集合-05

五.常见 Set 集合
1.说说 HashSet 的特点?
- 不能保证元素的排列顺序,顺序可能发生变化。
- 集合元素可以是 null,但只能有一个。
当向 HashSet 存入一个值时,需要计算 key 的 hashCode,并通过 hashCode 得到的结果再进行(length-1)&hash 得到 index 的位置,判断是否重复是通过 hashCode 和 equals 方法。存入数据是通过 key-value 方式,value 是初始化好的 new object。
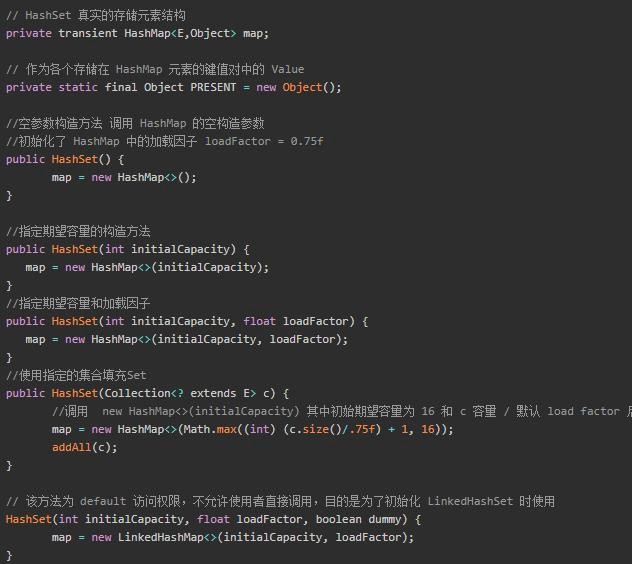
2.HashSet 的底层原理?
底层是依赖 HashMap 实现的,通过 HashSet 的构造参数可以知道,用 HashMap 来初始化成员变量。所以 HashSet 的初始容量也是 1<<4 即 16,加载因子为 0.75f。
//构造函数
public HashSet() {
map = new HashMap<>();
}
3.如何判断元素重复的?
HashSet 通过元素的 hashCode 和 equals 方法判断元素重复。
HashSet 的 add 方法,其实是 HashMap 的 put 方法,第一个参数 e 代表了存入的元素,第二个参数 present 代表初始化好的 new object 对象,这样 HashSet 在存入一个值的时候就可以很好的利用 HashMap 的 put 方法 key-value 结构。
// 初始化好的对象
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
4.contains()时间复杂度?
HashSet 和 ArrayList 的查找方法 contains()时间复杂度分析
ArrayList 本质就是通过数组实现的,查找一个元素是否包含要用到遍历,时间复杂度是 O(N)
HashSet 的查找是通过 HashMap 的 containsKey 来实现的,判断是否包含某个元素的实现,时间复杂度是 O(1)
//ArrayList判断是否包含某个元素的源码实现:
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++) //从头遍历
if (o.equals(elementData[i]))
return i;
}
return -1;
}
//HashSet判断是否包含某个元素的源码实现:
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { //直接通过hash确定元素位置,不用从头遍历
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))//部分情况下可能会继续遍历链表定位
return e;
} while ((e = e.next) != null);
}
}
return null;
}
5.LinkedHashSet 特点?
//定义
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
}
LinkedHashSet 是 Java 中的一个集合类,它是 HashSet 的一个子类,具有 HashSet 的所有特性,同时还保证了元素的顺序。
LinkedHashSet 使用哈希表来存储元素,与 HashSet 类似,它也是基于散列值来快速查找元素。但是,与 HashSet 不同的是,LinkedHashSet 还使用了一个双向链表来维护元素的插入顺序,从而保证了元素的顺序。因此,LinkedHashSet 中的元素是按照插入顺序进行排序的。
LinkedHashSet的主要特点如下:
- 元素唯一:LinkedHashSet 中的元素是唯一的,每个元素只会出现一次。
- 有序性:LinkedHashSet 中的元素是有序的,按照插入顺序进行排序。
- 性能:LinkedHashSet 的性能与 HashSet 类似,具有快速的查找和插入性能。
使用 LinkedHashSet 可以方便地维护元素的顺序,同时又具有 HashSet 的高效性能,因此在需要维护元素顺序的场景中,可以使用 LinkedHashSet 来代替 HashSet。
6.LinkedHashSet 源码?
HashSet 是依赖 HashMap,但是不是继承关系,是构造器时 new 的 HashMap。
//LinkedHashSet继承了HashSet
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
}
//HashSet其中一个构造器
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
分析 HashSet 的构造函数可以知道 只有一个 default 修饰的走了 LinkedHashMap,也就是专门为 LinkedHashSet 准备的。default 修饰的同包才能访问。其他的构造函数都是 new 的 HashMap 的构造函数。
7.说说 TreeSet?
TreeSet 是 Java 中的一个集合类,它实现了 Set 接口,可以存储一组唯一的元素,并且按照升序或自定义排序顺序来进行排序。它是基于红黑树(Red-Black Tree)数据结构来实现的,因此可以在 O(log n)的时间复杂度内完成插入、删除和查找等操作。
8.TreeSet 特点?
TreeSet的特点包括:
- 无重复元素:TreeSet 中不允许重复的元素,即集合中的元素是唯一的。
- 自动排序:TreeSet 会根据元素的自然顺序(如果元素实现了 Comparable 接口)或者自定义的比较器(通过构造函数指定)来对元素进行排序。在默认情况下,元素必须实现 Comparable 接口,否则在添加元素时可能会抛出 ClassCastException。
- 高效的查找:由于 TreeSet 使用红黑树作为底层数据结构,它能够在 O(log n)的时间复杂度内进行插入、删除和查找操作,使得它在处理大量数据时具有良好的性能。
需要注意的是,由于 TreeSet 是有序集合,因此它不适合用于需要保持元素插入顺序的场景。如果您需要保留插入顺序,请考虑使用 LinkedHashSet。
9.TreeSet 和 TreeMap?
与 HashSet 和 LinkedHashSet 一个套路,TreeSet 其实是使用了 TreeMap 的结构
TreeMap 也是 key-value 的结构,TreeSet 和 TreeMap 并没有继承关系,只是构造的时候使用了 TreeMap 构造函数。
//定义
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
............
}
// TreeSet的构造器
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}

- 点赞
- 收藏
- 关注作者
评论(0)