【云驻共创】GaussDB(DWS)查询优化技术大揭秘

大数据时代,数据量呈爆发式增长,经常面临百亿、千亿数据查询场景,当数据仓库数据量较大、SQL语句执行效率低时,数据仓库性能会受到影响。本文将深入讲解在GaussDB(DWS)中如何进行表结构设计,如何进行SQL优化,如何查找慢SQL和高频SQL,提高数据仓库的性能和响应速度。
1.认识优化器
1.1 什么是优化器,优化器的作用是什么?
当前市场上的数据库产品,基本上都是基于CBO模型的优化器,因此统计信息的及时收集显得很重要
- 基于规则的优化器(rbo,rule based optimizer)
基于硬编码的多组内置规则选取最优执行计划,比如优先使用唯一约束或主键来定位存储单元、优先使用Hash索引等等。它不考虑表大小、列大小、数据分布、排序占用的内存大小。优点:基于经验总结出来的一套规则,它的优点是执行计划稳定缺点:对开发者的SQL开发能力要求非常高,只有熟悉各种规则,才能写出优质的SQL。当表数据虽发生变化,原来的执行计划不是最优的时候,优化无法自动调整。
- 基于成本的优化器(cbo,cost based optimizer)
该优化器通过根据优化规则对关系表达式进行转换,生成多个执行计划,然后CBO会通过根据统计信息(Statistics)和代价模型(Cost Model)计算各种可能“执行计划”的“代价”,即COST,从中选用COST最低的执行方案,作为实际运行方案。优点:可以自动适应表数据量变化,计算量发生变化,自动调节,选择较优的执行计划缺点: 依赖于COST计算模型重要的影响因子: 统计信息,需要给优化器提供准确的统计信息,才能做出好的执行计划。
1.2 SQL执行流程
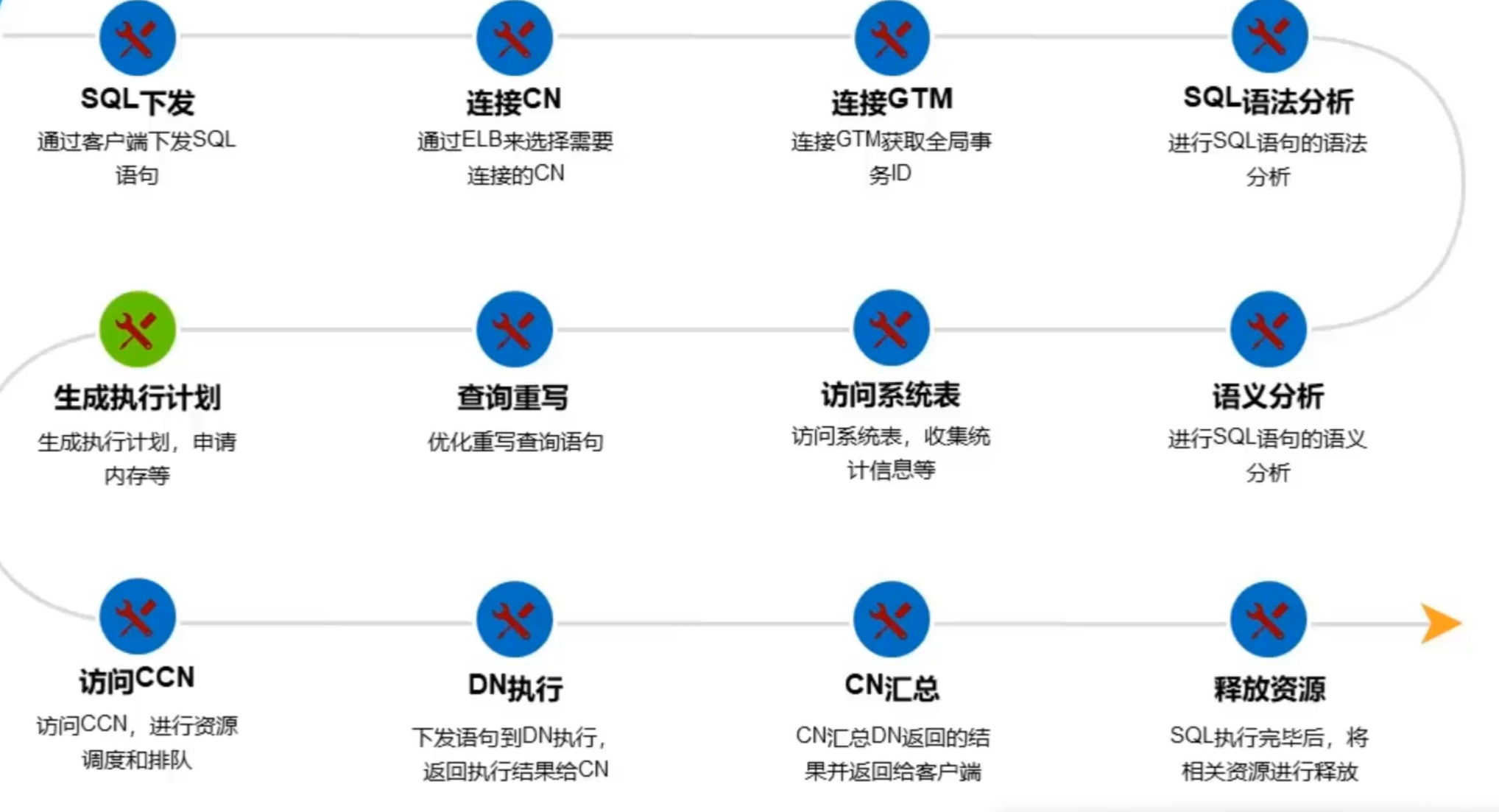
1.3 什么是执行计划
- 执行计划是查询语句在数据库中执行过程的描述
- 执行计划描述了SQL引擎为执行SQL语句进行的操作
- 分析SQL语句相关的性能问题或仅仅质疑查询优化器的决定时,必须知道执行计划;所以执行计划常用于sgl调优
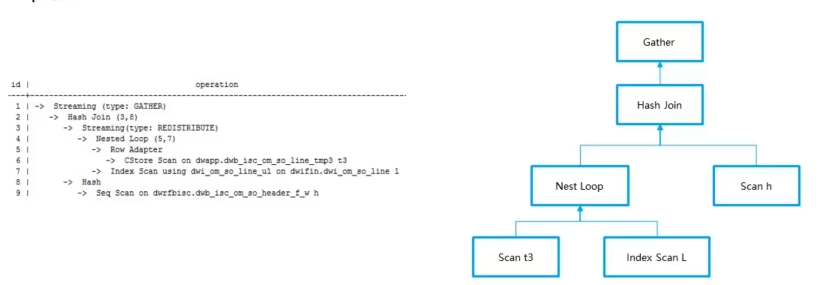
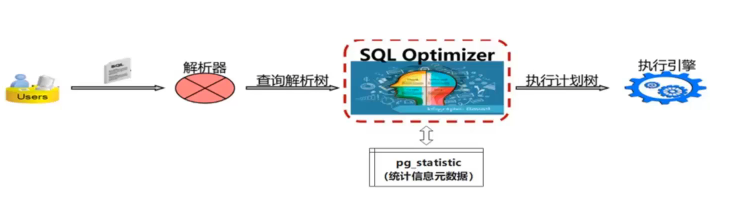
1. 4执行计划怎么生成的
SQL + 表统计信息 =>优化器 => 最优执行计划
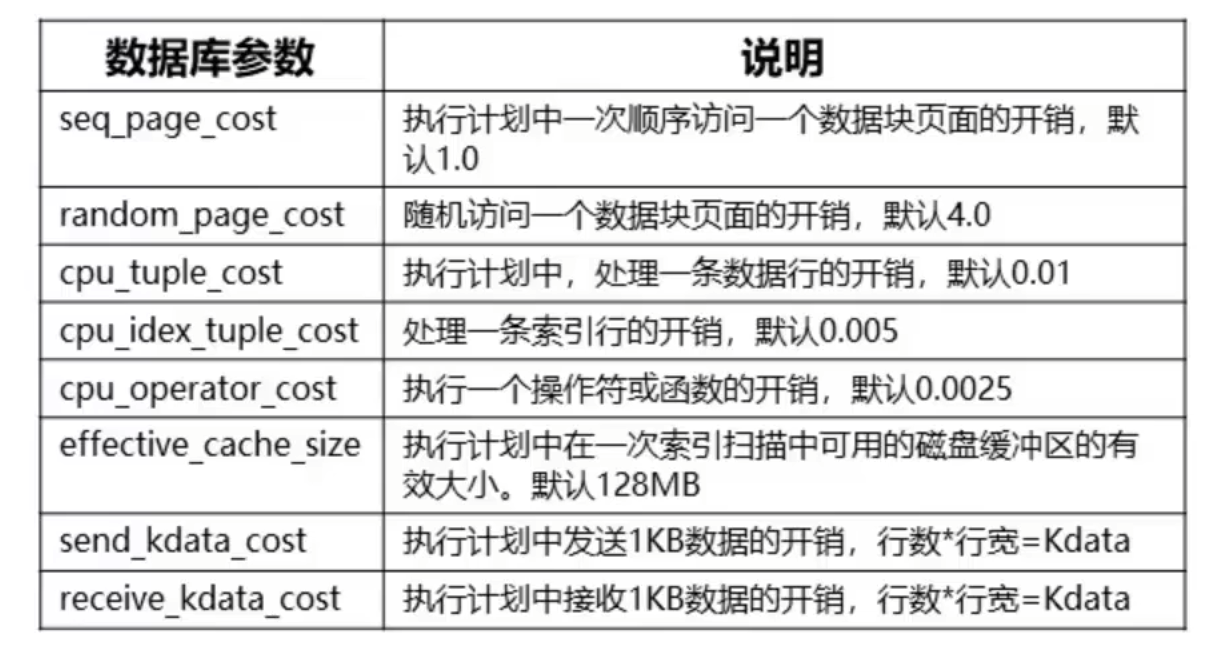
1. 5什么是COST?
