【愚公系列】2024年03月 《网络安全应急管理与技术实践》 016-网络安全应急技术与实践(Web层-应急响应技术总结)

🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2022年度博客之星TOP2,2023年度博客之星TOP2,2022年华为云十佳博主,2023年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
Web安全事件应急响应技术是指针对Web应用程序遭受风险和安全漏洞的事件,如网络攻击、数据泄露、恶意软件等,迅速采取措施进行监测、分析和应对的技术手段。
以下是一些常见的Web安全事件应急响应技术:
| 应急响应技术 | 描述 |
|---|---|
| 1. 监测和日志分析 | 通过实时监测和分析Web应用程序的日志,以便发现异常活动和潜在的安全威胁。 |
| 2. 威胁情报收集与分析 | 收集和分析来自多个来源的威胁情报,以帮助识别和应对潜在威胁。 |
| 3. 漏洞扫描和漏洞管理 | 通过定期对Web应用程序进行漏洞扫描,及时发现和修复潜在的安全漏洞。 |
| 4. 网络流量分析 | 通过对网络流量进行深入分析,识别并定位攻击源,以便及时采取应对措施。 |
| 5. 恶意软件检测与清除 | 通过使用反病毒软件、网络安全设备等技术手段,及时检测并清除Web应用程序中的恶意软件。 |
| 6. 溯源与取证 | 通过追踪攻击活动的来源、路径和行为,收集取证材料,为后续的法律追责提供支持。 |
| 7. 事件响应计划与团队 | 建立和执行完善的事件响应计划,配备专业的应急响应团队,以确保在安全事件发生时能够迅速、有效地应对。 |
| 8. 持续监测和改进 | 通过持续监测和改进安全措施,及时发现和应对新的安全威胁和漏洞。 |
Web安全事件应急响应技术是保障Web应用程序安全的关键手段,通过及时监测、分析和应对,可以最大程度地降低安全风险,确保Web应用程序的安全性。
🚀一、Web 安全事件应急响应技术总结
🔎1.Web 应用入侵检测
从应急响应流程的角度讲,应急响应共包括准备、检测、抑制、根除恢复、跟踪6个阶段。然而,从操作层面讲,安全事件应急响应过程是由检测触发的。如果没有检测,就无法进行事件应急响应。检测发现异常才会触发应急响应的后续流程。最简单的检测方法是部署IDS、IPS、WAF等安全检测设备,并通过设定过滤规则来检测可能的入侵行为并进行报警,从而触发应急响应流程。此外,人工例行检测也是有效发现入侵行为的关键工作。
🦋1.1 Web 入侵人工检测指标
入侵后的系统会存在一些特征或者难免会留下一些痕迹,这些特征和痕迹是日常工作中应该进行例行检查的内容,例如:
(1)Web 页面被篡改,这是被攻击的最明显的信号,容易发现。
(2)应用系统中出现了不是由系统维护人员创建的账号(如app1账号)应特别关注在非工作时间创建的账号。
(3)系统存在不活跃的账号或默认账号的登录日志(如UNIX的SMTP账户、Windows的TsInternetuser账户)。
(4)应用程序服务器中发现无法解释的普通用户账号权限异常提升或超级用户权限的使用。
(5)Web 目录被窜改或者出现了不熟悉的文件或程序。这些文件通常起了个不容易发现的名字,如/mp/user/etc/inet.d/bootd,甚至是目录文件和目录的权限被异常修改,攻击程序造成的文件修改时间、文件大小发生变化通常无法解释。
(6)应用程序服务器中发现用户异常使用命令,如 SMTP 用户去编译程序
(7)应用程序服务器中出现了黑客工具。这通常意味着攻击者已经获得了一定控制权,并植入了黑客工具来提升权限或者攻击其他主机。
