【愚公系列】软考中级-软件设计师 015-数据结构(线性结构)

🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,CSDN商业化专家,阿里云专家博主,阿里云签约作者,腾讯云优秀博主,腾讯云内容共创官,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2023年华为云十佳博主,2022年CSDN博客之星TOP2,2022年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
线性结构是指数据元素之间存在一对一的关系,即除了第一个和最后一个数据元素之外,其他数据元素都只有一个直接前驱和一个直接后继。线性结构包括以下几种:
-
数组(Array):一组连续的内存空间来存储相同类型的数据元素,通过下标访问元素。
-
链表(Linked List):由一系列节点组成,每个节点包含数据域和指向下一个节点的指针。
-
栈(Stack):一种特殊的线性表,只能在表的一端进行插入和删除操作,遵循先进后出(LIFO)的原则。
-
队列(Queue):一种特殊的线性表,只能在表的一端进行插入操作(队尾),在表的另一端进行删除操作(队头),遵循先进先出(FIFO)的原则。
-
双向链表(Doubly Linked List):每个节点包含数据域和指向前一个节点和后一个节点的指针。
-
循环链表(Circular Linked List):最后一个节点的指针指向第一个节点,形成一个闭环。
🚀一、线性结构
🔎1.概念
线性结构是指每个元素最多只有一个出度和一个入度,表现为一条线状。线性表是一种特殊的线性结构分为顺序表和链表。
- 顺序表:顺序表是使用一段连续的存储空间来存储线性表的元素,可以通过下标直接访问元素。顺序表的特点是插入和删除操作较慢,但是随机访问元素的效率较高。
- 链表:链表是通过一系列的节点来存储线性表的元素,每个节点包含数据域和指向下一个节点的指针。链表的特点是插入和删除操作较快,但是随机访问元素的效率较低。
在线性结构中,除了顺序表和链表,还有一些其他的线性结构,如栈和队列。栈是一种特殊的线性表,只能在表的一端进行插入和删除操作,遵循先进后出(LIFO)的原则。队列也是一种特殊的线性表,只能在表的一端进行插入操作(队尾),在表的另一端进行删除操作(队头),遵循先进先出(FIFO)的原则。
线性结构中元素在计算机内存中的存储方式,主要有顺序存储和链式存储两种方式。
