【愚公系列】2023年12月 数据结构(十三)-堆

🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,阿里云专家博主,腾讯云优秀博主,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2022年CSDN博客之星TOP2,2022年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
数据结构是计算机科学中的一个重要概念,它描述了数据之间的组织方式和关系,以及对这些数据的访问和操作。常见的数据结构有:数组、链表、栈、队列、哈希表、树、堆和图。
-
数组(Array):是一种线性数据结构,它将一组具有相同类型的数据元素存储在一起,并为每个元素分配一个唯一的索引。数组的特点是具有随机访问的能力。
-
链表(Linked List):也是一种线性数据结构,它由一系列的节点组成,每个节点包含数据和指向下一个节点的引用。链表的特点是可以动态地插入或删除节点,但访问某个节点时需要从头开始遍历。
-
栈(Stack):是一种后进先出(LIFO)的数据结构,它只能在栈顶进行插入和删除操作。栈通常用于实现递归算法、表达式求值和内存管理等场景。
-
队列(Queue):是一种先进先出(FIFO)的数据结构,它可以在队尾插入元素,在队头删除元素。队列通常用于数据的缓存、消息队列和网络通信等场景。
-
哈希表(Hash Table):也称为散列表,它是一种根据关键字直接访问数据的数据结构。哈希表通常由数组和散列函数组成,可以在常数时间内进行插入、删除和查找操作。
-
树(Tree):是一种非线性数据结构,它由一系列的节点组成,每个节点可以有若干个子节点。树的特点是可以动态地插入或删除节点,常见的树结构包括二叉树、平衡树和搜索树等。
-
堆(Heap):是一种特殊的树结构,它通常用于实现优先队列和堆排序等算法。堆分为最大堆和最小堆,最大堆的每个节点的值都大于等于其子节点的值,最小堆则相反。
-
图(Graph):是一种由节点和边组成的非线性数据结构,它可以用来表示各种实体之间的关系,如社交网络、路线图和电路图等。图的遍历和最短路径算法是常见的图算法。
