【论文精读】基于知识图谱关系路径的多跳智能问答模型研究

文章目录
🍋论文介绍
论文题目:基于知识图谱关系路径的多跳智能问答模型研究
作者信息:张元鸣,姬琦,徐雪松,程振波,肖刚
(浙江工业大学计算机科学与技术学院,浙江杭州 310023)
🍋摘要
多跳问题是一类通过知识推理才能给出答案的复杂问题,往往需要相关的多项关联知识融合生成最终答案.现有基于知识图谱的多跳智能问答方法推理过程比较复杂,没有考虑关系路径蕴含的结构信息和语义信息.为此,本文提出了基于知识图谱关系路径的多跳智能问答模型,*将多跳智能问答问题转换为在低维向量空间中查找知识图谱中最优关系路径的问题.*该模型利用表示学习将知识图谱和用户问题同时嵌入到低维的向量空间,实现知识空间和问题空间的统一表示;然后结合主题实体向量表示和问题向量表示对候选实体进行语义评分,产生候选答案集 合;以问题实体为起始节点,以候选答案实体为结束节点,从知识图谱中抽取与问题相关的关系路径集合;将关系路径 进一步嵌入到低维的向量空间,生成关系路径的向量表示,在向量空间中查找与问题语义匹配度最高的关系路径,最终根据关系路径生成多跳问题的答案.在公开的数据集上对所提出的模型进行了实验,结果表明该方法与现有方法 相比不仅具有良好的性能,而且具有良好的稳定性,不会随着问题跳数的增加而降低性能.
关键词:智能问答;知识图谱;复杂多跳问题;关系路径;表示学习
🍋1 引言
随着近年来信息技术的飞速发展,人类知识总量趋 于指数级增长,智能问答综合运用信息检索、深度学习和 自然语言处理等技术,充分理解用户语义,快速获得用户 问题的精确答案,在搜索引擎、教育、金融、电商等领域具 有广泛应用,成为当前自然语言处理领域的研究热点
…
主要分为基于模板的方法、基于语义匹配的方法和基于表示学习的方法.
-
基于模板匹配的方法针对特定知识领域和用户问题设计严密的问题模板,再利用模板匹配生成答 案,但性能依赖于模板数量,难以全面覆盖用户问题和知识库.
-
基于语义解析的方法通过分析用户问题的语 义组成,将用户问题转换为逻辑形式或结构化查询,但 语义分析的级联误差将降低答案的准确性
-
基于表示学习的方法则将知识库和用户问题特征嵌 入到低维向量空间,通过向量计算进行知识推理,是目前 智能问答研究的主流技术
接下来作者引入了Sun等人对于知识问答或其相关步骤所做的一些贡献
现有基于表示学习的方法往往从问题的主题实体 出发在知识图谱上通过逐步推理寻求问题答案,没有 考虑多跳问题中关系路径蕴含的结构信息和语义信
息,难以充分捕捉实体之间的复杂关系.针对该问题
接下来作者简单介绍了一下解决方案~
本文提出新的基于知识图谱关系路径的多跳智能问答 模型,建立主题实体到答案实体之间的关系路径,并将 关系路径嵌入到低维向量表示,在向量空间中查找与 问题语义匹配度最高的关联路径,再根据最优关系路 径生成最终答案,简化了多次检索知识图谱子图多步 推理过程,具有良好的性能和适用性
🍋2 问题描述
知识图谱本质上是一种结构化语义网络,通常用==< 实体-属性-属性值>与<头实体-关系-尾实体>==三元组方 式表达,为知识推理提供了结构化知识库.
