一起步入人工智能,了解机器学习

了解人工智能、机器学习,学习AI算法,欢迎大家沟通交流
目录
定义
构造复杂的、拥有与人类智慧同样本质特性的机器。
机器学习
一种实现人工智能的方式。机器学习最基本的做法是使用算法解析数据从中学习,然后对真实世界中的事件进行预测和决策。与传统的特定任务、硬编码的软件程序不同,机器学习是用大量的数据来训练,通过各种算法从数据中学习如何完成任务。
经验+思维=规律
数据+算法=模型
数据量决定了模型的高度,算法只是逼近这个高度
大数据是机器学习的根基
大数据是对历史的总结、机器学习是对未来的展望
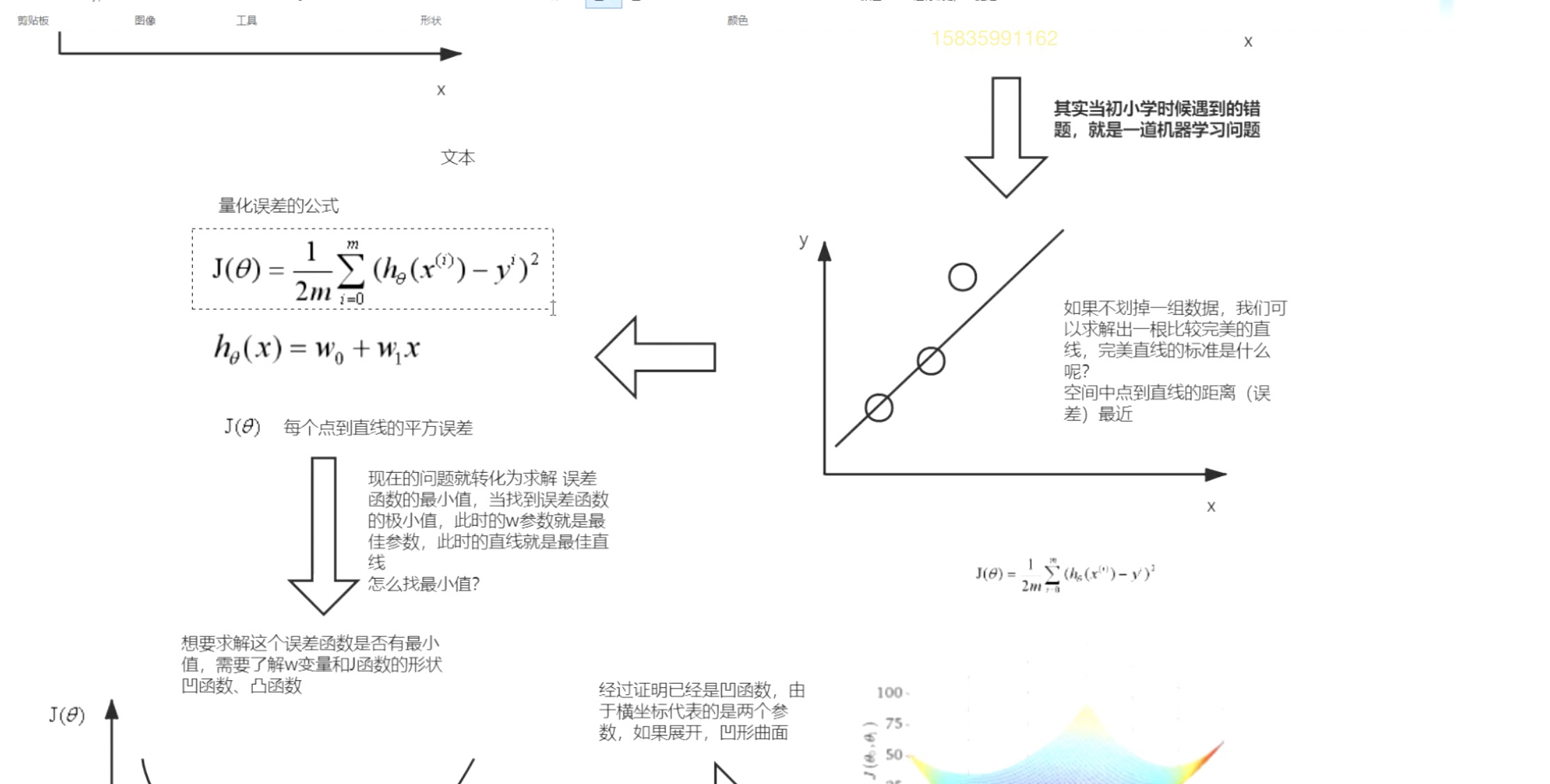
线性回归(回归算法)
在空间中找到一条合适的直线。
什么是合适的直线:
- 距离空间中的点误差小。
- 可以代表空间中的数据规律。

编辑
编辑
编辑
