【愚公系列】软考中级-软件设计师 022-数据结构(排序算法)

🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2023年华为云十佳博主,2022年CSDN博客之星TOP2,2022年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
常见的排序算法有以下几种:
-
冒泡排序(Bubble Sort):依次比较相邻的两个元素,将较大的元素交换到后面,每一轮比较都将最大的元素放到最后。时间复杂度为O(n^2)。
-
选择排序(Selection Sort):每次从待排序的元素中选取最小的元素,放置在已排序的末尾。时间复杂度为O(n^2)。
-
插入排序(Insertion Sort):将待排序的元素插入到已排序的序列中的适当位置,使得插入后仍然有序。时间复杂度平均为O(n^2),最好情况下为O(n),最坏情况下为O(n^2)。
-
希尔排序(Shell Sort):是插入排序的一种改进,通过将序列分组,每次对分组进行插入排序,然后逐步缩小分组的规模,最终完成排序。时间复杂度为O(nlogn)。
-
归并排序(Merge Sort):将序列不断地分割成两半,对每一半进行排序,然后合并两个已排序的子序列,最终完成排序。时间复杂度为O(nlogn)。
-
快速排序(Quick Sort):通过一趟排序将序列分成独立的两部分,其中一部分所有元素都比另一部分小,然后再对这两部分递归地进行快速排序。时间复杂度平均为O(nlogn),最坏情况下为O(n^2)。
-
