【C++干货基地】揭秘C++11常用特性:内联函数 | 范围for | auto自动识别 | nullptr指针空值

哈喽各位铁汁们好啊,我是博主鸽芷咕《C++干货基地》是由我的襄阳家乡零食基地有感而发,不知道各位的城市有没有这种实惠又全面的零食基地呢?C++ 本身作为一门篇底层的一种语言,世面的免费课程大多都没有教明白。所以本篇专栏的内容全是干货让大家从底层了解C++,把更多的知识由抽象到简单通俗易懂。
文章目录
以往我们在C语言中实现比较简单的函数来说都是用宏来实现的,比如说实现一个加法,但是用宏实现的小型函数有很多缺点:
- 第一点就是宏经常容易写错,末尾的引号问题和运算符优先级问题等等
- 第二点就是宏他并没有类型安全检查就算是一个加法也有可能有人给你传俩个字符
- 第三点就是宏不方便调试,导致代码可读性差
所以在C++中就采用了内联函数和枚举来解决宏的使用的问题
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调
用建立栈帧的开销,内联函数提升程序运行的效率。
内联函数是以inline修饰的函数,在调用其该函数的时候会直接在调用处展开并不会开辟函数的栈帧空间所以非常适用在一下短小函数上面:
下面就给大家来看一下使用内联函数的效果:
🍸 代码一:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int Add(int x, int y)
{
int ret = x + y;
return ret;
}
int main()
{
int ret = Add(1,2);
return 0;
}
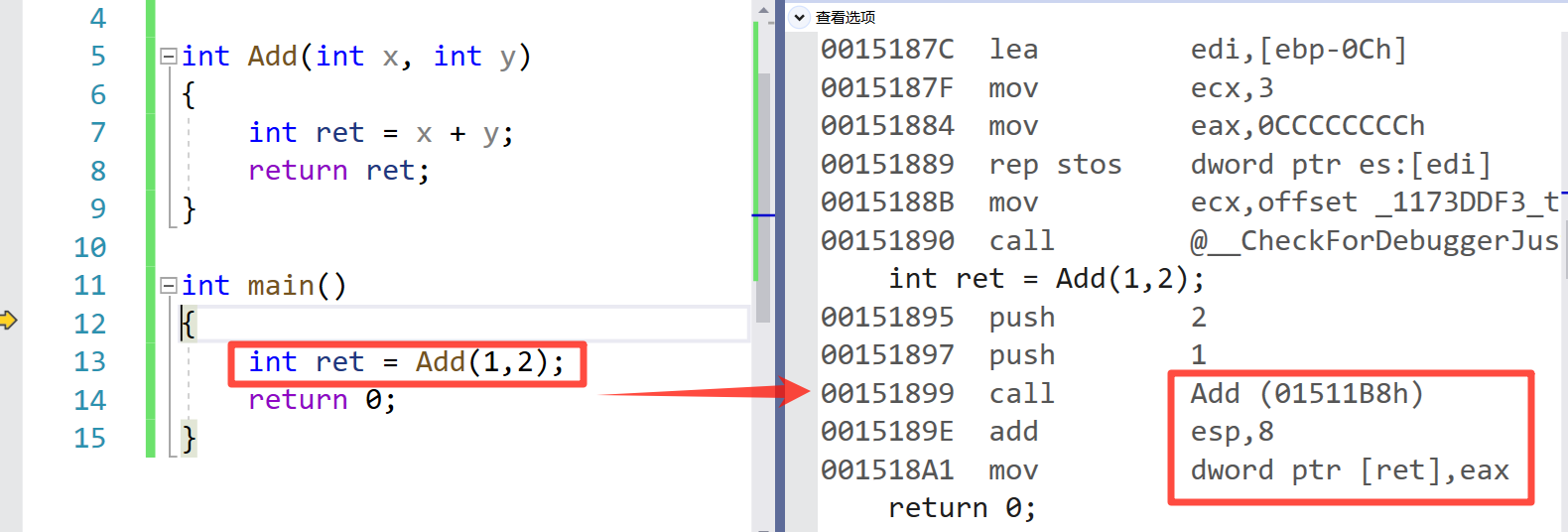
🍸 代码二:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
inline int Add(int x, int y)
{
int ret = x + y;
return ret;
}
int main()
{
int ret = Add(1,2);
return 0;
}
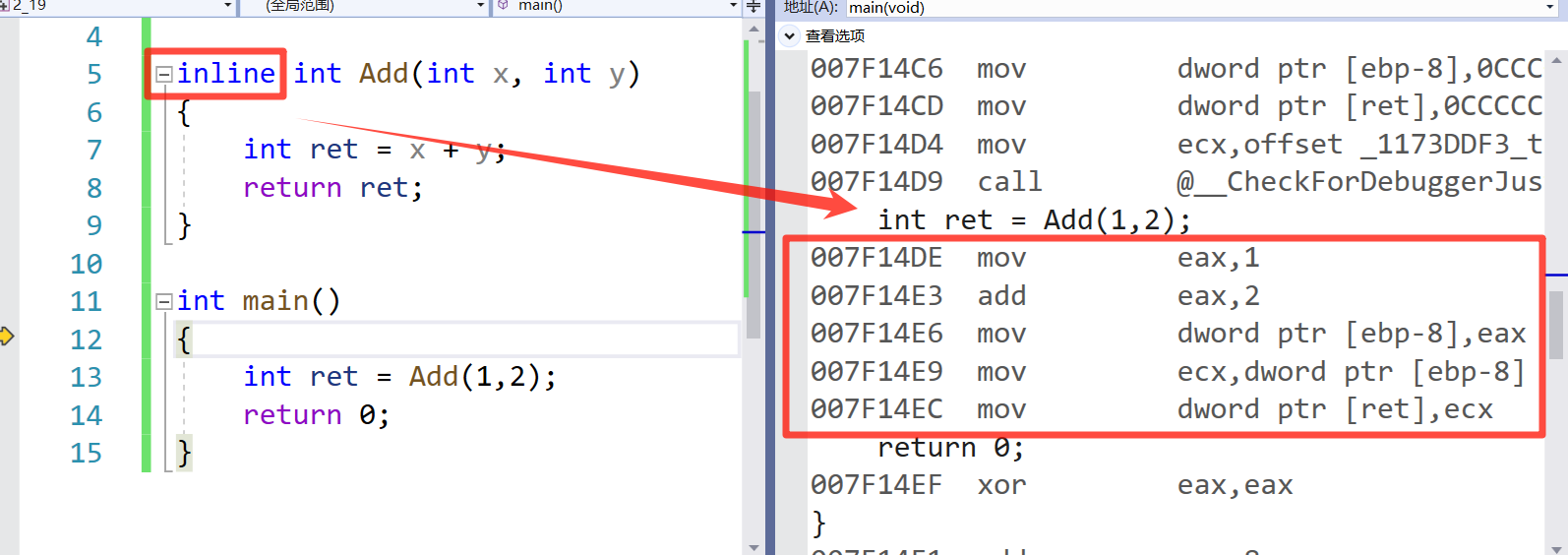
这里我们就可以看到只要函数我们加了 inline 关键字在调用的时候就直接展开不会开辟新的栈帧空间然后去 call 调用它。
内联函数看起来不用开辟函数的栈帧空间大大结束了效率但是每个短小的函数都适合使用内联函数吗?