(8)应用程序服务器的操作系统日志出现一段空白,这是系统被攻破的一个重要标志。
🦋1.2 webshell 检测
☀️1.2.1 静态检测
目前自动查杀工具使用匹配文件特征码、特征值、危险函数 eval 等来查找 webshell。这种方法只能查找已知的 webshell,无法查杀变种及 0day型,而且误报率高。但是根据特征码强弱特征,并结合人工判断,可以减少漏报和误报的概率。即将特征码分为强特征和弱特征两种,强特征匹配则必是 webshell,弱特征则需要人工判断。
另外,可以利用文件系统的属性判断,如apache是 nobody 启动的webshell 的属主必然也是 nobody。如果 Web 目录突然多出一个 nobody 属主的文件,则必定有问题。
因此,对于单站点的网站来说,结合人工使用静态检测是很有好处的,可以快速定位 webshell。
☀️1.2.2 动态检测
Webshell文件执行时表现出的特征即动态特征。当Webshell执行系统命令时,可以观察到正在运行的进程。在Linux下,可以看到nobody用户启动了bash进程;而在Windows下,则是IIS用户启动了cmd进程。这些都是动态特征,通过进程ID(PID)可以定位Webshell。根据之前我们所说的Webshell的定义,我们知道Webshell总是通过一个HTTP请求。因此,如果我们在网络层监控HTTP请求,并且检测到有人访问了一个之前从未访问过的文件,并且服务器返回的状态码是200(表示服务器成功处理了请求),那么我们很容易就能定位到Webshell。这就是HTTP异常模型检测方法。需要注意的是,这种检测方法需要高性能的支持。如果将其与业务系统进行串联,可能会影响到业务系统的性能。
🦋1.3 Rootkit 检测
Rootkit是一个复合词,由root和kit两个词组成。root用来描述具有计算机最高权限的用户,而kit被定义为工具和实现的集合。在这里,Rootkit是指Linux平台下最常见的一种木马后门工具,它通过技术编码来获得root访问权限,完全控制目标操作系统和其底层硬件。通过这种控制,恶意软件能够在系统中隐藏自身的存在,这对其生存和持久性非常重要。简单地说,Rootkit是一种特殊类型的恶意软件,我们不知道它在做什么事情,普通的查毒软件基本无法检测到它,几乎不能删除它。Rootkit的目的是隐藏自己和其他恶意软件,阻止用户识别和删除攻击者的软件。Rootkit本身不会像病毒或蠕虫那样影响计算机的运行。它几乎可以隐藏任何软件,包括文件服务器、键盘记录器等,许多Rootkit甚至可以隐藏大型的文件集合并允许攻击者在您的计算机上保存许多文件,而您无法看到这些文件。
Rkhunter是一款Rootkit后门检测工具,中文名叫"Rootkit猎手"。它可以发现大多数已知的Rootkit以及一些嗅探器和后门程序。Rkhunter通过一系列的测试脚本来确认服务器是否已经感染Rootkit,包括检查Rootkit使用的基本文件、可执行二进制的错误文件权限以及检查内核模块等。RKHunter的功能包括以下几种。
(1)MD5 校验测试,检测文件是否有改动
(2)检测 Rootkit 使用的二进制和系统文件。
(3)检测特洛伊木马程序的特征码。
(4)检测常用程序的文件属性是否异常:
(5)检测隐藏文件。
(6)检测系统已启动的监听端口
(7)检测可疑的核心模块 LKM。
RKHunter 命令的参数较多,但是使用非常简单,直接运行 rkhunter 即可显示此命令的用法。下面简单介绍一下rkhunter 常用的几个参数选项。
(1)c,–check:必选参数,表示检测当前系统
(2)configfile<file>:使用特定的配置文件。