🚀一、堆
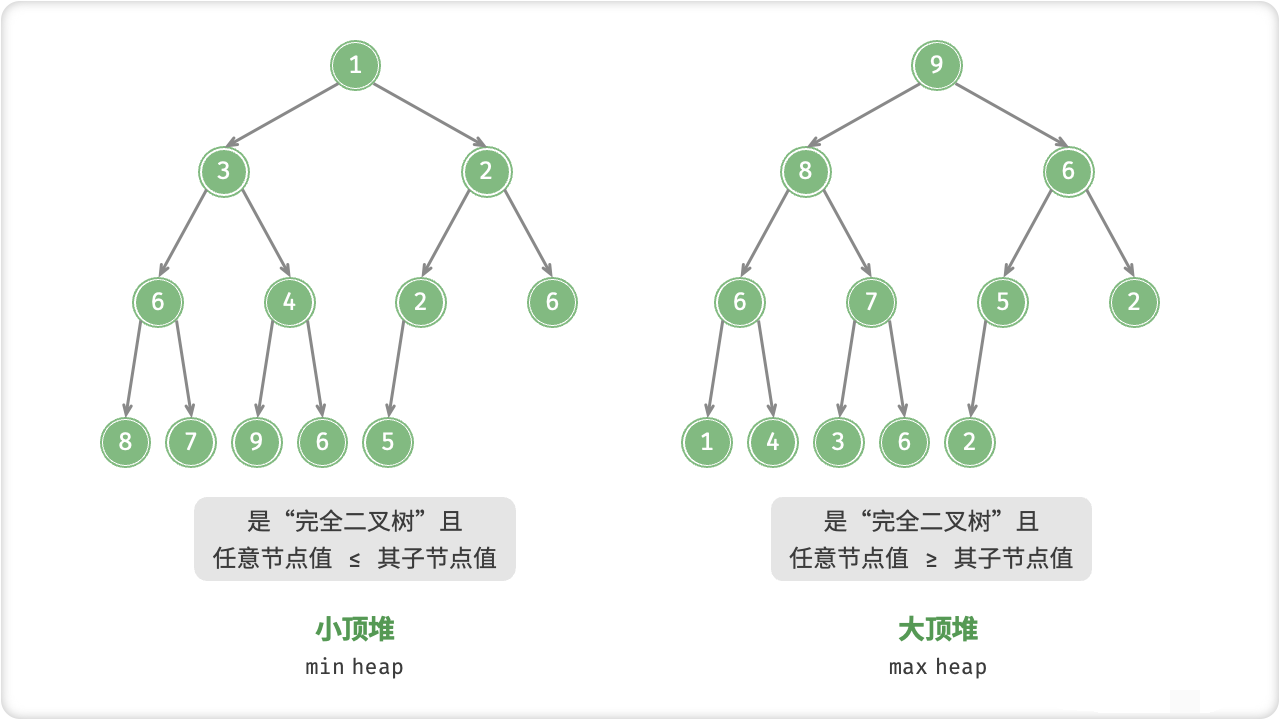
🔎1.基本思想
堆是一种基于完全二叉树的数据结构,它分为大根堆和小根堆两种,基本思想如下:
-
大根堆:每个节点的值都大于或等于其左右子节点的值,最大值在堆的根节点上。
-
小根堆:每个节点的值都小于或等于其左右子节点的值,最小值在堆的根节点上。
-
堆的插入:将元素插入堆的末尾,然后调整堆结构,使其保持堆的性质。
-
堆的删除:将堆的根节点删除,然后将堆的末尾节点移动到根节点,然后再次调整堆结构。
-
堆排序:将待排序的数组建立成堆,然后重复执行删除堆顶元素并调整堆结构的过程,直到堆为空,就可以得到一个有序的序列。
-
堆的应用:堆可以用来解决一些优先级相关的问题,比如优先级队列、求TopK等。
🔎2.堆的常用操作
public class heap {
public void testPush(PriorityQueue<int, int> heap, int val) {
heap.Enqueue(val, val); // 元素入堆
Console.WriteLine($"\n元素 {val} 入堆后\n");
PrintUtil.PrintHeap(heap);
}
public void testPop(PriorityQueue<int, int> heap) {
int val = heap.Dequeue(); // 堆顶元素出堆
Console.WriteLine($"\n堆顶元素 {val} 出堆后\n");
PrintUtil.PrintHeap(heap);
}
[Test]
public void Test() {
/* 初始化堆 */
// 初始化小顶堆
PriorityQueue<int, int> minHeap = new PriorityQueue<int, int>();
// 初始化大顶堆(使用 lambda 表达式修改 Comparator 即可)
PriorityQueue<int, int> maxHeap = new PriorityQueue<int, int>(Comparer<int>.Create((x, y) => y - x));