多跳智能问答可以形式化描述为:在知识图谱G 上,根据主题实体h、关系路径l给出问题q的答案集合 Aq⊆E,∀a∈A q是问题q正确的答案实体.本文假定问题的所有答案都是知识图谱中的实体,且每个问题只 包含一个主题实体
🍋3 多跳智能问答网络模型
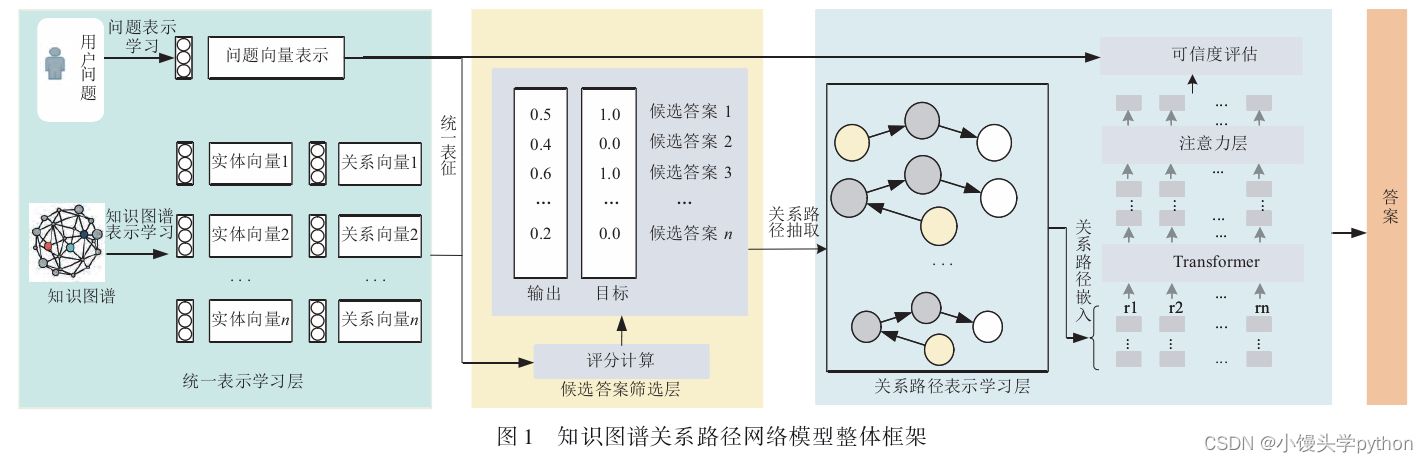
为了提高多跳智能问答的性能,本节给出了一个知识图谱关系路径网络模型(Knowledge Graph Relation⁃ ship Path Network,KGRPN),将问题与答案涉及的关联知识映射到知识图谱的关联路径,将智能问答问题转换 为知识图谱以主题实体为开始节点的最优关联路径查找问题.图1给出了模型的整体框架,该模型主要包括
统一表示学习层、候选答案筛选层和关系路径表示学习层.统一表示学习层分为知识图谱表示学习模块和用户问题表示学习模块,其中知识图谱表示学习模块将实体 和关系进行向量表示,
…
- 统一表示学习层(知识图谱表示学习模块、用户问题表示学习模块)
- 候选答案筛选层
- 关系路径表示学习层
- 知识图谱表示学习模块将实体 和关系进行向量表示
- 用户问题表示学习模块是对用户提出的问题进行向量表示
- 候选答案筛选层从知识图谱中提取主题 实体的所有可达实体,筛选与问题语义相关的实体作为 候选答案
- 关系路径表示学习层从知识图谱中抽取与主题实体相关的关系路径,并将关系路径嵌入到低维的向 量空间
- 根据问题语义相似度查找最优关系路径,生成问题最终答案
🍋3.1 统一学习表示层
🍋3.1.1 知识图谱表示学习
知识图谱表示学习旨在将知识图谱中实体和关系 的语义信息嵌入到低维向量空间,增强智能问答的准确性.本框架采用ComplEx表示学习模型[22],该模型能够将知识图谱中的实体和关系嵌入为包含实部和虚部 的复向量,在保留点积运算计算效率优势的基础上,使 实体的非对称关系能够得到不同的表征


🍋3.1.2 问题表示学习
问题表示学习旨在==将用户提出的问题也嵌入到低维 向量空间,并将该向量映射到与知识图谱相同的向量空间.==本模型采用RoBERTa预训练语言模型捕捉多跳问题隐含的丰富语义信息,该模型根据输入的自然语言问句能够生成融合文本上下文信息的深层双向语言表征[23]

🍋3.2 候选答案筛选层
候选答案筛选是从知识图谱中选择候选答案实体,提高下游关系路径推理的准确性.在向量空间中,根据问题向量表示的语义信息和主题实体向量表示的 特征信息评价答案实体的可信度,从而快速筛选出语义相关的实体作为候选答案.将问题视为主题实体和答案实体之间的语义联系,根据已经得到的向量表示计算语义评分,计算公式为:

🍋3.3 关系路径表示学习层
关系路径是指在知识图谱中主题实体到候选答案 实体依次经过的关系的序列,而跳数则表示关系路径的长度.如果关系路径长度为1,则是简单问题;如果关 系路径长度大于1,则是多跳问题.对于多跳问题,需要 通过融合关系路径的关联知识生成最终答案.