堆排序(Heap Sort):将待排序的序列构建成一个大顶堆,然后将堆顶元素与最后一个元素交换,再对剩余的n-1个元素进行调整,循环执行以上步骤,最终完成排序。时间复杂度为O(nlogn)。
-
计数排序(Counting Sort):统计待排序序列中每个元素的出现次数,然后根据元素的值从小到大依次输出。时间复杂度为O(n+k),其中k表示序列中元素的范围。
-
桶排序(Bucket Sort):将待排序的元素映射到一个有限数量的桶中,每个桶再分别进行排序,最后将所有桶中的元素按次序合并成有序序列。时间复杂度为O(n+k),其中k表示桶的数量。
-
基数排序(Radix Sort):将待排序的元素从低位到高位依次进行排序,每一位都使用一种稳定的排序算法(如计数排序或桶排序)。时间复杂度为O(d(n+k)),其中d表示元素的最大位数,k表示每一位的可能取值范围。
🚀一、排序算法
🔎1.术语说明
| 术语 | 说明 |
|---|---|
| 数据元素 | 要排序的数据的基本单位,可以是数字、字符、对象等 |
| 关键字 | 数据元素中用于排序的属性或值,可以是元素本身或元素的某个特定属性 |
| 升序 | 按照关键字的大小从小到大进行排序 |
| 降序 | 按照关键字的大小从大到小进行排序 |
| 稳定性 | 如果两个关键字相等的元素在排序后的序列中的相对位置保持不变,排序算法是稳定的;否则,排序算法是不稳定的 |
| 内部排序 | 排序过程中所有数据都能够全部加载到内存中进行排序 |
| 外部排序 | 排序过程中数据量太大,无法一次性加载到内存中,需要借助外部存储设备进行排序 |
| 比较排序 | 排序算法通过比较关键字的大小进行排序 |
| 非比较排序 | 排序算法不直接通过比较关键字的大小进行排序,而是利用元素的其他特性进行排序,如计数排序、桶排序和基数排序 |
