean accessOrder;
4.按 put 的顺序进行遍历?
可以使用 LinkedHashMap,有 2 种功能,一个是插入顺序,一个是访问顺序
初始化时可以指定。相对于访问顺序,插入顺序使用的场景更多一些,所以默认是插入顺序进行编排。
5.LinkedHashMap2 种遍历顺序?
LinkedHashMap 有两种遍历顺序,插入顺序和访问顺序
插入方式:遍历时和插入时位置固定
访问方式:put 和 get 方法都会将当前元素移到双向链表的最后
是否使用访问顺序遍历,是通过**LinkedHashMap 的 accessOrder 参数控制的,true 为访问顺序遍历,false 为插入顺序遍历。**默认是 false,插入方式遍历。如果是 true,注意并发修改异常。因为 get 方法会修改 LinkedHashMap 的结构。
-
LinkedHashMap 的底层数据结构继承至 HashMap 的 Node,并且其内部存储了前驱和后继节点。
-
LinkedHashMap 通过 accessOrder 来控制元素的相关顺序,false-按插入顺序存储数据,true-按访问顺序存储数据,默认为 false。
//默认插入顺序
public class Data_01_LinkedHashMapTest_02 {
public static void main(String[] args) {
LinkedHashMap<String, Integer> map = new LinkedHashMap<>(2, 0.75f, false);
map.put("1", 1);
map.put("5", 5);
map.put("6", 6);
map.put("2", 2);
map.put("3", 3);
map.get("5");
map.get("6");
for (Integer s : map.values()) {
System.out.println(s);
}
}
}
//输出结果
1
5
6
2
3
//访问顺序
public class Data_01_LinkedHashMapTest_01 {
public static void main(String[] args) {
LinkedHashMap<String, Integer> map = new LinkedHashMap<>(2, 0.75f, true);
map.put("1", 1);
map.put("5", 5);
map.put("6", 6);
map.put("2", 2);
map.put("3", 3);
map.get("5");
map.get("6");
for (Integer s : map.values()) {
System.out.println(s);
}
}
}
//输出结果,会把put和get操作的元素放在最后
1
2
3
5
6
6.LinkedHashMap 访问顺序的原理?
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
关键点是 accessOrder 参数,默认为 false,插入方式,true 为访问方式。
当调用 get 方法时,会判断 accessOrder 的值,如果为 true,会执行 afterNodeAccess 方法,就是放到 node 的后面。
public V get(Object key) {
Node<K,V> e;
// 通过getNode方法取出节点,如果为null则直接返回null
if ((e = getNode(hash(key), key)) == null)
return null;
// 如果accessOrder为true,则需要把节点移动到链表末尾
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
7.LinkedHashMap 的 put 方法的原理?
LinkedHashMap 没有 put 方法,使用的是 HashMap 的 put 方法,并且复写了 newNode 方法和 afterNodeAccess 方法。
新增的节点放到双向链表末尾
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
将新增的节点添加至链表尾部
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
8.LinkedHashMap 的 get 方法原理?
会判断是否是访问顺序,如果是,放到双向链表末尾。
JDK1.8 的 HashMap 的 get 方法
- 计算数据在桶中的位置 (tab.length- 1) & hash(key)
- 通过 hash 值和 key 值判断待查找的数据是否在对应桶的首节点, 如果在,则返回对应节点 据;否则判断桶首节点的类型。如果节点 为红黑树,从红黑树中获取对应数据;如果节点为链表节点,则遍历 链表,从中获取对应数据
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
9.用 LinkedHashMap 实现 LRU 算法?
主要考察 2 个点
- accessOrder 实现 lru 的逻辑
- removeEldestEntry 的复写
在插入之后,会调用 LinkedHashMap 的 afterNodeInsertion 方法,需要重写 removeEldestEntry 方法
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
class Scratch<K, V> extends LinkedHashMap<K, V> {
private int capacity;
public Scratch(int capacity) {
super(16, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > capacity;
}
}
10.LinkedHashMap 和 HashMap 区别?
- LinkedHashMap 继承自 HashMap,是基于 HashMap 和双向链表实现的。并实现了 HashMap 中预留的钩子函数,因此不必重写 HashMap 的很多方法,设计非常巧妙。
- HashMap 是无序的,LinkedHashMap 是有序的,分为插入顺序和访问顺序。如果是访问顺序,使用 put 和 get 时,都会把 entry 移动到双向链表的表尾。
- LinkedHashMap 存取数据还是和 HashMap 一样,使用 entry[]数组的形式,双向链表只是为了保证顺序。
- LinkedHashMap 也是线程不安全的。
- LinkedHashMap 默认容量为 16,扩容因子默认为 0.75,非同步,允许[key,value]为 null。LinkedHashMap 底层数据结构为双向链表,可以看成是 LinkedList+HashMap。如果 accessOrder 为 false,则可以按插入元素的顺序遍历元素,如果 accessOrder 为 true,则可以按访问顺序遍历元素。

- 点赞
- 收藏
- 关注作者
评论(0)