Zookeeper 工作流程

前言
Zookeeper 作为分布式协调服务为分布式系统提供了一些基础服务,如:命名服务、配置管理、同步等,使得开发者可以更加轻松地处理分布式问题。
在分布式系统中,协调是一项关键任务。例如,如何让一组独立的进程或机器知道它们应该执行哪些任务,如何将它们的状态同步到其他进程或机器上,以及如何处理故障或异常等。这些问题都是 Zookeeper 所解决的问题。
本文将带你深入了解 Zookeeper 的内部实现,从其各个组件和接口开始,分析其工作原理和设计思想。希望你在阅读这个源码分析的过程中,能够深入理解 Zookeeper 的工作原理和设计思想,从而更好地利用它来解决你的分布式问题。
Zookeeper启动
无论看什么代码,我们都应该从程序的入口点入手,这样可以更好地理解整体的结构和运行流程。
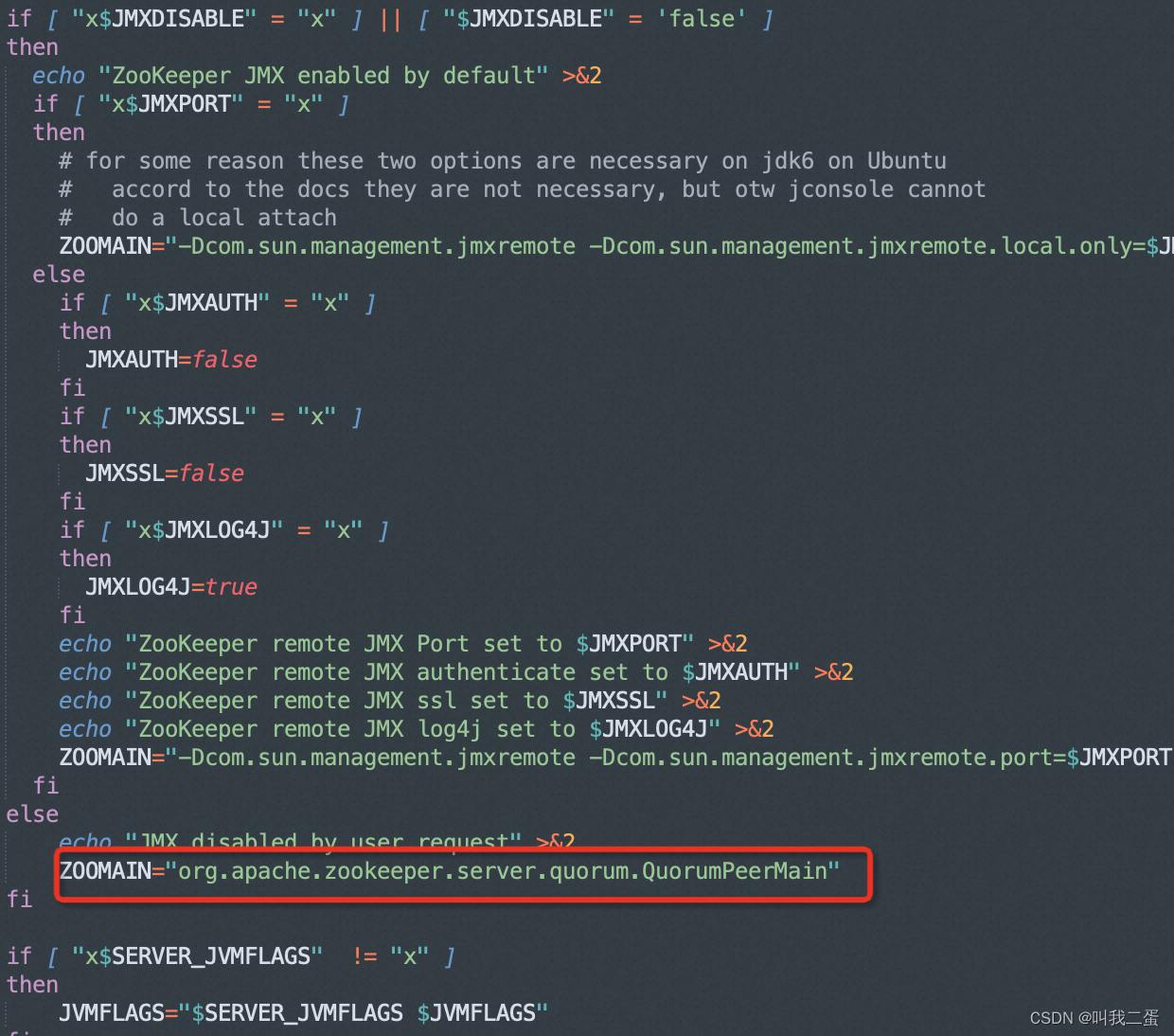
通过 zkServer.sh 脚本可以看到启动类为QuorumPeerMain。
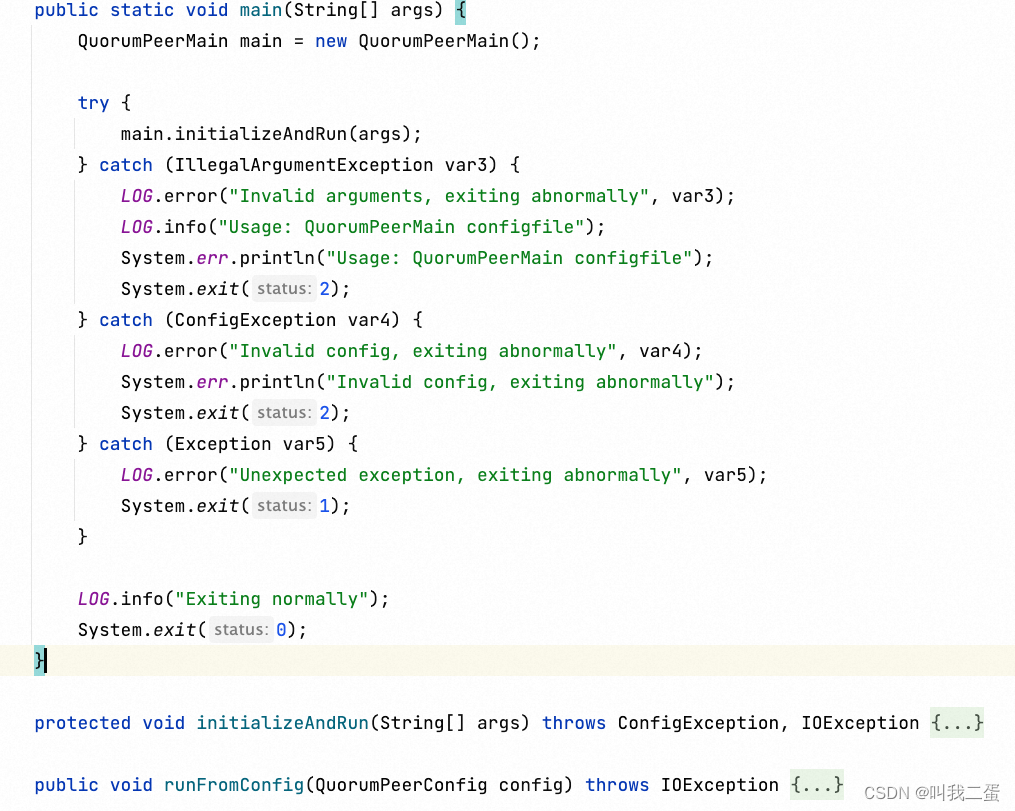
可以看到Zookeeper启动是通过main方法开始的,最终调用了runFromConfig方法设置并启动一个ZooKeeper的集群节点。
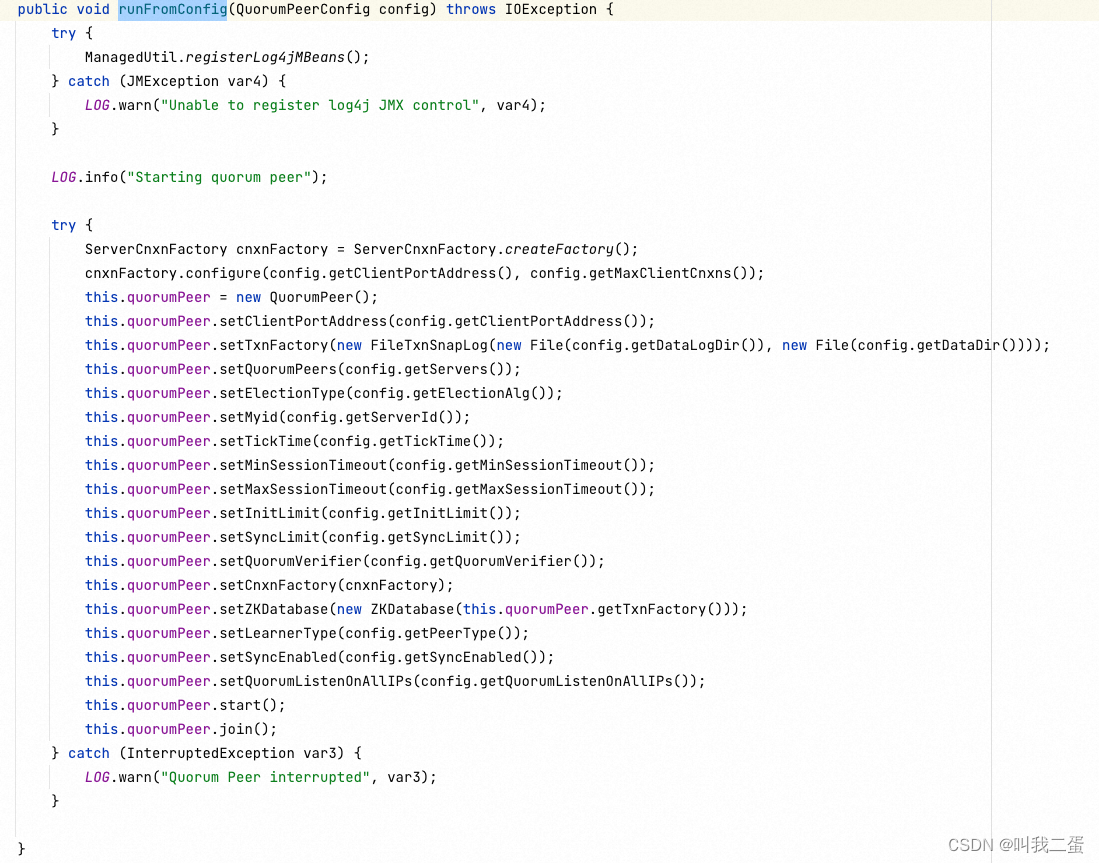
上面的代码设置了QuorumPeer的事务日志和快照目录路径、选举算法选择、指定服务器ID、定义时钟周期和数据保存实例等配置。此外,还创建了服务器和客户端连接的工厂类(NIO/Netty)。最后,调用start方法启动服务。