| 原地排序 | 排序过程中只使用了常数级别的额外空间 |
| 时间复杂度 | 描述算法的耗时程度,即算法执行所需的时间 |
| 空间复杂度 | 描述算法所需的额外空间 |
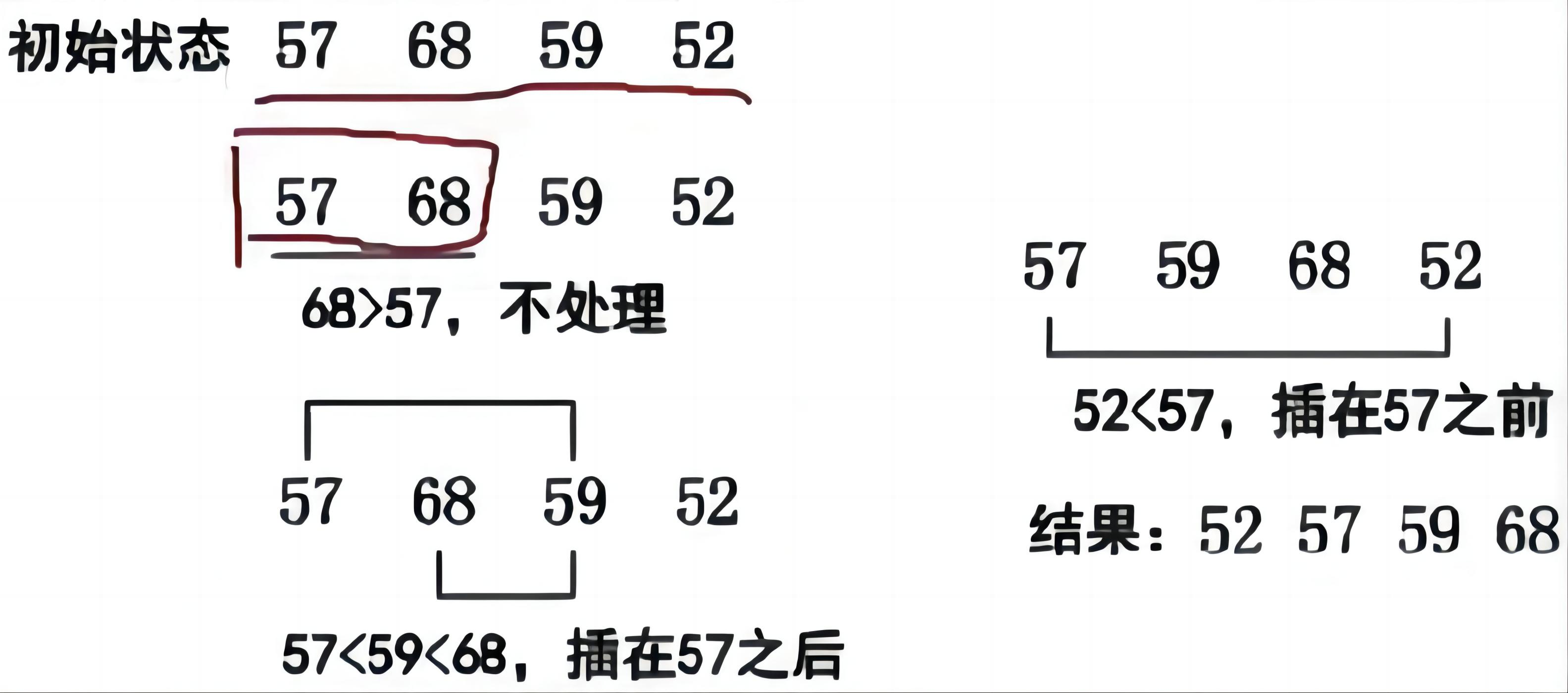
🔎2.插入排序
直接插入排序是一种简单直观的排序算法,它的思想是将一个序列分为有序和无序两部分,每次从无序部分中取出一个元素,插入到有序部分的正确位置上,直到整个序列有序为止。
具体步骤如下:
- 将序列分为有序和无序两部分,初始时有序部分只有一个元素(即序列的第一个元素),无序部分包括剩余的元素。
- 从无序部分中取出一个元素,记为待插入元素。
- 将待插入元素与有序部分的元素进行比较,找到待插入元素在有序部分的正确位置。
- 将有序部分中大于待插入元素的元素后移一位,腾出位置给待插入元素。
- 将待插入元素放入正确位置。
- 重复步骤2到步骤5,直到无序部分为空。
时间复杂度:
- 最好情况下,当序列已经有序时,直接插入排序的时间复杂度为O(n),因为只需遍历一次序列。
- 最坏情况下,当序列逆序时,直接插入排序的时间复杂度为O(n^2),因为要进行n次插入操作,每次插入操作的时间复杂度为O(n)。
- 平均情况下,直接插入排序的时间复杂度也为O(n^2)。
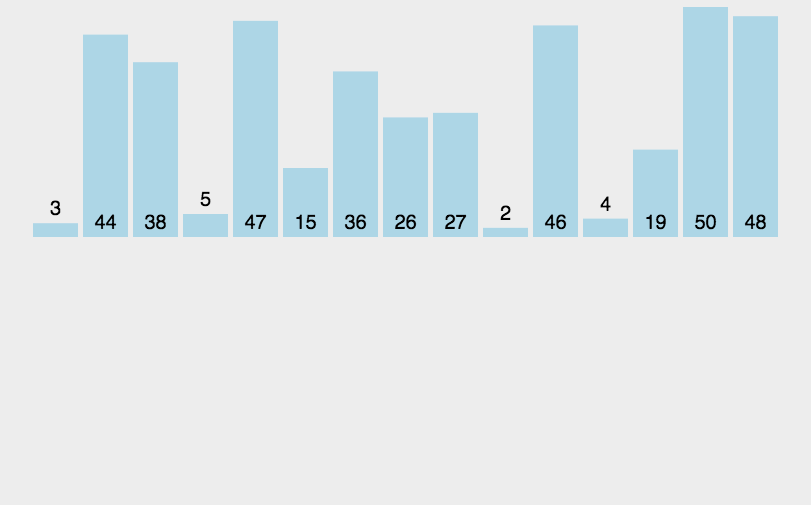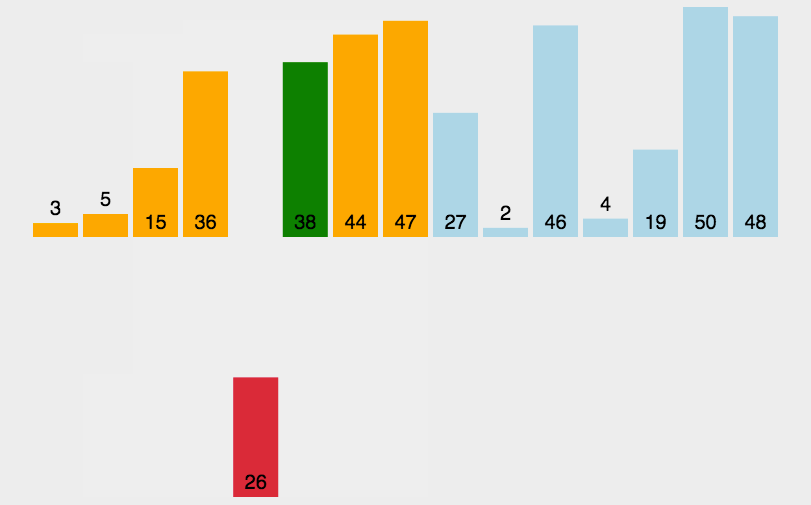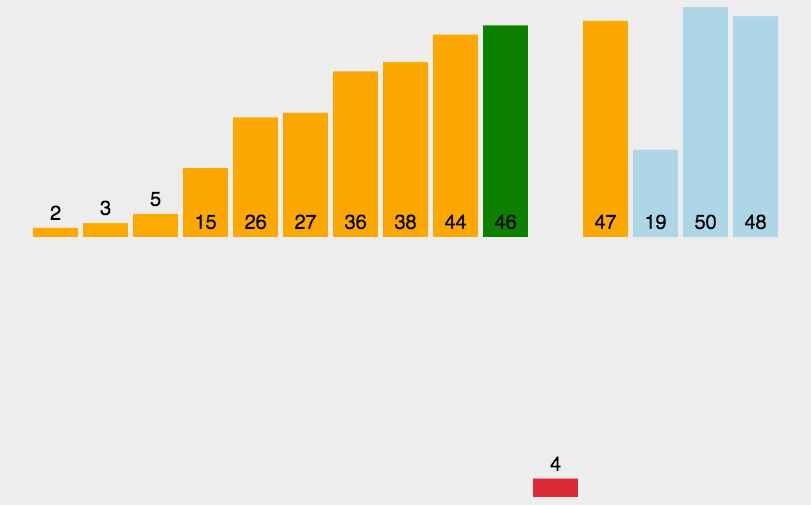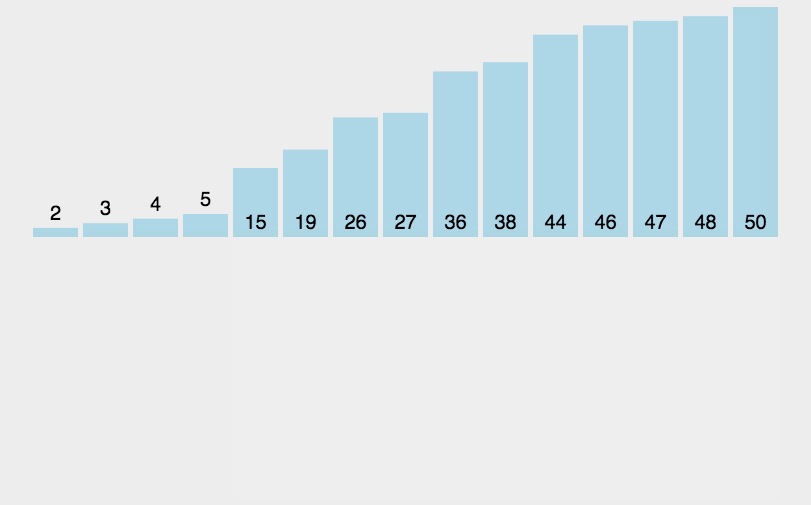