Console.WriteLine("以下测试样例为大顶堆");
/* 元素入堆 */
testPush(maxHeap, 1);
testPush(maxHeap, 3);
testPush(maxHeap, 2);
testPush(maxHeap, 5);
testPush(maxHeap, 4);
/* 获取堆顶元素 */
int peek = maxHeap.Peek();
Console.WriteLine($"堆顶元素为 {peek}");
/* 堆顶元素出堆 */
// 出堆元素会形成一个从大到小的序列
testPop(maxHeap);
testPop(maxHeap);
testPop(maxHeap);
testPop(maxHeap);
testPop(maxHeap);
/* 获取堆大小 */
int size = maxHeap.Count;
Console.WriteLine($"堆元素数量为 {size}");
/* 判断堆是否为空 */
bool isEmpty = maxHeap.Count == 0;
Console.WriteLine($"堆是否为空 {isEmpty}");
/* 输入列表并建堆 */
var list = new int[] { 1, 3, 2, 5, 4 };
minHeap = new PriorityQueue<int, int>(list.Select(x => (x, x)));
Console.WriteLine("输入列表并建立小顶堆后");
PrintUtil.PrintHeap(minHeap);
}
}
🔎3.堆的实现
/* 大顶堆 */
class MaxHeap {
// 使用列表而非数组,这样无须考虑扩容问题
private readonly List<int> maxHeap;
/* 构造函数,建立空堆 */
public MaxHeap() {
maxHeap = new List<int>();
}
/* 构造函数,根据输入列表建堆 */