(3)cronjob:作为 cron 任务定期运行。
(4)sk,–skip-keypress:自动完成所有检测,跳过键盘输入。
(5)summary:显示检测结果的统计信息。
(6)update:检测更新内容。
下面就以实操形式演示该工具的查杀过程
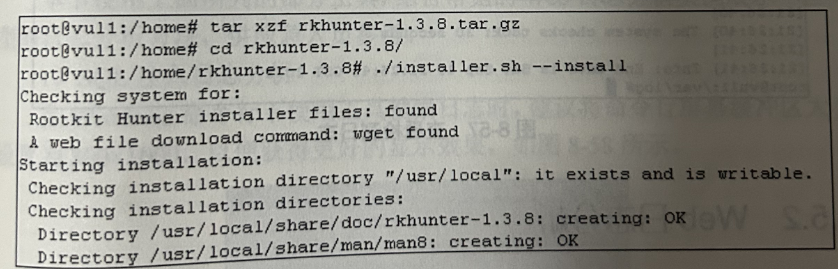
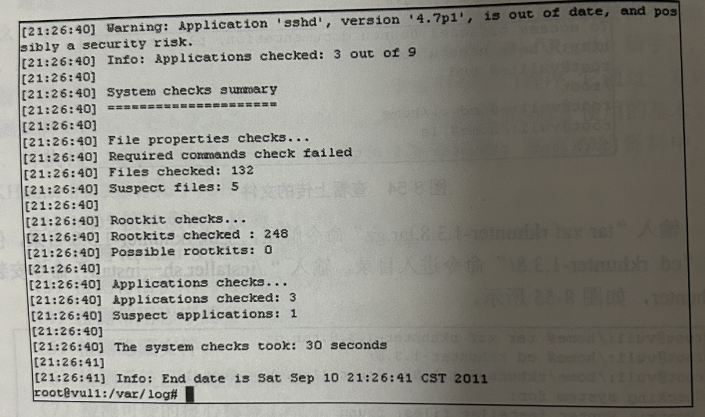
安装成功后,输入 rkhunter --check 命令即可进行完整的 Rootkit 检测流程,在检测过程中,发现的风险都会通过不同颜色字体突出显示。

Rootkit 检测完毕后,在/var/og/目录下会生成详细的检测日志 rkhunter.log,分析这些文件就能发现并取证这些 Rootkit 后门
🔎2.Web 日志分析
日志分析是计算机系统发现安全事件、分析入侵行为的重要手段。任何程序的运行都可能产生日志,如防火墙日志、操作系统日志、应用程序日志等。本节将重点讨论Web应用程序日志分析的方法。目前常见的日志分析方法有人工日志审计和自动化日志分析。人工审计日志的缺点是审计时间长、分析不全面。同时,若采用攻击特征匹配的方法,其准确性依赖于人对攻击特征的了解程度。因此,在应急响应过程中,通常会借助一些Web日志分析工具来更好地分析Web日志。
🦋2.1 日志分析工具
除了SQL注入入侵排查使用的Web Log suit pro日志分析工具外,还有其他常用的Web日志分析工具,包括:
1)Web日志安全分析工具:该工具支持大部分Web日志格式,报表清晰,但不支持多文件分析,其支持检测的攻击类型有限。
2)日志宝:该工具支持访问数据统计,可根据返回码、攻击类型、攻击源IP对分析结果进行分类,报表清晰直观。然而,该工具只支持在线日志分析,若日志较大,则需要花费较多的时间上传日志文件。
3)Notepad++:Notepad++是Windows操作系统下的一套文本编辑器。通过文件查找功能,在查找目标中写入需要查找的内容或者正则表达式,可实现在多文件中查询攻击者相关行为的功能。
4)常用的文本日志分析命令:常用的文本日志分析命令包括LogParser(Windows)、grep(UNIX/Linux/Windows)、awk(UNIX/Linux/Windows)、findstr(Windows)、wc(UNIX/Linux/Windows)、uniq(UNIX/Linux/Windows)、sort(UNIX/Linux/Windows)、split(UNIX/Linux/Windows)。
🦋2.2 典型日志分析
☀️2.2.1 SOL注入日志分析
在 Windows 命令行下使用工具搜索日志时,建议将命令行屏幕缓冲区大小设置为 300x1000,以便获得更好的显示效果
(1)利用 LogParser 分析
为方便查看,本章内所有 LogParser 命令均分为多行列举,在实际应用时应写在单行中,且关键字之间以空格隔开。
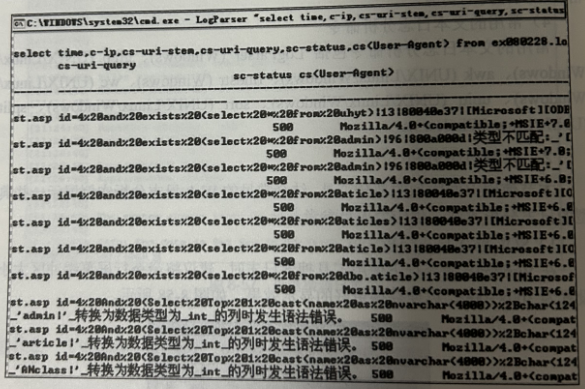
LogParser "select time,c-ip,cs-uri-stem,cs-uri-query,sc-status,cs(User-Agent) from ex080228.log where cs-uri-query LIKE '%select%'"