🔎3.希尔排序
希尔排序是一种基于插入排序的排序算法,也称为缩小增量排序。它通过逐步减小增量的方式分组并对元素进行比较和交换,最终实现整体的有序。
希尔排序的算法步骤如下:
- 选择一个增量序列,常用的是希尔增量序列,即初始增量gap为数组长度的一半,然后每次将gap缩小一半,直到gap为1。
- 对每个增量间隔进行插入排序。从第gap个元素开始,将其与之前的元素进行比较,如果前面的元素更大,则将其向后移动gap个位置。重复这个过程直到无法向前移动为止。
- 缩小增量,重新进行插入排序,直到最后一次增量为1,即进行最后一次插入排序,此时整个数组已经是有序的了。
希尔排序的时间复杂度取决于选取的增量序列,最好的情况下可以达到O(nlogn),最坏的情况下为O(n^2)。

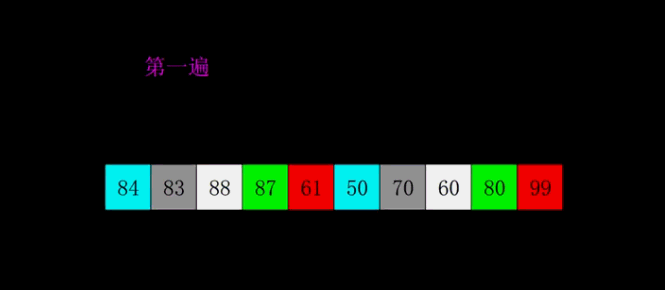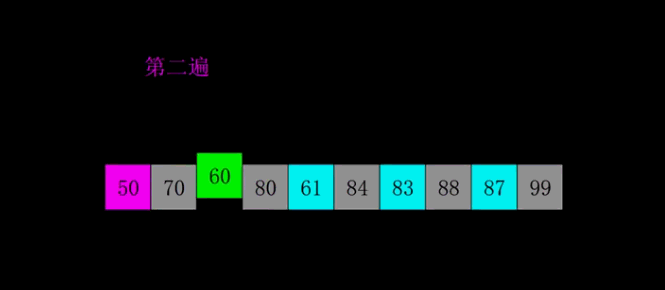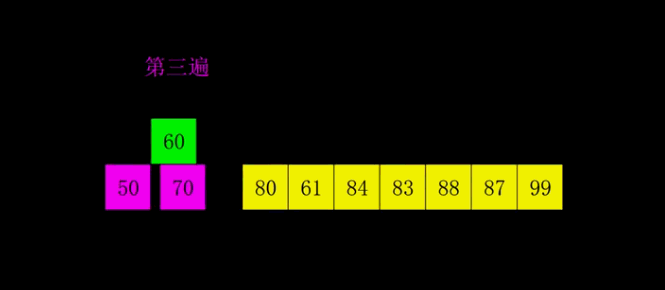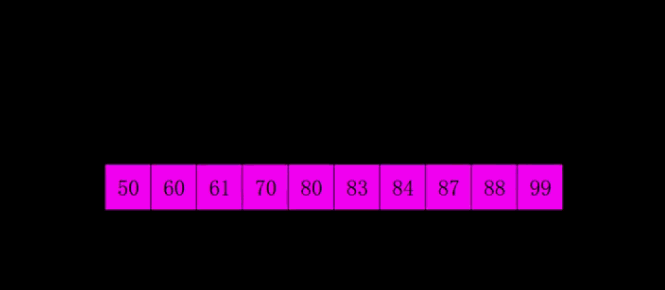
🔎4.简单选择顺序
简单选择排序是一种简单直观的排序算法,它的基本思想是每次从待排序的数据中选择最小(或最大)的元素,然后放到已排序序列的末尾,直至所有元素排序完毕。
具体的排序过程如下:
- 从待排序序列中,找到关键字最小的元素。
- 如果最小元素不是待排序序列的第一个元素,将其和第一个元素互换位置。
- 从剩余的待排序序列中,继续找到关键字最小的元素,重复步骤2。
- 重复步骤2和步骤3,直到待排序序列中只剩下一个元素。