public MaxHeap(IEnumerable<int> nums) {
// 将列表元素原封不动添加进堆
maxHeap = new List<int>(nums);
// 堆化除叶节点以外的其他所有节点
var size = parent(this.size() - 1);
for (int i = size; i >= 0; i--) {
siftDown(i);
}
}
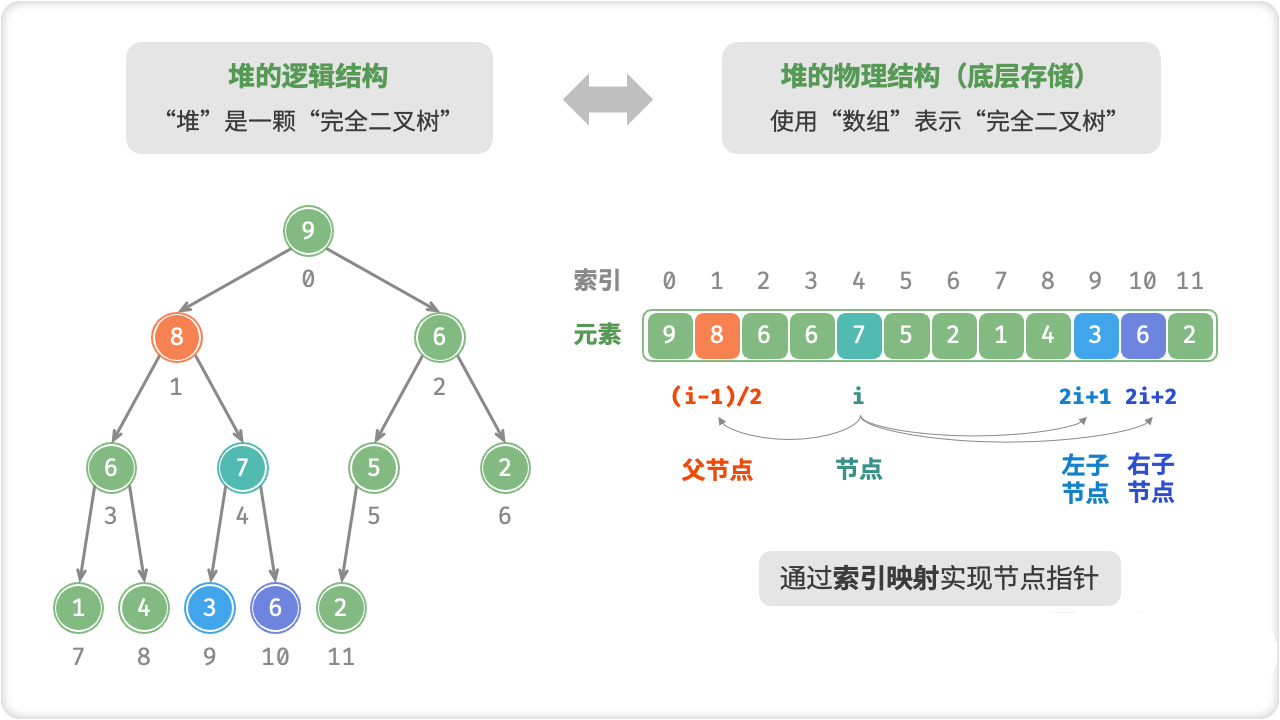
/* 获取左子节点索引 */
int left(int i) {
return 2 * i + 1;
}
/* 获取右子节点索引 */
int right(int i) {
return 2 * i + 2;
}
/* 获取父节点索引 */
int parent(int i) {
return (i - 1) / 2; // 向下整除
}
/* 访问堆顶元素 */
public int peek() {
return maxHeap[0];
}
/* 元素入堆 */
public void push(int val) {
// 添加节点
maxHeap.Add(val);
// 从底至顶堆化
siftUp(size() - 1);
}
/* 获取堆大小 */
public int size() {
return maxHeap.Count;
}
/* 判断堆是否为空 */
public bool isEmpty() {
return size() == 0;
}
/* 从节点 i 开始,从底至顶堆化 */
void siftUp(int i) {
while (true) {
// 获取节点 i 的父节点
int p = parent(i);
// 若“越过根节点”或“节点无须修复”,则结束堆化
if (p < 0 || maxHeap[i] <= maxHeap[p])
break;
// 交换两节点
swap(i, p);
// 循环向上堆化
i = p;
}
}
/* 元素出堆 */
public int pop() {
// 判空处理
if (isEmpty())