- 其实函数在调用次数过多的情况下就不适合使用内联函数,这样就会导致代码膨胀到处都是重复的代码,从而使得可执行程序变大;
- 还有在函数的递归时也不能使用内联函数,函数栈帧是可以复用的,但内联函数一旦使用也会导致代码膨胀
🔥 注: inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建
议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不
是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。下图为
《C++prime》第五版关于inline的建议:
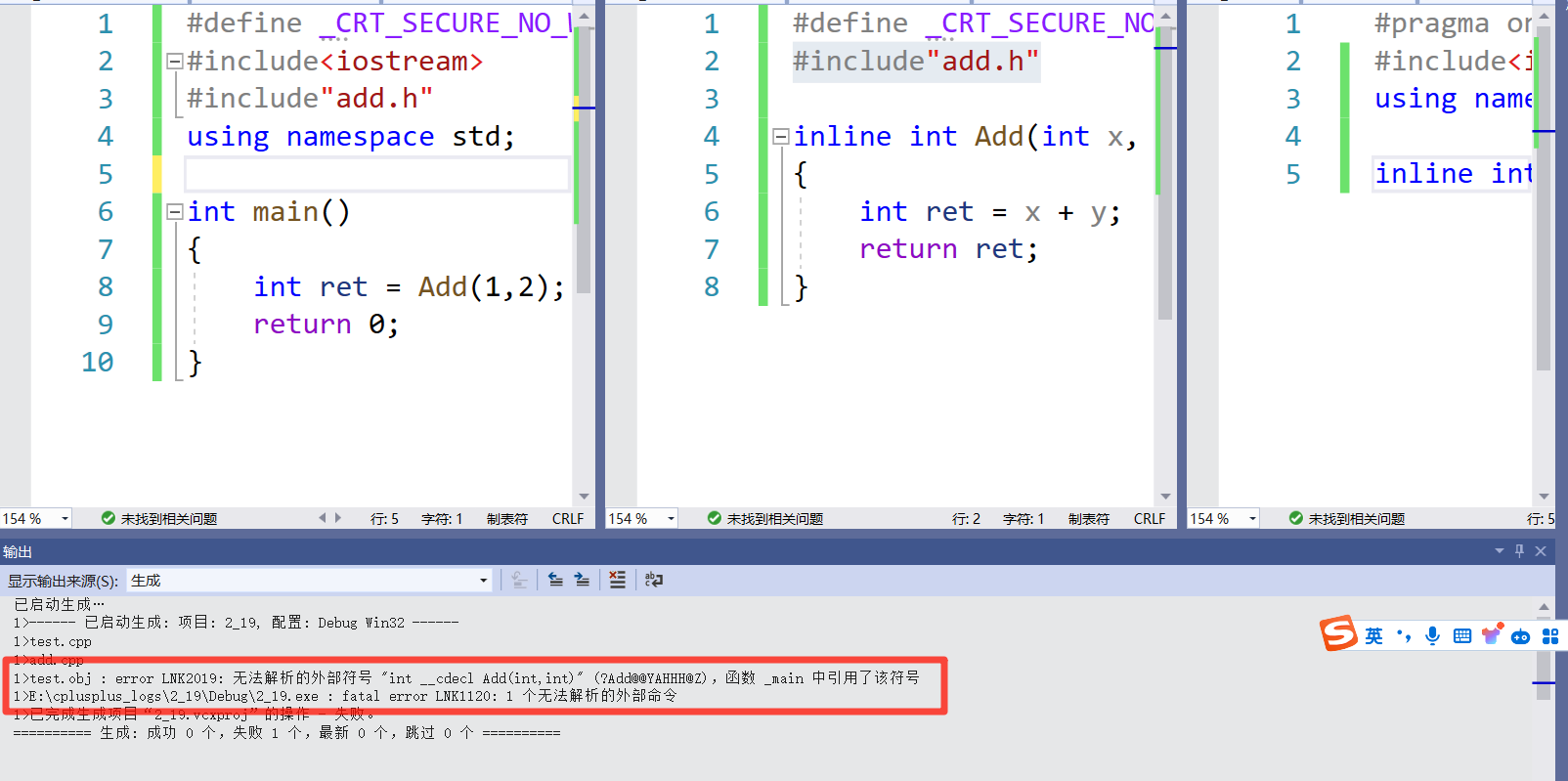
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址
了,链接就会找不到。
auto 关键字听听名字就非常简单,是C++11的时候,标准委员会赋予了auto全新的含义即可以自动推导变量类型使用起来也十分简单:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
int a = 10;
auto p1 = a;
auto* p2 = &a;
auto& p3 = a;
return 0;
}
这里auto后面加的 * 号就代表指针,&和以前一样是引用是我们指定自动类型。
🔥 注:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。
因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
auto 关键的意义其实并不是像我们前面那样去使用,是针对特别复杂的类型配合使用的比如:
🍸 场景一:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int fun(int x, int y)
{
int ret = x + y;
return ret;
}
int main()
{
int(*fp1)(int, int) = fun;
auto fp2 = fun;
return 0;
}
🍸 场景一:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{
std::map<std::string, std::string> dict;
std::map<std::string, std::string>::iterator it = dict.begin();
auto it = dict.begin();
return 0;
}
- auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
- auto不能直接用来声明数组
void TestAuto()
{
int a[] = {1,2,3};
auto b[] = {4,5,6};
}
在以前只要遍历数组我们就可能想到,使用for循环来遍历数组比如这样:
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)
cout << *p << endl;
}
但是使用这种方法遍历数组太麻烦了,而且还不好写比较繁琐所以在C++11 中新增加了范围 for 的概念
for循环后的括号由冒号“ :”分为两部分:
- 第一部分是范围内用于迭代的变量
- 第二部分则表示被迭代的范围。
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for(auto& e : array)
e *= 2;
for(auto e : array)
cout << e << " ";
}
在这里就巧妙的运用了我们上面讲的 auto 关键字来自动识别数组元素的类型:
- e 在这里是数组元素的临时拷贝所以我们如果想要改变数组元素
- 就得指定自动类型为引用,去用于改变数组元素
🔥 for循环迭代的范围必须是确定的
- 对于数组而言,就是数组中第一个元素和最后一个元素的范围;
- 对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
例如以下代码就是错误的:
- 这里我们并不明确因为for的范围不确定
void TestFor(int array[])
{
for(auto& e : array)
cout<< e <<endl;
}
一般我们定义变量好的习惯是每一个变量都初始化值但是 C++98 中 祖师爷在定义 NULL 指针空值的时候是这样定义的:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
这就导致了一个问题大家看一下下面这个代码结果你们猜是什么呢?