简单选择排序的时间复杂度为O(n^2),其中n为待排序序列的长度。虽然简单选择排序的时间复杂度较高,但对于小规模的数据排序还是比较高效的。

🔎5.堆排序
堆排序是一种基于二叉堆数据结构的排序算法。它的时间复杂度为O(nlogn),空间复杂度为O(1)。
堆排序的具体步骤如下:
-
将待排序序列构建成一个大顶堆(或小顶堆),从最后一个非叶子节点开始,自下而上地进行堆调整。
-
交换堆顶元素(最大值或最小值)和堆中最后一个元素。
-
从根节点开始,自上而下地进行堆调整,保持堆的性质。
-
重复步骤2和步骤3,直到堆中只剩下一个元素。
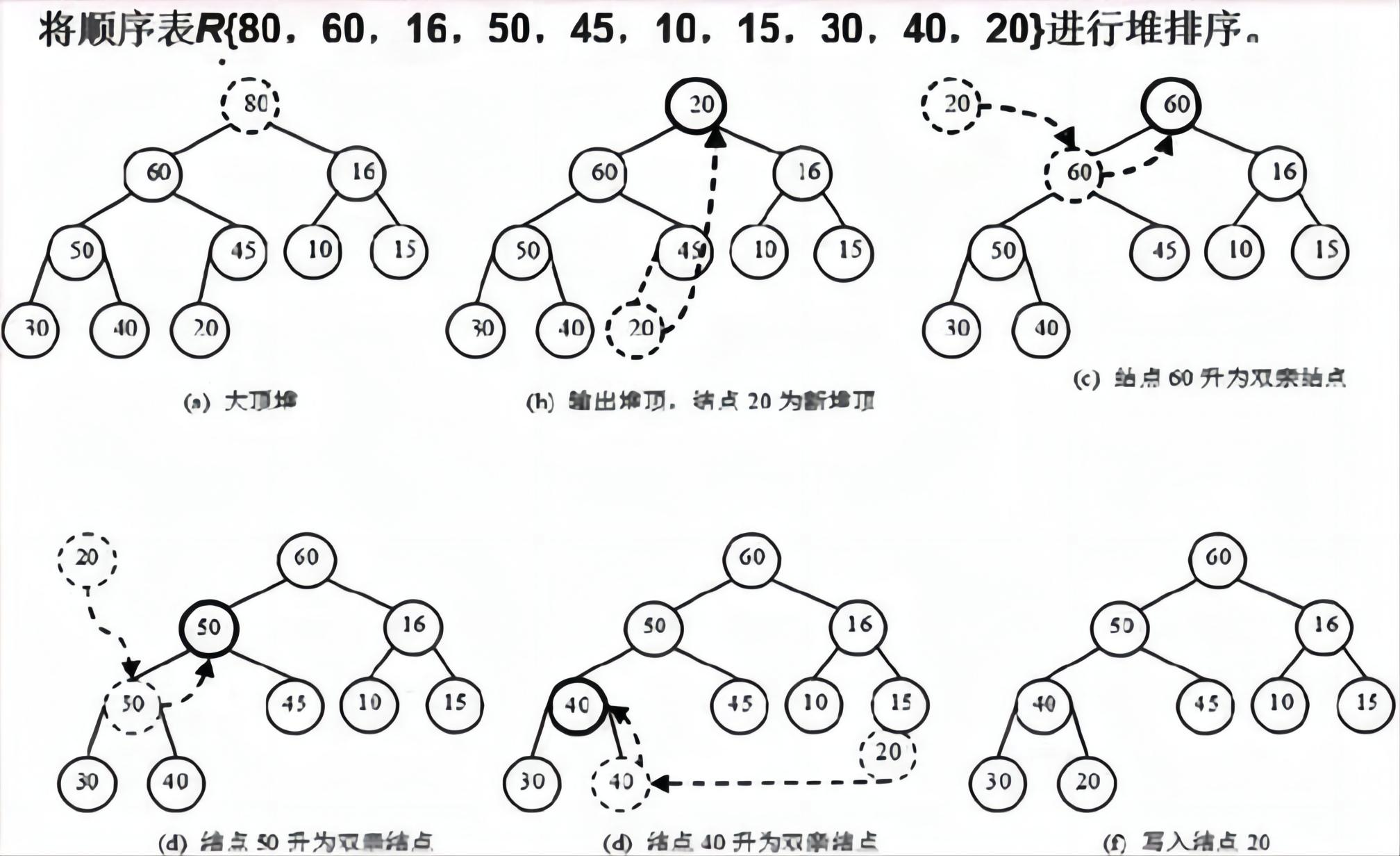

堆排序适用于在多个元素中找出前几名的方案设计,因为堆排序是选择排序,而且选择出前几名的效率很高。
🔎6.冒泡排序
冒泡排序是一种简单直观的排序算法。它重复地遍历要排序的列表,通过比较相邻元素并交换它们,将列表中的最大元素逐渐“冒泡”到列表的末尾。在每一次遍历中,比较相邻的两个元素,如果它们的顺序不正确,则交换它们的位置。重复这个过程,直到整个列表排序完成。
具体算法步骤如下:
- 比较相邻的两个元素,如果它们的顺序不正确,则交换它们的位置。
- 对每一对相邻的元素重复步骤1,直到最后一对元素。
- 重复步骤1和步骤2,直到没有需要交换的元素,即列表已经有序。
冒泡排序的时间复杂度为O(n^2),其中n是列表的长度。由于每次遍历都会将当前未排序部分的最大元素“冒泡”到末尾,因此需要遍历n次。每次遍历中需要比较相邻的元素并可能交换它们的位置,最坏情况下需要比较和交换(n-1)次,因此总的比较和交换次数为n*(n-1)/2,即O(n^2)。