较各种操作代价时的相对性能指标
PostgresQL的查询优化是基于代价(Cost)的。代价是一个无量纲的值,它并不是一种绝对的性能指标,但可以作为比
- 举个例子
全表顺序扫描并过滤,代价公式为:
Cost = seq scan cost*relpages + cpu tuple cost*reltuples + cpu operator cost*reltuples
COST计算的两个影响因素,其中数据库参数基本按实践值,一次修改长期不变;表的统计信息,要及时收集,以反映最真实的表数据状态
使用explain命令可以查看优化器为每个查询生成的具体执行计划
edw_db=#h explainCommand:EXPLAINDescription:show the execution plan of a statementsyntax :...] ) ] statement;EXPLAINoptionANALYSE 3 ][VERBOSE ]PERFORMANCE statement;EXPLAINANALYZEEXPLAINSTATS[ boolean ] ) statement;
where option can be:ANALYZE[boolean ]ANALYSEbooleanVERBOSEbooleanCOSTSbooleanCPUboolean]DETAIL[booleanNODESboolean]NUM_NODES[booleanBUFFERSbooTeanTIMINGbooleanPLAN [booleanFORMATTEXTXMLJSON YAML 3
- INTO/CREATETABLE AS)详细的计划信息
执行EXPLAIN VERBOSE命令,收集DML语句 (SELECT/UPDATE/INSERT/DELETE/MERGE
EXPLAIN VERBOSE
SELECT
sum(l extendedprice * (1 - l discount)) AS revenue
FROM orders
INNER JOIN lineitem ON l orderkey = o orderkey
o orderdate >=11994-01-01'::date AND o orderdate <1994-01-01'::date +WHEREinterval1 year';
- INTO/CREATETABLEAS)详细的执行信息
执行EXPLAIN PERFORMANCE命令,收集DML语句 (SELECT/UPDATE/NSERT/DELETE/MERGE
EXPLAIN PERFORMANCE
SELECT
sum(l extendedprice * (1 - l discount)) AS revenue
FROM orders
INNER JOIN lineitem ON l orderkey = o orderkey
WHERE o orderdate >= '1994-01-01'::date AND o orderdate < '994-01-01'::date + interval '1 year';
1.6 理解执行计划
执行计划阅读方法:
从最右缩进开始;从下往上逐步执行,算子后面的数字表示算子编号,左边表示外表,右边表示内表(如Hash Joim(3.8),3号算子做为外表,8号算子做为内表);