搜索目标日志 ex080228.log(如果搜索某目录下所有 log 文件,可使用 *.log 代替),搜索字段 cs-uri-query,即访问某页面时提交的参数。搜索关键字 select,使用通配符%select%代表匹配出类似“xxx select zzz”这样的关键字行。若搜索到匹配的行,则打印该行的time,c-ip,cs-uri-stem,cs-uri-query,sc-status,cs(User-Agent)这些字段中的内容。若在搜索结果的 cs-uri-query 字段中含有大量的 SQL语句,则这些日志至少说明有人在进行SOL注入的尝试,判断注入是否成功,需根据日志上下文做详细分析
在搜索过程中,建议不要只是用 select 作为关键字进行搜索,应尽可能多地更换关键字。另外,还需要注意多种不同的编码方式的搜索。
(2)利用 grep 分析
grep 命令无法像 LogParser 命令那样进行精确査询,但以一些常见的 SOL注入为关键字作为搜索文件也能排除大量的无用日志信息。
grep -i select%20 ex080228.log |grep 500 | grep -i \.asp
- -i参数用于表明搜索过程中忽略字符的大小写。
- select%20 为搜索时使用的关键字,其中%20 代表空格。
- ex080228.log 为搜索的目标文件(可用*.log 代替)。
- 竖线(|)为管道符号,此处意为在搜索结果中再次进行 grep 查询。
- grep 500是用来在前段搜索的结果中査找带有 HTTP 500 信息的行。
- grep -i .asp 则是搜索带有“.asp”关键字的行,即只对 asp 文件所产生的日志进行搜索,根据实际情况此处需要调整。
☀️2.2.2 反射型 XSS 日志分析
利用 LogParser 分析,相关命令如下
LogParser "select time,c-ip,cs-uri-stem,cs-uri-query,sc-status,cs(User-Agent) from ex080228.log where cs-uri-query LIKE '%<script>%'"
搜索日志中包含有<script>关键字的行。除了简单搜索<script>这样的关键字,还需考虑其他编码方式,或是其他测试手法,因此也建议搜索一些常见的标签,如 img、iframe等
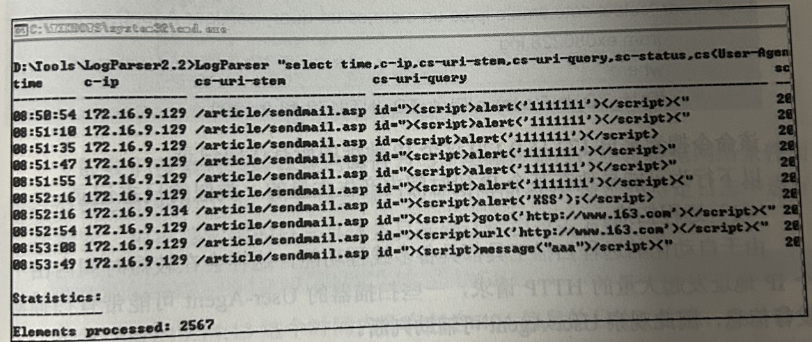
☀️2.2.3 特定时间日志记录搜索
LogParser "select time,c-ip,cs-uri-stem,cs-uri-query,sc-status,cs(User-Agent) from ex080228.log
where time
between
TIMESTAMP( '09:07:00', 'hh:mm:ss' )
and
TIMESTAMP( '09:08:00', 'hh:mm:ss' )"
此处 between … and 指令用于搜索某一范围内的日志,TIMESTAMP 指令则用于描述特定格式的时间,如TIMESTAMP(09:08:00,hh:mm:ss’)即是指明09:08:00的时间格式为hh:mm:ss(hh:时,mm:分,ss:秒)。该条命令搜索了09:07:00~09:08:00 的所有日志。
在 Apache 日志中,时间格式类似于[08/Apr/2009:10:47:12],因此,搜索某一特定时间内的日志可采用如下方法。
grep \[08/Apr/2009:10:47:* apache.log
☀️2.2.4 根据IP地址统计访问情况
LogParser "select date,time,c-ip,cs-uri-stem,cs-uri-query,cs(User-Agent),sc-status from ex080228.log where IPV4_TO_INT(c-ip) between IPV4_TO_INT('172.16.9.0') and IPV4_TO_INT('172.16.9.255')"
