【昇思技术公开课笔记-大模型】Transformer理论知识

什么是Transformer
Transformer是一种神经网络结构,由Vaswani等人在2017年的论文“Attention Is All You Need”中提出,用于处理机器翻译、语言建模和文本生成等自然语言处理任务。
Transformer与传统NLP特征提取类模型的区别主要在以下两点:
- Transformer是一个纯基于注意力机制的结构,并将自注意力机制和多头注意力机制的概念运用到模型中;
*由于缺少RNN模型的时序性,Transformer引入了位置编码,在数据上而非模型中添加位置信息;
以上的处理带来了几个优点:
- 更容易并行化,训练更加高效;
- 在处理长序列的任务中表现优秀,可以快速捕捉长距离中的关联信息。
注意力机制 (Attention)
如同阅读时,视线只会集中在正在阅读的部分;自然语言处理中,根据任务内容的不同,句子中需要更加关注的部分也会不同。

注意力机制便是在判断词在句子中的重要性,我们通过注意力分数来表达某个词在句子中的重要性,分数越高,说明该词对完成该任务的重要性越大。
计算注意力分数时,我们主要参考三个因素:query、key和value。
- query:任务内容
- key:索引/标签(帮助定位到答案)
- value:答案
一般在文本翻译中,我们希望翻译后的句子的意思和原始句子相似,所以进行注意力分数计算时,query一般和目标序列,即翻译后的句子有关,key则与源序列,即翻译前的原始句子有关。
计算注意力分数,即为计算query与key的相似度。常用的计算注意力分数的方式有两种:additive attention和scaled dot-product attention,在这里我们主要介绍第二种方法。
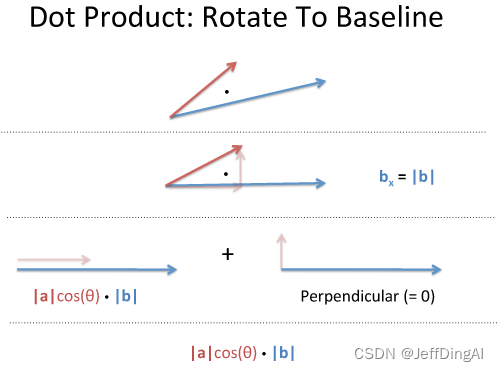
在几何角度,点积(dot product)表示一个向量在另一个向量方向上的投影。换句话说,从几何角度上解读,点积代表了某个向量中的多少是和另一个向量相似的。
自注意力机制(Self-Attention)
自注意力机制中,我们关注句子本身,查看每个单词对于周边单词的重要性。这样可以很好地理清句子中的逻辑关系,如代词指代。
举个例子,在’The animal didn’t cross the street because it was too tired’这句话中,‘it’指代句中的’The animal’,所以自注意力会赋予’The’、'animal’更高的注意力分值。

多头注意力(Multi-Head Attention)

多头注意力是注意力机制的扩展,它可以使模型通过不同的方式关注输入序列的不同部分,从而提升模型的训练效果。
不同于之前一次计算整体输入的注意力分数,多头注意力是多次计算,每次计算输入序列中某一部分的注意力分数,最后再将结果进行整合。
简单来说,在多头注意力中,每个头部可以’解读’输入内容的不同方面,比如:捕捉全局依赖关系、关注特定语境下的词元、识别词和词之间的语法关系等。
Transformer 结构
Transformer同样是encoder-decoder的结构,只不过这里的“encoder”和“decoder”是由无数个同样结构的encoder层和decoder层堆叠组成。
在进行机器翻译时,encoder解读源语句(被翻译的句子)的信息,并传输给decoder。decoder接收源语句信息后,结合当前输入(目前翻译的情况),预测下一个单词,直到生成完整的句子。

Transformer的具体结构如下图所示,在进入encoder或decoder前,源序列和目标序列需要经过一些“加工”。
- word embedding: 将序列转换为模型所能理解的词向量表示,其中包含了序列的内容信息。
- positional encoding:在内容信息的基础上添加位置信息。

位置编码(Positional Encoding)
Transformer模型不包含RNN,所以无法在模型中记录时序信息,这样会导致模型无法识别由顺序改变而产生的句子含义的改变,如“我爱我的小猫”和“我的小猫爱我”。
为了弥补这个缺陷,我们选择在输入数据中额外添加表示位置信息的位置编码。
编码器(Encoder)
Transformer的Encoder负责处理输入的源序列,并将输入信息整合为一系列的上下文向量(context vector)输出。
每个encoder层中存在两个子层:多头自注意力(multi-head self-attention)和基于位置的前馈神经网络(position-wise feed-forward network)。
子层之间使用了残差连接(residual connection),并使用了层规范化(layer normalization)。二者统称为“Add & Norm”

基于位置的前馈神经网络
基于位置的前馈神经网络被用来对输入中的每个位置进行非线性变换。它由两个线性层组成,层与层之间需要经过ReLU激活函数。
Add & Norm
Add & Norm层本质上是残差连接后紧接了一个LayerNorm层。
&
- Add:残差连接,帮助缓解网络退化问题,注意需要满足x与Sublayer(x)的形状一致
- Norm:Layer Norm,层归一化,帮助模型更快地进行收敛;
解码器 (Decoder)

解码器将编码器输出的上下文序列转换为目标序列的预测结果 ,该输出将在模型训练中与真实目标输出进行比较,计算损失。
不同于编码器,每个Decoder层中包含两层多头注意力机制,并在最后多出一个线性层,输出对目标序列的预测结果。
第一层:计算目标序列的注意力分数的掩码多头自注意力;
第二层:用于计算上下文序列与目标序列对应关系,其中Decoder掩码多头注意力的输出作为query,Encoder的输出(上下文序列)作为key和value;

- 点赞
- 收藏
- 关注作者
评论(0)