算子运行时间=当前算子的a-time减去下层算子的a-time(如2号算子Hash Jomn(3.8= 25388-21483)

1.7Explain 执行计划-算子介绍
1.7.1 扫描算子
功能:扫描算子的作用是扫描表,每次获取一条元组作为上层节点的输入。
扫描算子普遍存在于查询计划树的叶子节点,它不仅可以扫描表,还可以扫描函数的结果集、链表结构、子查询结果集等
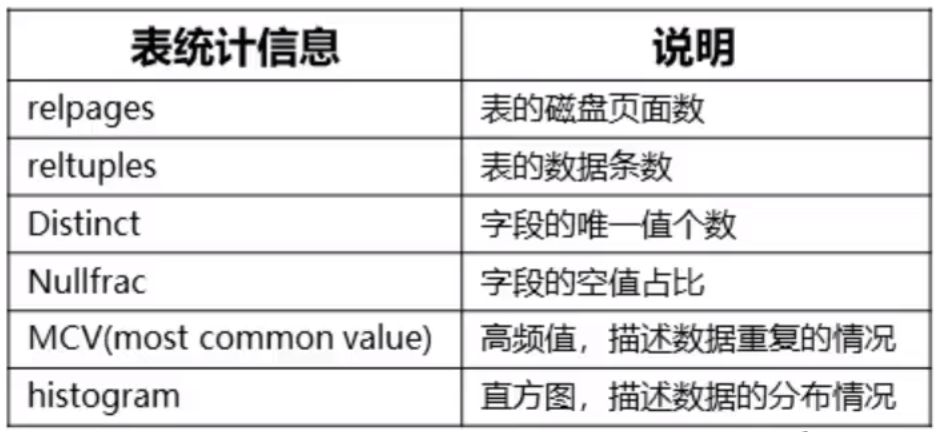
1.7.2 连接算子
连接算子对应于关系代数中的连接操作,主要的几种连接类型如下:

1.7.3 Stream算子
功能: Streaming是一个特殊的算子,它实现了分布式架构的核心数据shuffle功能,Streaming共有三种形态,分别对应分布式结构下不同的数据shuffle功能

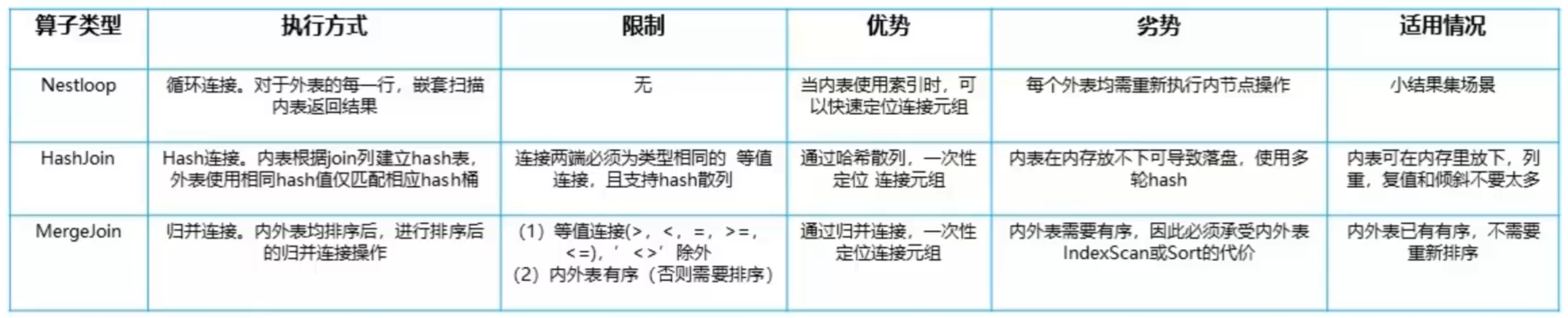
1.7.4 物化算子
物化算子是一类可以缓存元组的节点
在执行计划中,很多扩展的物理操作符需要首先获取所有的元组才能进行操作(例如聚集函数操作、没有索引辅助的排序等),这是要用物化算子将元组缓存起来
1.8 总结
本节主要介绍通过Explain命令查看查询语句的执行计划的两种常用方法,并以示例的查询语句为例,详细介绍Explain Performance 命令收集到的各部分执行信息及SQL性能调优过程需要重点关注的信息。
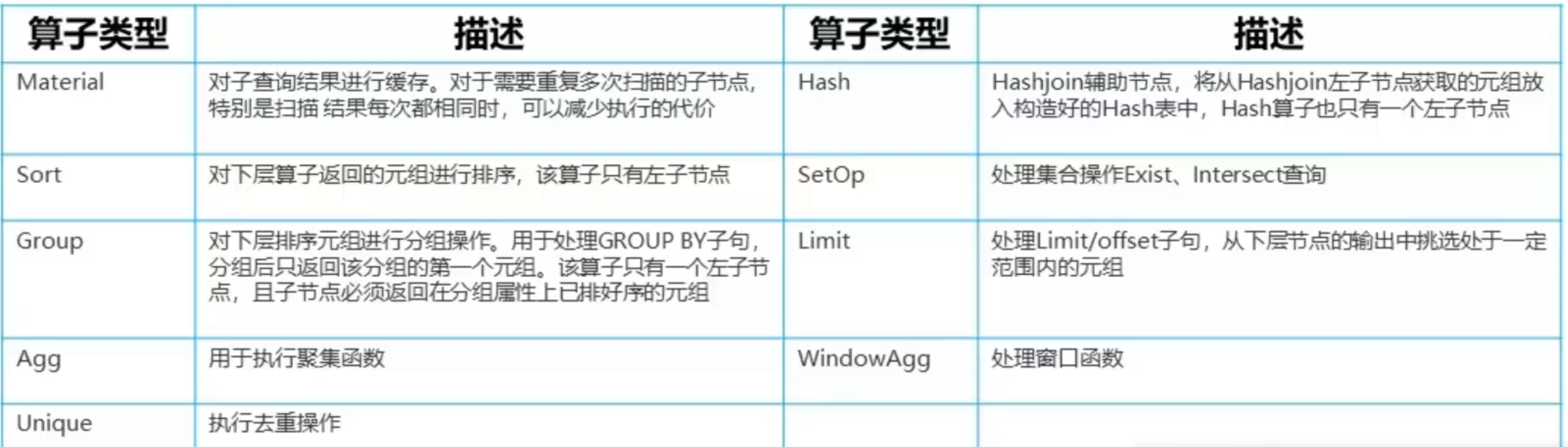
2. 调优流程
- 静态调优
根据硬件资源和客户的业务特征确定集群部署方案,表定义。- 表定义:行列存、复制/哈希分布等0
- 集群部署方案和表定义一旦确定,后续改动的代价会比较大
- 执行态调优(动态调优)根据SQL语句执行的实际情况采取针对性干预SQL执行计划的方式来提升性能
- SQL改写
- GUC参数干预
- Plan Hint
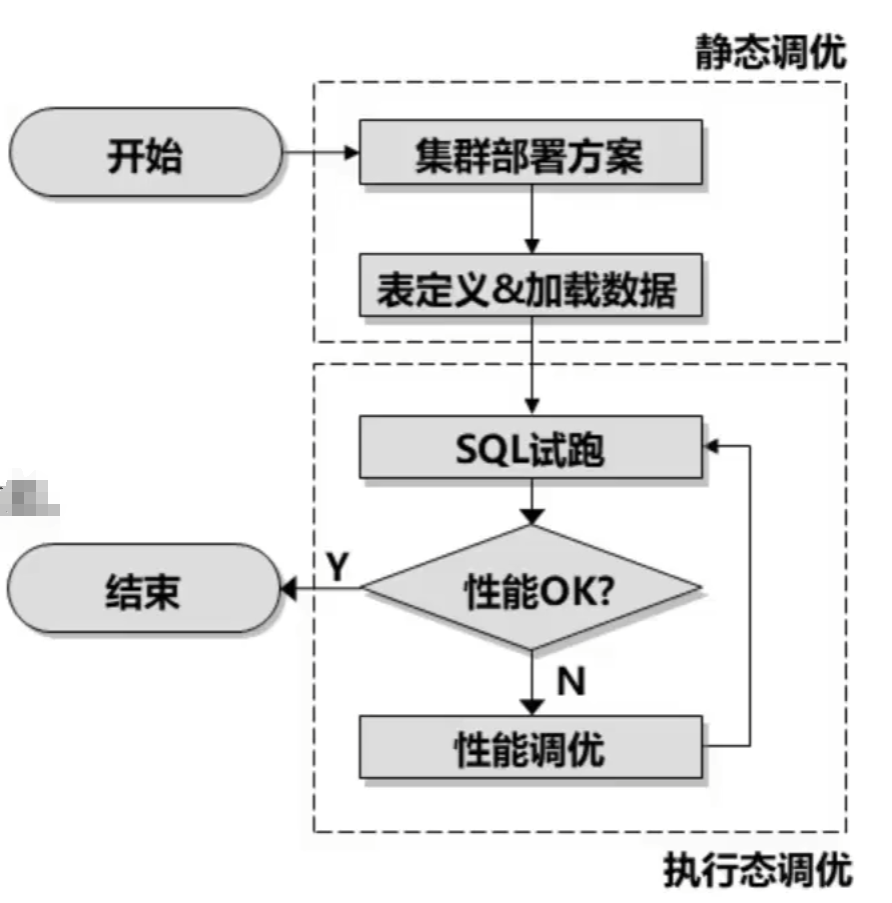
DWS逻辑架构
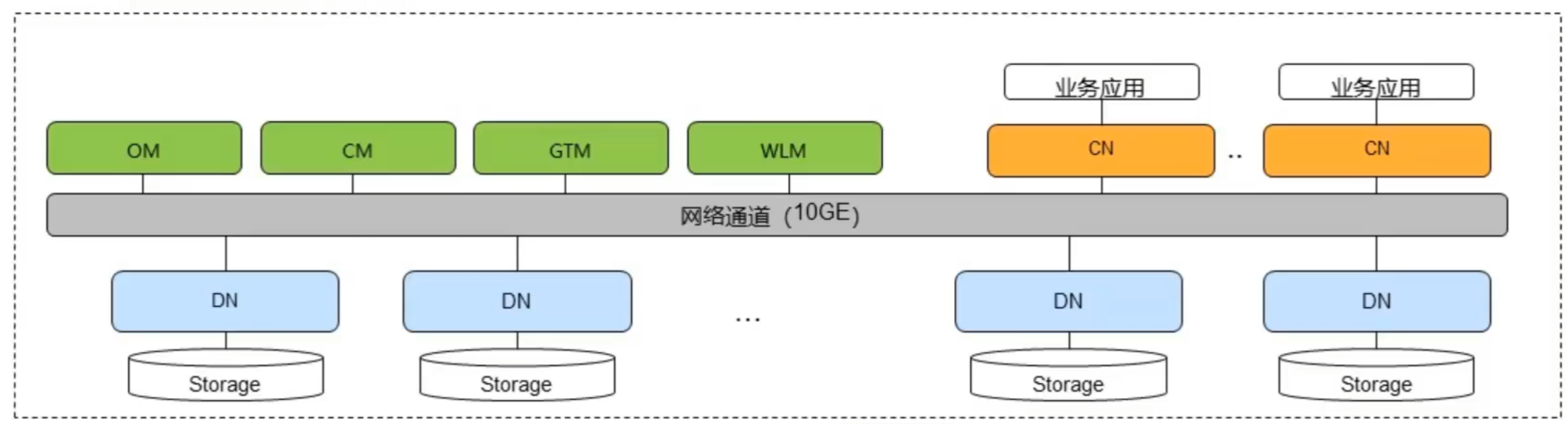
- 运维管理模块,提供日常运维、配置管理的管
理接口、工具。 - 集群管理模块,管理和监控分布式系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行
- 协调节点,负责接收来自应用的访问请求并向客户端返回执行结果
CN负责分解任务,并调度任务分片在各Data Node上并行执行 - 全局事务控制器,负责生成和维护全局事务ID事务快照、时间戳等需要全局唯一的信息。
- 工作负载管理器,控制系统资源的分配,防止过量业务负载对系统的冲击而导致业务拥寒和系统崩溃。
- 数据节点,负责存储业务数据(支持行存、列存、混合存储)、执行数据查询任务以及向CN返回执行结果
服务器的本地存储资源,持久化存储数据
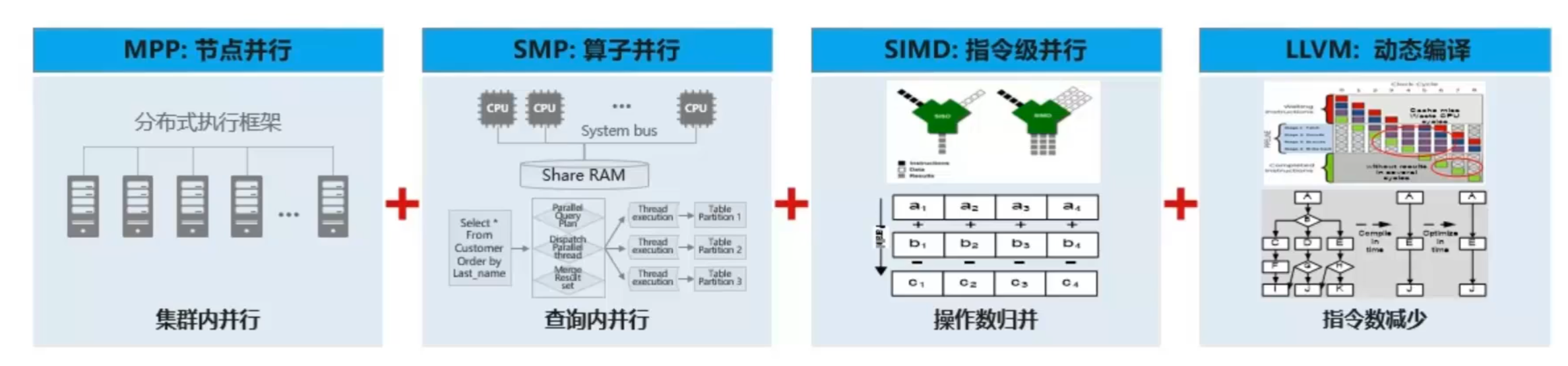
全并行架构,发挥系统极致性能
核心问题:
x86 PC Server集群架构下,单核处理能力有限,如何利用x86多核计算资源,提升集群处理性能:华为鳃鹏众核架构下,如何解决众核、Numa架构资源利用问题;
2.1 分布式优化技术,大幅提升分布式执行性能
核心问题:分布式架构下,单机优化方法无法保证最优计划的生成
问题一: 单机SQL逻辑无法完全实现分布式执行?

