【愚公系列】2023年12月 数据结构(十)-Trie树

🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,阿里云专家博主,腾讯云优秀博主,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2022年CSDN博客之星TOP2,2022年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
数据结构是计算机科学中的一个重要概念,它描述了数据之间的组织方式和关系,以及对这些数据的访问和操作。常见的数据结构有:数组、链表、栈、队列、哈希表、树、堆和图。
-
数组(Array):是一种线性数据结构,它将一组具有相同类型的数据元素存储在一起,并为每个元素分配一个唯一的索引。数组的特点是具有随机访问的能力。
-
链表(Linked List):也是一种线性数据结构,它由一系列的节点组成,每个节点包含数据和指向下一个节点的引用。链表的特点是可以动态地插入或删除节点,但访问某个节点时需要从头开始遍历。
-
栈(Stack):是一种后进先出(LIFO)的数据结构,它只能在栈顶进行插入和删除操作。栈通常用于实现递归算法、表达式求值和内存管理等场景。
-
队列(Queue):是一种先进先出(FIFO)的数据结构,它可以在队尾插入元素,在队头删除元素。队列通常用于数据的缓存、消息队列和网络通信等场景。
-
哈希表(Hash Table):也称为散列表,它是一种根据关键字直接访问数据的数据结构。哈希表通常由数组和散列函数组成,可以在常数时间内进行插入、删除和查找操作。
-
树(Tree):是一种非线性数据结构,它由一系列的节点组成,每个节点可以有若干个子节点。树的特点是可以动态地插入或删除节点,常见的树结构包括二叉树、平衡树和搜索树等。
-
堆(Heap):是一种特殊的树结构,它通常用于实现优先队列和堆排序等算法。堆分为最大堆和最小堆,最大堆的每个节点的值都大于等于其子节点的值,最小堆则相反。
-
图(Graph):是一种由节点和边组成的非线性数据结构,它可以用来表示各种实体之间的关系,如社交网络、路线图和电路图等。图的遍历和最短路径算法是常见的图算法。
🚀一、Trie树
🔎1.基本思想
Trie树,也称前缀树或字典树,是一种以字典序为基础的树形数据结构。它基本思想是将一组字符串按字符顺序存储在树形结构中,利用相同的前缀来合并重复节点,从而实现快速的字符串查找和搜索。
Trie树的根节点不存储任何字符,每个节点代表一个字符,每个节点包含一个指向子节点(即下一个字符)的指针数组和一个标识是否为单词结尾的标记。当插入或搜索一个字符串时,从根节点开始,依次遍历字符串的每个字符,如果存在该字符对应的子节点,继续向下遍历,否则新建一个子节点,并将指针指向该节点。当遍历完整个字符串后,标记最后一个节点为单词结尾。
Trie树的优点在于,它可以支持快速的字符串查找和前缀匹配,避免了字符串比较的开销,是一种非常高效的数据结构。
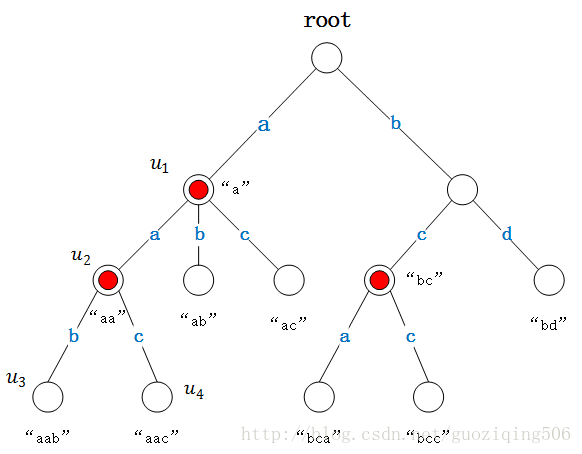
🔎2.Trie树常用操作
以下是C#实现Trie树常用操作的代码:
class TrieNode
{
public char Val { get; set; } // 节点字符
public bool IsEndOfWord { get; set; } // 是否为单词结尾
public TrieNode[] Children { get; set; } // 子节点数组
public TrieNode(char ch)
{
Val = ch;
IsEndOfWord = false;
Children = new TrieNode[26]; // 字母表大小为26
}
}
class Trie
{
private TrieNode root;
public Trie()
{
root = new TrieNode('#'); // 根节点不存储字符
}
// 插入一个单词
public void Insert(string word)
{
TrieNode node = root;
foreach (char ch in word)
{
int idx = ch - 'a';
if (node.Children[idx] == null)
node.Children[idx] = new TrieNode(ch); // 新建一个子节点
node = node.Children[idx]; // 继续向下遍历
}
node.IsEndOfWord = true; // 标记最后一个节点为单词结尾
}
// 查找一个单词
public bool Search(string word)
{
TrieNode node = root;
foreach (char ch in word)
{
int idx = ch - 'a';
if (node.Children[idx] == null)
return false; // 未找到该字符对应的子节点
node = node.Children[idx];
}
return node.IsEndOfWord; // 判断最后一个节点是否为单词结尾
}
// 查找Trie中是否有以给定前缀开头的单词
public bool StartsWith(string prefix)
{
TrieNode node = root;
foreach (char ch in prefix)
{
int idx = ch - 'a';
if (node.Children[idx] == null)
return false; // 未找到该字符对应的子节点
node = node.Children[idx];
}
return true; // 存在以该前缀开头的单词
}
}
以上代码实现了Trie树的插入、查找单词、查找前缀等常用操作。注意,在这个示例中,我们默认单词只包含小写字母。如果需要支持其他字符集,需要根据情况调整节点数组的大小。
🔎3.优点和缺点
Trie树(又称字典树或前缀树)是一种树形结构,用于存储关联数组,其中键通常是字符串。Trie树的优点和缺点如下:
优点:
- 查询效率高:Trie树是基于字符串前缀的搜索方法,可快速检索出以指定前缀开头的字符串。
- 空间利用率高:Trie树中的节点可以被多个字符串共享,而且仅在树的深度上消耗空间,因此它比哈希表等结构更节省空间。
- 可以实现自动补全功能:Trie树可以在每个节点记录一个字符串,因此可以在输入一个前缀时,自动补全所有以该前缀开头的字符串。
缺点:
- 空间复杂度高:Trie树中可能会存在很多节点,因此需要占用较多的空间。如果字符串集合中存在许多相似的字符串,Trie树的空间占用会更大。
- 构建Trie树的时间复杂度高:构建Trie树需要遍历所有的字符串,并将每个字符插入到Trie树中,因此时间复杂度为O(nk),其中n为字符串的数量,k为字符串的平均长度。
- 不利于模糊匹配: Trie树只能进行字符串前缀的匹配,无法进行模糊匹配,而模糊匹配通常需要用到正则表达式等高级技术。
🔎4.应用场景
Trie树(又称前缀树或字典树)是一种树形数据结构,用于高效地搜索和插入字符串。Trie树常用于以下场景:
-
字符串的查找和匹配:如文本编辑器中的自动补全、搜索引擎中的单词联想等。
-
单词统计:如在一组文本中统计单词出现的次数,可以将单词插入到Trie树中,并在每个单词的结尾节点记录出现的次数。
-
IP地址的路由查找:在路由表中查找与给定IP地址最长匹配的前缀。
-
序列匹配:如在DNA序列匹配中,Trie树可以用于快速查找匹配模式。
-
数据压缩:如将一个文本文件压缩成一个Trie树,可以达到较好的压缩效果。
Trie树是一个非常有用的数据结构,适用于许多需要高效查找和存储字符串的场景。
🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”

- 点赞
- 收藏
- 关注作者
评论(0)