编辑
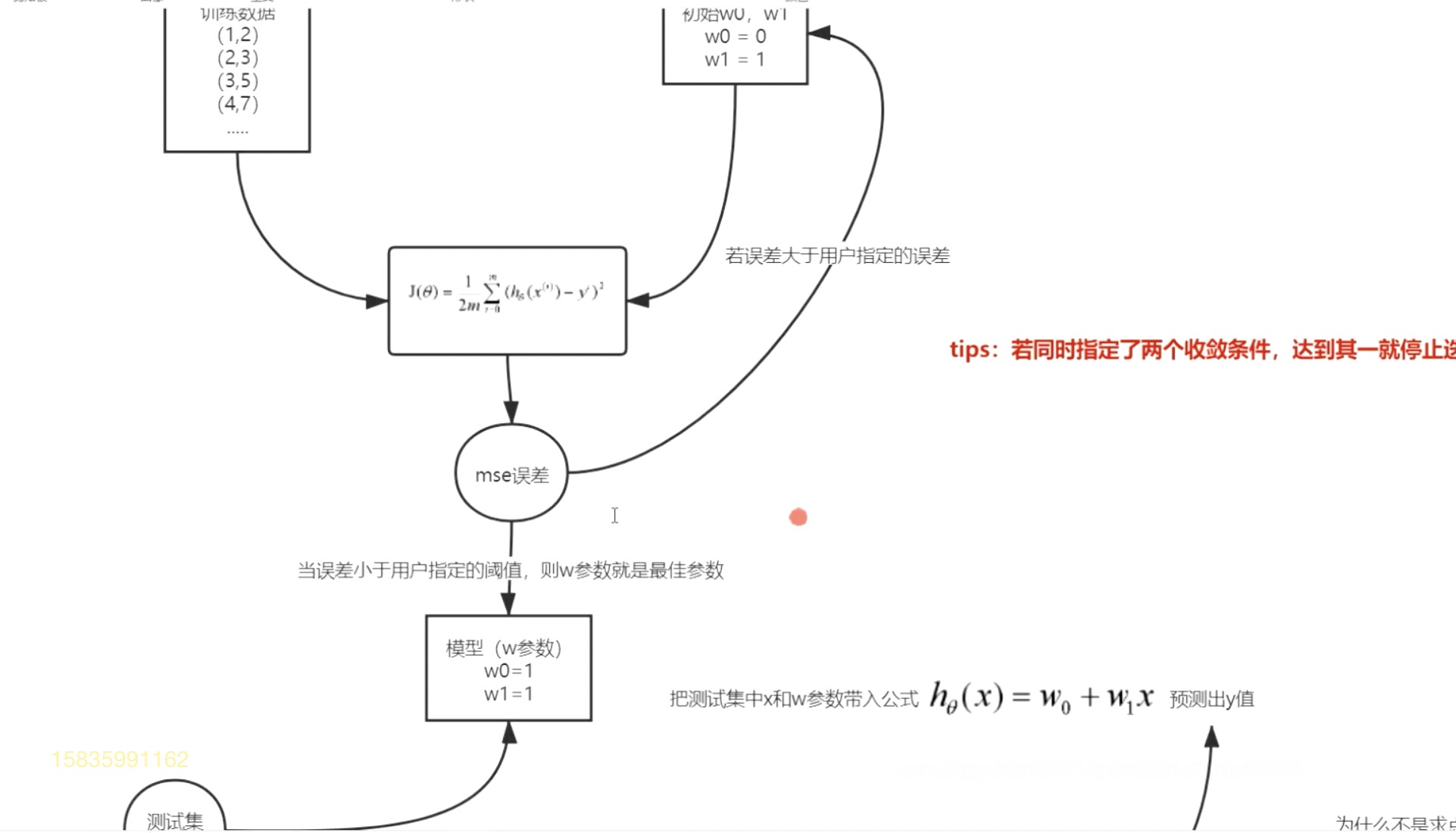
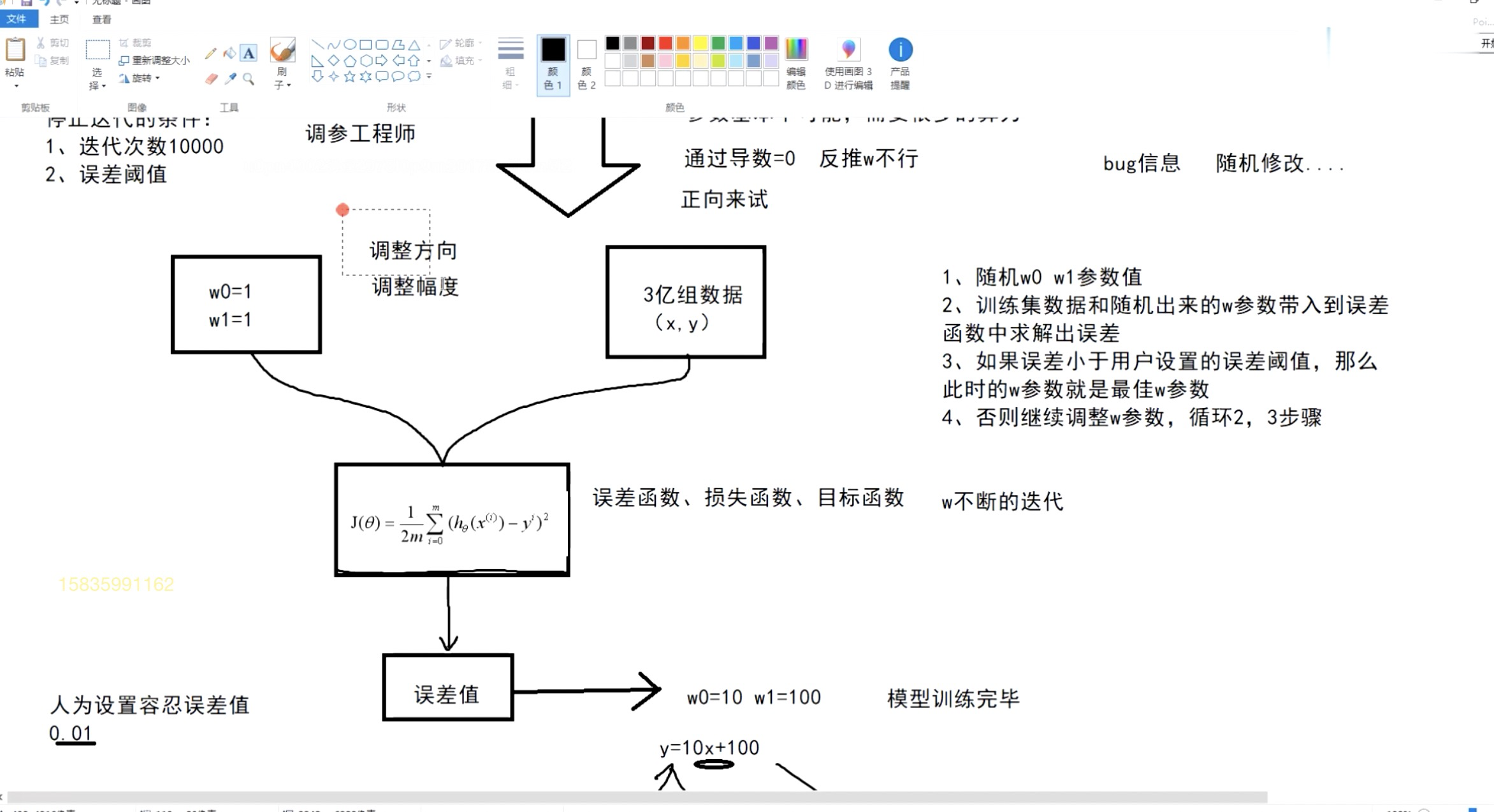
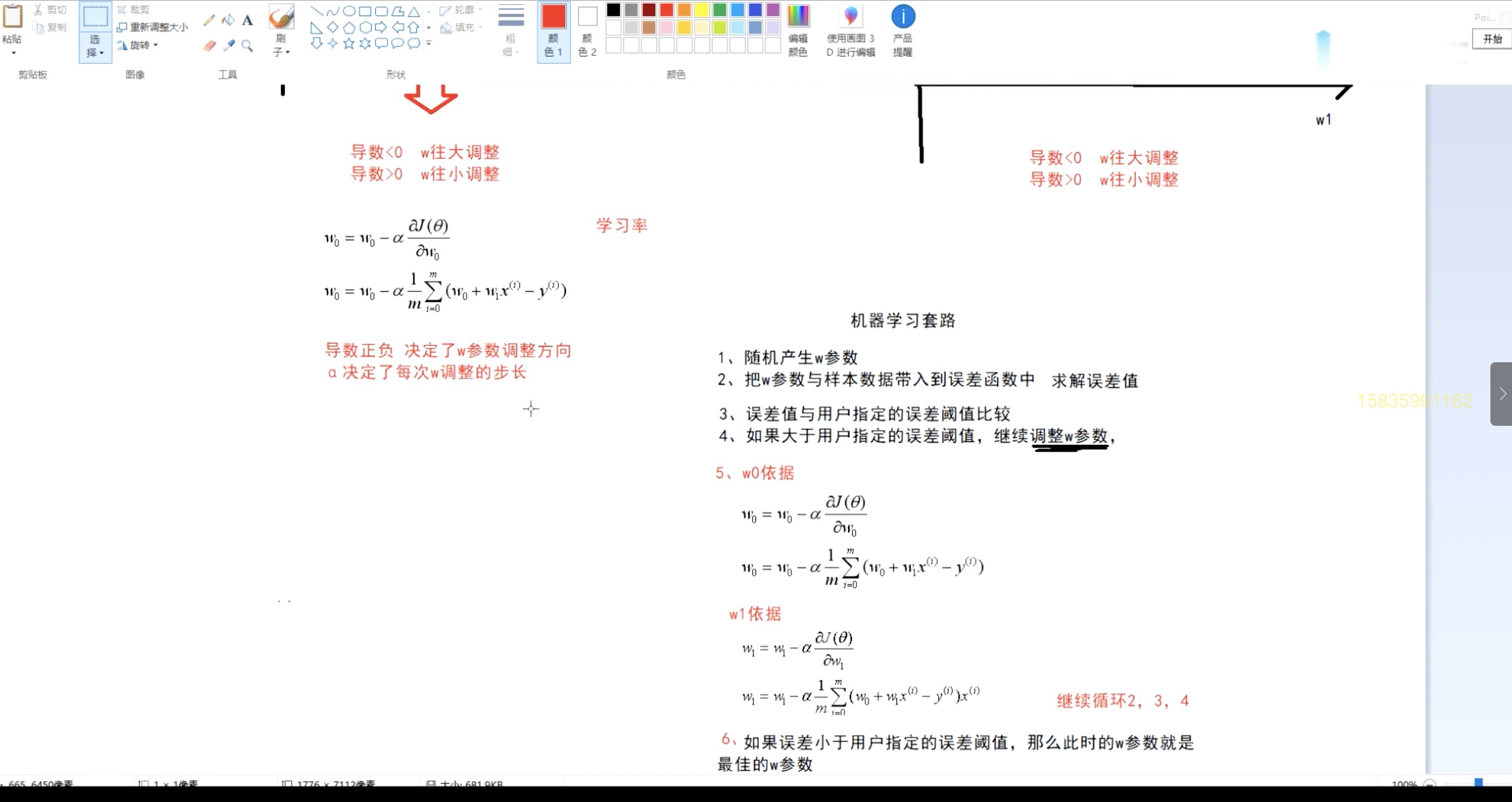
梯度下降法:优化误差函数(损失函数),调整w参数。
贝叶斯(分类算法)
逆概
条件概率
公示:p(A|B)=P(A)*P(B|A)/P(B)
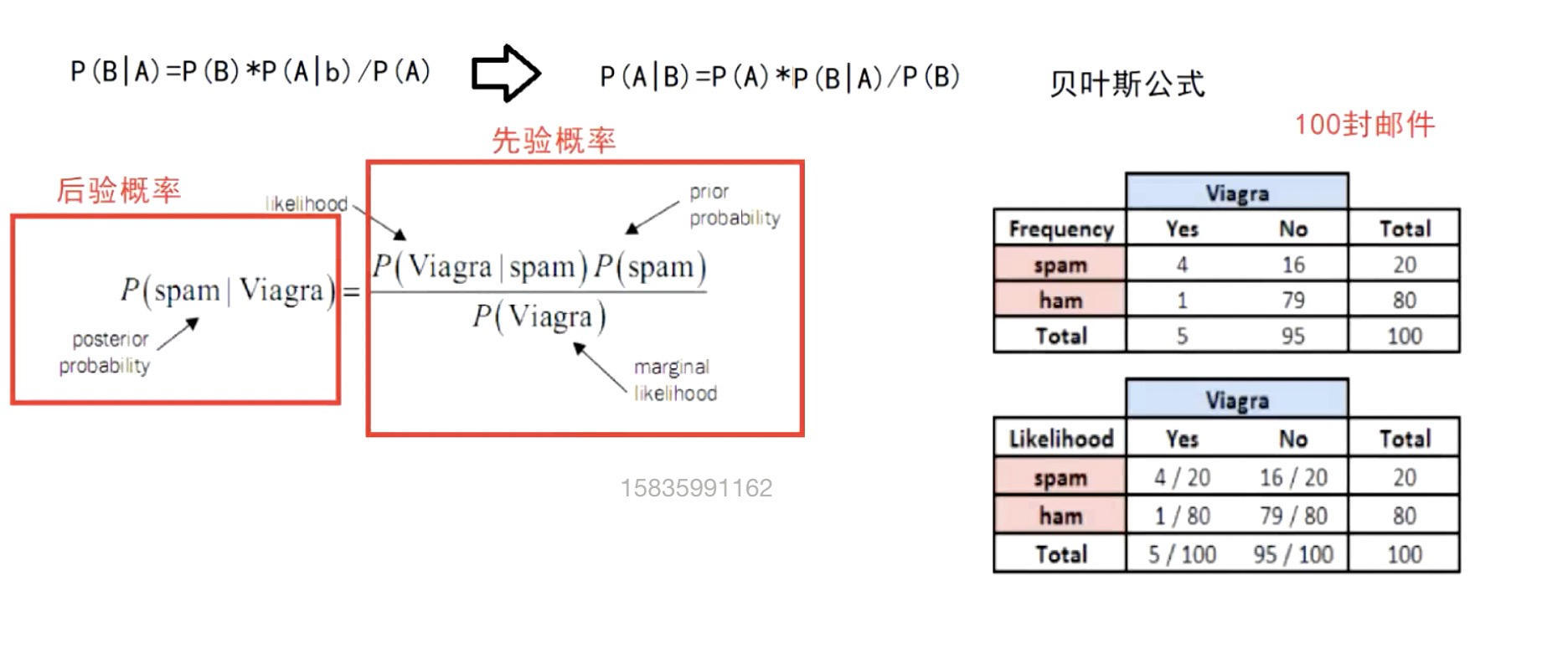
编辑
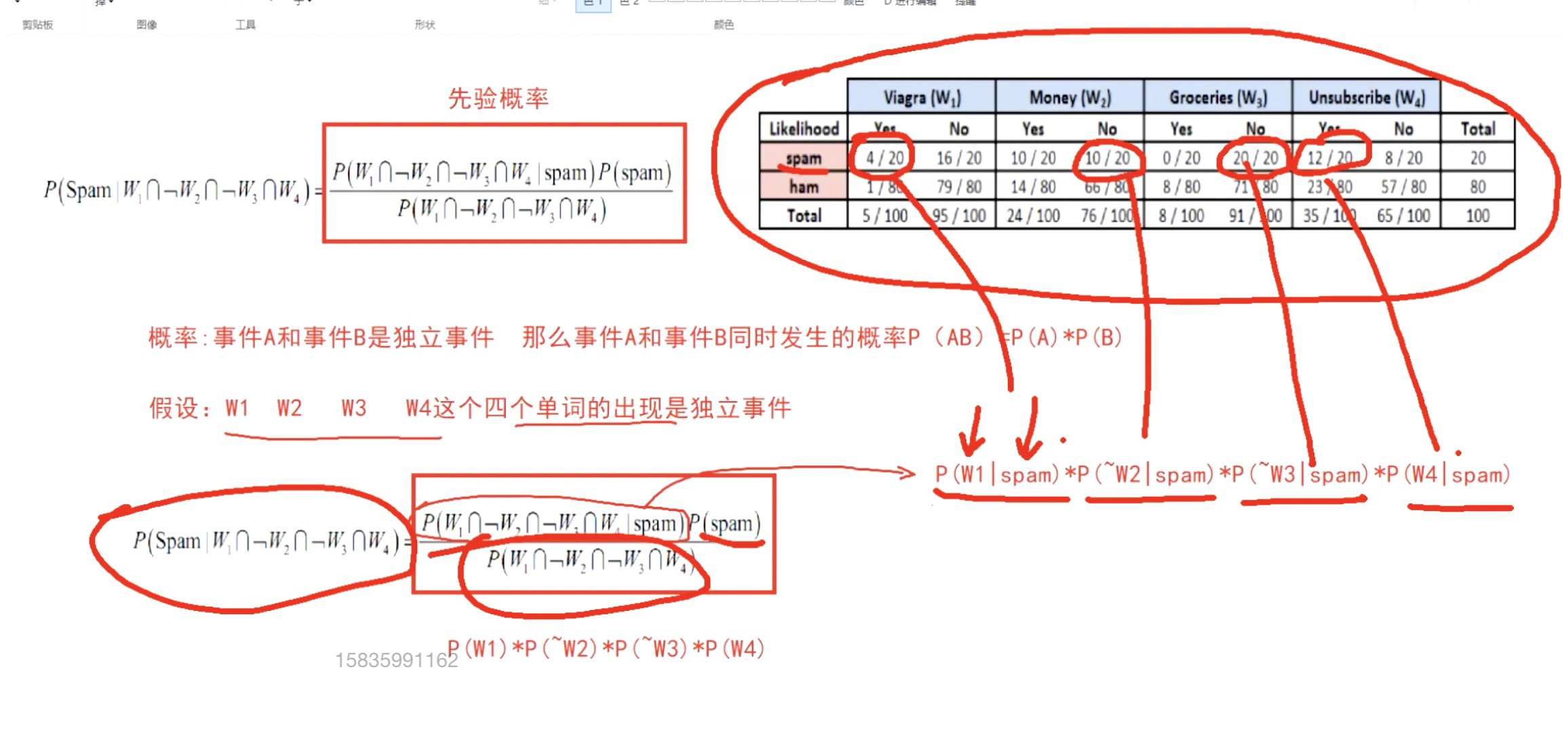
编辑
适用简单分类
KNN(分类算法)
KNN思想:如果一个样本在特征空间中的K个最相似的样本中的大多数属于一个类别,则该样本也属于这个类别。k值不同,预测的结果也可能不同。

编辑
距离测度的几种方法:
- 欧式距离:两点直线距离。
- 平方欧氏距离
- 曼哈顿距离:没有斜线
- 余弦距离:一般用来计算文本相似度
- 闵可夫斯距离:对一组距离的定义
归一化问题:
**如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖**(比如这时实际情况是值域范围小的特征更重要)数据归一化将所有数据映射到统一尺度
适用多分类
Kmeans(聚类算法)
聚类算法是一种无监督的机器学习任务,无监督是一种对不含标记的数据建立模型的机器学习范式,可以自动将数据划分,因此聚类分组不需要提前被告知所划分的组应该是什么样的。我们甚至不知道我们在寻找什么,所以聚类是用于只是发现而不是预测。
聚类流程(不断迭代):
- 随机找到k个样本(中心点)
- 计算空间中所有样本与k个样本的距离
- 统计每一个样本与k个样本距离的大小,距离哪个k样本最近,那么属于哪一类
- 每个组中重新计算一个新的中心点,中心点可能为虚拟的点
- 再次计算空间中所有样本与这个k中心点的距离
- 再次重新分类
- 依次迭代,直到中心点坐标不再改变或指定迭代次数
问题一:如果随机中心点比较集中,导致聚类效果差,迭代次数高
解决:
Kmeans++ 算法,Kmeans升级版,在第一步选中心点优化。首先找第一个中心点差c1,依次找距离前面中心点远的中心点。
a.从输入的数据点集合中随机选择一个点作为第一个聚类中心
b.对于数据集中的每一个点x,计算它与最近聚类中心的距离D(x)
c.选择一个新的数据点作为新的中心点,选择的原则是:D(x)较大的点被选取作为聚类中心的概率较大
d.重复复b和c直到k类聚类中心被选出
e.利用这k个出事的聚类中心运行标准的k-means算法
问题二:k值怎么选择?选几个?