核心技术:
- 30+查询重写技术,10+项分布式查询重写,在分布式场景下消除NestLoop和子查询等瓶颈运算
- 查询重写相关专利4篇
问题二: 单机统计信息不能全面反应分布式数据特征
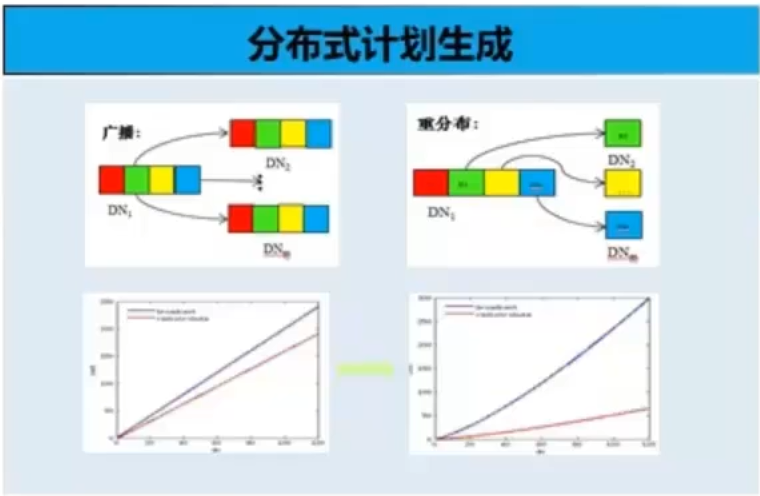
核心技术:
- 单机+全局统计信息收集、自动统计信息收集技
- 基于Poisson的估算模型、全局/单点cost估算模型
- Local+Global结合的数据处理估算模型
问题三: 数据倾斜会造成分布式执行木桶效应
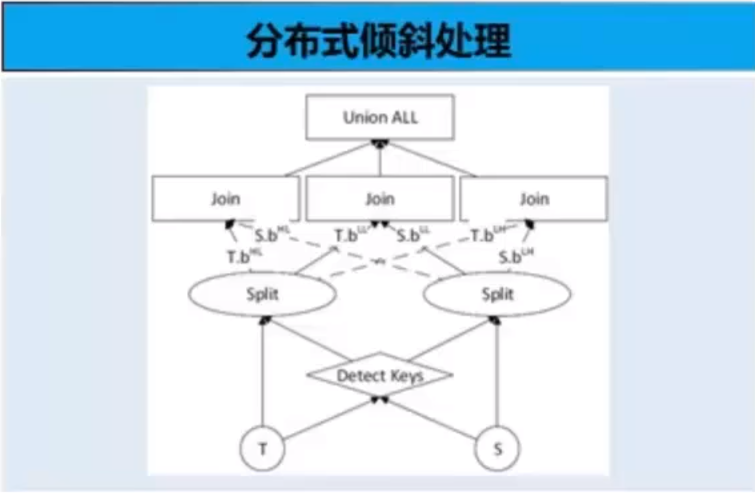
核心技术:
- 静态模型:分布式倾斜估算模型
- 动态模型:RLBT(Runtime Load BalanceTechnology)动态倾斜处理方案
2.2 如何查找待优化SQL
基于topSQL的慢SQL识别
topSQL记录了查询作业运行结束时的资源使用情况(包括内存、下盘、CPU时间、IO等)和运行状态信息(包括报错、终止,异学等)以及性能告警信息

SELECTqueryid,start timeduration,--执行时间warning,--SQL自诊断信息query--SQL语句queryplan--SQL语句简单的explainFROM pgxc wlm session infoWHERE username =edw poc’-- 用户
AND dbname =pluat'-- 数据库AND duration>10000-- 长SQL值,单位msAND start time BETWEEN now0 AND (now0 -interva/ 1 days --SQL时间段ORDER BYduration DESC-- 按照执行时长倒序输出LIMIT100:-- top100
高频SOL: SELECTunique sl id.count() FROM pgxc wlm session imfo WHERE start time >='2023-04-20 15:00:00' and stat time <=2023-04-20 18:00:00GROUPBYunique sql id ORDER BY 2 desc;
CPUSOL: SELECT start time.finish time.block time.usemame.duration.status.abort infosubstr(query.1.100) FROMpgxc wlm session info WHERE start time >=(now0 - interval '1 daty) ORDER BY ax cpu time desc;
不下推SOL:
SELECT start timefinish time,block timeusenameduration.status,abot infosubstr(query,1.100) FROMpgxc wlm session imfo WHERE start time >=(now0 - interval "1 daty) and waming like "%can not be shipped%' ORDER BY duration desc:
复杂SOL:
SELECT nodenamestart time.duration.substring(guery .1.40) as query name.(leneth(query plan) -length(replace(query plan.Streaming,"))/ length(Streaming) as stream count FROM pgxc wlm session info WHERE stream count >= 10 and stat time >= (now0interval '1 day) ORDER BY stream count DESC:
历史SQL:
SELECT start time.duraton.block time.statusspil info.abort info FROMpgxc wlm session imfo WHERE start time between'2023-08-01'and2023-08-08ORDERBYduration DESC
2.3 静态调优
2.3.1审视和修改表定义
-
集群部署有SA协助规划,只关注表定义创建策略
-
数据分布在DN上,好的表定义要求
- 表数据均匀分布在各个DN口
防止单个DN数据过多导致集群有效容量下降 - 表Scan压力均匀分散在各个DN避免单DN的Scan压力过大,形成Scan的单节点瓶颈
- 减少扫描数据量:通过分区机制实现
- 尽量减少随机IO:通过聚族/局部聚族可以实现这
- 减小网络压力

- 表数据均匀分布在各个DN口
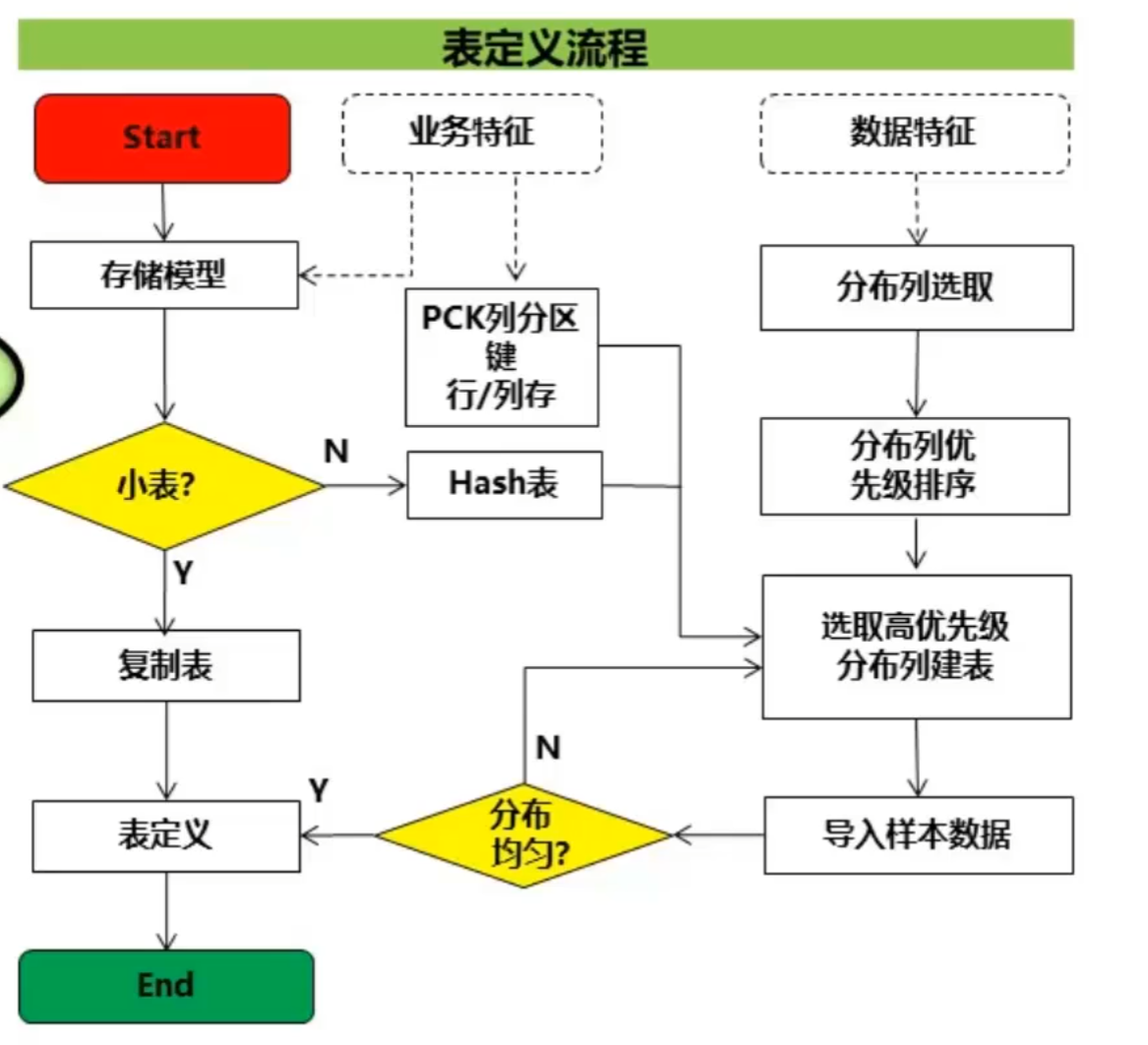
2.3.2选择存储类型
- 存储类型的重要性
- 存储类型决定存储格式,进而影响I/O操作行为
- 客户业务属性决定表的存储类型
- 行列存选择依据

2.3.3 分布列-简述
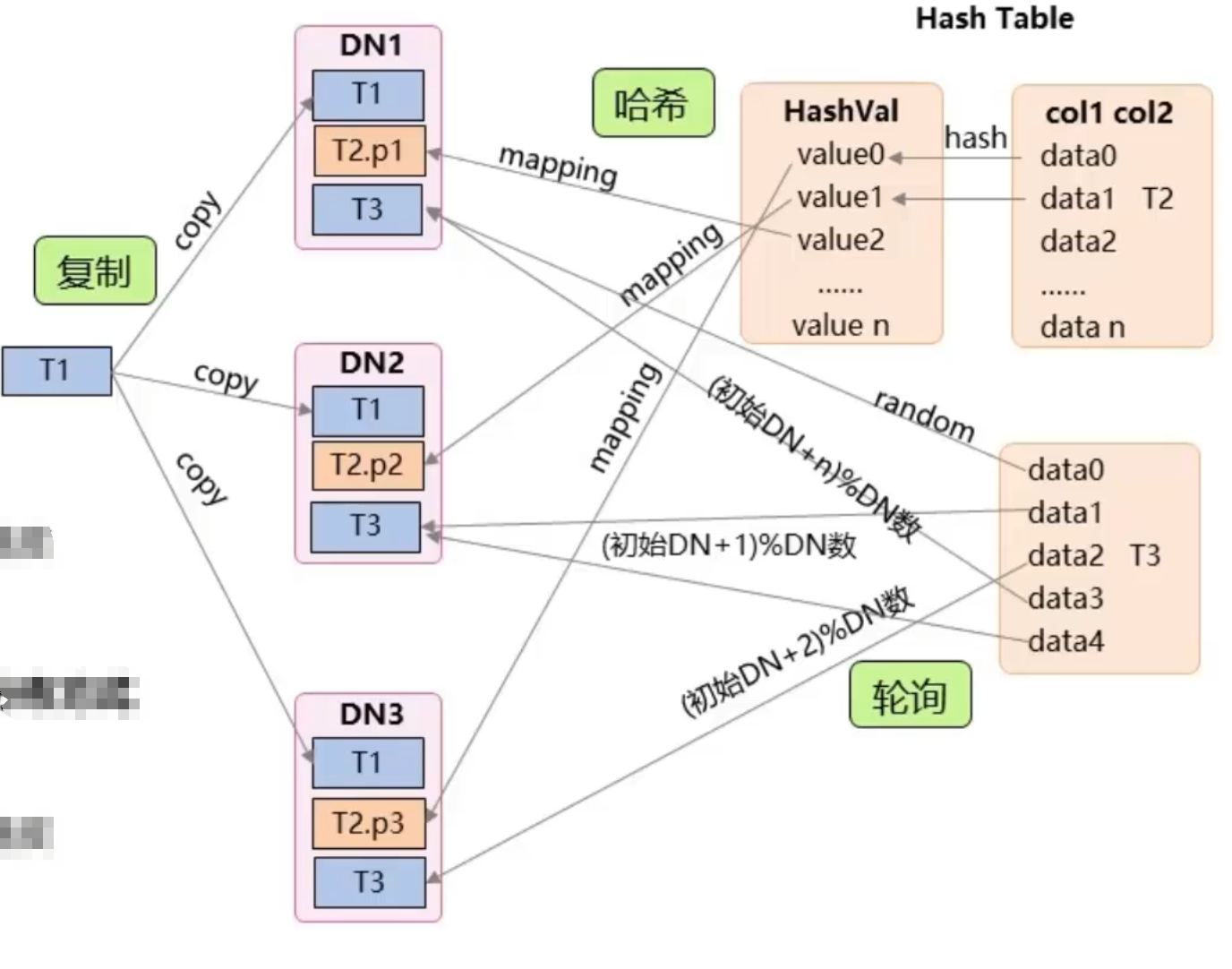
- 复制(Replication)
- 集群中每个DN实例上都有一份全量表数据
- Join操作可减小重分布造成的网络开销
- 存在数据冗余
- 适用于小表、维表
- 哈希(Hash)-- 8.1.3之前默认分布方式
- 数据通过Hash方式散列到集群的所有DN实例
- 读写数据可充分利用各个节点O资源,提升读写速度
- 适用于数据量大的表
- 轮询(RoundRobin)-- 8.1.3开始之后默认分布方式
- 数据通过轮询方式发放到集群内所有DN实例
- 读写数据可充分利用各个节点IO资源,提升读写速度
- 适用于数据量大的表,且各列都有严重倾斜的表
2.3.4 分布列- 选取原则
- 选择分布列的基本原则
- 各个DN列值应比较离散,以便数据能够均匀分布到通常选择表的主键为分布列
示例:人员信息表,选择身份证号作为分布列 - 尽量不要选取存在常量等值过滤条件,避免DN剪枝后Scan集中到一个DNcjk的列zqdh 存在常量的约束(例如zqdh=000001),
- 示例:如果表dwcjk相关查询中经常出现不用zqdh做分布列
- 选择查询中的连接条件为分布列,以便Join能够推到DN中执行,且减少DN间的通信数据量布方式,无法确定时可以选择roundbobin分布
- 根据上述原则尽量根据业务特征选择hash分布