throw new IndexOutOfRangeException();
// 交换根节点与最右叶节点(即交换首元素与尾元素)
swap(0, size() - 1);
// 删除节点
int val = maxHeap.Last();
maxHeap.RemoveAt(size() - 1);
// 从顶至底堆化
siftDown(0);
// 返回堆顶元素
return val;
}
/* 从节点 i 开始,从顶至底堆化 */
void siftDown(int i) {
while (true) {
// 判断节点 i, l, r 中值最大的节点,记为 ma
int l = left(i), r = right(i), ma = i;
if (l < size() && maxHeap[l] > maxHeap[ma])
ma = l;
if (r < size() && maxHeap[r] > maxHeap[ma])
ma = r;
// 若“节点 i 最大”或“越过叶节点”,则结束堆化
if (ma == i) break;
// 交换两节点
swap(i, ma);
// 循环向下堆化
i = ma;
}
}
/* 交换元素 */
void swap(int i, int p) {
(maxHeap[i], maxHeap[p]) = (maxHeap[p], maxHeap[i]);
}
/* 打印堆(二叉树) */
public void print() {
var queue = new Queue<int>(maxHeap);
PrintUtil.PrintHeap(queue);
}
}
public class my_heap {
[Test]
public void Test() {
/* 初始化大顶堆 */
MaxHeap maxHeap = new MaxHeap(new int[] { 9, 8, 6, 6, 7, 5, 2, 1, 4, 3, 6, 2 });
Console.WriteLine("\n输入列表并建堆后");
maxHeap.print();
/* 获取堆顶元素 */
int peek = maxHeap.peek();
