键值对Map-03

1.Hashtable 定义
Hashtable 是 Java 中的一个散列表实现,继承自 Dictionary 类,实现了 Map 接口。Hashtable 使用键值对的方式来存储数据,其中每个键对应唯一的值,即 key-value 对。
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable {
.........
}
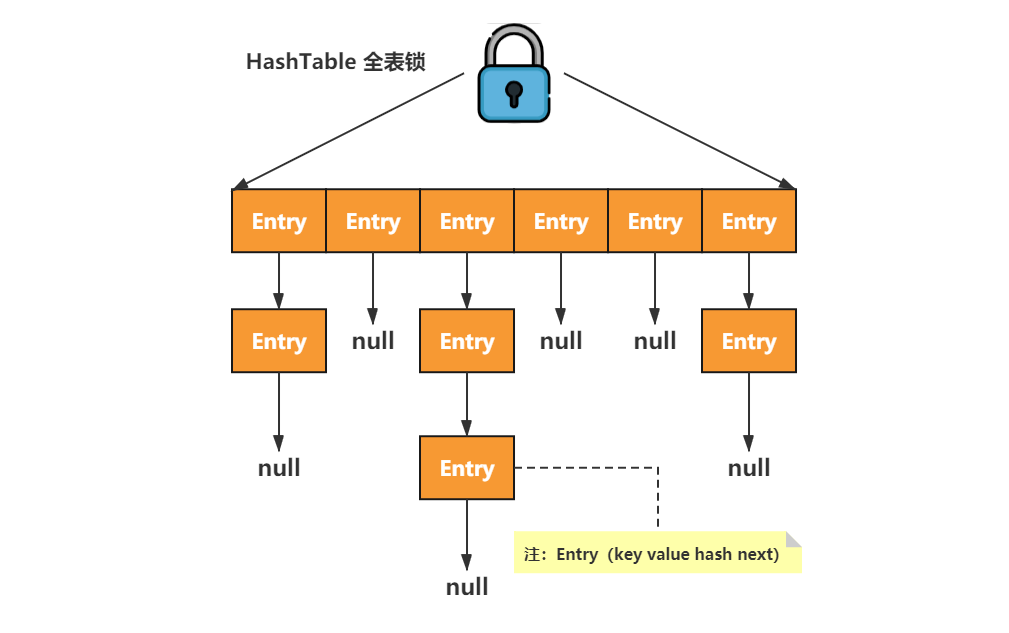
2.为啥 key 和 value 都不能为 null
Hashtable 中的 key 和 value 都不能为 null,这是因为 Hashtable 内部使用了哈希算法来计算 key 的散列值,然后将 key-value 对存储在散列表中。如果 key 为 null,那么在计算散列值时就会抛出 NullPointerException 异常;
如果value为null,那么存储value时就无法区分一个null值是表示这个key不存在还是表示这个key对应的值为null
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
}
为了解决这个问题,Java 中提供了 HashMap 类,它和 Hashtable 类类似,也是一个散列表实现,但是 HashMap 允许 key 和 value 都为 null,而且 HashMap 的性能也比 Hashtable 更好。
因此,在开发中如果不需要考虑线程安全问题,建议使用 HashMap 来代替 Hashtable。如果需要线程安全,也可以使用 Java 中提供的 ConcurrentHashMap 类来实现线程安全的散列表。
3.HashTable 是有序的吗?
HashTable 是无序的,生成的 hashcode 不一样,找到的 index 不一样,Hashtable 与 HashMap 一样,都是以键值对的形式存储数据。但是 Hashtable 的键值不能为 null,而 HashMap 的键值是可以为 null 的。Hashtable 是线程安全,因为它的元素操作方法上都加了 synchronized 关键字,这就导致锁的粒度太大,因此日常开发中一般建议使用 ConcurrentHashMap。
4.Hashtable 确定 index 位置?
int index = (hash & 0x7FFFFFFF) % tab.length;
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
5.构造函数
从默认构造函数可知:Hashtable 的默认容量为 11,扩容因子为 0.75f。
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
6.Hashtable 扩容?
在 put 函数中涉及扩容,但是由于 put 操作为线程安全,所以扩容时也是线程安全的。扩容要求:当前元素个数大于等于容量与扩容因子的乘积。还有一点需注意插入的新节点总是在头部。
整个扩容过程比较简单,注意新的数组大小是原来的 2 倍加 1,还有一点比较重要扩容时插入新元素采用的是头插法,元素会进行倒序。
protected void rehash() {
// 旧的容量大小
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
// 扩容后新的容量等于原来容量的2倍+1
int newCapacity = (oldCapacity << 1) + 1;
// 容量大小控制,不要超过最大值
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
// 创建新的数组
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
// 更新扩容因子
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
// 数组转移 这里是从数组尾往前搬移
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
// 计算元素在新数组中的位置
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
// 进行元素插入,注意这里是头插法,元素会倒序
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
7.HashTable 扩容方式为 2n+1?