void f(int)
{
cout << "f(int)" << endl;
}
void f(int*)
{
cout << "f(int*)" << endl;
}
int main()
{
f(0);
f(NULL);
f((int*)NULL);
return 0;
}
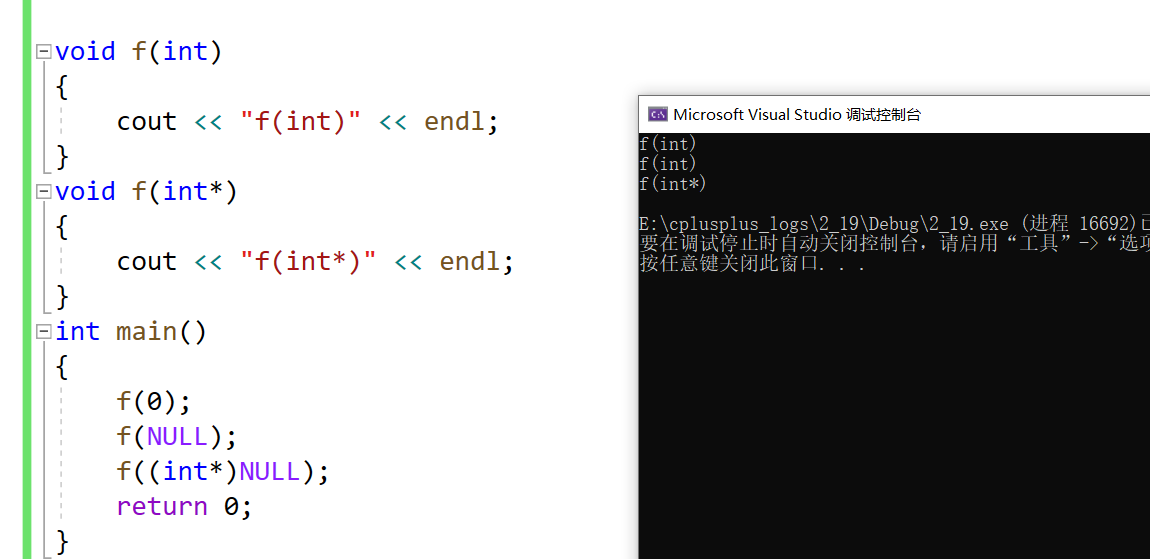
诶这里使用指针 NULL 定义空值的时候就出现问题了,所以在C++11中新增了一个关键字来填这个缺陷
nullptr 的由来就是因为祖师爷在一开始定义 NULL是使用宏定义这就导致
- NULL 被替换成 0 了,而不是((void *)0);
- 所以新增了一个关键字 nullptr == ((void *)0);
注意:
-
在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。
-
在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。
-
为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
📝文章结语:
☁️ 看到这里了还不给博主扣个:
⛳️ 点赞🍹收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
拜托拜托这个真的很重要!
你们的点赞就是博主更新最大的动力!


- 点赞
- 收藏
- 关注作者
评论(0)