在start中,主要完成了以下四个任务:
- 将磁盘中的数据加载到内存中,为后续的处理和响应提供必要的数据储备。
- 建立Socket来处理客户端的请求,实现与客户端的通信交互。
- 进行了Leader的选举准备工作,确定选举算法。。
- 进行Leader选举并对节点状态进行监听并相应处理,及时发现和处理节点故障或异常状态,确保整个系统的可靠性和稳定性。
加载磁盘数据
ZooKeeper 操作事内存级别的,为了保障可靠性,会将数据以事务日志形式持久化到文件中,所以在启动时先加载数据到内存。
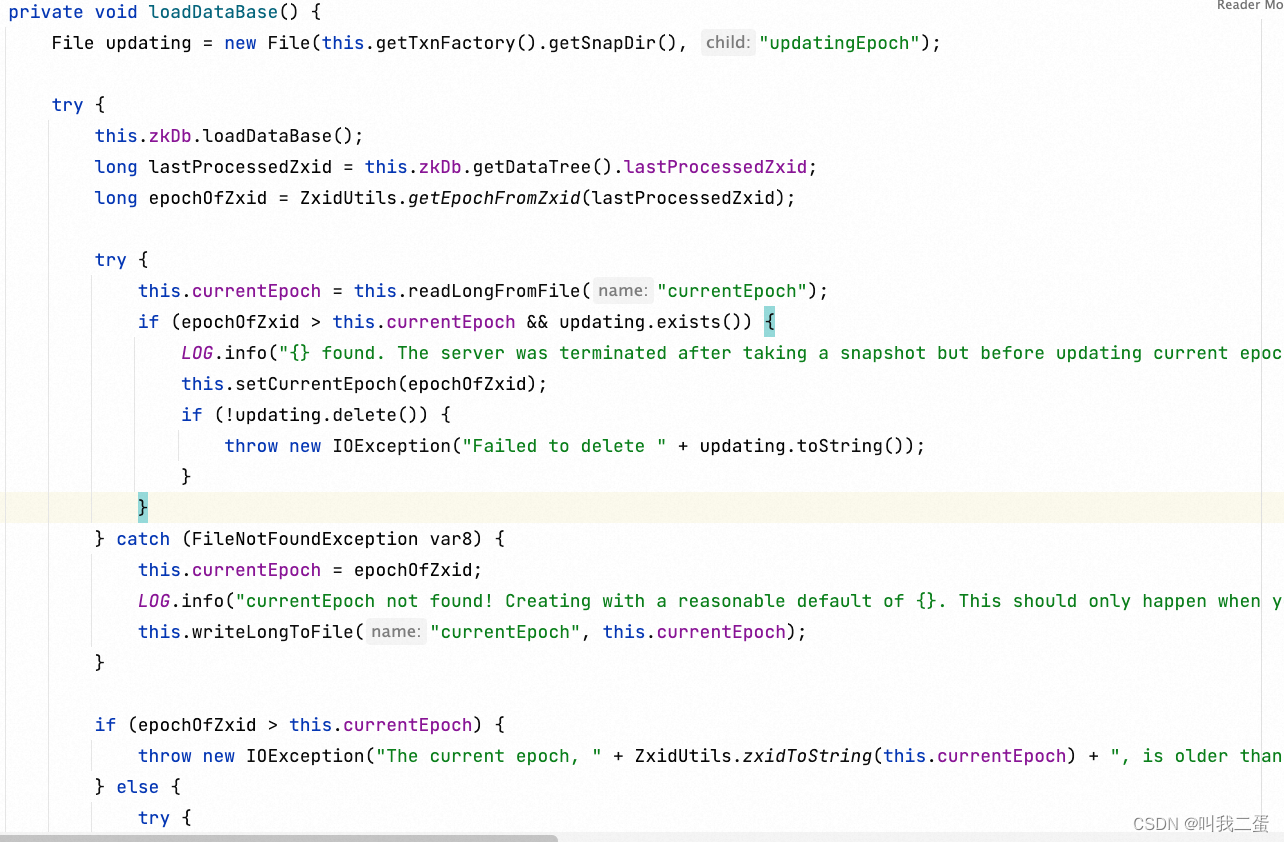
这段代码的主要目的是从磁盘加载Zookeeper数据库到内存,并检查并处理相关的epoch信息。