从知识图谱中抽取以主题实体为起点、候选答案 实体为终点的所有关系路径,其中关系路径的长度需 小于设定的最大跳数,并剔除重复的关系路径,关系路
径示意图如图2所示.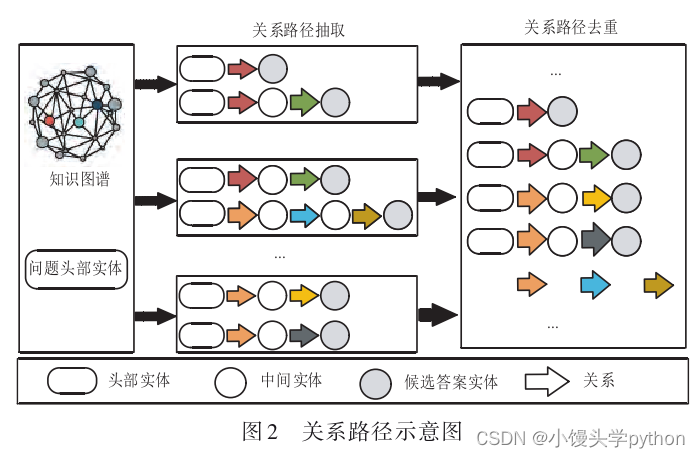
将每个关系的向量表示进一步融合生成关系路径的向量表示.本文采用Transformer网络[24]和全局注意力机制生成关系路径的向量表示,关系路径的表示学习网络模型如图3所示.Transformer是一种基于自注意 力机制的序列编码模型,该模型包括Encoder和De⁃ coder两个部分,Encoder包含6层叠加的Transformer block,每个Transformer-block包含多头注意力机制、残差连接、层归一化、全连接网络四个部分,输入为句子 词汇的词向量编码和位置编码之和,其中位置编码层 的目的是区分句子中词的位置关系能学习到输入序列与输出序列之间的对应关系.
关系路径中所有关系的向量表示构成了一个向量表示序列.模型利用多头注意力机制提取向量表示序列的特征信息,不同注意力头得到的结果拼接并点乘权重矩阵得到多头注意力的输出,再通过残差连接与 前馈神经网络进行处理,得到融合序列特征的新向量 表示,然后将问题的表示向量和关系路径中每个关系 的向量表示进行点积运算,生成全局注意力矩阵,聚合不同关系的语义特征,生成整个关系路径的向量表示.
通过Transformer网络提取关系路径特征,计算不同注意力头下的注意力概率分布,计算公式为
.