聚类效果好不好?衡量标准:类与类之间的差异大,但是类内部相似度很高
解决:
肘部法
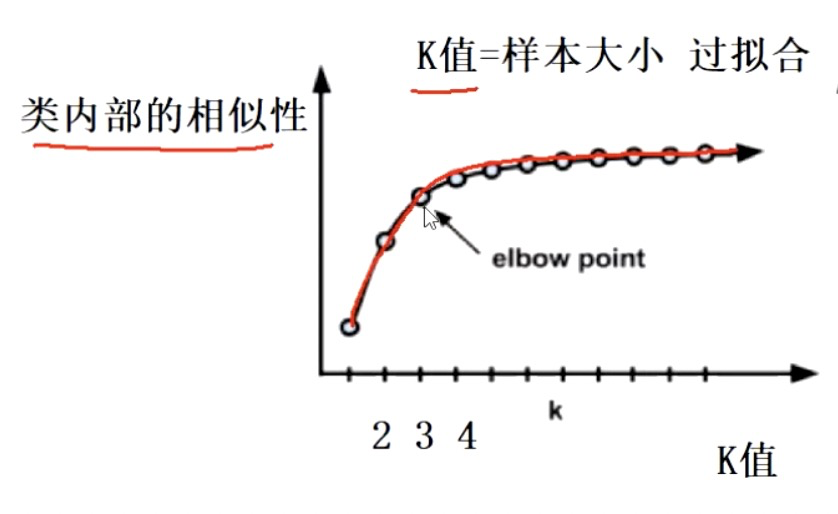
编辑
逻辑回归(分类算法)

编辑
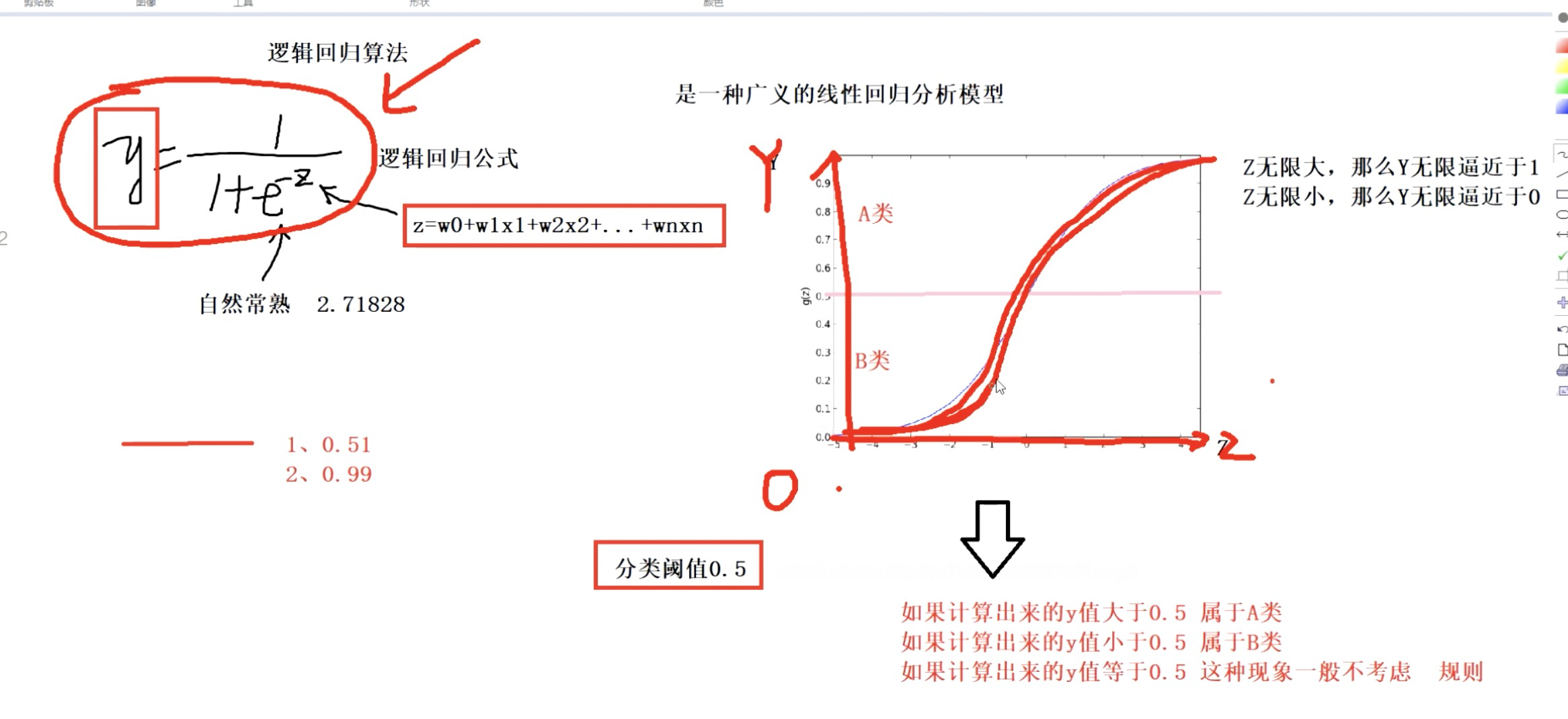
编辑

编辑

编辑
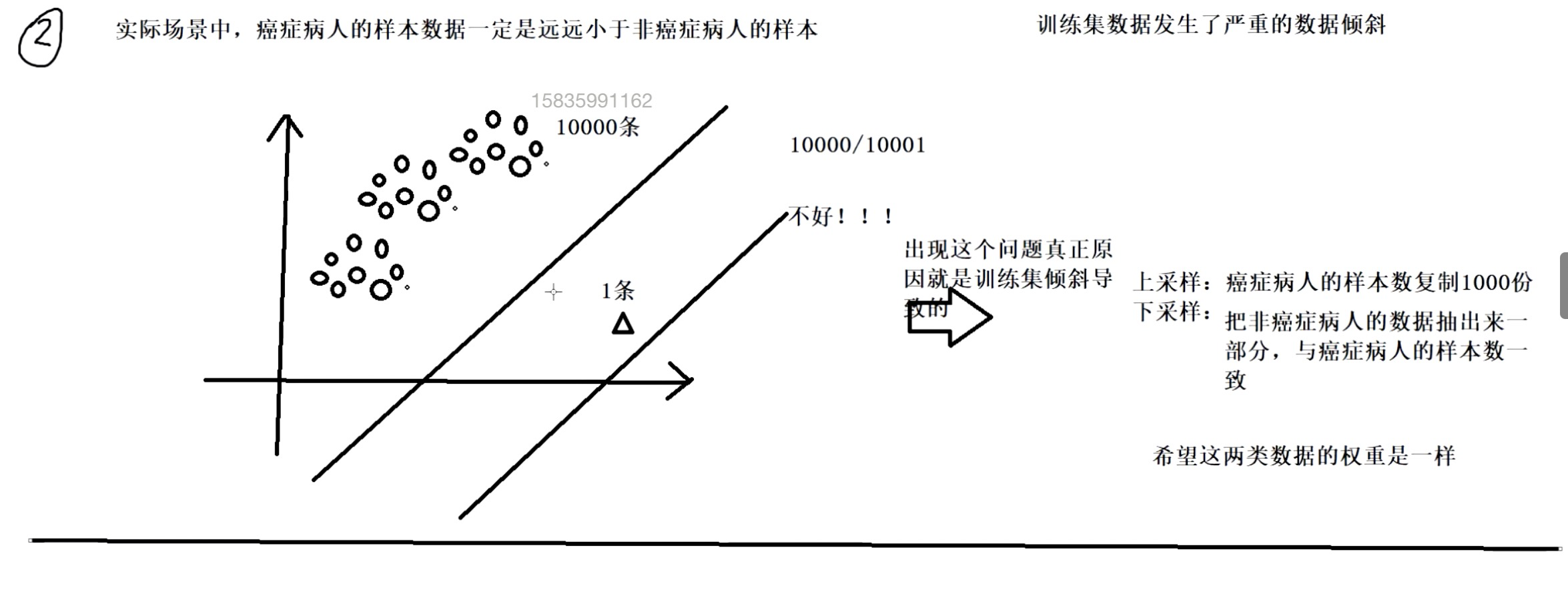
编辑
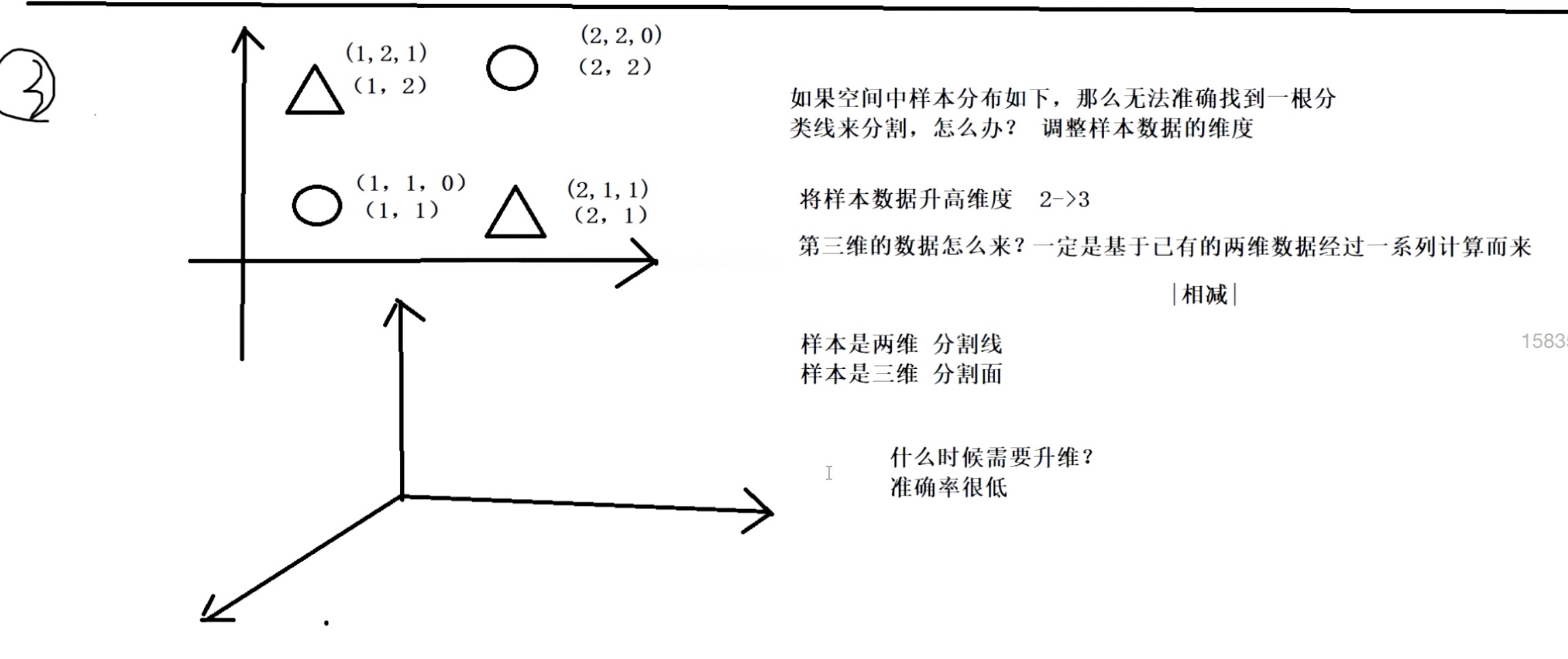
编辑
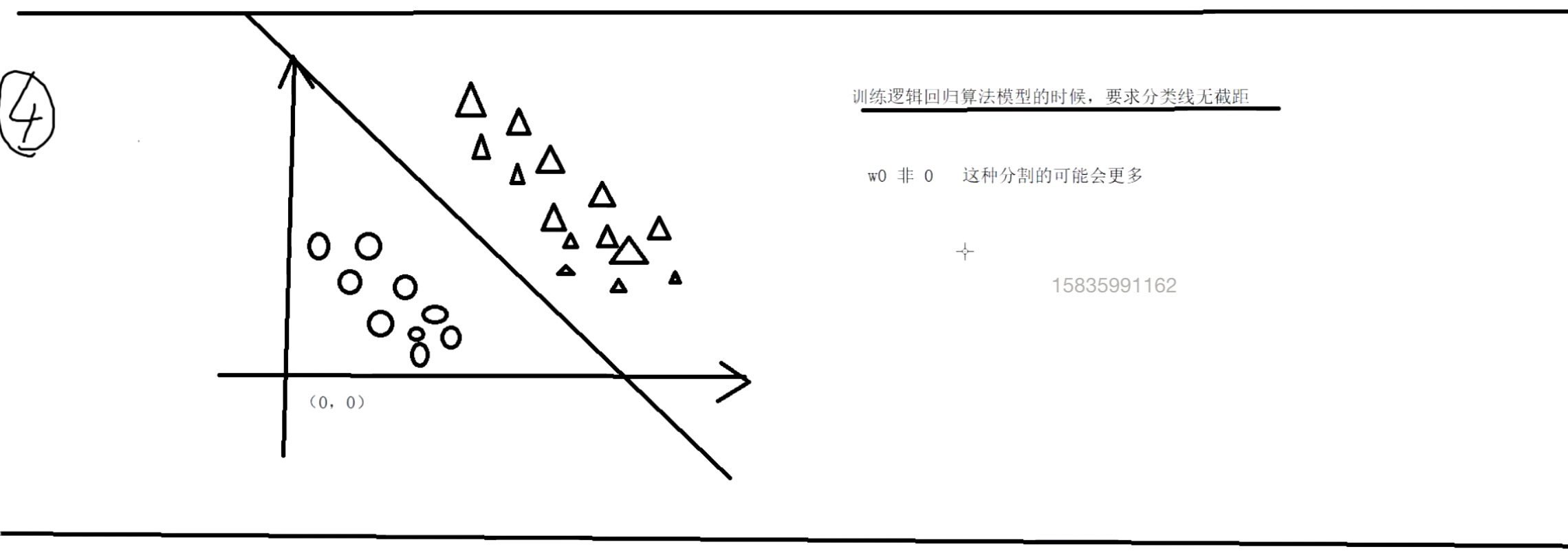
编辑
线性回归VS逻辑回归