getDataTree().lastProcessedZxid 这行代码获取在ZooKeeper服务器上已处理的最新的事务的zxid,ZxidUtils.getEpochFromZxid(lastProcessedZxid)这行代码从zxid中获取epoch,readLongFromFile(CURRENT_EPOCH_FILENAME): 这行代码从文件中读取当前的epoch信息。如果zxid所属的epoch小于当前的epoch,会抛出IOException异常。
与客户端的通信交互
cnxnFactory 是建立了Socket服务端,用来接收客户端的请求并处理,下图中的代码是NIOServerCnxnFactory,还有一个NettyServerCnxnFactory。选用NIO还是Netty可以在配置文件中设置。对NIO和Netty不熟悉的可以看下网络编程专栏
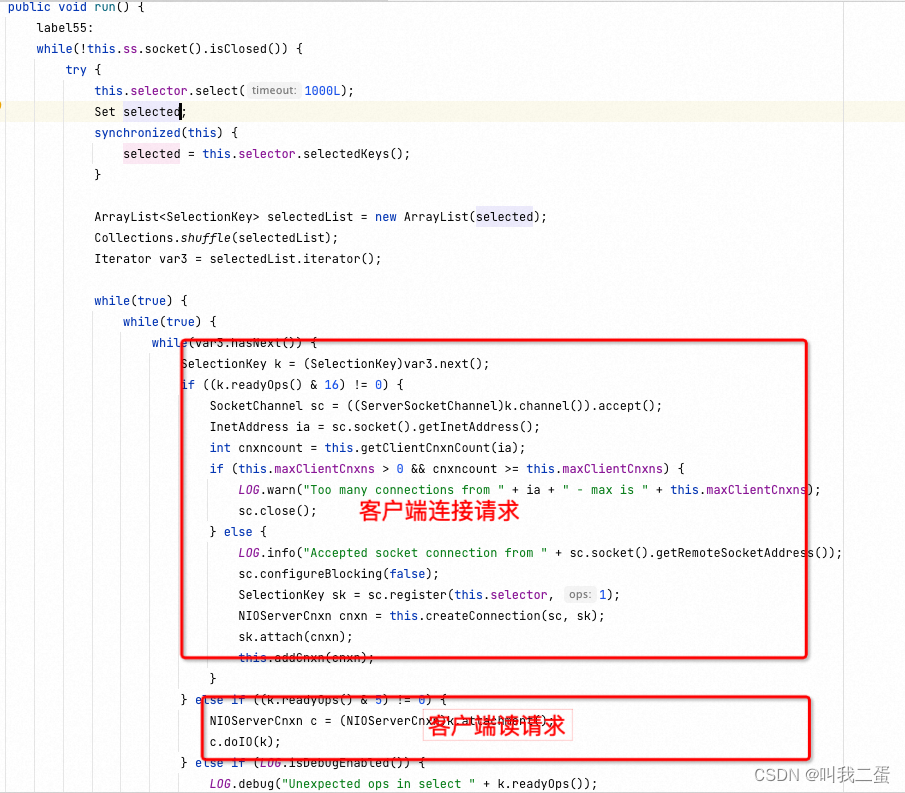
最核心的就是对客户端请求的处理,有如下几个处理器:

CommitProcessor是事务提交处理器,它会等待集群内针对Proposal的投票直到该Proposal可以被提交。SyncRequestProcessor负责把事务请求(写request)持久化到本地磁盘。AckRequestProcessor是Leader特有的处理器,其主要职责是在SyncRequestProcessor处理器完成事务日志记录后,向Proposal的投票收集器发送ACK反馈,以通知投票收集器当前服务器已经完成了对该Proposal的事务日志记录。FollowerRequestProcessor这个处理器可能会负责处理来自客户端的读请求和写请求,并将其转发给其他处理器进行处理,比如写请求转发给Leader节点。