根据关系路径的向量表示序列生成整个关系路径的向量表示.先计算问题的向量表示与每个关系的权重系数,计算公式为
🍋3.4 模型训练
为了从候选关系路径中查找最优关系路径,本模型使用三元组损失函数[25],该函数使用锚点、正样本和负样本组成三元组,其中锚点和正样本类别相同,锚点
与负样本类别不同.通过训练使正样本与锚点在向量空间中的位置接近,使负样本与锚点的位置远离,最小化同类别样本之间的距离,并最大化不同类别样本之间的距离,其训练原理如图4所示.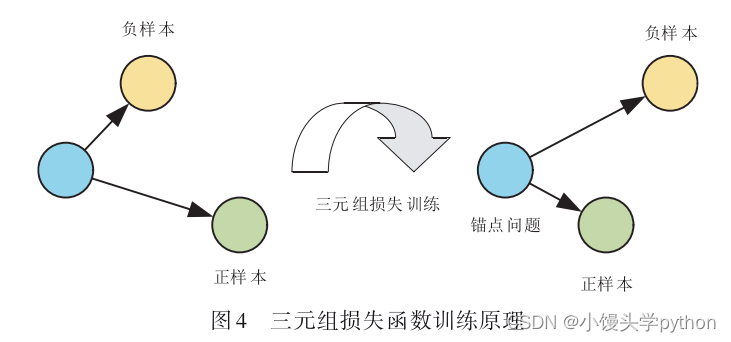

🍋4 实验评价
🍋4.1 实验环境


🍋4.2 实验结果
本文在Pytorch深度学习框架实现了KGRPN模型, 并采用Adam算法进行参数更新,操作系统为
…
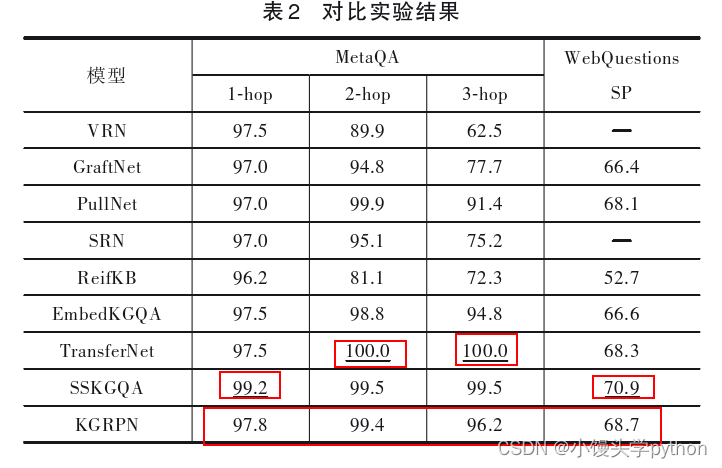
表2给出了本模型与对比模型在两个数据集上的 实验结果.根据该结果,可以看出本文提出的KGRPN模型在这些数据集上尽管性能不是最好,但表现最为稳健.在多跳情况下,EmbedKGQA模型通过分析问题和知识图谱每类关系的相关性计算关系路径的可信度,而KGRPN模型考虑了关系路径的顺序语义和复合 语义.在MetaQA的2-hop和3-hop数据集上,Trans⁃ ferNet模型的性能最好,但该模型每一跳都需要维护一个代表实体间转移概率的矩阵,通过大量矩阵运算模拟每跳的关系选择,以实现复杂的推理过程.与该模型 相比,KGPRN模型则通过特征向量匹配最符合问题语 义的关系路径,不需要复杂的矩阵运算.WebQues⁃ tionsSP数据集具有百万级的知识图谱实体,但包含非常少的问答记录,因此这些智能问答模型在该数据集
上的性能较低.在MetaQA的1-hop和WebQuestionsSP 数据集上,SSKGQA模型的性能最好,但该模型需要预先定义问题的语义结构,根据预测的问题语义结构在知识图谱中检索符合问题语义结构的查询图.与该模 型相比,KGPRN模型**不需要预先定义问题的语义结构,**而是以知识图谱中包含的关系和关系间的顺序语义信 息为基础,识别最符合问题语义的关系路径来生成问
题答案,具有更好的适用性.
