【C++干货基地】C++引用与指针的区别:深入理解两者特性及选择正确应用场景

引入
哈喽各位铁汁们好啊,我是博主鸽芷咕《C++干货基地》是由我的襄阳家乡零食基地有感而发,不知道各位的城市有没有这种实惠又全面的零食基地呢?C++ 本身作为一门篇底层的一种语言,世面的免费课程大多都没有教明白。所以本篇专栏的内容全是干货让大家从底层了解C++,把更多的知识由抽象到简单通俗易懂。
文章目录
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空
间,它和它引用的变量共用同一块内存空间。
比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"。

所以,铁牛 和 黑旋风,都是 李逵
- 这俩就相当于李逵的别名
引用的概念其实有点相当于指针的平替,以往我们在使用指针等要
取地址 解引用太麻烦了,所以C++祖师爷在开发C++的时候就有了引用的概念,下面就来看看引用到底是个什么东西吧!
- 类型& 引用变量名(对象名) = 引用实体;
以上就是引用的语法了下面我们就来看一下实际是如何使用的
🍸 代码演示:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
int a = 10;
//给a取别名
int& b = a;
b = 20;
cout << b << endl;
return 0;
}
📑代码结果: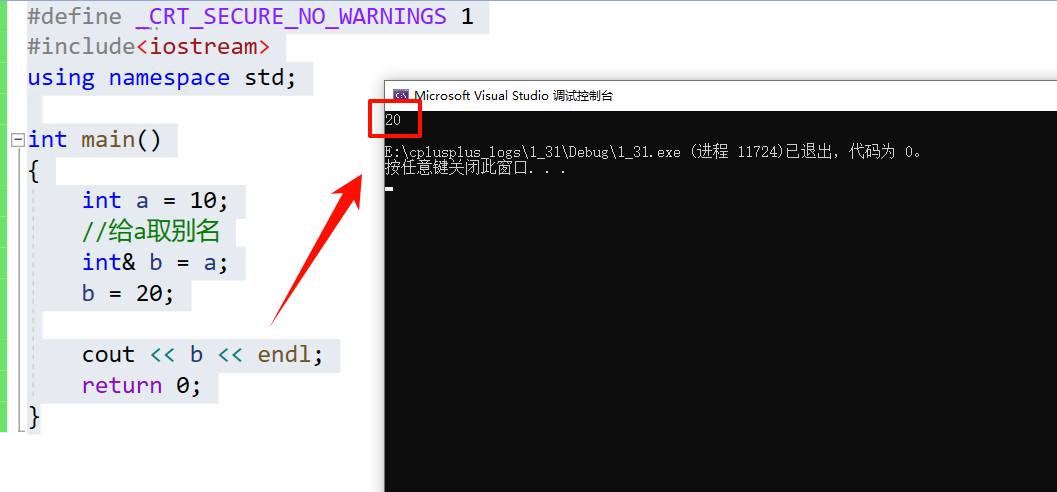
这时就有很多人说了这引用不就相当于指针吗?对的引用和指针的作用其实是差不多的,对变量引用的修改会影响变量,而指针也是对指针的修改会影响指针所指向的内容:
- 但是引用在使用上和一些场景比指针更简便更容易理解
🍸 代码演示:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
