数据结构界的终极幻神----树

目录
一.数的概念和分类
种类
二.重点概念
哈希树:
二叉树的线索化
什么是线索化
为什么要线索化
特殊的查找树
完全二叉树
三.手撕完全二叉树(堆)
重点讲解
向上搜索算法
向下搜索算法
一.数的概念和分类
树(tree)是包含 n(n≥0) [2] 个节点,当 n=0 时,称为空树,非空树中
条边的有穷集,在非空树中:
- (1)每个元素称为节点(node)。
- (2)有一个特定的节点被称为根节点或树根(root)。
- (3)除根节点之外的其余数据元素被分为
 个互不相交的集合,其中每一个集合本身也是一棵树,被称作原树的子树(subtree)。
个互不相交的集合,其中每一个集合本身也是一棵树,被称作原树的子树(subtree)。
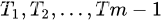 ,其中每一个集合
,其中每一个集合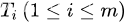 本身也是一棵树,被称作原树的子树(subtree)。
本身也是一棵树,被称作原树的子树(subtree)。树也可以这样定义:树是由根节点和若干颗子树构成的。树是由一个集合以及在该集合上定义的一种关系构成的。集合中的元素称为树的节点,所定义的关系称为父子关系。父子关系在树的节点之间建立了一个层次结构。在这种层次结构中有一个节点具有特殊的地位,这个节点称为该树的根节点,或称为树根。
树中的节点具有明显的层级关系,并且一个节点可以对应多个节点。 我们可以形式地给出树的递归定义如下:
单个节点是一棵树,树根就是该节点本身。
设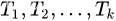 是树,它们的根节点分别为
是树,它们的根节点分别为 。用一个新节点
。用一个新节点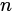 作为
作为 的父亲,则得到一棵新树,节点n就是新树的根。我们称
的父亲,则得到一棵新树,节点n就是新树的根。我们称 为一组兄弟节点,它们都是节点
为一组兄弟节点,它们都是节点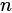 的子节点。我们还称
的子节点。我们还称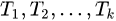 为节点n的子树。
为节点n的子树。
空集合也是树,称为空树。空树中没有节点;
孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
节点的度:一个节点含有的子节点的个数称为该节点的度;
叶节点或终端节点:度为0的节点称为叶节点;
非终端节点或分支节点:度不为0的节点;
双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
兄弟节点:具有相同父节点的节点互称为兄弟节点;
树的度:一棵树中,最大的节点的度称为树的度;
节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
树的高度或深度:树中节点的最大层次;
堂兄弟节点:双亲在同一层的节点互为堂兄弟;
节点的祖先:从根到该节点所经分支上的所有节点;
子孙:以某节点为根的子树中任一节点都称为该节点的子孙;
森林:由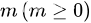 棵互不相交的树的集合称为森林。
棵互不相交的树的集合称为森林。
种类
无序树:树中任意节点的子结点之间没有顺序关系,这种树称为无序树,也称为自由树;
有序树:树中任意节点的子结点之间有顺序关系,这种树称为有序树;
二叉树:每个节点最多含有两个子树的树称为二叉树;

满二叉树:叶节点除外的所有节点均含有两个子树的树被称为满二叉树;

完全二叉树:除最后一层外,所有层都是满节点,且最后一层缺右边连续节点的二叉树称为完全二叉树;