Console.WriteLine($"堆顶元素为 {peek}");
/* 元素入堆 */
int val = 7;
maxHeap.push(val);
Console.WriteLine($"元素 {val} 入堆后");
maxHeap.print();
/* 堆顶元素出堆 */
peek = maxHeap.pop();
Console.WriteLine($"堆顶元素 {peek} 出堆后");
maxHeap.print();
/* 获取堆大小 */
int size = maxHeap.size();
Console.WriteLine($"堆元素数量为 {size}");
/* 判断堆是否为空 */
bool isEmpty = maxHeap.isEmpty();
Console.WriteLine($"堆是否为空 {isEmpty}");
}
}
🔎4.建堆操作
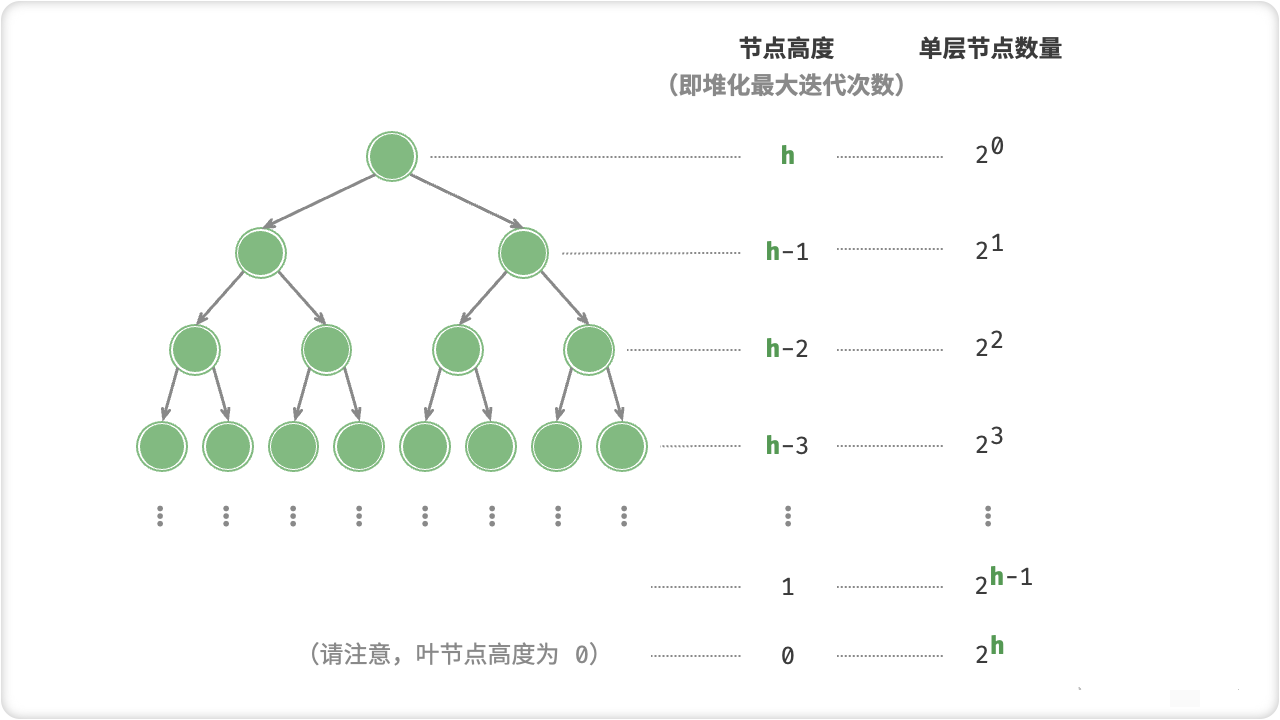
在堆排序中,建堆是指将一个无序的序列变为一个堆(binary heap)。建堆操作的时间复杂度为O(n),是堆排序的第一步。
堆是一种完全二叉树,其中每个节点的值都大于或等于其左右子节点的值,称为大根堆(max heap);或者每个节点的值都小于或等于其左右子节点的值,称为小根堆(min heap)。
建堆的过程就是将无序序列按照堆的性质调整为一个堆的过程。在建堆的过程中,从最后一个非叶子节点(叶子节点的父节点)开始,依次向上调整堆,对于每个节点,比较其与左右子节点的大小,将最大/最小的节点作为父节点。如果当前节点被交换,继续向下调整该节点,重复以上步骤,直到所有节点都满足堆的性质。
建堆操作的时间复杂度为O(n),因为只需要调整非叶子节点,即n/2个节点。
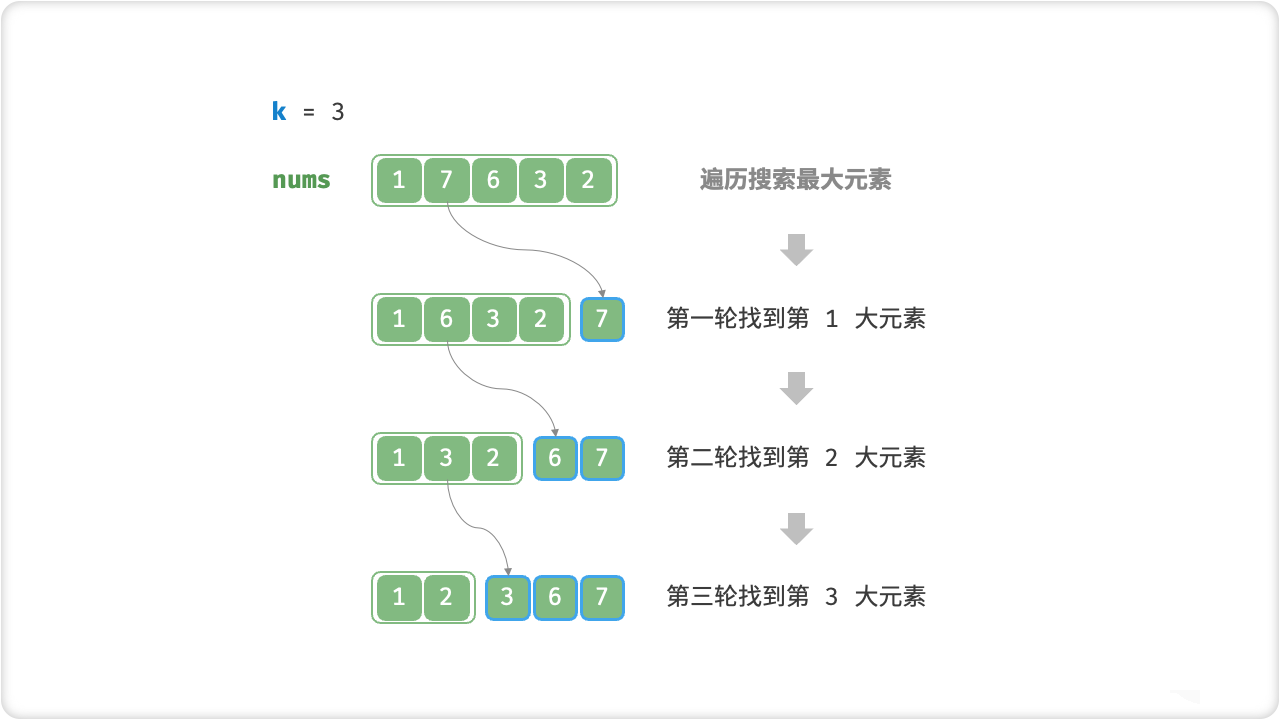
🔎5.Top-K 问题
堆是一种完全二叉树,满足堆序性质:每个节点的值都大于等于(或小于等于)其左右子节点的值。堆的Top-K问题即为从一个未排序的数组中找出前K个最大(或最小)的元素。