void fun(int* x)
{
*x = 20;
}
void fun1(int& y)
{
y = 30;
}
int main()
{
int a = 10;
//使用指针做形参
fun(&a);
cout << a << endl;
//使用引用做形参
fun1(a);
cout << a << endl;
return 0;
}
哦豁,这里我们就可以看到引用的奇妙之处了。以往我们用指针做参数的时候老是忘记去地址传参,而引用本身就是变量的别名所以,在当形参的时候我们只需要传变量就好了
- 而在修改变量值的时候指针还要解引用才能修改
- 而引用却可以直接修改
现在看来引用和指针对比,简直就是一个还在使用老年机一个却已经使用智能手机全自动了,别急引用的好处还在后面呢大家慢慢看完,我们在以后的项目里面可以说%80的地方都不需要指针而用引用了。
以往我们在指针定义时候老是忘记初始化而到处野指针的情况频频发生,所以祖师爷在定义引用的时候规定了引用必须初始化
🍸 代码演示:
int main()
{
int a = 10;
int& b = a;
int& c;
return 0;
}
📑代码结果:
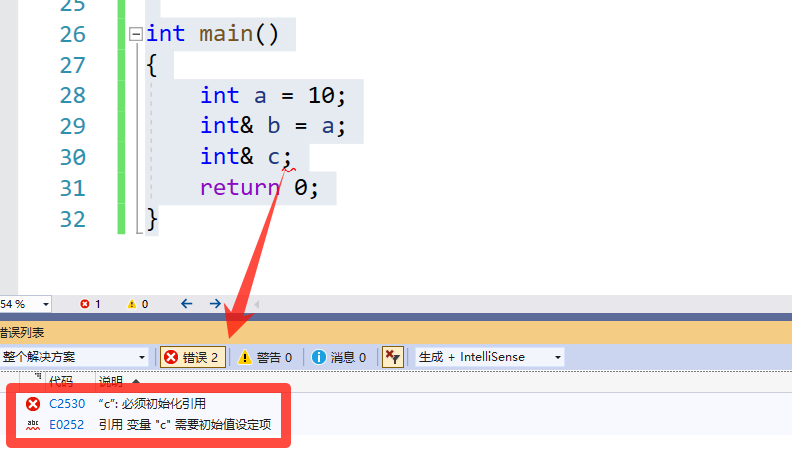
指针我们都知道是可以更改指向的,但是引用祖师爷规定了引用不能更改指向。因为C++是兼容 C语言祖师爷可能认为更改指向的事情交给 指针 做就可以了,没必要去让引用去更改指向;
🍸 代码演示:
int main()
{
int a = 10;
int x = 30;
int& b = a;
cout << b << endl;
b = x;//不是改变指向而是赋值
cout << b << endl;
cout << a << endl;
return 0;
}
📑代码结果: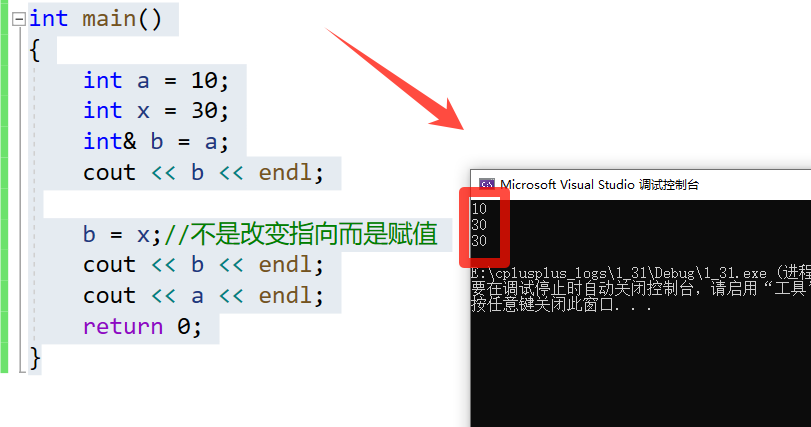