该命令搜索 172.16.9.0/24整个C段的IP 地址的访问记录。其中IPV4_TO_INT指令将IP地址转换为整型后进行比较等逻辑操作。若需要搜索某个特定IP地址的访问记录,可使用以下命令。
LogParser "select date,time,c-ip,cs-uri-stem,cs-uri-query,cs(User-Agent),sc-status from ex080228.log where IPV4_TO_INT(c-ip)=IPV4_TO_INT(172.16.9.129')"
该命令搜索来白 172.16.9.129这个IP地址的所有访问记录。以下行为可能导致在某个 IP 段时间内产生大量的、类似的日志记录
(1)远程扫描。
由于自动化的远程扫描工具都具备多线程功能,这样会在较短时间内由一个 IP 地址发起大量的 HTTP 请求,一些扫描器的 User-Agent 可能带有扫描器发行信息,因此观察 User-Agent 可辅助判断。
(2)表单或 HTTP 认证破解。
如果短时间内同一 IP 发起大量的 POST 请求,而请求地址又相同,则应查看该地址是否存在认证或数据提交的地方,若地址存在认证,那么远程可能在进行表单破解尝试;如果地址存在用户数据提交,则可能有远程自动化工具在进行数据提交尝试,这种尝试也属于扫描行为。
如果短时间内同一IP发起大量正常请求,而请求返回的HTTP 状态值(sc-status 字段)中含有大量的 401,那么该地址存在 HTTP 认证,且远程用户在尝试 HTTP 认证破解。
(3)目录猜解。
如果短时间内同一IP 发起大量请求,而这些请求返回的 HTTP 状态值中含有大量的 404信息,那么,该远程用户很有可能在进行目录猜解。
☀️2.2.5 目录猜解搜索
LogParser "select time,c-ip,count(time) as BAD
from ex080228.1og
where sc-status=404 group by time,c-ip having BAD>5"
命令以时间(time)作为计数器,以状态值(sc-status)等于 404(HTTP 404代表文件未找到)作为查询条件,当同一秒内出现的HTTP404超过5次,则打印该条日志的时间(time)、客户端地址(c-ip)和计数器(BAD)信息
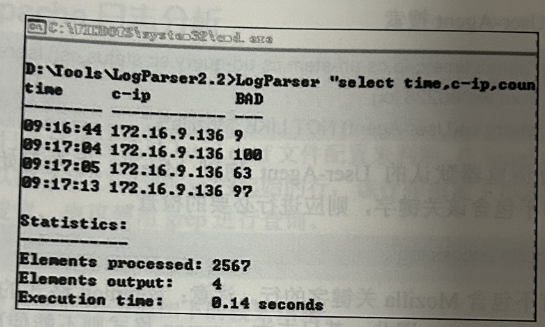
一般我们搜索目录时设定的阀值为5,实际搜索过程中可根据网络条件而定,但建议不要小于3。对于该结果,应使用时间和地址到特定日志中进行二次搜索,根据搜索到的日志具体条目来确认远程攻击方式。
grep 404 access.log |grep "2009:15:14:13"|wc -
搜索 2009:15:14:13 这个时间内所有包含 404 信息的日志。注意:grep 命令无法一次性完成类似于 LogParser 命令的精准查询,需多次筛选后人工判断时间范围。
LogParser "select time,c-ip,cs-uri-stem,count(time,cs-uri-stem) as BAD from ex090609.log where sc-status=200 and cs-method='POST' group by time,c-ip,cs-uri-stem having BAD>4"
命令以请求页面(cs-uri-stem)和时间(time)两个字段作为计数器,以状态值(sc-status)为查询条件,HTTP 方法为 POST,若每秒内对同一页面的请求次数超过 4次则打印