SendAckRequestProcessor负责向领导者(Leader)节点发送确认收到的消息(ACK),通知领导者节点该请求已经得到处理。
Leader选举准备
startLeaderElection 中主要调用了createElectionAlgorithm 创建了集群间网络连接的管理器 QuorumCnxManager,并选择了一个选举算法,这个通过配置文件配置,默认为FastLeaderElection。
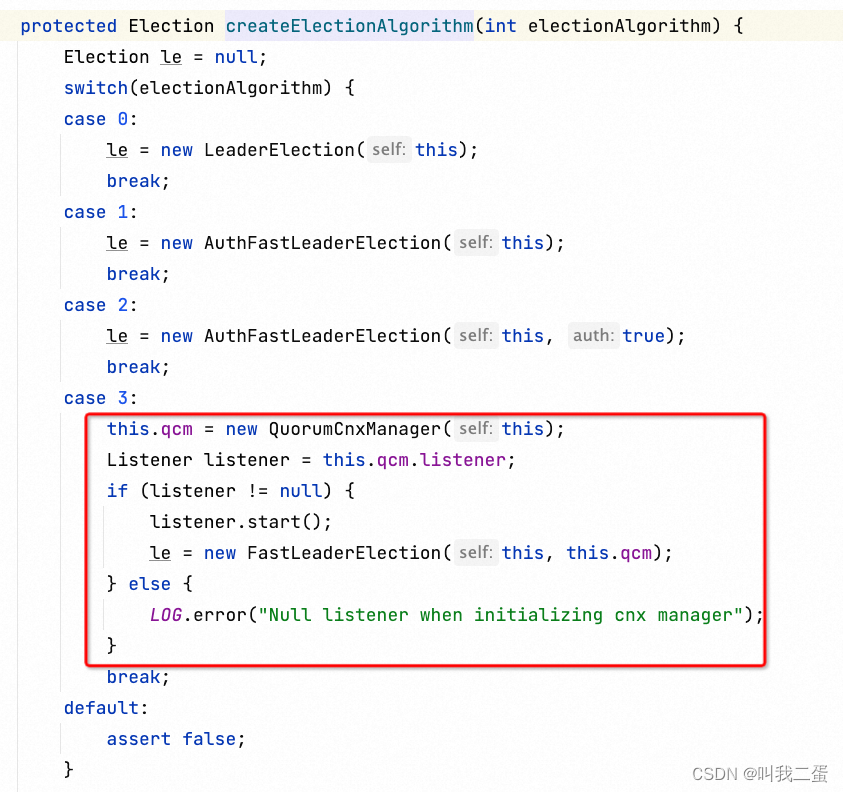
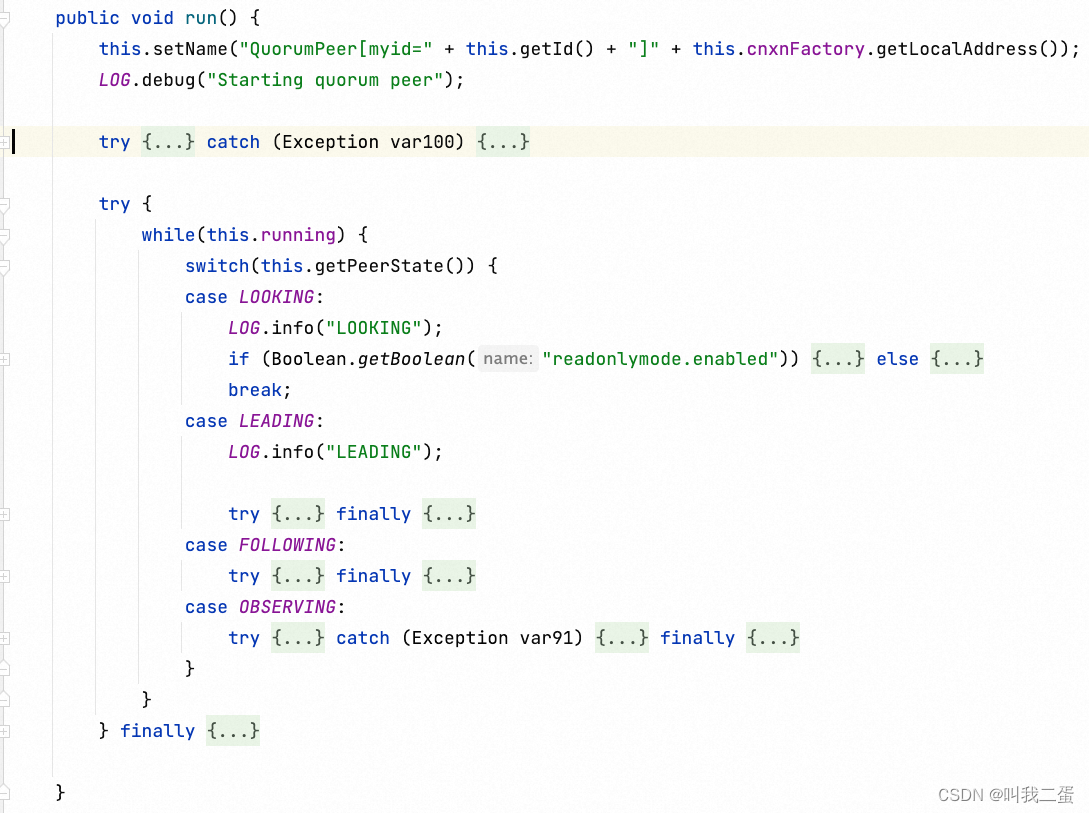
节点状态处理
super.start()执行 QuorumPeer.java 类中的 run()方法,主要是对节点状态的监听及处理。