🍸 代码演示:
int main()
{
int a = 10;
int& b = a;
b = 20;
cout << a << endl;
//给别名起别名
int& c = b;
c = 30;
cout << a << endl;
return 0;
}
📑代码结果: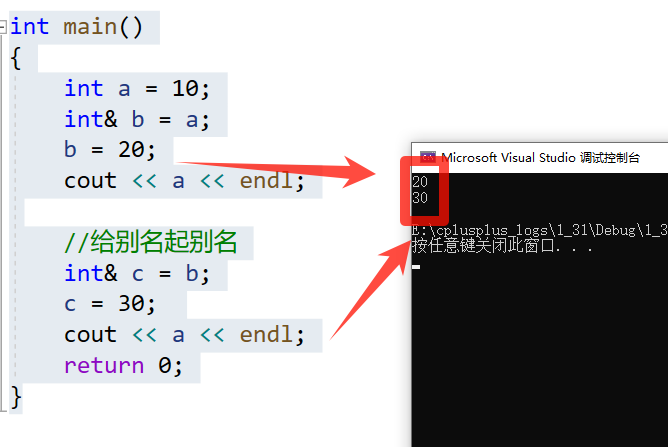
这里为什么会有常引用的概念呢?引用和指针一样都会去改变所指向的变量从而造成失误。而这时使用常引用就不会了
🍸 代码演示:
void fun(const int& x)
{
x = 30;
}
int main()
{
int a = 10;
fun(a);
return 0;
}
📑代码结果: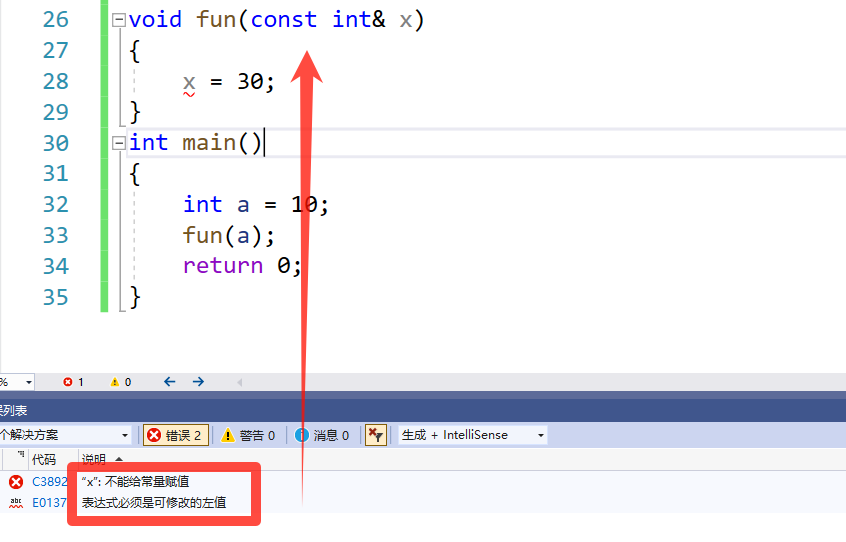
- 权限的缩小
🍸 代码演示:
int main()
{
int a = 10;
//权限的缩小
const int& b = a;
b = 30;
return 0;
}
📑代码结果:
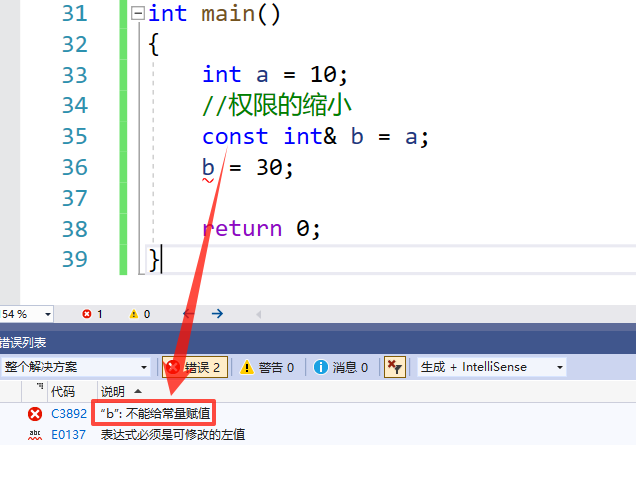
这里我们就把变量 a 的别名 b 的权限缩小了,从可读可写变成了可读,所以我们就不能就行修改了
- 权限的平移
🍸 代码演示:
int main()
{
const int a = 8;
//权限的平移
const int& c = a;
const int& b = 10;
return 0;
}
平移很简单就是相同权限的变量我们就给他相同权限的别名才能使用
- 权限的放大
在我们变成中其实权限是不能放大的,一个常量如果强行把它提升成变量是非常不安全
- 所以权限是不能放大的
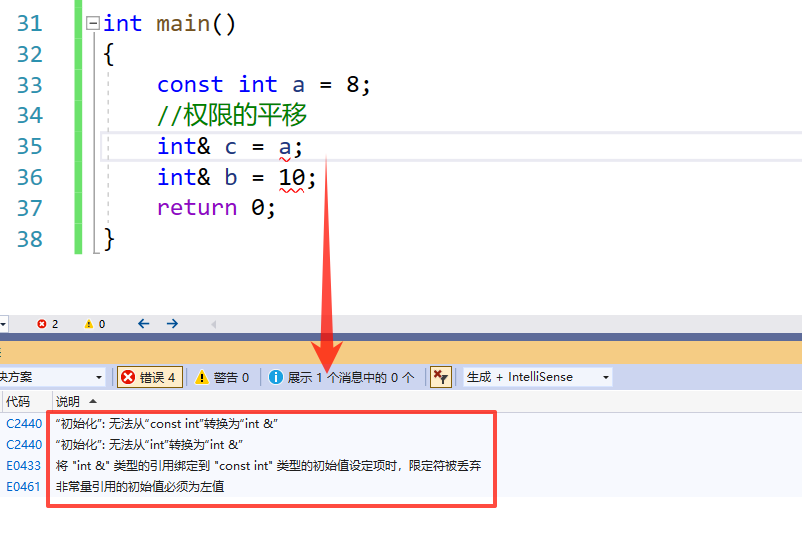
这里给大家看一个代码,这里为什么int 类型可也转换为double double 却转换不了为int 引用?