冒泡排序是一种稳定的排序算法,即相等元素的相对位置在排序后不会改变。
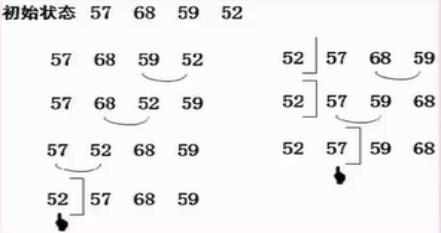
🔎7.快速排序
快速排序是一种高效的排序算法,它基于分治的思想。
快速排序的基本思想是选择一个基准元素(通常选择数组的第一个元素),将数组分成两个子数组,使得左子数组的所有元素均小于基准元素,右子数组的所有元素均大于基准元素,然后对这两个子数组分别进行快速排序,最后将左子数组、基准元素和右子数组合并起来。
具体的实现步骤如下:
- 选择一个基准元素,通常选择数组的第一个元素。
- 定义两个指针,一个指向数组的第一个元素,一个指向数组的最后一个元素。
- 将指针进行移动,直到找到左边大于等于基准元素的元素和右边小于等于基准元素的元素。
- 如果左指针小于等于右指针,则交换这两个元素的位置。
- 继续移动指针,直到左指针大于右指针。
- 交换基准元素和左指针的元素的位置,使得左指针左边的元素都小于基准元素,右指针右边的元素都大于基准元素。
- 对左子数组和右子数组分别进行快速排序,递归地进行上述步骤。
- 当子数组的长度小于等于1时,停止递归。
快速排序的时间复杂度为O(nlogn),其中n为数组的长度。
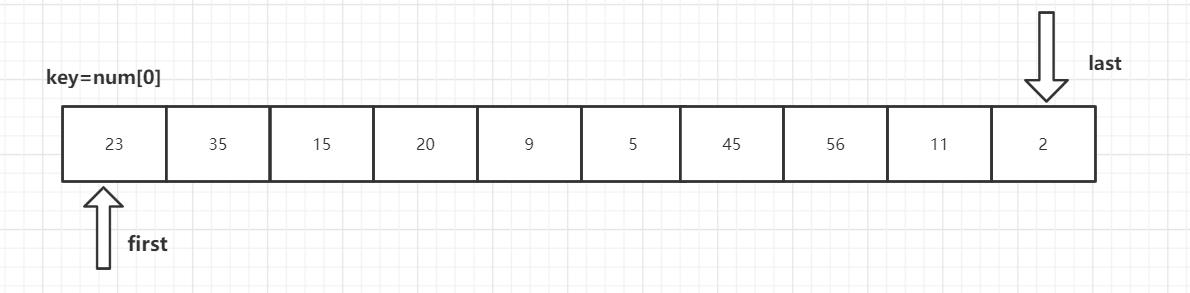
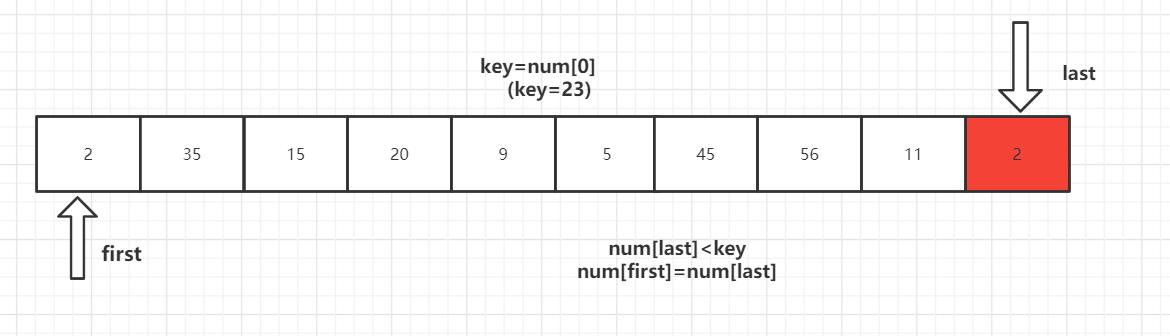
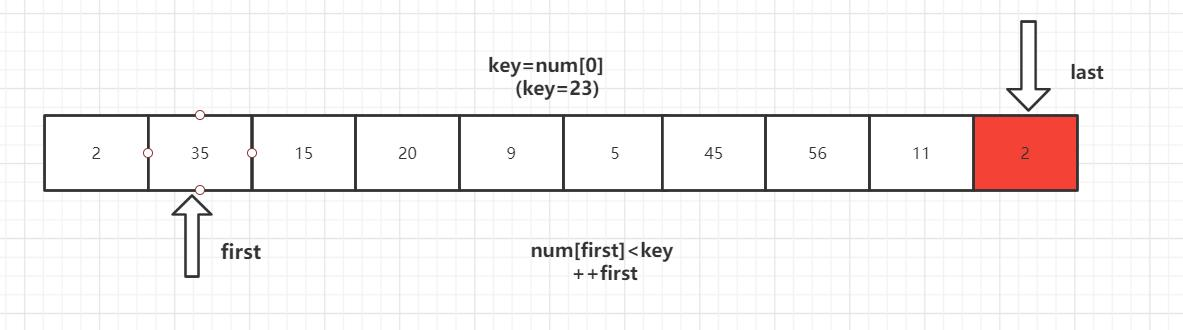
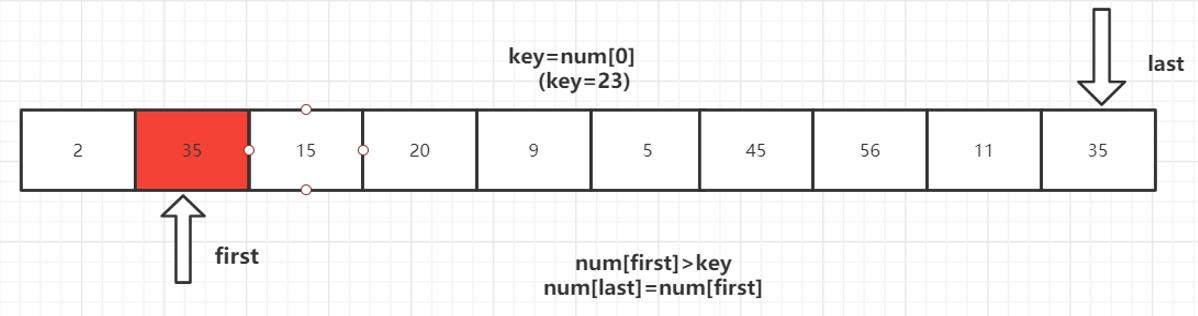
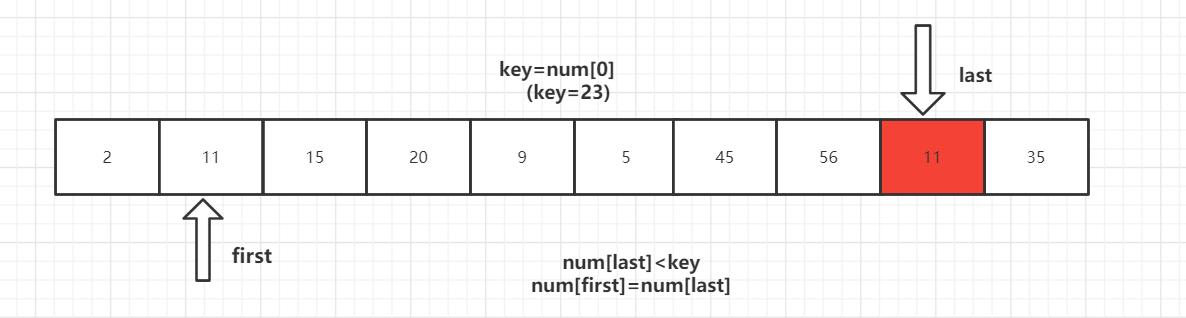