- 顺序存储:顺序存储是将线性表中的元素依次存储在一组地址连续的存储单元中,使得逻辑上相邻的元素在物理上也相邻。顺序存储的特点是通过元素的下标可以直接访问元素,因此查找效率高。插入和删除元素时需要移动其他元素,效率较低。
- 链式存储:链式存储是通过存储各数据元素的结点的地址来实现元素的存储,每个结点包含数据域和指向下一个结点的指针。链式存储的特点是插入和删除元素时只需要修改指针,不需要移动其他元素,因此效率较高。但是链式存储无法直接访问中间的元素,需要从头节点开始顺序遍历。
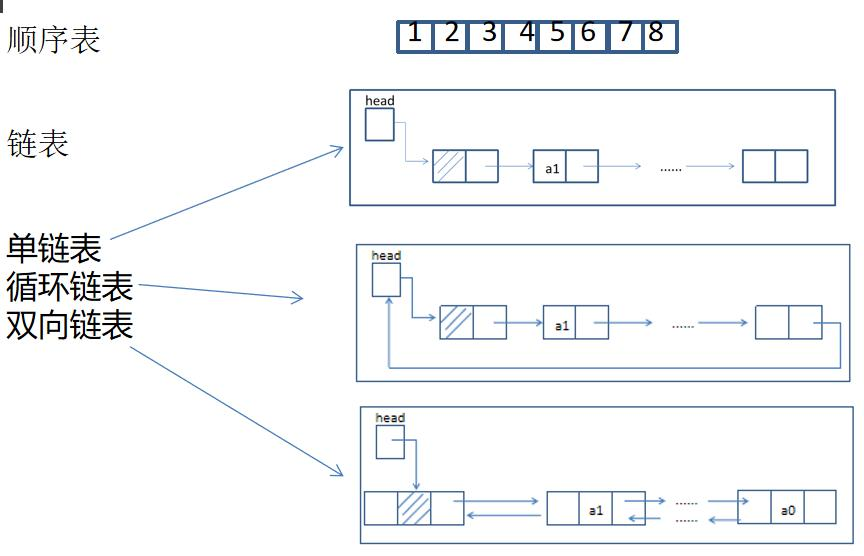
🔎2.顺序存储和链式存储区别
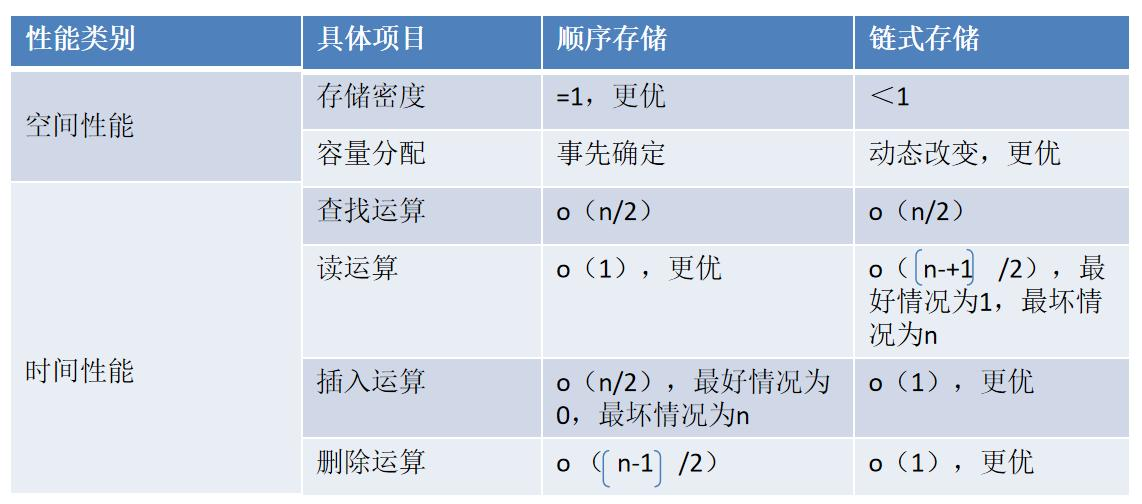
在空间方面,链表需要额外存储指针,导致空间浪费。
在时间方面:
-
链表在插入和删除元素时效率更高,因为只需要修改指针指向,而顺序表因为地址连续,插入或删除元素后需要移动其他节点。
-
在读取和查找元素时,顺序表效率更高,因为物理地址连续,可以通过索引快速定位,而链表需要从头节点开始逐个查找。
🔎2.单链表的插入和删除
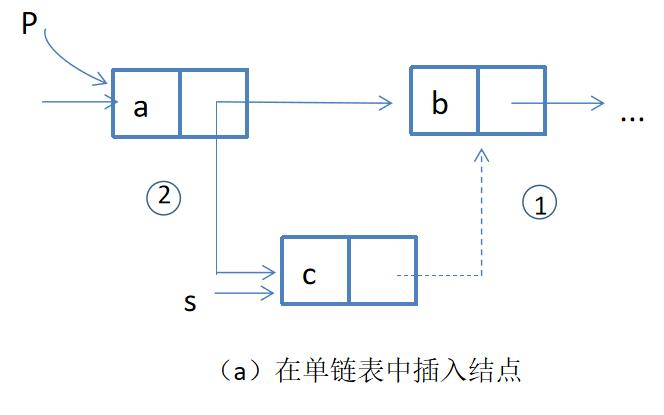
在上图中p所指向的节点后插入s所指向的节点,操作为:
s->next=p->next;
p->next=s;
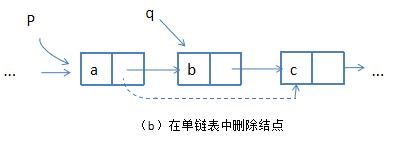
在单链表中删除p所指向节点的后继节点q时,操作为:
p->next=p->next->next;
free(q);

🔎3.栈和队列
栈、队列和循环队列是常见的数据结构,用于存储和操作数据。
-
栈(Stack)是一种后进先出(Last In First Out,LIFO)的数据结构。它只允许在栈的一端进行插入和删除操作,这一端称为栈顶。栈的常用操作有入栈(push)、出栈(pop)和获取栈顶元素(top)。栈可以用数组或链表实现。
-
队列(Queue)是一种先进先出(First In First Out,FIFO)的数据结构。它允许在队列的一端(队尾)插入新元素,而在另一端(队头)删除元素。队列的常用操作有入队(enqueue)、出队(dequeue)和获取队头元素(front)。队列可以使用数组或链表实现。
-