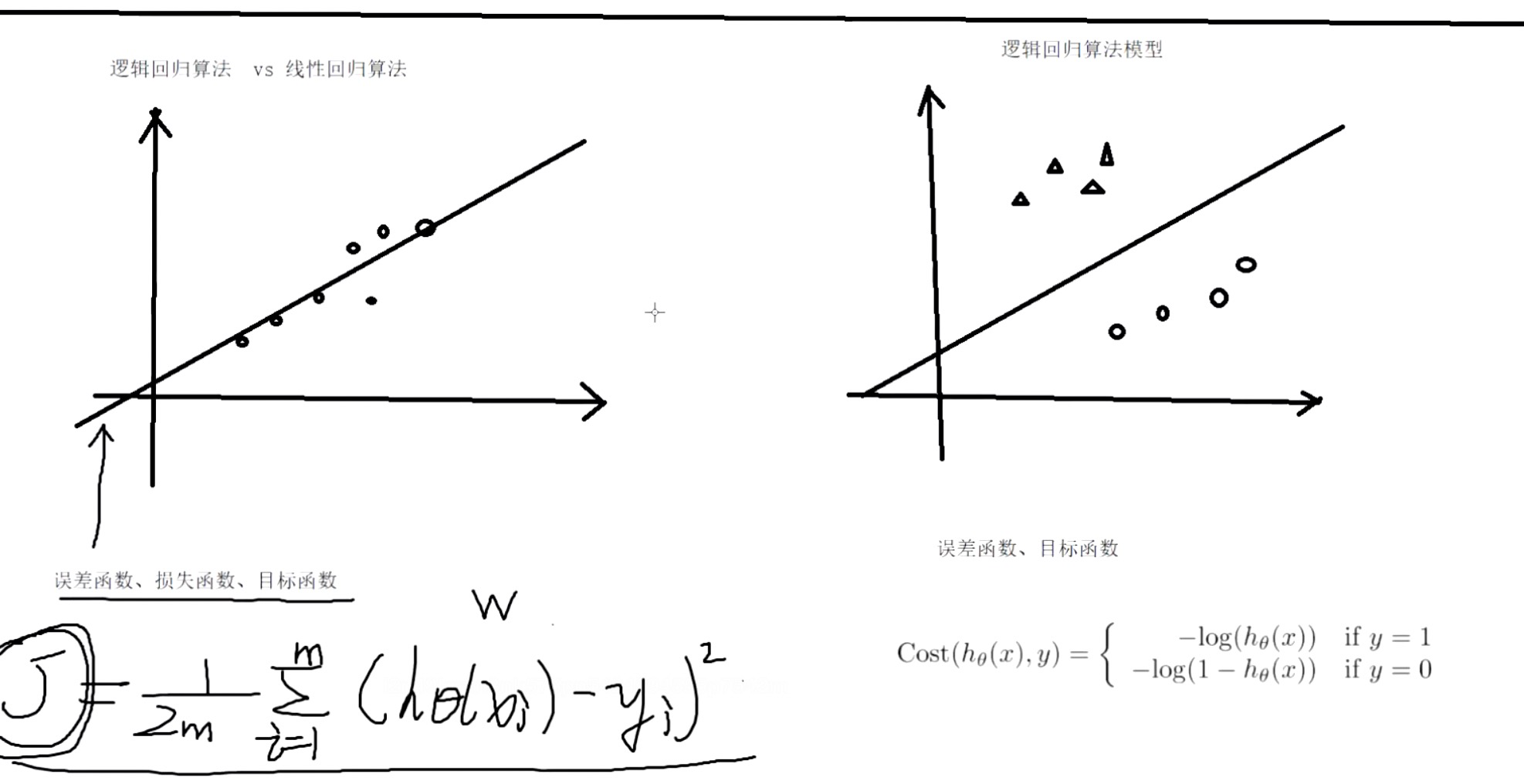
编辑

编辑
决策树(分类算法)&随机森林
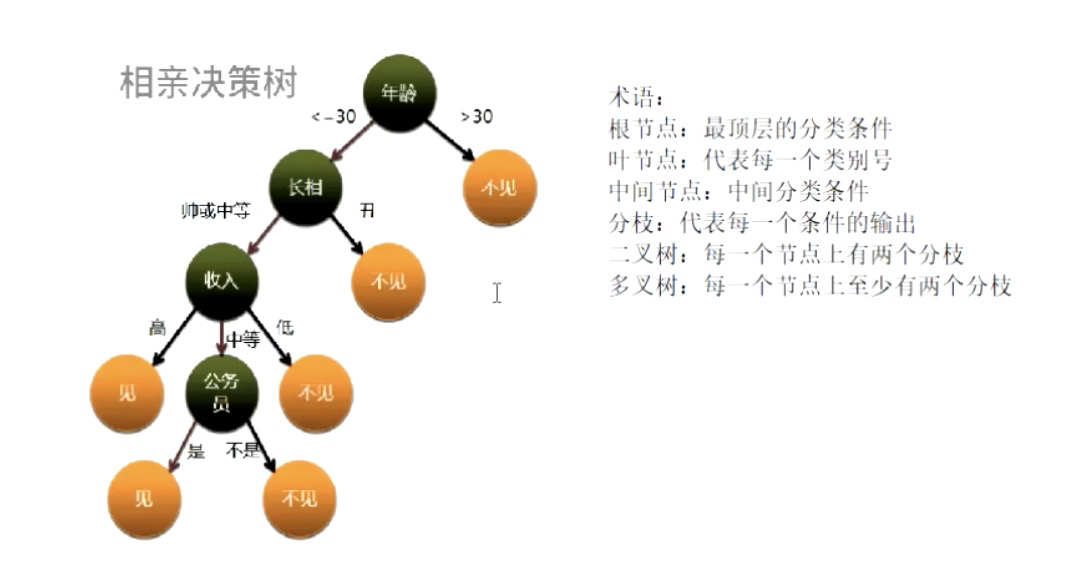
编辑

编辑
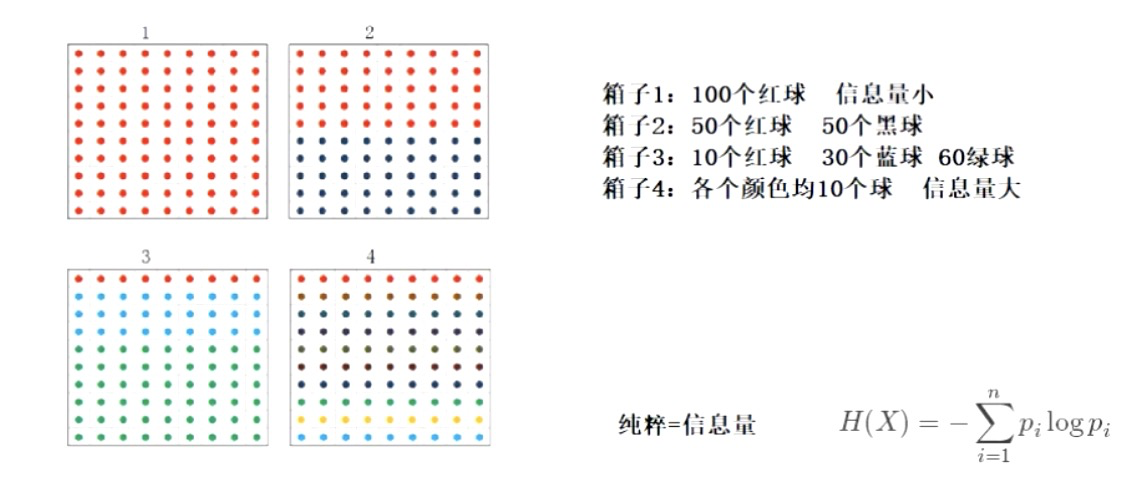
编辑
纯粹度用信息熵表示

编辑

编辑

编辑
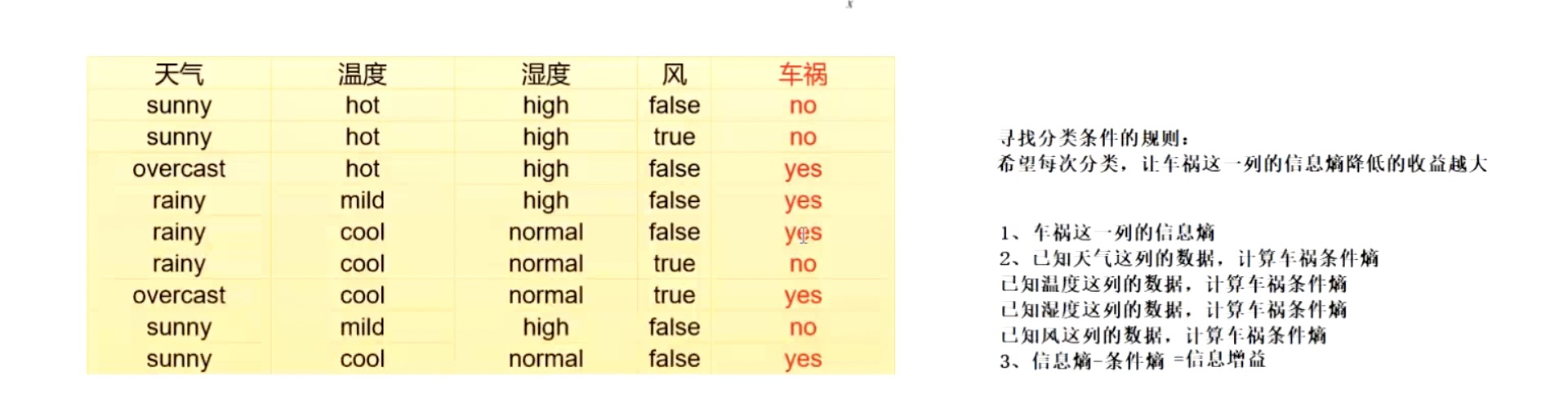
编辑

编辑

编辑
总结:决策树有监督的非线性分类,通过树来分类,根据历史数据对已知的分类结果以及分类条件进行计算达到最有效、最纯粹的分类。计算流程:
1. 计算各个分类结果的信息熵(纯粹度)=-(分类结果1占比\*log分类结果1占比+分类结果n占比\*log分类结果n占比)。
2.计算各个分类条件的条件熵=-(分类结果1/分类条件1)+(分类结果n/分类条件1)\*分类条件1占比-(分类结果1/分类条件n)+(分类结果n/分类条件n)\*分类条件n占比。
3.获得信息增益(信息熵-条件熵),信息增益最大先进行分类。
4.为了防止过拟合问题(比如用id作为条件分类),可以使用信息增益率(信息增益/信息熵)来进行分类。
5.信息增益率也会出现过拟合问题,这个时候需要进行剪枝操作:
(1)预剪枝:指定树的高度、信息增益等指标,达到指标后不在进行分类
(2)后剪枝:树已构建出,对已有的树进行剪枝。通过对比剪枝前与剪枝后(某个节点的叶子节点)的误差决定是否剪枝,剪枝前误差<剪枝后的误差需要剪枝。误差函数:信息熵\*该节点样本数+叶子节点个数。
决策树缺点:
1.运算量大,需要一次性加载所有的数据到内存。并且寻找分割条件极耗资源。
2.抗干扰能力差,训练数据样本出现异常数据会产生很大影响。
随机森林
随机森林=分布式决策树。解决运算量大、抗干扰能力差。
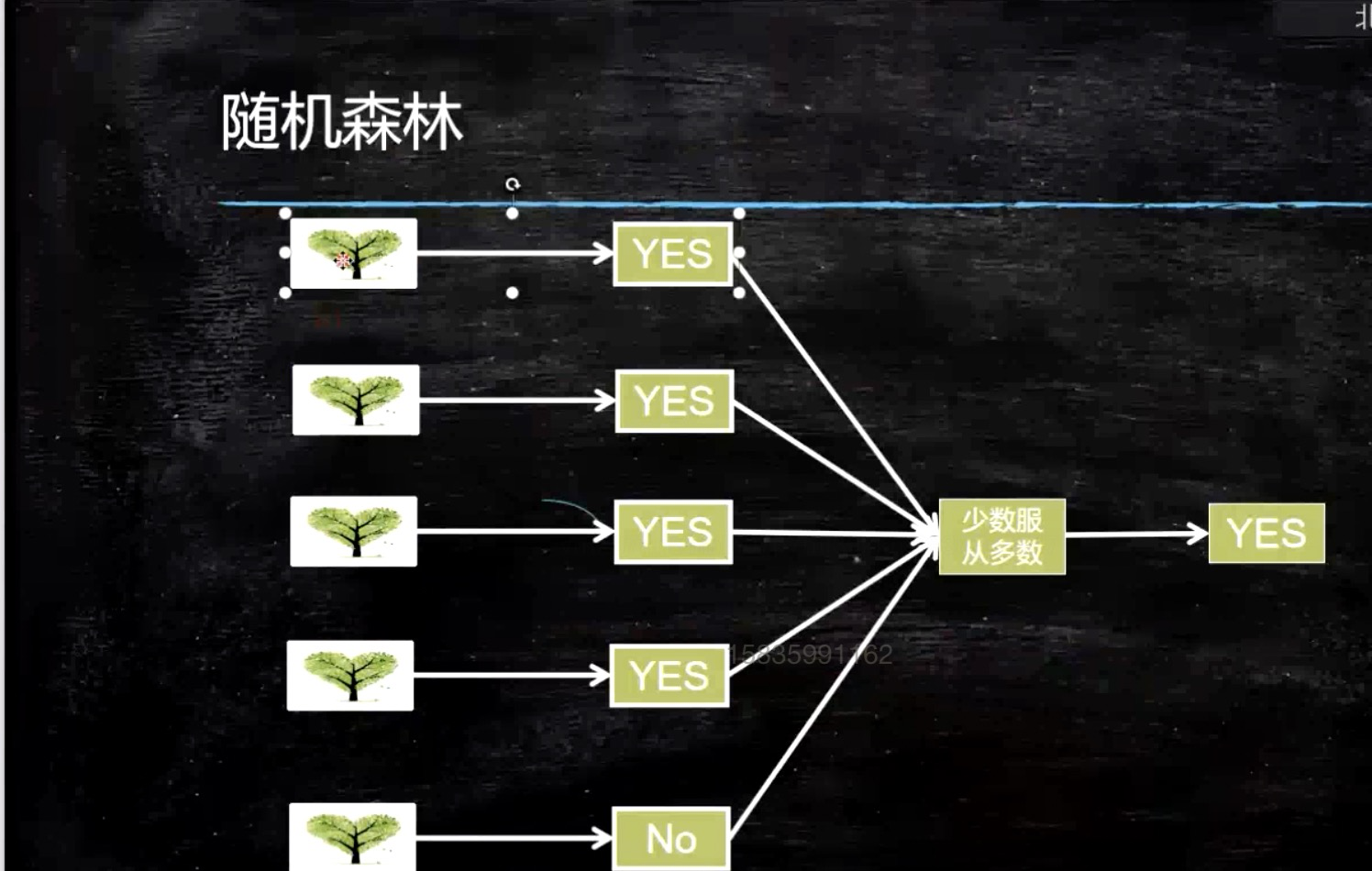
编辑

- 点赞
- 收藏
- 关注作者
评论(0)