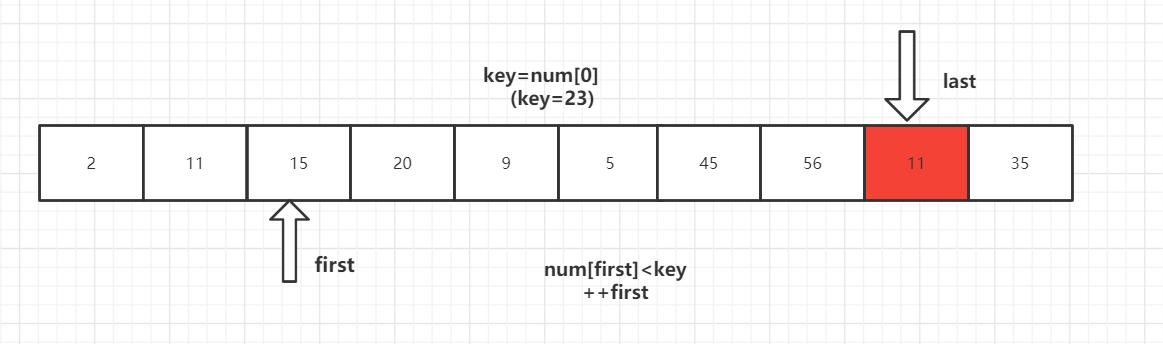
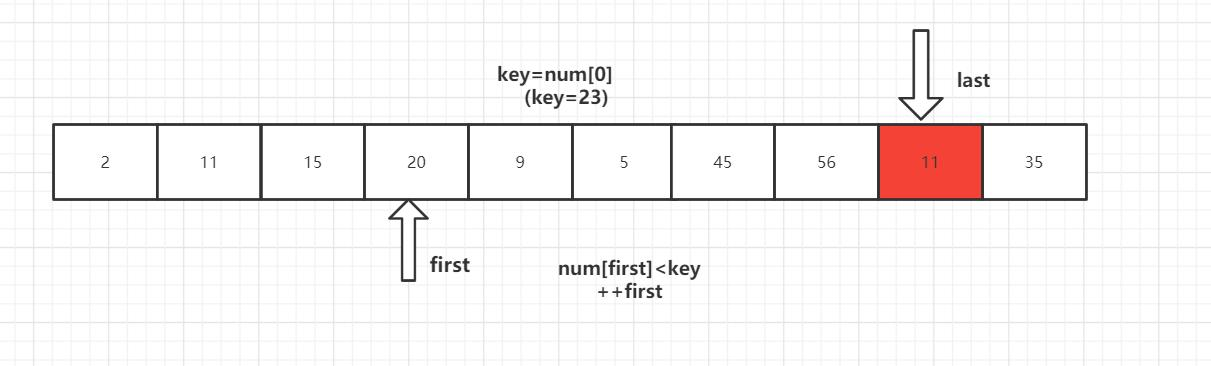
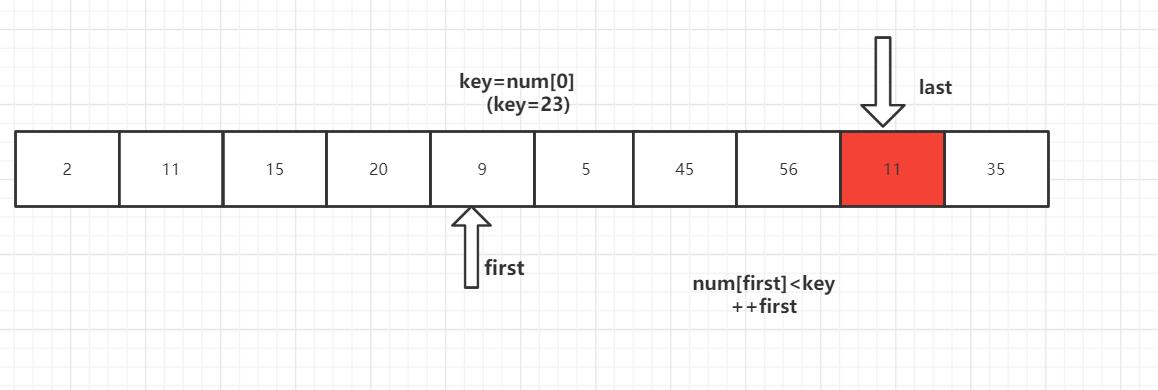
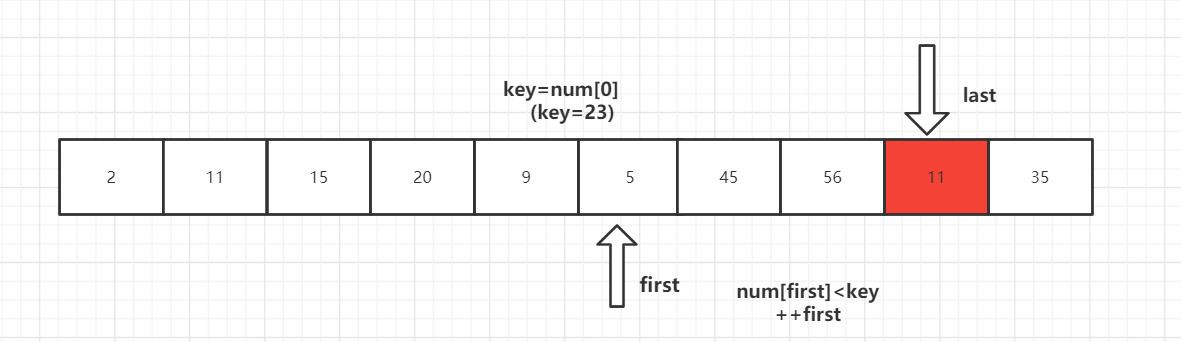
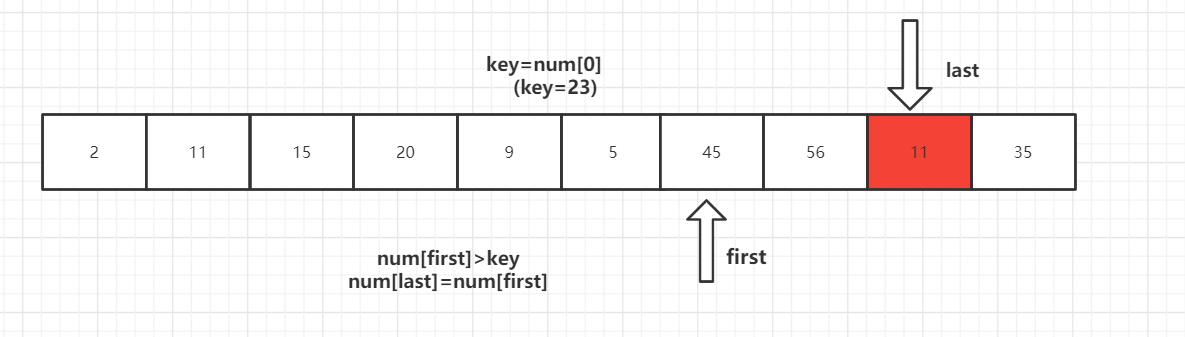
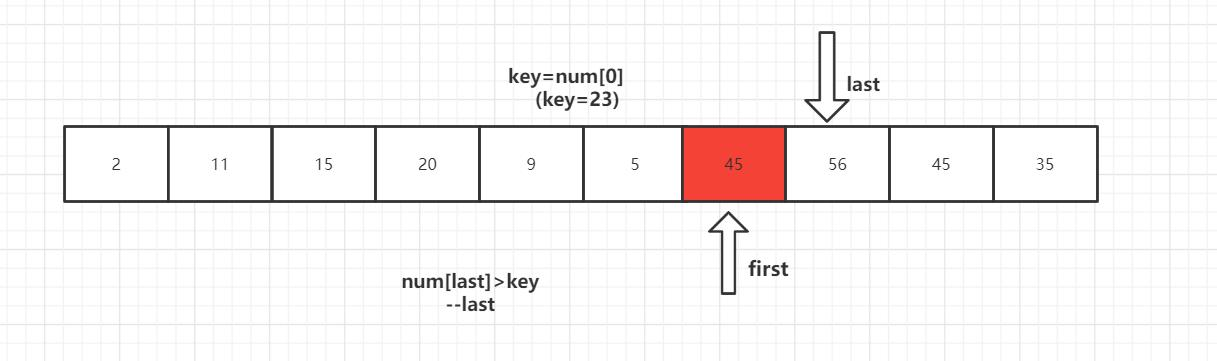
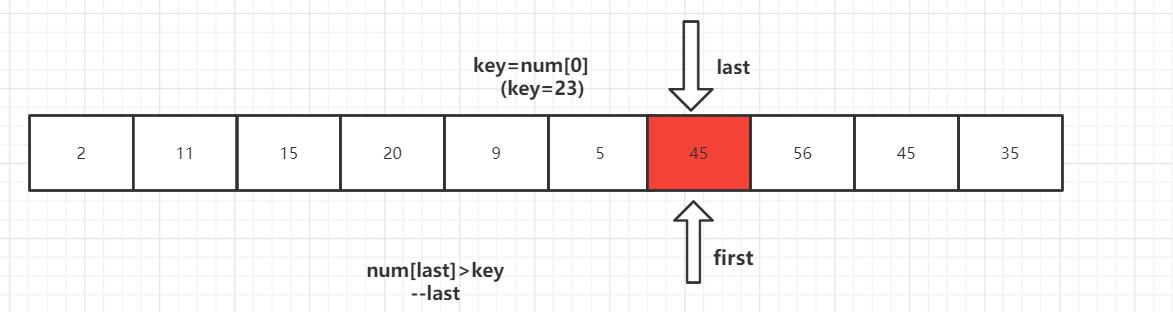
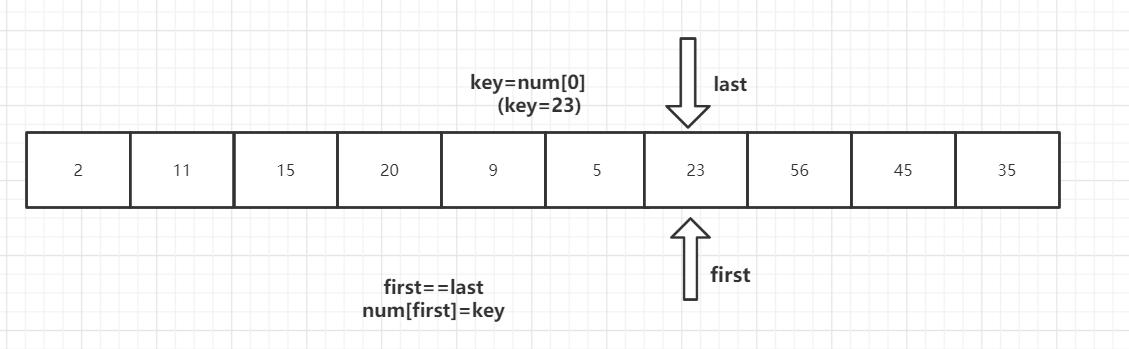
第一趟排序结束,得到[2,11,15,20,9,5] 23 [56,45,35] 然后对左右子数列进行同样的操作。
2 [11,15,20,9,5] 23 [35,45] 56
2 [5,9] 11 [20,15] 23 35 45 56
2 5 9 11 15 20 23 35 45 56
🔎8.归并排序
归并排序是一种分治算法,它将一个数组分成两个子数组,对每个子数组进行递归排序,然后将两个子数组合并为一个有序的数组。
具体步骤如下:
- 将待排序数组分成两个子数组,分别递归地对两个子数组进行排序。
- 合并两个有序的子数组,得到一个有序的数组。
合并两个有序的子数组的步骤如下:
- 创建一个临时数组,用来存储合并后的有序数组。
- 比较两个子数组的首元素,将较小的元素放入临时数组,并将对应子数组的指针向后移动一位。
- 重复上述步骤,直到其中一个子数组的元素全部放入临时数组。