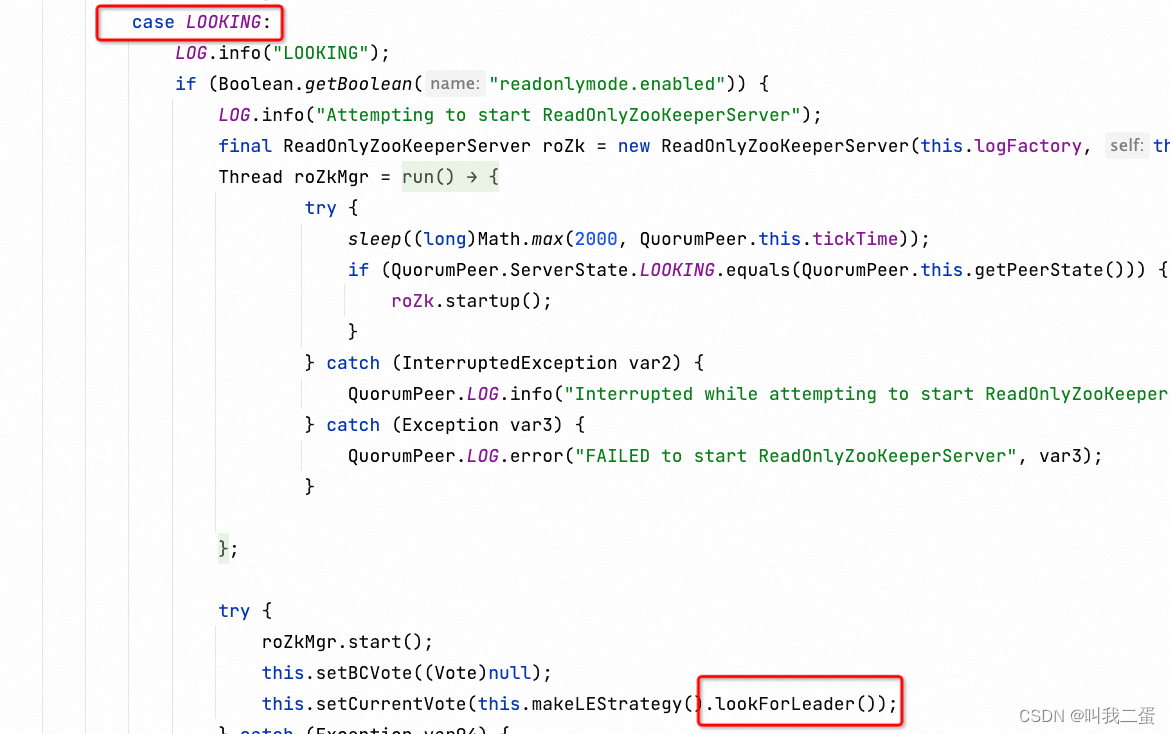
当 Zookeeper 启动后,首先都是 Looking 状态,通过选举,让其中一台服务器成为 Leader,其他的服务器成为 Follower。如果代码比较难理解可以看一下ZAB协议。
总结
通过深入解析源代码,我注意到其功能实现的简洁性以及巧妙设计,尽管代码所处理的功能相当复杂,但组织结构和代码风格的简洁性使得阅读和理解变得相当容易。特别注意到网络编程的大量应用,对连接安全和优化的细致处理。还有其ZAB协议如何巧妙地解决了分布式一致性问题,这些细腻的设计理念无疑为分布式系统的开发提供了宝贵的借鉴,期待能在未来的工作中将这些思想融入到的代码中。

- 点赞
- 收藏
- 关注作者
评论(0)