- 各个DN列值应比较离散,以便数据能够均匀分布到通常选择表的主键为分布列
2.3.5 分布列-倾斜分析和分布调整
-
判断数据是否存在存储倾斜的方法: table distribution函数
- 不同DN的数据量:相差5%以上即可视为倾斜:相差10%以上建议调整分布列
-
在线判定列是否倾斜: table skewness函数


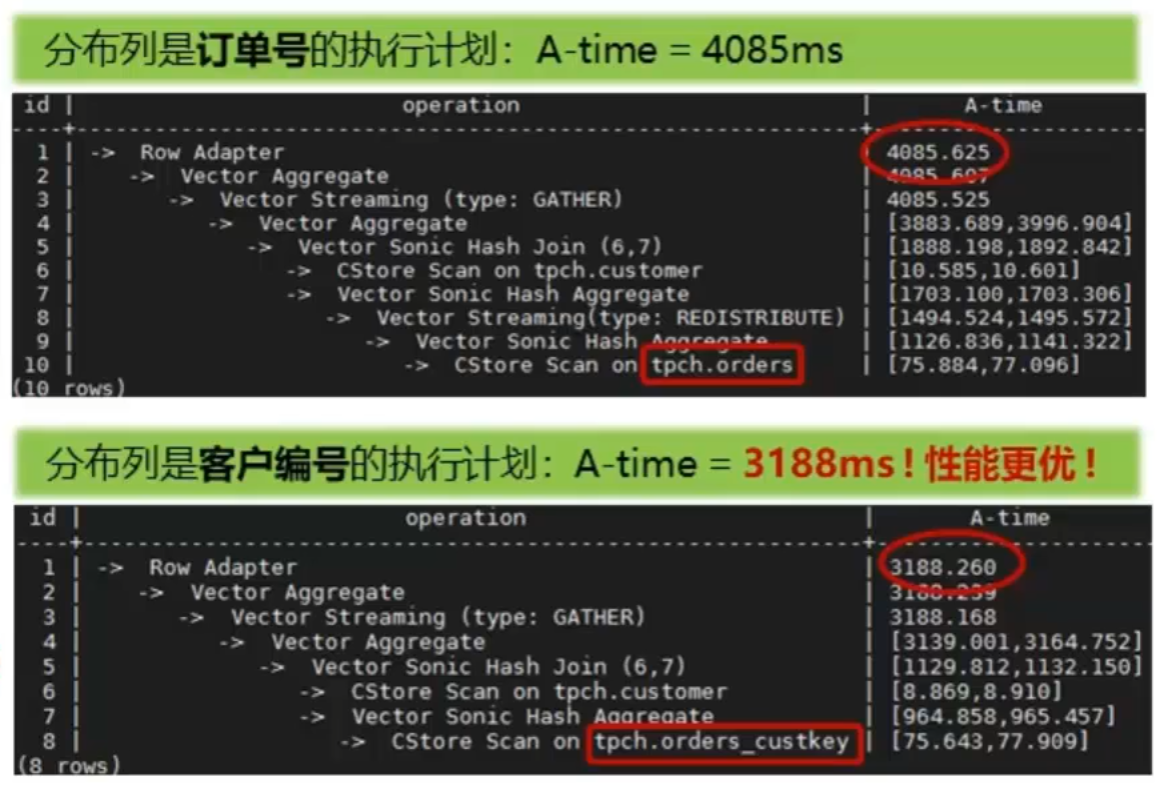
2.3.6 选择分布列 典型案例
-
常见场景
- a)原始表定义存在数据倾斜,需要通过调整分布列达到数据分区均衡的目标
- b)把表分布列修改为关联列,达到性能加速的目的
SELECT count(distinctc custkey)FROM customerWHERE c custkey IN (SELECT DISTINCT o custkeyFROM orders custkey #原orders表的分布列为订单号o orderkeyorders custkey表为调整分布列为客户编号o custkeyALTER TABLE orders DISTRIBUTE BY HASH(o custkey)
2.3.7 局部聚族-简述
- 局部聚族(Partial Cluster Key,简称PCK)
- 列存储下一种通过min/max稀疏索引实现基表快速扫描的一种索引技术
- 适用场景
- 业务特征:大表大批量数据导入,每次导入数据量远大于DN数*6W
- 基表存在大量形如col op Const约束,其中col为列名,const为常量值,op为操作符 =、>、>=
- 选用选择度比较高的简单表达式的列上建pck
- 使用约束
- 列存表,一个表只能创建一个PCK
- 适用数据类型有整型、时间类型、字符串类型
- 对于字符串类型,如果当前库的collate不为C,则只对表达式col=Const起大加速查询的效果
- 使用方法
- 创建表时指定PCK约束,或者ALTER TABLE语法增加PCK约束(只对后续导入数据生效)
2.3.8 局部聚簇- 优化原理
优化原理:入库时候进行局部排序换查询性能
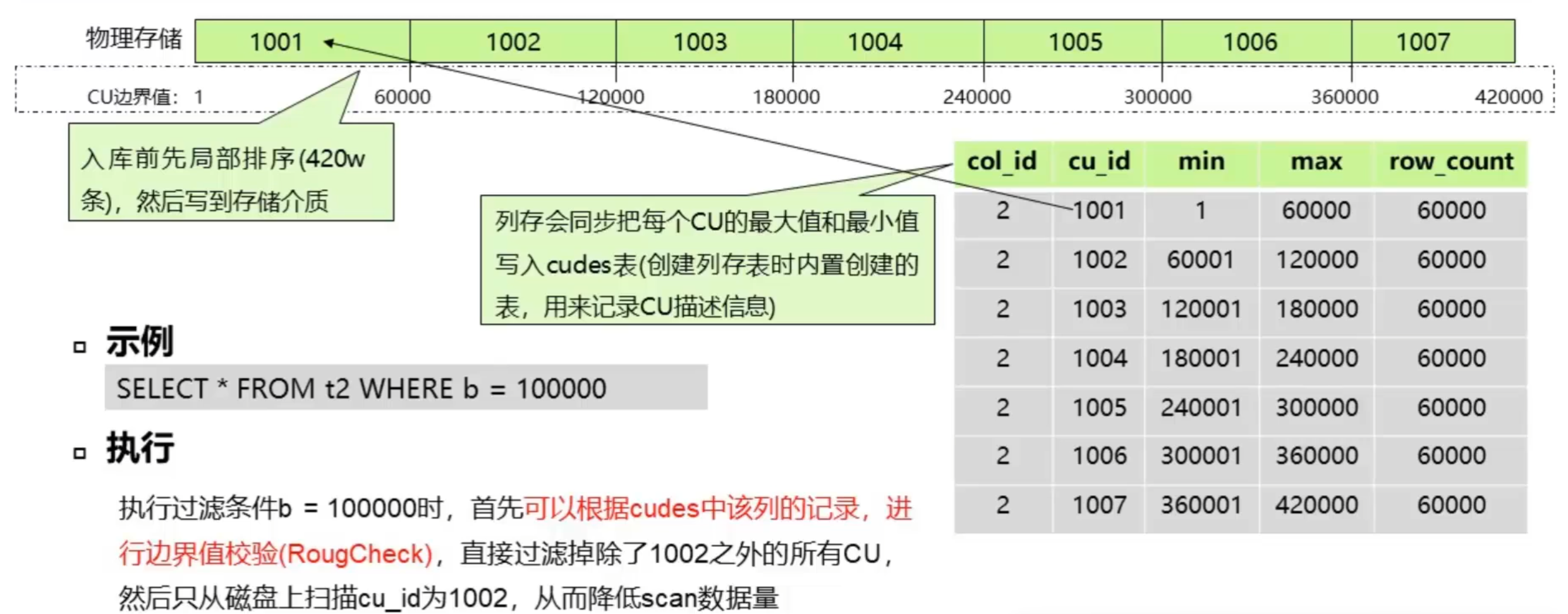
2.3.9 局部聚族-典型案例
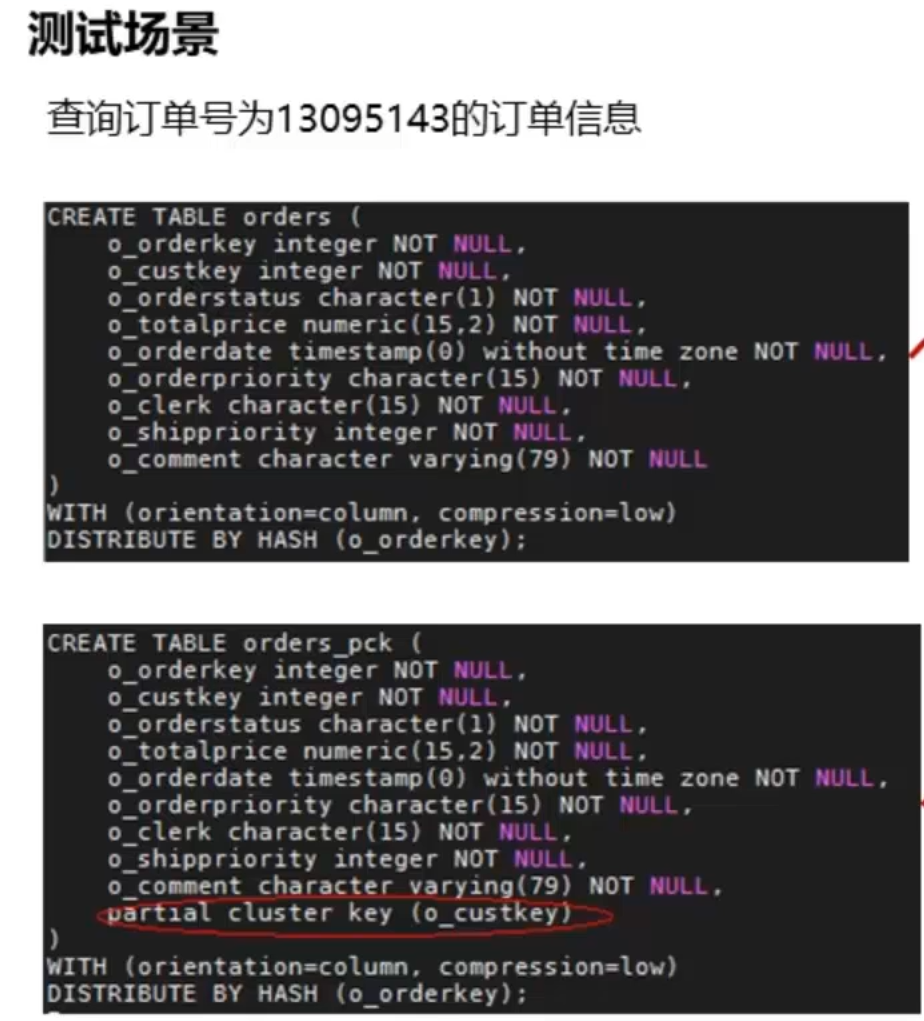
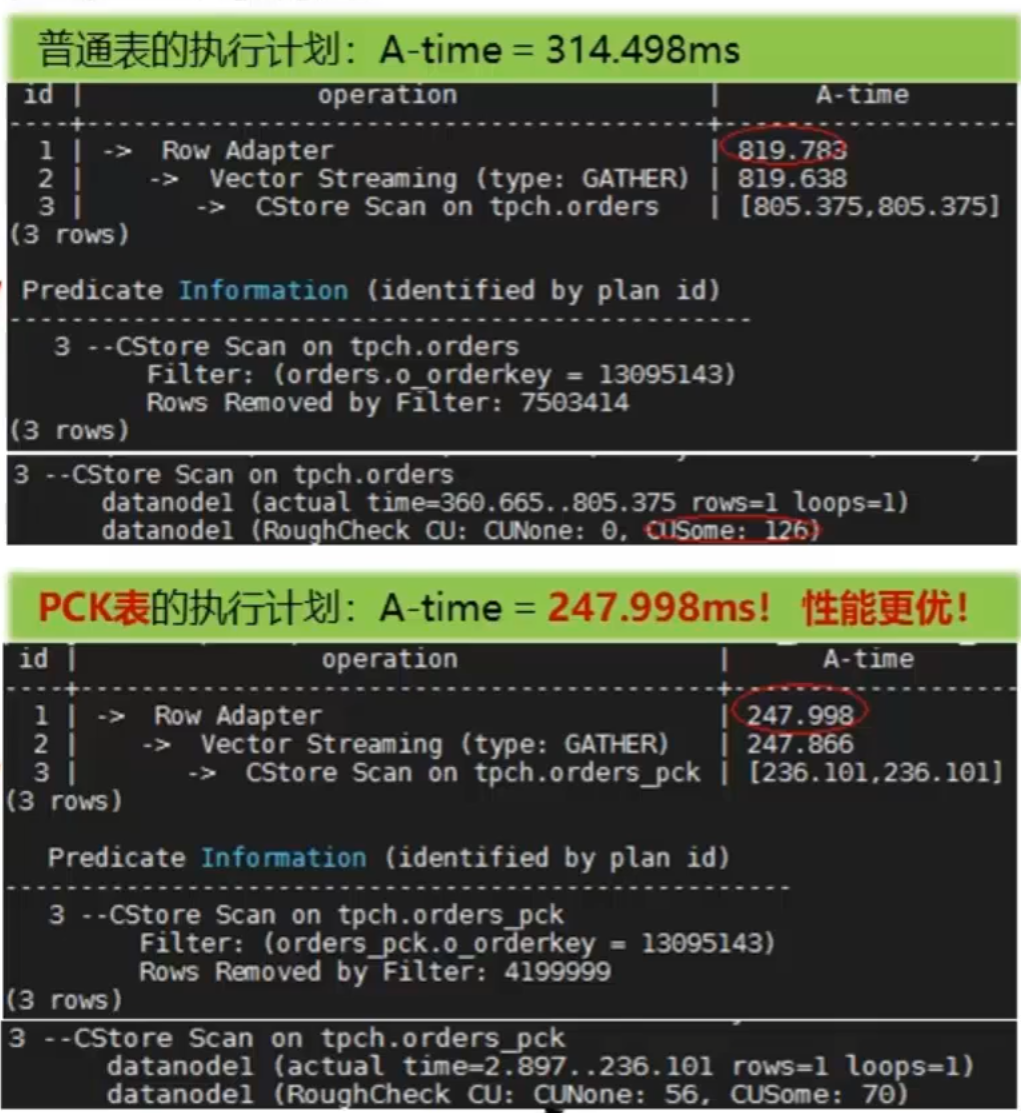
2.4 总结
本节主要从表定义角度,介绍静态调优的几种常用方法,从而指导用户根据业务场景正确选择表的存储类型、分布方式和分布列,合理使用局部聚簇、分区表来设计和定义表,提高SQL语句的查询性能
3. 动态调优
3.1 概述
- 概述
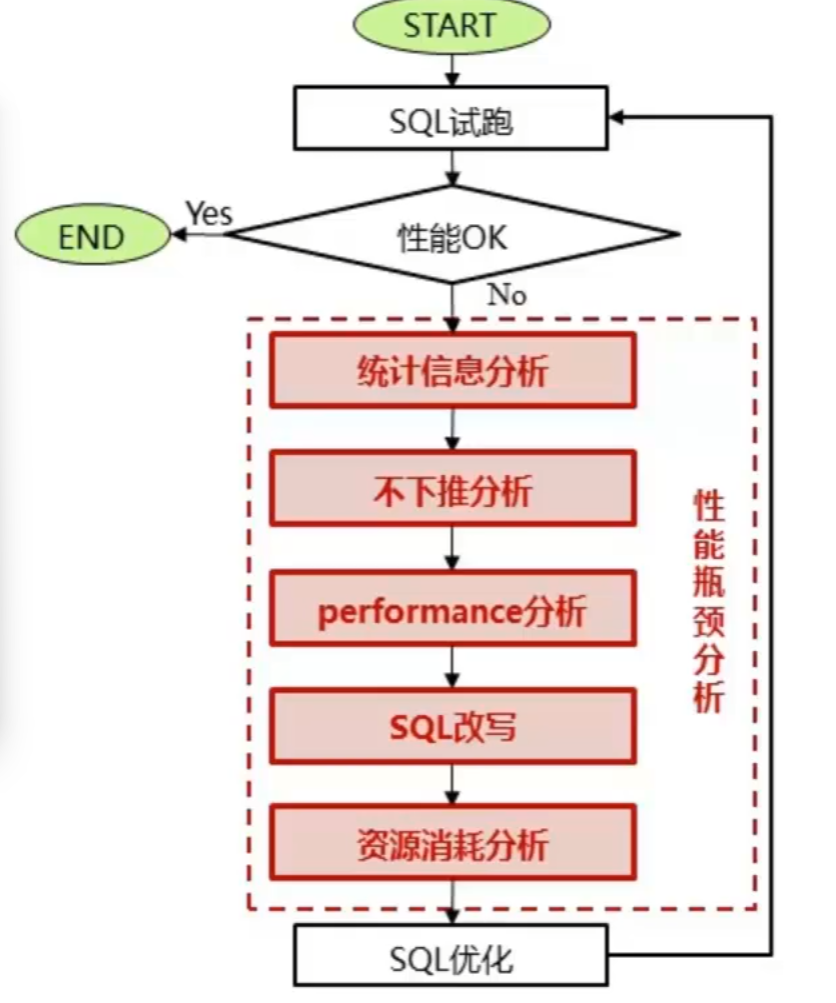
动态调优,即执行态调优,是一个不断分析与尝试的过程
首先,试跑Query;然后,判断性能是否满足客户需求;如果不满足客户需求,则需要进一步分析性能瓶颈点获取性能瓶颈点之后进行针对性优化,重新试跑,一直到满足性能目标。
- 基本步骤
判断查询相关表是否已收集统计信息
判断查询语句是否下推
收集Perfromance信息进行性能分析,并做针对性优化
SQL改写优化
3.2动态调优
3.2.1 统计信息-简述
-
可用的统计信息有哪些?