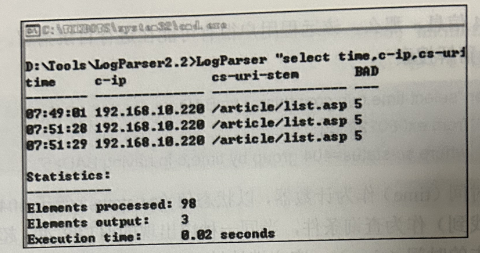
☀️2.2.6 异常 User-Agent 搜索
LogParser "select time,c-ip,cs-uri-stem,cs-uri-query,sc-status,cs(User-Agent) from ex080228.log where cs(User-Agent) NOT LIKE 'Mozilla%'"
绝大部分浏览器默认的 User-Agent 均以 Mozilla 作为起始关键字,若User-Agent 中不包含该关键字,则应进行必要的检査。
grep -v Mozilla access.log
搜索所有不包含 Mozilla 关键字的行。注意:common 格式的 Apache 日志默认不记录 User-Agent,因此,若日志为common 格式则不能使用该命令,否则将会列出全部日志
☀️2.2.7 异常的 HTTP请求分析
LogParser "select time,c-ip,cs-method,cs-uri-stem from ex090609.log where cs-method in('HEAD';'OPTIONS';'PUT';MOVE';'COPY';’TRACE';DELETE’)"
搜索 HTTP 方法字段(cs-method)是否为 HEAD、OPTIONS、PUT、MOVECOPY、TRACE 或 DELETE 中的一种。默认情况下,站点一般只使用 POST 和GET 两种方法,而使用不到这些方法。PUT方法特别危险,若含有PUT方法的日志中的状态值为 201,则说明远程用户已通过 PUT方法成功上传文件到服务器。
LogParser "select time,c-ip,cs-method,cs-uri-stemfrom ex090609.log where cs-method='PUT' and sc-status=201 "
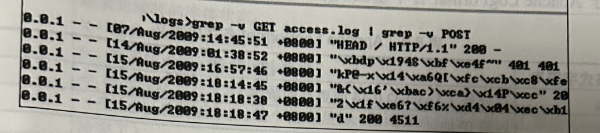
grep -v GET access.log | grep -v POST
搜索不包含 GET 和 POST 的行,在 Apache 日志中,标准的 HTTP 方法都被记录为大写,因此不需要使用-i参数
🔎3.Apache 日志分析
🦋3.1 日志位置
Apache 日志位置应通过 httpd.conf 文件配置来判断。在 httpd.conf 中搜索未被注释的、以指令字 CustomLog 为起始的行,该行即指定了日志的存储位置,可使用文本搜索,也可使用 grep 进行查询。
grep -i CustomLog httpd.conf | grep -v ^#
搜索结束后会获得类似如下的搜索结果。
CustomLog /var/mylogs/access.log common
其中/var/mylogs/为客户日志的路径,若此处未指明日志的完整路径而只是列举日志的文件名(如 access.log),则是指该文件存储于默认的日志存储目录下(即/var/log/httpd 或/var/httpd)。
🦋3.2 日志格式
CustomLog指令除了指定日志路径外,还指定了日志格式如下。
CustomLog /var/mylogs/access.log common
注意:apache 默认配置的日志格式为common 格式,该行中 common 为日志格式,日志格式在 httpd.conf 中也有相关定义。搜索指令字 LogFormat 即可查找关于日志格式的定义指令。
grep -i LogFormat httpd.conf | grep -v ^#
搜索结果类似如下描述。