- 将另一个子数组的剩余元素放入临时数组。
- 将临时数组的元素复制回原数组的对应位置。
归并排序的时间复杂度为O(nlogn),空间复杂度为O(n)。它是一种稳定的排序算法,适用于处理大规模数据和外部排序。
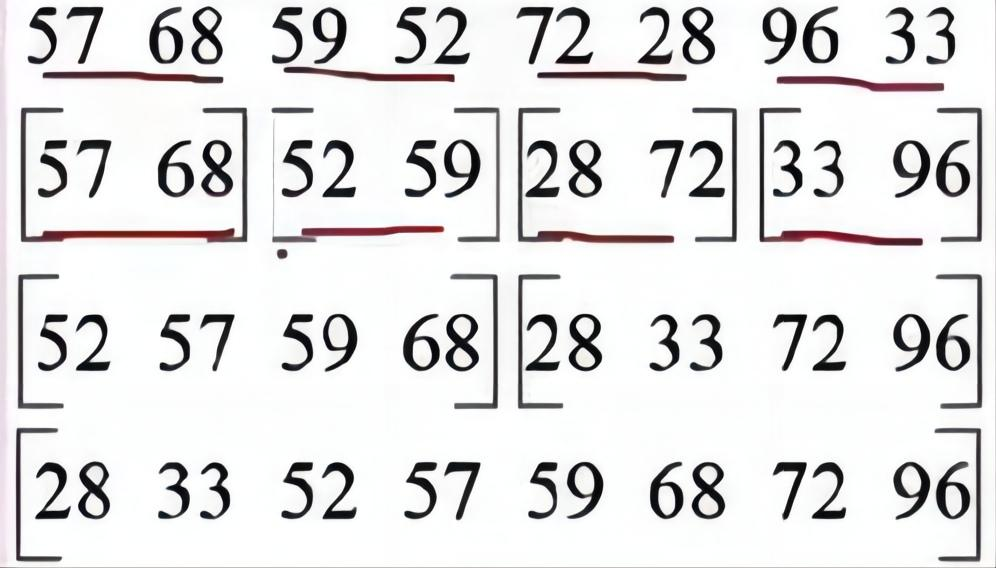
对第三次归并,将52与28比较,28小,放入新表头,52再与33比较,33放入新表,52再与72比较,52放入新表,57再与72比较,57放入新表
🔎9.基数排序
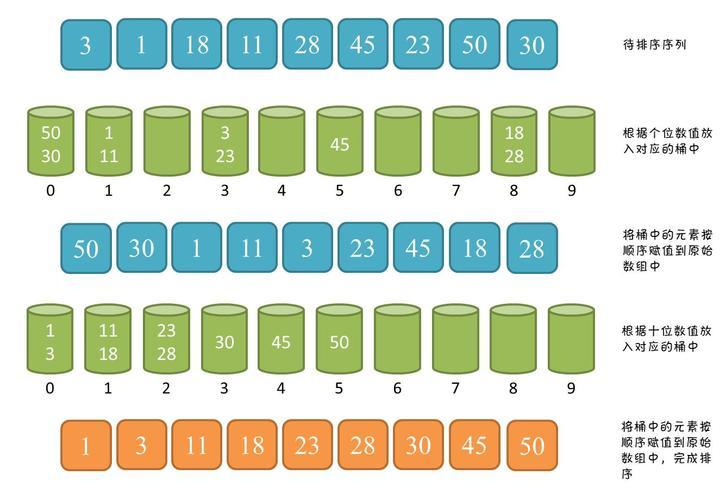
基数排序是一种非比较型的排序算法,它按照元素的各个位的值来进行排序。基数排序可以用于整数或者字符串的排序。
基数排序的基本思想是:将待排序的元素分配到有限数量的桶中,然后按照桶的顺序依次取出元素构成有序序列。桶的数量一般和基数的范围有关。
具体的算法步骤如下:
- 找出待排序元素中的最大值,确定最大值的位数,这个位数决定了需要进行多少次排序操作;
- 准备桶,桶的数量一般和基数的范围有关;
- 对待排序的元素按照从低位到高位的顺序依次进行排序:
- 将待排序的元素按照当前位的值分配到对应的桶中;
- 按照桶的顺序依次取出元素构成有序序列;
- 循环上述步骤,直到所有位都排序完成。
基数排序的时间复杂度取决于数据的位数和数据范围,一般情况下为O(d*(n+r)),其中d是最大值的位数,n是元素个数,r是基数的范围。基数排序是一种稳定的排序算法。

🔎10.总结




🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”

- 点赞
- 收藏
- 关注作者
评论(0)