-
统计信息(表数据特征)
- 表的元组数、字段宽度、NULL记录比率、DISTINCT值、MCV值(Most CommonValue)HB
- 值(直方图,数据分布概率区间)
-
优化器 (基于代价的优化(Cost-Based Optimization,简称CBO
- 数据库根据大量表数据特征,结合代价计算模型,通过代价估算输出估算的最优执行计划
- 统计信息是查询优化的核心输入,准确的统计信息可以帮助优化器选择最合适的查询计划
-
-
统计信息如何收集?
- 使用ANALYZE语法收集整个表或表的若干列的统计信息
-
如何操作
- 大批量数据导入/更新/删除之后及时analyze
3.2.2统计信息-典型案例
-
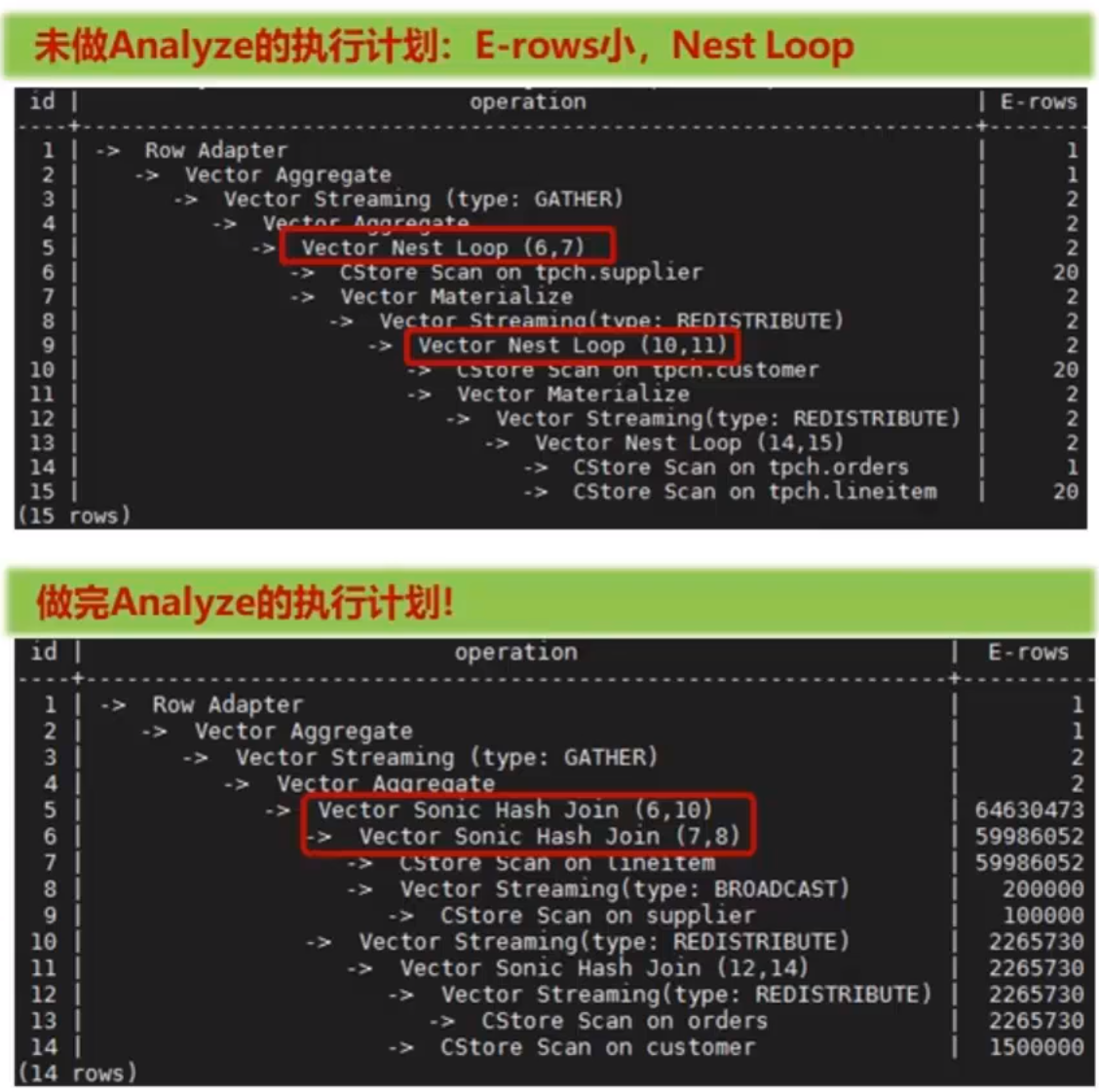
收集统计信息前后执行计划对比分析
- E-rows:
没有收集统计信息的计划中,估计值E-rows比实际值小
- 执行计划:
没有收集统计信息的计划中,出现两个低效的Nest Loop算子
-
示例:
查询所有供货商在1994年1月1日起的1年间为公司带来的总收入
SELECT
sum(l extendedprice * (1 - l discount)) AS revenueFROM customer, orders, lineitem, supplierWHERE c custkey = o custkeyAND l orderkey = o orderkeyAND I suppkey = s suppkeyAND o orderdate >=1994-01-01'::dateAND o orderdate <11994-01-01'::date + interval '1 year'
3.2.3 不下推分析 -计划类型
-
并行计算能力是GaussDB(DWS)的性能优势
-
优化器在分布式框架下有三种执行规划策
-
下推语句计划
CN发送查询语句到DN直接执行,执行结果返回给CN
-
分布式计划
CN生成计划树,发送计划树给DN执行
DN执行完后,将结果返回给CN -
不下推计划: CN承载大量计算任务,导致性能劣化!