解决堆的Top-K问题的基本思路是维护一个大小为K的小(或大)根堆,遍历数组时将元素与小(或大)根堆堆顶元素比较,若大于(或小于)堆顶元素,则将堆顶元素弹出并将该元素加入堆中。遍历完成后,堆中保存的即为前K个最大(或最小)的元素。
具体实现分为两种:
1.堆排序法:使用堆排序的思想,构建一个小根堆,然后将未排序的元素加入堆中,并弹出堆顶元素直至堆大小为K,最后堆中的元素即为前K个最大的元素。
2.快速选择法:采用快速排序的思想,对数组进行划分,使得左边的数都比右边的数小,然后根据K的大小判断继续在左半边或右半边进行划分,直到找到前K个最大的数。
🦋5.1 遍历选择
🦋5.2 排序
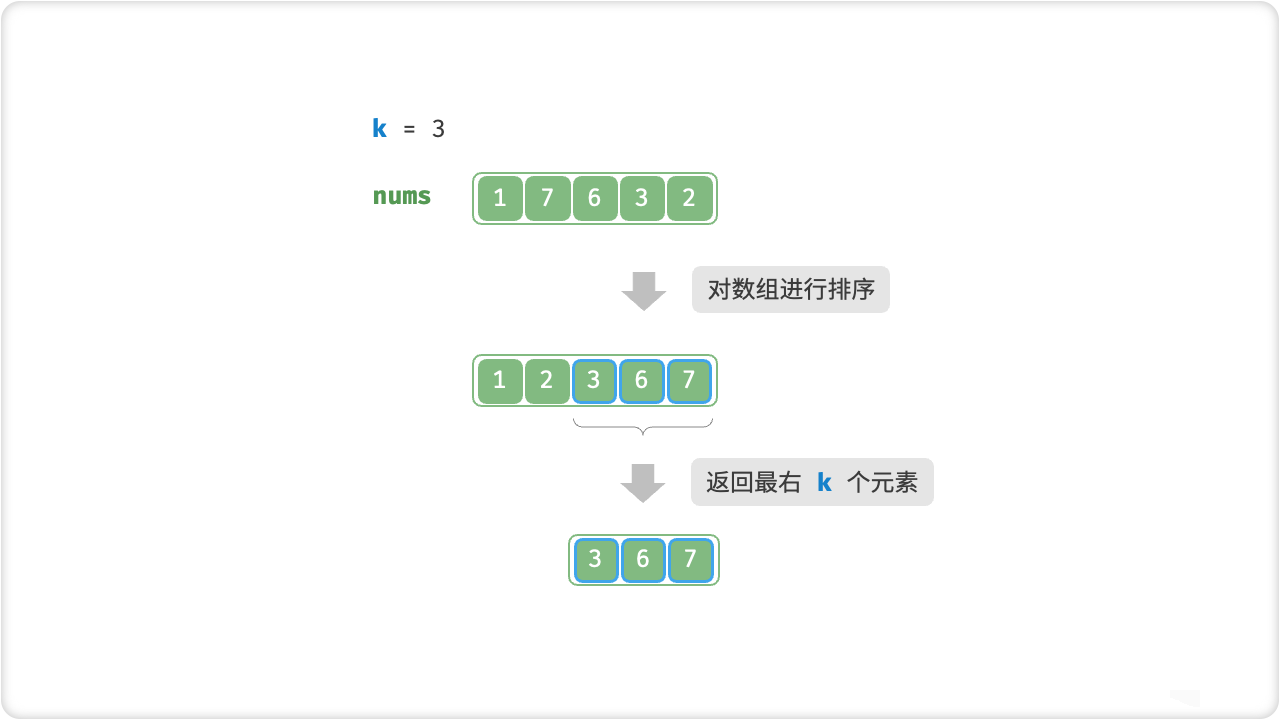
🦋5.3 堆
/* 基于堆查找数组中最大的 k 个元素 */
using NUnit.Framework;
static PriorityQueue<int, int> topKHeap(int[] nums, int k)
{
PriorityQueue<int, int> heap = new PriorityQueue<int, int>();
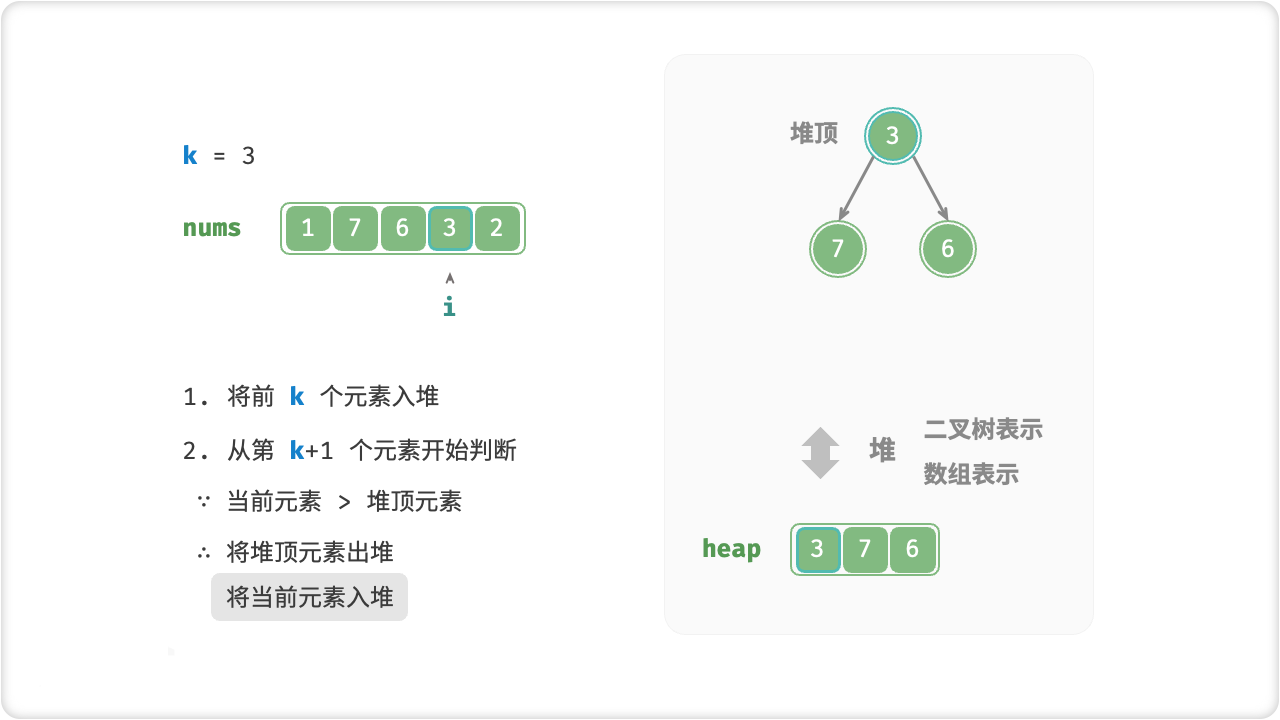
// 将数组的前 k 个元素入堆
for (int i = 0; i < k; i++)
{
heap.Enqueue(nums[i], nums[i]);
}
// 从第 k+1 个元素开始,保持堆的长度为 k
for (int i = k; i < nums.Length; i++)
{
// 若当前元素大于堆顶元素,则将堆顶元素出堆、当前元素入堆
if (nums[i] > heap.Peek())
{
heap.Dequeue();
heap.Enqueue(nums[i], nums[i]);
}
}
return heap;
}
int[] nums = { 1, 7, 6, 3, 2,8,9 };
int k = 3;
PriorityQueue<int, int> res = topKHeap(nums, k);
Console.WriteLine("最大的 " + k + " 个元素为");