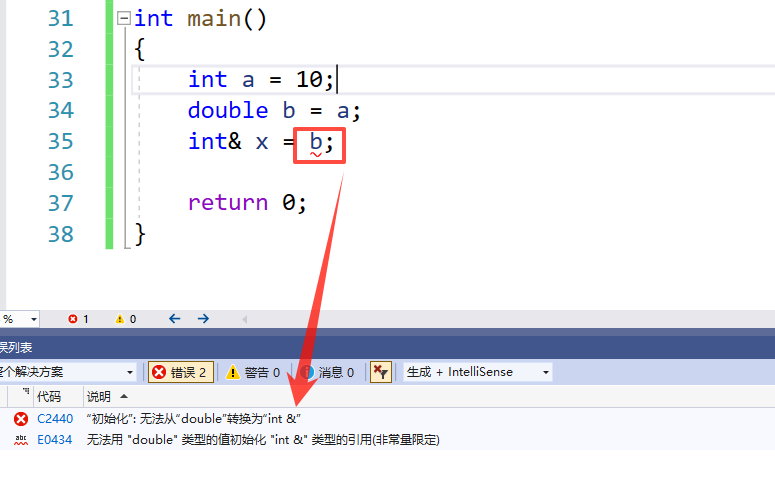
这是因为 当我们进行赋值,或者进行隐式类型转换的时候,这里会产生一个临时变量,而临时变量具有常性
- 是不可进行,改变和隐式类型转换的

- 这是我们对其 临时变量的常性,进行权限的平移就会进行报错了
int main()
{
int a = 10;
double b = a;
const int& x = b;
return 0;
}
那么为什么会产生临时变量?下面看一下这段代码,这里我们进行判断比较时是不会进行提升?
- 那么这里是对变量本身进行提升吗?
int main()
{
int a = 97;
char b = 'a';
if (a == b)
{
cout << "a == b" << endl;
}
}
这里是对临时变量进行对比然后提升进行对比的
- 权限放大案例


int main()
{
int a = 10;
int b = 20;
//权限的放大,a+b的结果是一个临时变量。临时变量具有常性
//int& b = a + b;
const int& b = a + b;
return 0;
}
看到这里其实大家,都知道指针和引用的功能大致相同
- 但是 C++ 的引用是为了替换掉一下指针复杂场景的替换使代码,使代码更加简介但是引用不能代替指针
- 他们更多的是相辅相成
引用的更多使用场景就是传参来用的,以往我们在使用指针更改指针指向的变量,或者二级指针使用起来太不方便了,但是使用引用就非常简单:
void swap(int& x, int& y)
{
int tmp = x;
x = y;
y = tmp;
}
int main()
{
int a = 10;
int b = 20;
swap(a, b);
cout << a << endl;
cout << b << endl;
return 0;
}
以往我们在进行交换函数的使用每次都需要,取地址进行传参,而有了引用的概念用起来就方便多了
📑 错误示范:
int& fun()
{
int a = 10;
return a;
}
int& fx()
{
int b = 20;
return b;
}
int main()
{
int& a = fun();
cout << a << endl;
fx();
cout << a << endl;
return 0;
}
这里我们就错误的使用引用做返回值的,我们吧函数 fun 里面本来要销毁的变量给使用别名返回了。但是这个快空间本来是要还给操作系统的:
- 这样我们就造成了内存泄漏
- 当我们在进行调用函数时会对上一个销毁的函数空间进行复用,所以就把原来的空间a给改变了
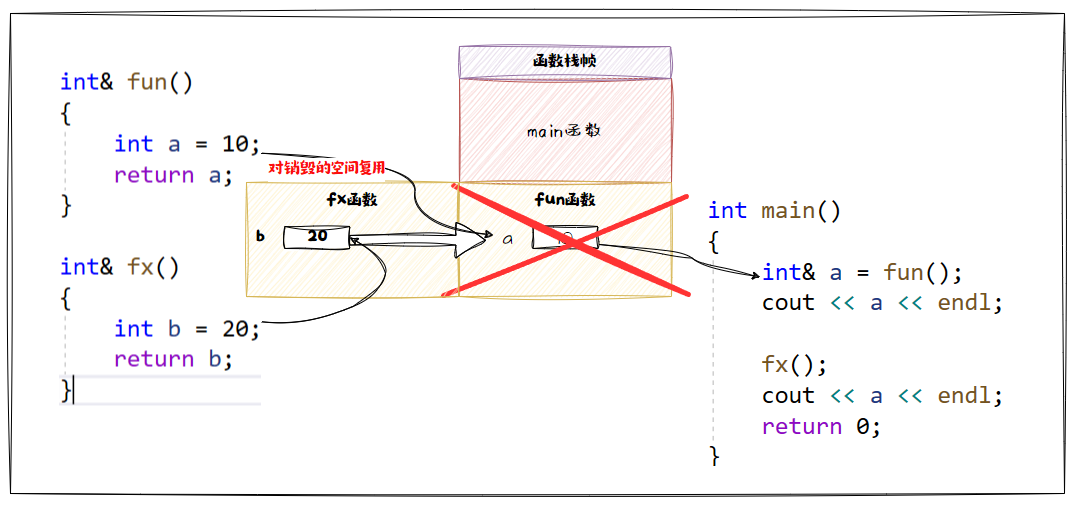
🔥 所以使用引用做返回值的时候一定是对在堆上开辟,或者动态开辟的空间不会随着函数销毁而销毁的空间才可以用引用做返回值
- 如果不是动态开辟的空间或者再堆上开辟的空间,会随着函数的销毁而销毁就一定要用传值传参
这里在顺序表里面如果把 Get 获取函数指定位置的值进行传引用返回的话就可以把修改循序表的的 Modity 给干掉了
- 一个函数既可以获取值又可以修改值
struct SeqList
{
int* a;
int size;
int capacity;
//成员函数
void Init(SeqList& sl)
{
int* tmp = (int*)malloc(sizeof(int) * 4);
if (tmp == NULL)
{
perror("malloc file");
exit(-1);
}
sl.a = tmp;
sl.size = 0;
sl.capacity = 4;
}
void PushBack(SeqList& sl,int x)
{
//...
sl.a[size++] = x;
}
int& Get(SeqList& sl, int pos)
{
return sl.a[pos];
}
};
int main()
{
SeqList s;
s.Init(s);
s.PushBack(s, 1);
s.PushBack(s, 2);
s.PushBack(s, 3);
s.PushBack(s, 4);
for (int i = 0; i < s.size; i++)
{
cout << s.Get(s, i) << " ";
}
cout << endl;
for (int i = 0; i < s.size; i++)
{
s.Get(s, i) *= 2;
cout << s.Get(s, i) << " ";
}
cout << endl;
cout << endl;
return 0;
}
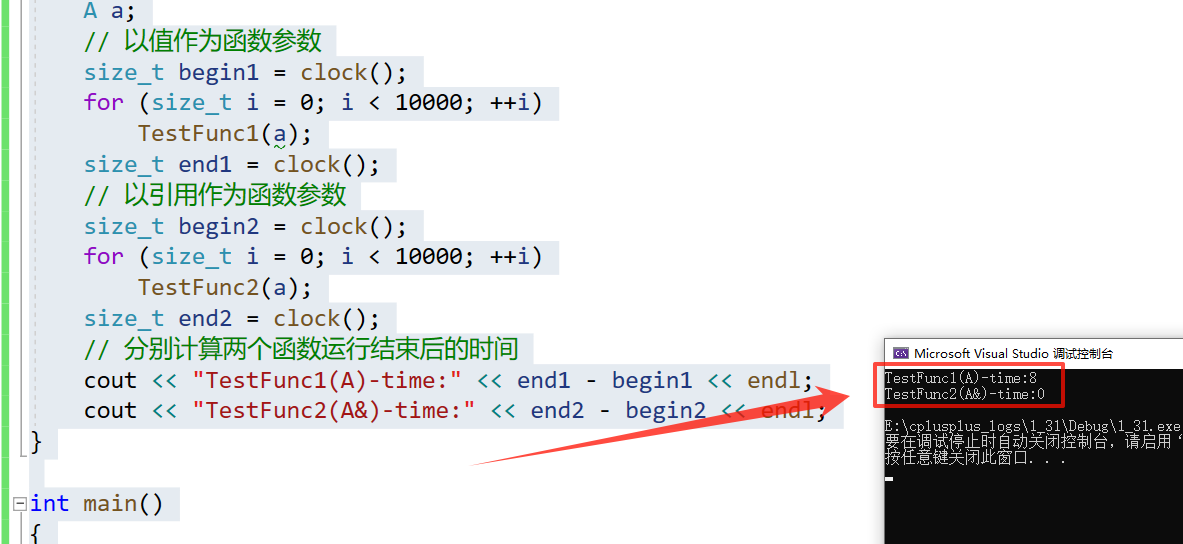
函数在进行传值做形参的话,形参是实参的一份临时拷贝。所以对系统的空间是有一定消耗的,当我们调用函数次数多的话就在效率上就会有一定影响,从而降低效率:
- 下面我们就来测试一下传值调用和传引用调用的效率吧!