优化器将部分查询(多为基表扫描语句)
-
-
常见的不下推因素
- 含有shippable属性为false的函数的语句不下推
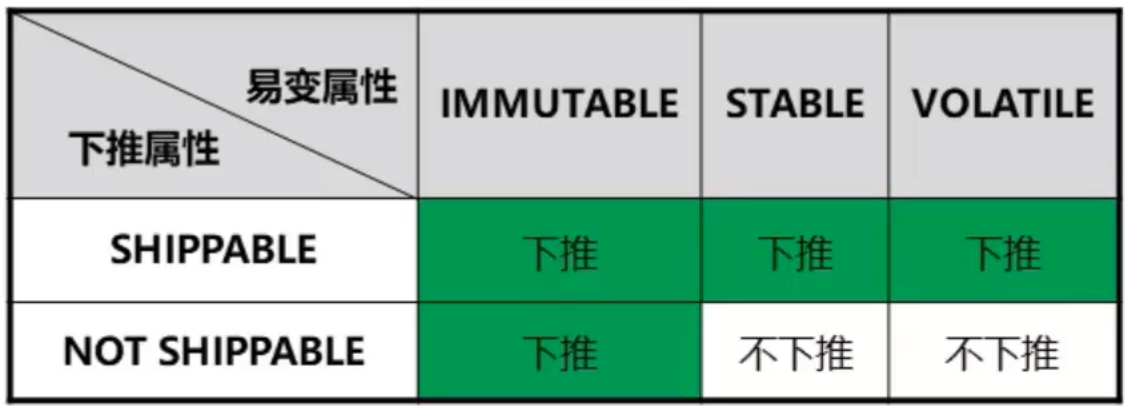
3.2.4 不下推分析-函数易变属性
- 函数下推行为的分析
- 函数的易变属性可分为三种,在创建函数时如果不指定函数易变属性,默认为VOLATILE
- IMMUTABLE: 相同的入参值,总是返回相同的结果。如,pg catalog.trunc(numeric)
- STABLE:相同的入参值,同一次表扫描中,函数返回值不变,但在不同SQL语句中函数返回值可能发生变化。
- VOLATILE:相同的入参值,函数值随时可能返回不同的结果,即便是同在一次表扫描内
- 函数定义时可指定函数下推属性为SHIPPABLE,默认为NOT SHIPPABLE,即调用函数的SQL语句不下推。
- 函数的下推行为由其易变属性和下推属性共同决定
- 函数的易变属性可分为三种,在创建函数时如果不指定函数易变属性,默认为VOLATILE

3.2.5 Performance分析
- Explain Performance: 收集Query的执行信息+分析可能的性能问题+针对性优化
- 重点关注:耗时占整体执行时间高的算子
- 重要执行信息: DataNode lnformation、Memory Information、Targetlist Information
- 常见算子的瓶颈及优化策略
- Scan性能瓶颈
- 基表扫描元组数过多: 增加索引、使用PCK、使用分区
- 数据在各个DN分布不均衡: 调整分布列方式
- Join性能瓶颈
- Join方式选择不当: 增加索引、使用Plan Hint
- Join内外表选择不当: 使用PIanHint、改写SQL
- Scan性能瓶颈
3.2.6 Scan性能优化
- Scan性能提升策略
- 减少实际IO
- 标准点查场景: 增加索引; 使用PCK(列存表
- 减少实际IO

3.2.7 Join性能优化- Join类型
表连接(Join): 根据特定规则从两个其他表(真实表或生成表)中派生出结果集
join语法
T1 Join type T2 [join condition]
join类型
语法层支持: 内连接(lnner Join)、外连接(Outer Jin) 和交叉连接(或笛卡尔积,CrossJoin)
T1( [INNER]
T1
[INNER]
TI NATURAL
( LEFT
RIGHT
( LEFT I RIGHT
[INNER]
( LEET
FULL
FULL 1
RIGHT
[OUTER1
[OUTER]
JOINT2ON boolean expression
T2USING ( join column list )
JOIN
FULL 1
OUTER] JOIN T2
3.2.8 Join性能优化-优化策略
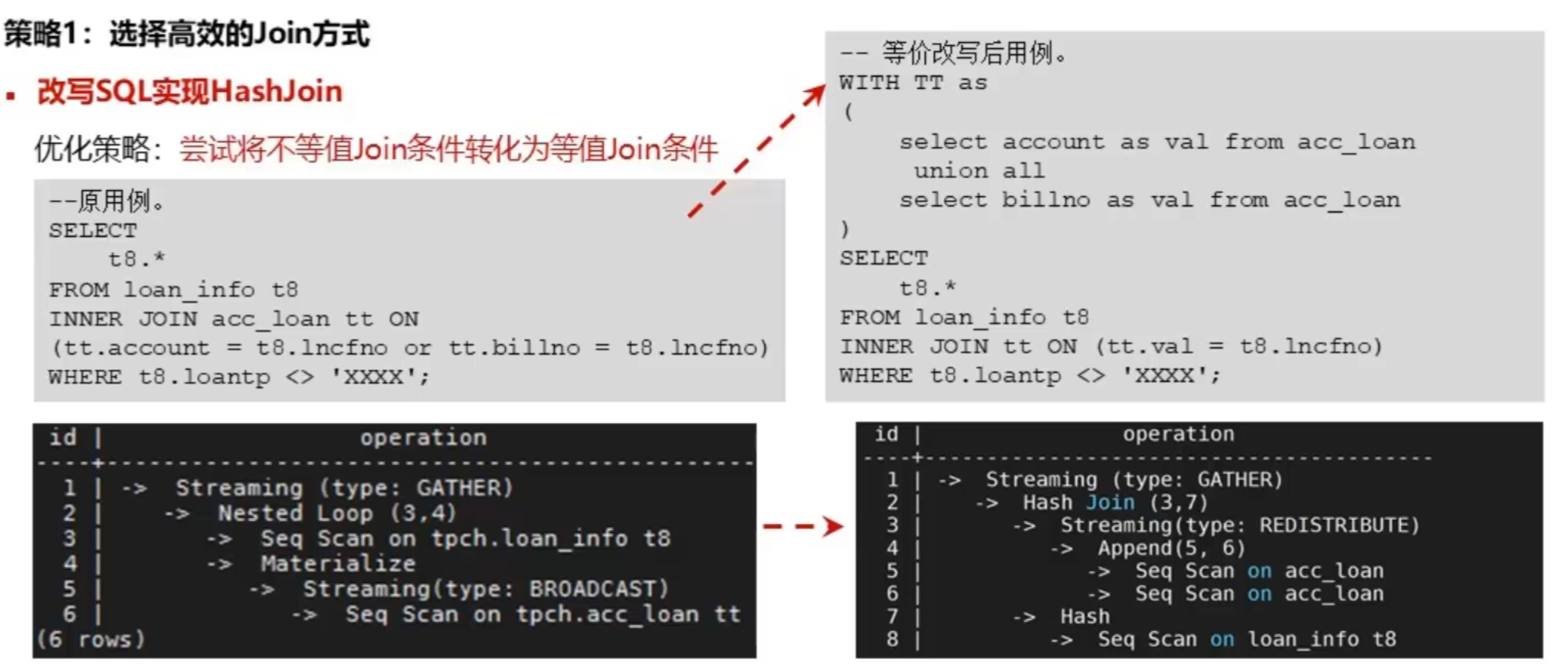
策略1:选择高效的Join方式
改写SQL实现HashJoin
优化策略: 尝试将不等值Join条件转化为等值Join条件
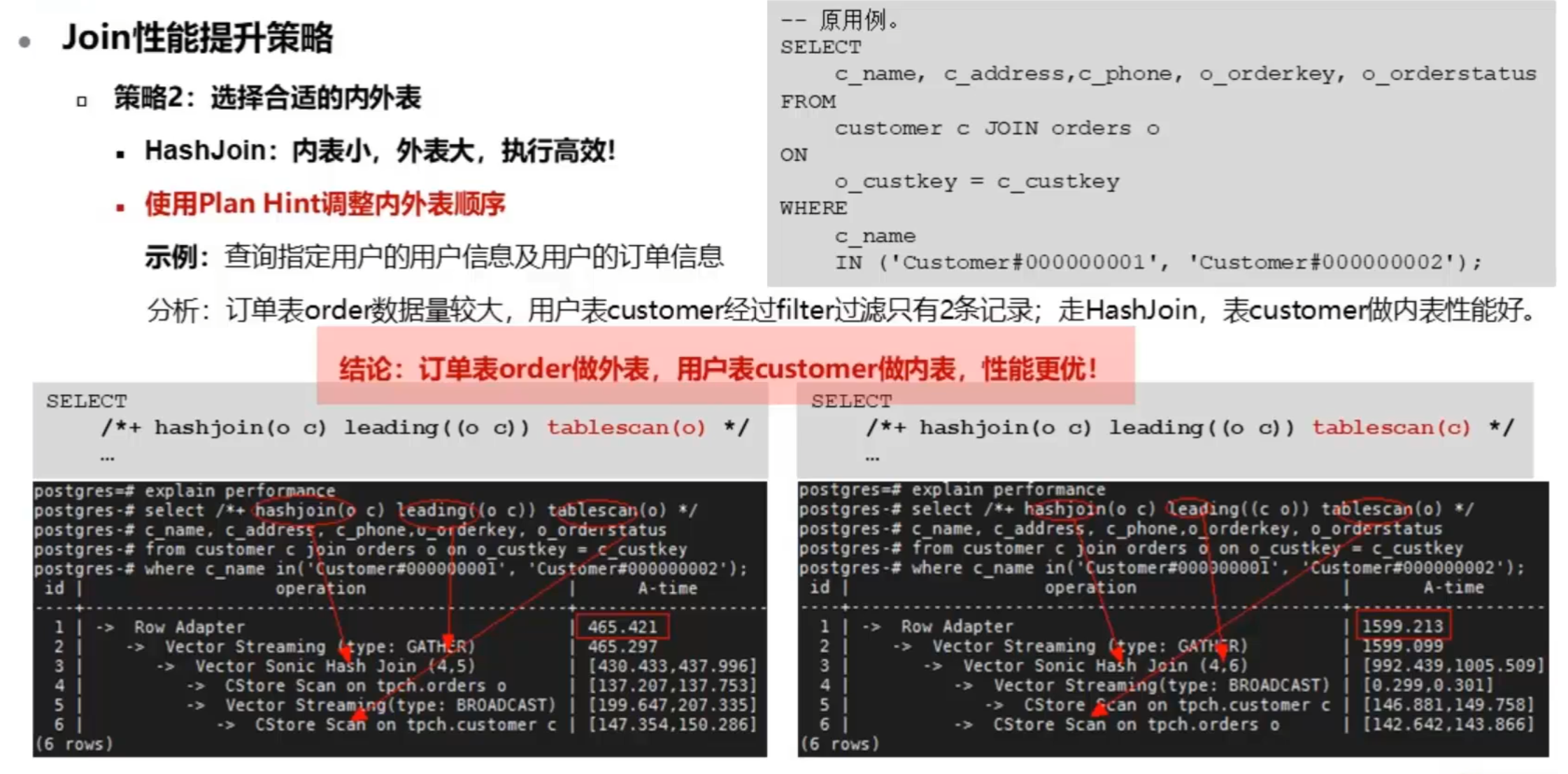
策略2:选择合适的内外表
HashJoin:内表小,外表大,执行高效!
使用Plan Hint调整内外表顺序
3.3 总结
本节简要介绍动态调优的基本流程,常用的统计信息及其收集方法,如何根据执行信息分析SQL语句的性能瓶颈,并着重介绍因计划不下推造成性能问题的典型场景码优化等收
4. 总结
在大数据时代,数据量剧增,查询效率成为关键。
GaussDBDWS作为高效的数据仓库解决方案,其查询优化技术是核心。首先,优化器是数据库查询优化的核心组件,分为基于规则的优化器和基于成本的优化器。前者根据硬编码规则选取最优执行计划,稳定但要求高;后者则依赖统计信息和代价模型,能自动适应数据变化,选择最优执行计划。其次,执行计划是查询执行过程的描述,用于分析和调优。最后,调优技术包括静态和动态调优,前者针对已知问题优化,后者则实时调整。此外,分布式优化技术也能大幅提升分布式执行性能。
总之,要提高GaussDBDWS的数据仓库性能和响应速度,需关注表结构设计、SQL优化、慢SQL和高频SQL查找等关键环节。准确统计信息是优化器做出好决策的前提。深入理解执行计划和优化器原理,结合实际场景灵活运用调优技术,是提升大数据查询效率的关键。

- 点赞
- 收藏
- 关注作者
评论(0)