2024-03-02:用go语言,一个句子是由一些单词与它们之间的单个空格组成, 且句子的开头和结尾没有多余空格, 比方说,“H

2024-03-02:用go语言,一个句子是由一些单词与它们之间的单个空格组成,
且句子的开头和结尾没有多余空格,
比方说,“Hello World” ,“HELLO” ,“hello world hello world” 都是句子,
每个单词都 只 包含大写和小写英文字母,
如果两个句子 sentence1 和 sentence2,
可以通过往其中一个句子插入一个任意的句子(可以是空句子)而得到另一个句子,
那么我们称这两个句子是 相似的。
比方说,sentence1 = “Hello my name is Jane” ,
且 sentence2 = “Hello Jane”。
我们可以往 sentence2 中 “Hello” 和 “Jane” 之间插入 “my name is”,
得到 sentence1。
给你两个句子 sentence1 和 sentence2,
如果 sentence1 和 sentence2 是相似的,请你返回 true ,否则返回 false。
输入:sentence1 = “My name is Haley”, sentence2 = “My Haley”。
输出:true。
答案2024-03-02:
来自左程云。
大体步骤如下:
1.将句子sentence1和sentence2以空格为分隔符拆分成单词列表w1和w2。
2.初始化变量i、j,分别表示句子开头相似部分的单词数量和句子结尾相似部分的单词数量。
3.循环比较w1和w2中的单词,直到遇到第一个不同的单词或其中一个句子的单词已经全部比较完毕。
4.循环结束后,得到i的值,表示句子开头相似部分的单词数量。
5.从句子结尾开始,循环比较w1和w2中的单词,直到遇到第一个不同的单词或其中一个句子的单词已经全部比较完毕。
6.循环结束后,得到j的值,表示句子结尾相似部分的单词数量。
7.返回i+j是否等于w1和w2中较小的单词数量,如果相等,则说明两个句子是相似的,返回true;否则返回false。
时间复杂度分析:
-
拆分句子的时间复杂度为O(n),其中n为句子中单词的个数。
-
比较单词的时间复杂度为O(k),其中k为句子中相同的单词数量。
-
总的时间复杂度为O(n + k)。
额外空间复杂度分析:
-
使用了两个字符串列表w1和w2来存储拆分后的单词,空间复杂度为O(n),其中n为句子中单词的个数。
-
使用了几个整数变量和常量,空间复杂度可以忽略不计。
-
总的额外空间复杂度为O(n)。
go完整代码如下:
package main
import (
"strings"
"fmt"
)
func areSentencesSimilar(sentence1 string, sentence2 string) bool {
w1 := strings.Split(sentence1, " ")
w2 := strings.Split(sentence2, " ")
i, j, n1, n2 := 0, 0, len(w1), len(w2)
for i < n1 && i < n2 && w1[i] == w2[i] {
i++
}
for n1-j > i && n2-j > i && w1[n1-1-j] == w2[n2-1-j] {
j++
}
return i+j == min(n1, n2)
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
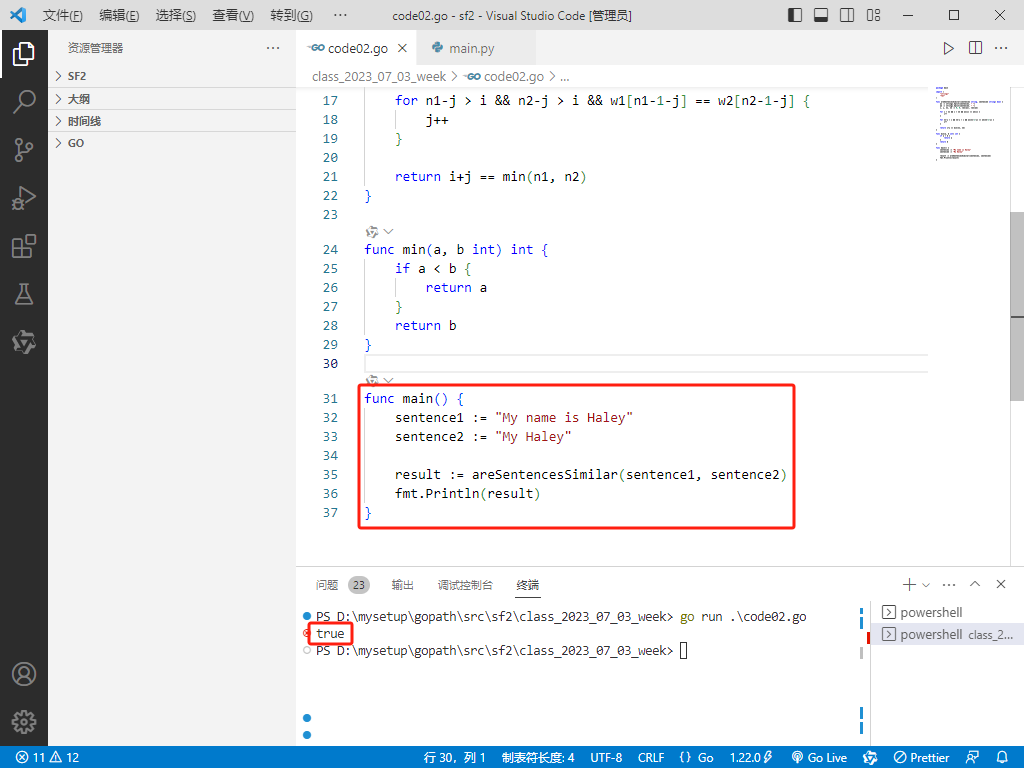
func main() {
sentence1 := "My name is Haley"
sentence2 := "My Haley"
result := areSentencesSimilar(sentence1, sentence2)
fmt.Println(result)
}
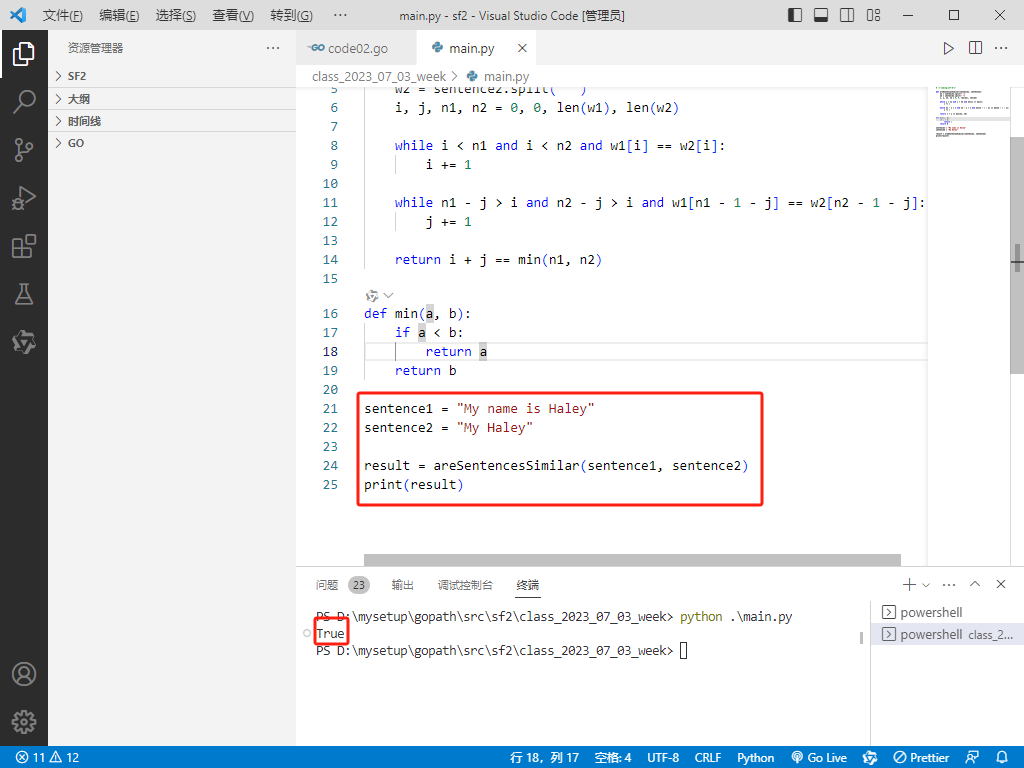
python完整代码如下:
# -*-coding:utf-8-*-
def areSentencesSimilar(sentence1, sentence2):
w1 = sentence1.split(" ")
w2 = sentence2.split(" ")
i, j, n1, n2 = 0, 0, len(w1), len(w2)
while i < n1 and i < n2 and w1[i] == w2[i]:
i += 1
while n1 - j > i and n2 - j > i and w1[n1 - 1 - j] == w2[n2 - 1 - j]:
j += 1
return i + j == min(n1, n2)
def min(a, b):
if a < b:
return a
return b
sentence1 = "My name is Haley"
sentence2 = "My Haley"
result = areSentencesSimilar(sentence1, sentence2)
print(result)

- 点赞
- 收藏
- 关注作者
评论(0)