循环队列(Circular Queue)是一种具有固定大小的队列,它可以像队列一样先进先出,但是它的队尾和队头是相连的。当队尾到达数组的末尾时,它可以循环回到数组的开头。循环队列的常用操作有入队(enqueue)、出队(dequeue)和获取队头元素(front)。循环队列可以使用数组实现,通过维护两个指针(队头和队尾的索引)来实现循环。
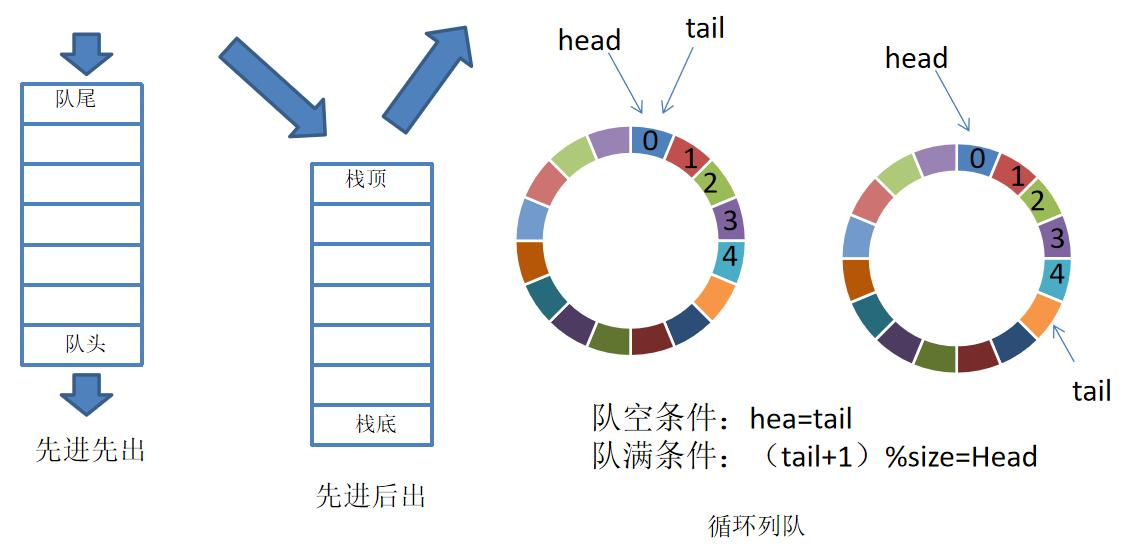
在循环队列中,头指针指向第一个元素,尾指针指向最后一个元素的下一个位置。当队列为空时,头尾指针相等;当队列满时,头尾指针也相等,无法区分。因此,一般会将队列空出一个元素位置,这样队列满的条件就是尾指针的下一个位置等于头指针。考虑到循环队列特性,需要使用最大元素数取余运算来实现循环,即(tail + 1) % size = head。循环队列的长度可以通过(Q.tail - Q.head) % size公式得到。另外,优先队列是一种特殊的队列,其中的元素被赋予了优先级。在访问元素时,具有最高优先级的元素最先被删除。优先队列常使用堆来存储元素,因为堆的顺序不是按照元素在队列中的顺序来决定的。

🔎4.串
🦋4.1 串的定义
| 术语 | 定义 |
|---|---|
| 空串 | 长度为0的字符串,没有任何字符。 |
| 空格串 | 由一个或多个空格组成的串,空格是空白字符,占一个字符长度。 |
| 子串 | 串中任意长度的连续字符构成的序列称为子串。含有子串的串称为主串,空串是任意串的子串。 |
🦋4.2 串的匹配
| 算法 | 定义 |
|---|---|
| 模式匹配算法 | 子串的定位操作,用于查找子串在主串中第一次出现的位置的算法。 |
| 基本的模式匹配算法 | 也称为布鲁特一福斯算法,其基本思想是从主串的第1个字符起与模式串的第1个字符比较,若相等,则继续逐个字符进行后续的比较;否则从主串中的第2个字符起与模式串的第1个字符重新比较,直至模式串中每个字符依次和主串中的一个连续的字符序列相等时为止,此时称为匹配成功,否则称为匹配失败。 |
| KMP算法 | 对基本模式匹配算法的改进,其改进之处在于:每当匹配过程中出现相比较的字符不相等时,不需要回溯主串的字符位置指针,而是利用已经得到的“部分匹配”结果将模式串向右“滑动”尽可能远的距离,再继续进行比较。 |
KMP算法相比于基本的模式匹配算法差别:
-
基本的模式匹配算法:匹配失败从第二位开始继续
-
KMP算法:匹配失败从失败位置开始继续
🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”

- 点赞
- 收藏
- 关注作者
评论(0)