二叉搜索树:满足左子节点比父节点小,右子节点比父节点大

哈夫曼树(最优二叉树):带权路径最短的二叉树称为哈夫曼树或最优二叉树。
二.重点概念
哈希树:
其实在数据结构中哈希树的概念并不怎么被认可,不过在区块链中确实有这种概念
哈希树,也称为默克尔树(Merkle Tree),是一种树形数据结构,用于在计算机科学中高效地验证和组织数据。哈希树特别适用于需要快速查找和验证大量数据的情况,如在区块链技术中。
哈希树的每个节点都包含数据的哈希值,这使得它可以用于数据完整性的验证。树的根节点包含整个数据结构的哈希值,即默克尔根(Merkle Root)。如果数据结构中的任何部分发生更改,会导致默克尔根变化,从而能够检测到这些更改。
哈希树在密码学和安全领域有着广泛的应用,特别是在数字签名和加密货币(如比特币)中,它用于确保交易记录的安全性和不可篡改性。
二叉树的线索化
什么是线索化
线索化的步骤:
根据某种遍历序列(前、中后序遍历),先确定下来每个节点的前驱和后继。
对于每个节点来说,他的左右指针可能没有指向节点(值为NULL),这时候我们可以运用这些“空闲”的指针。比如:左指针如果有空闲,就用这个指针指向这个节点对应遍历序列的前驱,右指针如果有空闲,就用这个指针指向这个节点对应遍历序列的后继。(注意:遍历序列中一头一尾是没有前驱或者后继的,所以如果指针有空闲,我们还是当它指向的是孩子,而不是前驱或者后继)
对于每个节点都实现了步骤2后,线索化完成
为什么要线索化
我们来线索化主要有两个原因
从空间上来说
对于一颗有n个节点二叉树,每个节点都有两个指针,这一棵树的所有节点总共有2n个指针。对于除了根节点以外的节点,每个节点都对应着一个指向其的指针,有且仅有这些指针是非空的,共有(n-1)个指针,那么空值指针就有n+1个,这个数量是很大的,对于空间的浪费也比较多
从遍历实现上
在我们用二叉树的递归遍历时,会遇到两个问题,一是:遍历需要的时间较多;二是:递归时候不断创建函数副本,对于内存来说也有一定压力。如果我们只用先进行一次递归遍历实现线索化,之后通过线索来遍历,能大大减少遍历时间和内存风险。
或者栈等数据结构来保持遍历的状态。而线索化后的二叉树可以通过线索(即额外的指针)直接找到前驱和后继节点,从而无需用额外的空间。这样可以提高遍历的效率和性能。
原文链接:https://blog.csdn.net/m0_74222411/article/details/132240822
我们常听到有的人说线索二叉树,但其实这种说法并不准确,准确来说应该是二叉树的线索化
特殊的查找树

但所有子节点都比父节点大时,就会破会树状结构,这是就引入了一些新的树形结构AVL树,红黑树

完全二叉树
通俗来讲就是,该结构的n-1层都被填满,最后一层可以不满,但从左至右不能有空位,必须按位置顺序排列,不能两个子节点中间空一个节点的位置
而满二叉树则是一种特殊的完全二叉树,堆则是完全二叉树
堆分为大堆和小堆
大堆即父节点的数据大于子节点,小堆反之
三.手撕完全二叉树(堆)
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <assert.h>
typedef int HeapDataType;
typedef struct Heap
{
HeapDataType* data;
int size;
int capacity;
}HP;
void initHP(HP* php)
{
assert(php);
php->data = NULL;
php->size = 0;
php->capacity = 0;
}
void destroyHP(HP* php)
{
assert(php);
free(php->data);
php->capacity = 0;
php->size = 0;
}
void Swap(HeapDataType* x, HeapDataType* y)
{
HeapDataType temp = *x;
*x = *y;
*y = temp;
}
void adjustUP(HeapDataType* p, int size, HeapDataType data)
{
int child = size;
int parent = (child - 1) / 2;
while (parent >= 0)
{
if (p[parent] < p[child])
{
Swap(&p[parent], &p[child]);
child = parent;
parent = (parent - 1) / 2;
}
else break;
}
}
void pushHP(HP* php, HeapDataType data)
{
assert(php);
if (php->capacity == php->size)
{
int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;
HeapDataType* tmp = (HeapDataType*)realloc(php->data, sizeof(HeapDataType) * newcapacity);
if (tmp == NULL)
return;
php->data = tmp;
php->capacity = newcapacity;
}
php->data[php->size] = data;
php->size++;
adjustUP(php->data, php->size - 1, data);
}
bool isEmpty(HP* php)
{
assert(php);
return php->size == 0;
}
HeapDataType topHP(HP* php)
{
assert(php);
assert(!isEmpty(php));
return php->data[0];
}
void adjustDown(HeapDataType* p, int size, HeapDataType data)
{
int parent = 0;
int child = parent * 2 + 1;
if (p[child] < p[child + 1])
child++;
while (child <= size)
{
if (child + 1 <= size && p[parent] < p[child])
{
Swap(&p[parent], &p[child]);
parent = child;
child = child * 2 + 1;
if (p[child] < p[child + 1])
child++;
}
else break;
}
}
void popHP(HP* php)
{
assert(php);
assert(!isEmpty(php));
Swap(&php->data[0], &php->data[php->size - 1]);
php->size--;
adjustDown(php->data, php->size, php->data[0]);
}重点讲解
向上搜索算法
在我们插入新的数据到该结构时(这里以小堆为例),我们需要判断子节点是否会比父节点还小,如果是,则要将子节点与父节点进行交换,直到不是
向下搜索算法
与向上搜索算法同理,应用于删除第一个节点
首先将第一个数据和最后一个数据交换位置,然后让新的第一个数据向下(因为这个数据为父节点,有可能比下面的某个子节点小),这是我们有两个选择,与左节点交换还是右节点,答案是最小的那个,这样才能保证最后被换上来的父节点最小

- 点赞
- 收藏
- 关注作者
评论(0)