#include <time.h>
struct A { int a[10000]; };
void TestFunc1(A a) {}
void TestFunc2(A& a) {}
void TestRefAndValue()
{
A a;
// 以值作为函数参数
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc1(a);
size_t end1 = clock();
// 以引用作为函数参数
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i)
TestFunc2(a);
size_t end2 = clock();
// 分别计算两个函数运行结束后的时间
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
return 0;
}
🔥 在这里我们调用一万次他们的差别分别是 8毫秒多 和 0毫秒
🍸 代码演示:
int main()
{
int a = 10;
int& b = a;
int* c = &a;
cout << "引用大小:" << sizeof(a) << endl;
cout << "指针大小:" << sizeof(c) << endl;
cout << "int大小:" << sizeof(int) << endl;
cout << "longlong大小:" << sizeof(long long) << endl;
cout << "引用大小:" << sizeof(long long&) << endl;
cout << "指针大小:" << sizeof(long long*) << endl;
return 0;
}
📑代码结果:
🔥 在sizeof中:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
这边我们定义一个指针和引用,然后我们把它转成汇编代码会发现他们来生成的汇编代码是一样的
- 🔥 所以在底层,引用和指针都是一回事,引用是按照指针方式来实现的。
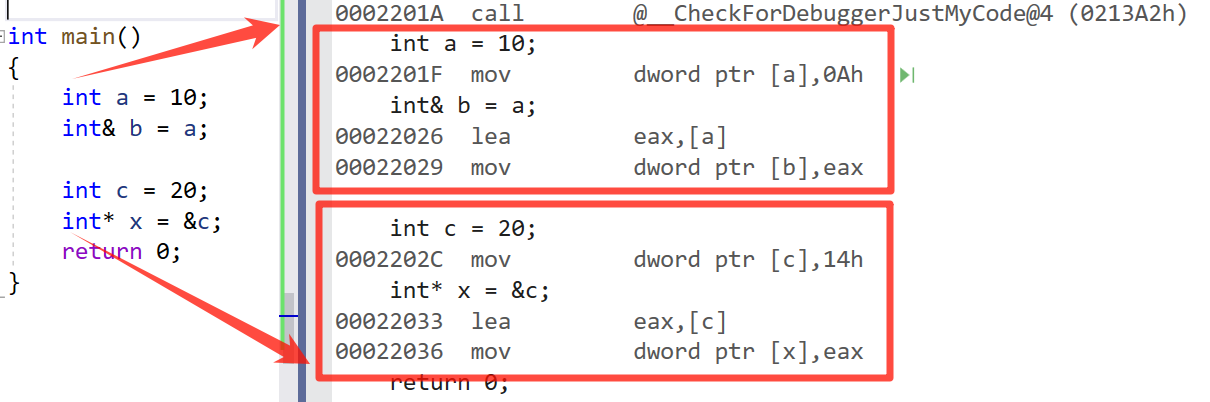
引用和指针的底层对比
-
在语法上引用是给一个变量起别名,不开空间。指针是把一个变量的地址存起来。
-
引用必须初始化才能使用,指针可以初始化也可以不初始化
-
引用不可以改变指向,但指针可以改变指向
-
在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32
位平台下占4个字节) -
引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
-
有多级指针,但是没有多级引用
-
访问实体方式不同,指针需要显式解引用,引用编译器自己处理
-
引用比指针使用起来相对更安全
底层上:
🔥 在底层上引用是开辟空间的,因为引用是用指针实现的
☁️ 看到这里了还不给博主扣个:
⛳️ 点赞🍹收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
拜托拜托这个真的很重要!
你们的点赞就是博主更新最大的动力!


- 点赞
- 收藏
- 关注作者
评论(0)