为了均匀分布,降低冲突率
首先,Hashtable 的初始容量为 11。扩容方式为
int newCapacity = (oldCapacity << 1) + 1;
Index 的计算方式为:
int index = (hash & 0x7FFFFFFF) % tab.tength;
常用的 hash 函数是选一个数 m 取模(余数),推荐 m 是素数,但是经常见到选择 m=2^n^,因为对 2^n^求余数更快,并认为在 key 分布均匀的情况下,key%m 也是在[0,m-1]区间均匀分布的。
但实际上,key%m 的分布同 m 是有关的。
证明如下:key%m = key - xm,即 key 减掉 m 的某个倍数 x,剩下比 m 小的部分就是 key 除以 m 的余数。 显然,x 等于 key/m 的整数部分,以 floor(key/m)表示。假设 key 和 m 有公约数 g,即 key=ag, m=bg, 则 key - xm = key - floor(key/m)*m = key - floor(a/b)*m。由于 0 <= a/b <= a,所以 floor(a/b)只有 a+1 种取值可能,从而推导出 key%m 也只有 a+1 种取值可能。a+1 个球放在 m 个盒子里面,显然不可能做到均匀。
由此可知,一组均匀分布的 key,其中同 m 公约数为 1 的那部分,余数后在[0,m-1]上还是均匀分布的, 但同 m 公约数不为 1 的那部分,余数在[0, m-1]上就不是均匀分布的了。把 m 选为素数,正是为了让所有 key 同 m 的公约数都为 1,从而保证余数的均匀分布,降低冲突率。 鉴于此,在 HashTable 中,初始化容量是 11,是个素数,后面扩容时也是按照 2N+1 的方式进行扩容, 确保扩容之后仍尽量是素数。
8.HashMap 和 Hashtable 的区别?
-
继承的父类不同
- Hashtable 继承自 Diconary 类,HashMap 继承自 AbtractMap 类
- 两者都实现了 map 接口
-
线程安全不同
-
HashMap 的实现不是同步的,如果多线程同时访问同一 hash 映射,至少有一个线程从结构上修改了该映射,则应该实现外部同步。结构上的修改是指添加或删除一个或多个映射关系的任
何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。
-
Hashtable 的方法是 synchronize 修饰的。在多线程环境下可以直接使用 Hashtable,不需要额外增加同步,使用 HashMap 需要额外处理同步问题。一般使用封装好的工具类。或则加上 synchronize 修饰。
-
-
是否提供 contains 方法
- HashMap 去掉了 contains 方法,保留了 containValue 和 containsKey 方法。因为 contains 方法容易让人产生误解。
- Hashtable 保留了 contains 方法,contains 方法和 containsValue 方法功能相同。
-
key 和 value 是否允许为 null
- Hashtable 中,key 和 value 都不能为 null。put(null,null)编译可以通过,因为 key 和 value 都是 object 类型,但是执行会报错。会报空指针异常。
- 在 HashMap 中 key 可以为 null,并且只能有一个 null 键。值可以有多个 null 值。当 get 方法获取到的值为 null 时,可能是 HashMap 中不存在该 key,也可能是 key 对应的值为 null,所以不能通过 get 方法判断 key 是否存在,应该用 containsKey 方法。
-
迭代方式不同
- 两者都使用了 terator 迭代器。
- 由于历史原因,Hashtable 还使用了 enumeration 的方式。
-
hash 值不同
- Hashtable 直接使用了 hashCode 与 Integer 的最大值进行与操作,再和数组长度取余;
- HashMap 还进行了扰动函数的计算和与函数运算;
-
内部实现(初始化+扩容)
- Hashtable 默认不指定长度为 11,HashMap 默认为 16。Hashtable 不要求数组的容量为 2 的幂次方,HashMap 要求数组的容量为 2 的幂次方。
- Hashtable 扩容时为 2n+1,HashMap 为 2n。
9.Hashtable 总结?
- Hashtable 线程安全、元素无序(因为以 hashCode 为基准进行散列存储),不允许[key,value]为 null。
- Hashtable 默认容量为 11,与 HashMap 不同(默认容量 16),扩容时容量增长为 2n+1(HashMap 直接增长为 2 倍)。
- 扩容转移元素时采用的是头插法

- 点赞
- 收藏
- 关注作者
评论(0)