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i" \"%{User-Agent)i\"" combined
LogFormat "%h % %u %t \"%r\" %>s %b" common
从上面搜索结果可见,common 的格式为"%h %l %u %t \"%r\" %>s %b"关于 Apache LogFormat 各个字段的定义和描述。
| 字段 | 定义 | 描述 |
|---|---|---|
| %a | 远程IP地址 | 发出请求的客户端的IP地址。 |
| %A | 本地IP地址 | 请求被处理的服务器的IP地址。 |
| %b | 传输给客户端的字节数 | 响应中传输给客户端的字节数。 |
| %B | 输出的字节数 | 整个响应中传输给客户端的字节数,包括HTTP头和响应体。 |
| %c | 请求的状态码 | |
| %D | 请求处理时间(微秒) | 从请求到响应的处理时间,以微秒为单位。 |
| %f | 请求的文件名 | 请求的文件名。 |
| %h | 客户端的主机名 | 如果无法解析主机名,则显示客户端的IP地址。 |
| %H | 请求的协议头 | 请求中包含的协议头。 |
| %i | 客户端的请求头 | 客户端发送的HTTP请求中的请求头。 |
| %k | 支持Keep-Alive的连接数 | 当前活跃的Keep-Alive连接数。 |
| %l | 客户端身份 | 通常为"-"(表示未知)。 |
| %m | 请求的方法 | HTTP请求的方法(GET、POST等)。 |
| %p | 服务器的端口号 | 服务器监听的端口号。 |
| %P | 进程ID | 处理请求的Apache进程的ID。 |
| %q | 请求的查询字符串 | 请求中的查询字符串。 |
| %r | HTTP请求的第一行 | 包括请求方法、URL和HTTP协议版本。 |
| %s | 服务器响应的HTTP状态码 | 服务器返回的HTTP状态码。 |
| %t | 请求的时间戳 | 以常见的Apache日志格式"[day/month/year:hour:minute:second zone]"表示。 |
| %T | 请求处理时间(秒) | 从请求到响应的处理时间,以秒为单位。 |
| %u | 请求的用户身份 | 如果未提供身份验证则为空。 |
| %U | 请求的URL路径 | 请求的URL中的路径部分。 |
| %v | 服务器的主机名 | 服务器的主机名。 |
| %X | 连接状态 | 如果连接是通过SSL加密的,则显示"+",否则为空。 |
| %I | 输入字节数 | 从客户端接收的字节数。 |
| %O | 输出字节数 | 发送给客户端的字节数。 |
| %{Foobar}i | 自定义请求头 | 请求头中名为"Foobar"的自定义请求头的值。 |
| %{Foobar}o | 自定义响应头 | 响应头中名为"Foobar"的自定义响应头的值。 |
🔎4.IIS 日志分析
🦋4.1 日志位置
IIS 日志默认存储于%systemroot%\system32\LogFiles\W3SVC 日录中,日志命名方式为exYYMMDD.log(YYMMDD 指年、月、日)。但IIS日志路径也可通过用户配置来指定,通过 Web 站点配置可确认其位置:打开 Web 站点,单击鼠标右键,选择“属性”,单击“活动日志格式”右侧的“属性”按钮,指定日志文件目录,即可存放 IIS 日志

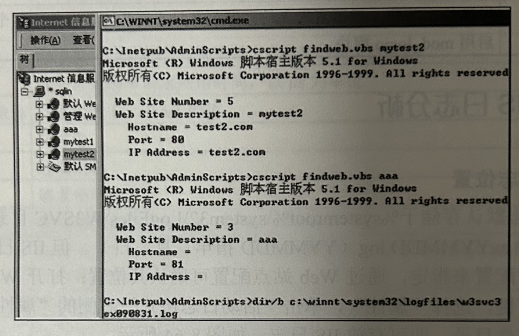