🍋4.3 消融实验
先单独考察候选答案筛选模块性能,实验结果如表3所示,可以看出候选答案筛选模块能够生成高质量 的候选答案集合,在MetaQA数据集中几乎所有问题的 答案均被正确提取到候选答案集合中,在WebQues⁃ tionsSP数据集的实验中Hit@10值仍然能够达到78.8%.然而,如果简单地选择候选答案筛选模块生成的语义评分最高的实体作为答案,在MetaQA 2-hop数据集上 的Hit@1值只能达到86.0%,在WebQuestionsSP数据集 上的Hit@1值只能达到48.1%,与表2中完整模型的性能相比具有较大的差距.因此,如果不考虑关系路径包含的关系语义和关系间的顺序信息,模型的性能将显
著下降,证明了关系路径推理模块的重要性.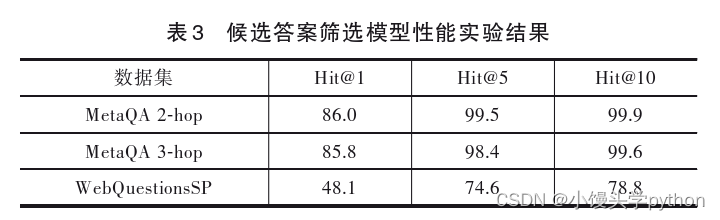
再考察关系路径表示学习模块中注意力机制对性能的影响,本文在Web QuestionsSP数据集上分析了不同向 量表示生成方法对性能的影响,实验结果如表4所示.根 据该实验结果,可知注意力机制的性能最好.相较于平均池化方法,注意力机制能够更好地捕捉向量表示序列的 全局语义,使问题和关系序列更关注彼此相关的部分,而采用最大池化策略会导致序列的语义不完整.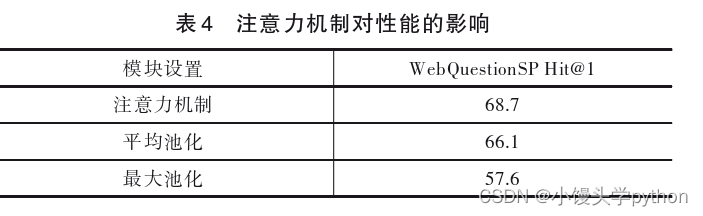
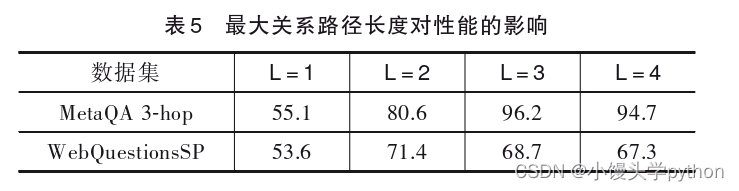
使用热力图对问题和关系路径之间的注意力分布进 行了可视化,每个热力图的单元格对应一个关系的注意力系数.图5给出了两个问题的注意力可视化示例,图5(a) 是Meta QA 3-hop数据集中的问题“who acted in the movies directed by the director of Zouzou”,该问题答案的关系路径 包括“directed_by”“directed_by_reverse”和“starred_actors” 三个关系,它们的注意力系数分别为0.38、0.28、0.34; 图5(a)是MetaQA 3-hop数据集中的问题“in which years were movies released which starred actors who appeared in the movie Thunderbolt”,该问题答案的关系路径包括 “starred_actors_reverse”“starred_actors”“release year”三个 关系,它们的注意力系数分别为0.37、0.26、0.37.在生成关系路径的特征向量时,每个关系对路径的整体语义贡献不同.最后考察关系路径的长度对性能的影响.最大关系路径长度L是影响关系路径检索范围的主要参数,本 文通过设置该参数来控制关系路径的抽取策略,以观
察抽取策略对性能的影响,实验结果如表5所示.根据 该实验结果,对于只包含三跳问题的MetaQA 3-hop数据集,当L=3时本模型的性能最高;对于只包含两跳问
题和单跳问题的WebQuestionsSP数据集,当L=2时模 型性能最高.因此,当最大关系路径长度等于数据集的最大问题跳数时,可以抽取完整的关系路径语义信息,问答性能最好;当最大关系路径长度小于数据集的最大问题跳数时,问答性能将会下降.
🍋 结论
针对复杂多跳问题在知识推理中难以提取关系路 径蕴含的结构信息和语义信息的问题,本文提出了基于知识图谱关系路径的多跳智能问答模型,通过表示 学习实现了知识图谱和自然语言问题的统一表示,将知识图谱和问题映射到同一向量空间中.从知识图谱 中抽取与问题相关的关系路径集合,并利用Trans⁃ former网络学习关系路径的语义和结构信息,在向量空间推理候选关系路径集合中最符合问题语义的关系路
径,生成候选答案.本方法可以应用于智能搜索、电子 商务和金融等领域,有效提高智能问答的精准度.
挑战与创造都是很痛苦的,但是很充实。

- 点赞
- 收藏
- 关注作者
评论(0)