🔎6.优点和缺点
堆(Heap)是一种完全二叉树结构,同时满足堆序性质(Heap property),即父节点的值永远小于或大于子节点的值。堆在数据结构中具有以下优点和缺点:
优点:
-
快速找到最值:堆是一种优秀的数据结构,可以快速找到最值。在最小堆中,根节点总是存储最小元素;在最大堆中,根节点总是存储最大元素。这使得堆非常适合实现优先队列。
-
插入和删除元素的效率高:堆的插入和删除元素的时间复杂度通常为O(log n)。这是因为堆是一棵完全二叉树,插入和删除操作只需对树进行最多O(log n)次比较和交换即可完成。
-
可以高效地处理动态数据集合:堆能够高效地处理动态数据集合,即在元素数量不断变化的情况下,能够快速地找到最值。
缺点:
4. 不支持查找任意元素:虽然堆可以快速找到最值,但是如果需要查找任意元素,则需要对所有节点进行遍历,时间复杂度为O(n)。
-
不支持快速修改元素:当堆中某个元素值发生变化时,需要重新调整堆以维持堆序性质,这通常需要O(n)的时间复杂度。
-
无法保证结构平衡:堆不像平衡二叉树那样能够保证结构平衡,可能会导致某些操作的最坏时间复杂度较高。例如,在极端情况下,堆可能退化为一条链表,导致插入和删除操作的时间复杂度为O(n)。
🔎7.应用场景
堆是一种基于完全二叉树的数据结构,在实际应用中有很多应用场景,以下是一些常见的应用场景:
1.堆排序:堆排序是一种高效的排序算法,利用堆的性质实现时间复杂度为O(nlogn)的排序。
2.优先队列:堆可以用来实现优先队列,优先队列可以在O(logn)时间内找到最小或最大元素。
3.求top k问题:如求一组数据中前k大或前k小的数据,可以使用堆来实现。
4.求中位数:使用堆可以在O(logn)时间内求出一组数据的中位数。
5.图搜索的最短路径算法:如Dijkstra算法和Prim算法,都需要使用堆来实现优先队列。
总之,堆是一种非常有用的数据结构,能够在许多应用场景中发挥重要作用。
🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”

- 点赞
- 收藏
- 关注作者
评论(0)