自定义IIS日志位置时若目标系统为虚拟主机,并在IIS上配置了多个站点,这些站点的日志均以文件夹的形式存储于%systemroot%\system32\LogFiles中(目录根据用户配置而不同),每个虚拟站点用于存储日志的目录名类似W3SVCxxx,其中xxx为数字,为确认每个站点对应的数字编号,可使用IIS5.0 中附带的 findweb.vbs 脚本查找。
findweb.vbs 使用方法: cscript findweb.vbs site name(site name为IS中示的站点名称),在返回的信息中,“Web Site Number”一项的值即为目录数字编号。
如 cscript findweb.vbs aaa,返回站点名为 aaa 的信息,若其数字编号为 5,则其存储日志的目录为%systemroot%\system32\logfiles\w3svc3,如图所示。
🦋4.2 日志格式
IIS 日志格式也可根据用户需求进行自定义,定义之后每个字段的含义在每个 IIS 日志文件的第4行(以#Fields 起始的行)会有相关的提示,信息类似如下。
#Fields: date time c-ip cs-username s-ip s-port cs-method cs-uri-stem cs-uri-query sc-status cs(User-Agent)
Fields用于指明当前日志中各列的含义,常见含义描述如下。
(1)date:日期,默认格式为 yyyy-mm-dd。
(2)time:时间,默认为 GMT+0。
(3)c-ip:客户端IP地址。
(4)cs-username:若页面存在认证(HTTP认证),此列显示认证时客户端使用的用户名。
(5)s-ip:服务端 IP 地址。
(6)s-port:服务器的端口。
(7)cs-method:客户端使用何种 HTTP 方法访问。
(8)cs-uri-stem:请求的页面文件。
(9)cs-uri-query:请求页面时发送的参数。如访问 http://site/abc.asp?id=100,那么cs-mehotd为GET,cs-uri-stem为abc.asp,cs-uri-query 为id=100。
(10)sc-status:返回的 HTTP 状态值。
(11)cs(User-Agent):客户端发送的 User-Agent。
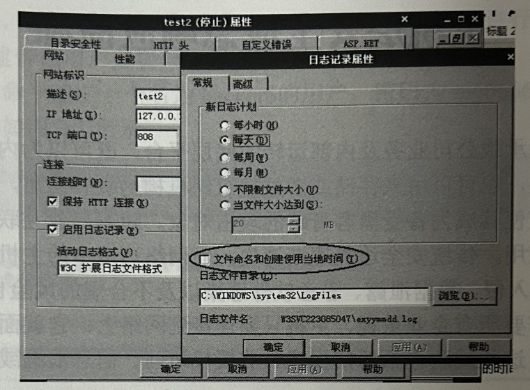
需要注意的是,进行 ⅡS 日志分析前,应先在站点属性中确认 ⅡS 是否使用了当地时间,否则默认使用的时间为GMT+0,在最终统计时间时需要额外+8,如图所示。
🔎5.其他服务器日志
🦋5.1 Tomcat 服务器日志
日志文件通常位于 Tomcat 安装目录下的 logs 文件夹内,若不存在,则参考 Apache Tomcat 日志位置,通过${catalina}/conf/server.xml 配置来判断。${catalina}是 Tomcat 的安装目录,默认为 Tomcat 安装目录下的 logs 文件夹,代码如下。
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" prefix="localhost_access_ log." suffix=".txt" pattern="common" resolveHosts="false"/>
🦋5.2 nginx 服务器日志
日志存储路径在 nginx 的配置文件 nginx.conf中。其中,access_log 变量规定了日志的存储路径与名字,以及日志格式名称,默认值为 access_log
🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”

- 点赞
- 收藏
- 关注作者
评论(0)