【愚公系列】2023年12月 数据结构(八)-二叉树

🏆 作者简介,愚公搬代码
🏆《头衔》:华为云特约编辑,华为云云享专家,华为开发者专家,华为产品云测专家,CSDN博客专家,阿里云专家博主,腾讯云优秀博主,掘金优秀博主,51CTO博客专家等。
🏆《近期荣誉》:2022年CSDN博客之星TOP2,2022年华为云十佳博主等。
🏆《博客内容》:.NET、Java、Python、Go、Node、前端、IOS、Android、鸿蒙、Linux、物联网、网络安全、大数据、人工智能、U3D游戏、小程序等相关领域知识。
🏆🎉欢迎 👍点赞✍评论⭐收藏
🚀前言
数据结构是计算机科学中的一个重要概念,它描述了数据之间的组织方式和关系,以及对这些数据的访问和操作。常见的数据结构有:数组、链表、栈、队列、哈希表、树、堆和图。
-
数组(Array):是一种线性数据结构,它将一组具有相同类型的数据元素存储在一起,并为每个元素分配一个唯一的索引。数组的特点是具有随机访问的能力。
-
链表(Linked List):也是一种线性数据结构,它由一系列的节点组成,每个节点包含数据和指向下一个节点的引用。链表的特点是可以动态地插入或删除节点,但访问某个节点时需要从头开始遍历。
-
栈(Stack):是一种后进先出(LIFO)的数据结构,它只能在栈顶进行插入和删除操作。栈通常用于实现递归算法、表达式求值和内存管理等场景。
-
队列(Queue):是一种先进先出(FIFO)的数据结构,它可以在队尾插入元素,在队头删除元素。队列通常用于数据的缓存、消息队列和网络通信等场景。
-
哈希表(Hash Table):也称为散列表,它是一种根据关键字直接访问数据的数据结构。哈希表通常由数组和散列函数组成,可以在常数时间内进行插入、删除和查找操作。
-
树(Tree):是一种非线性数据结构,它由一系列的节点组成,每个节点可以有若干个子节点。树的特点是可以动态地插入或删除节点,常见的树结构包括二叉树、平衡树和搜索树等。
-
堆(Heap):是一种特殊的树结构,它通常用于实现优先队列和堆排序等算法。堆分为最大堆和最小堆,最大堆的每个节点的值都大于等于其子节点的值,最小堆则相反。
-
图(Graph):是一种由节点和边组成的非线性数据结构,它可以用来表示各种实体之间的关系,如社交网络、路线图和电路图等。图的遍历和最短路径算法是常见的图算法。
🚀一、二叉树
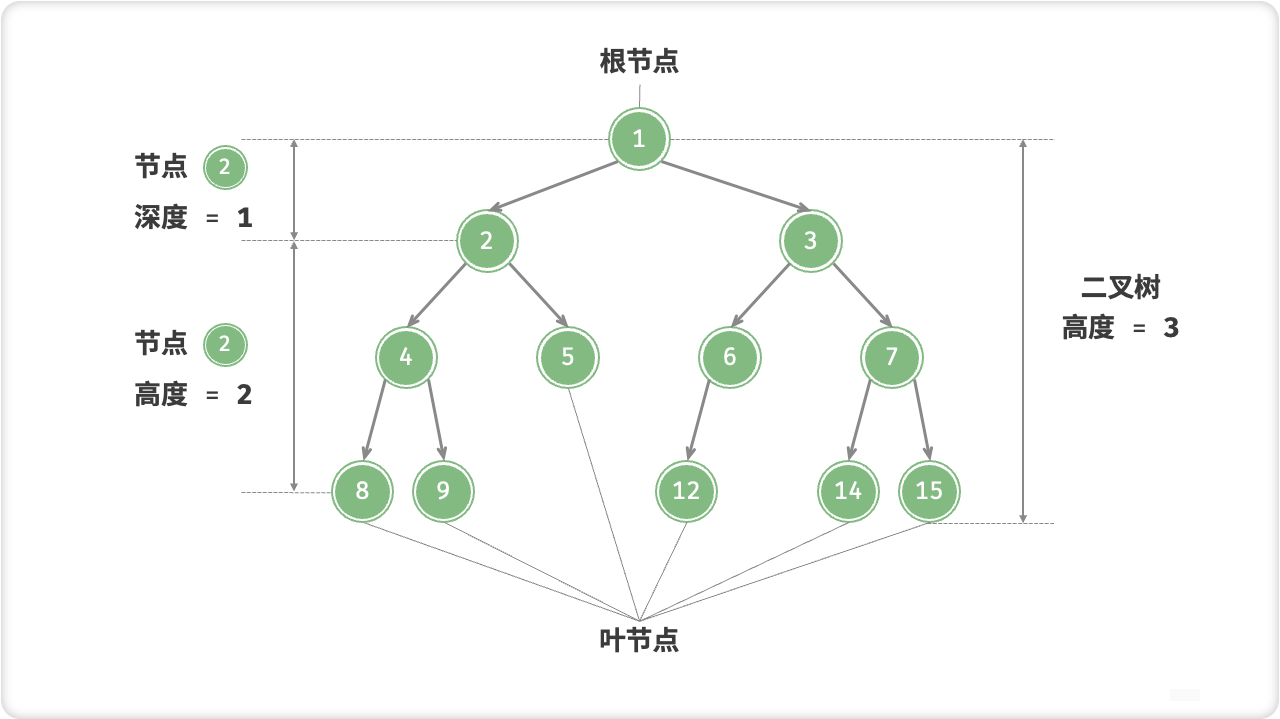
🔎1.基本思想
二叉树是一种数据结构,它由节点和连接节点的边组成。每个节点最多有两个子节点,即左子节点和右子节点。二叉树可以用来表示排序算法、搜索算法、哈夫曼编码等。
二叉树的基本思想是将一个问题或数据集合逐步分解为小问题或子集合,最终实现对整个问题或数据集合的处理。一般而言,二叉树有以下几个基本操作:
-
创建二叉树:可通过递归方式创建二叉树,从根节点开始,分别递归左子树和右子树;
-
遍历二叉树:有深度优先遍历(前序遍历、中序遍历、后序遍历)和广度优先遍历(层次遍历)两种方法;
-
插入节点:在二叉树中插入一个新节点,需要找到合适的位置进行插入;
-
删除节点:在二叉树中删除一个节点,需要注意维护二叉树的结构,保证二叉树仍然是一棵合法的二叉树。
二叉树是一种重要的数据结构,它广泛应用于计算机科学领域中的算法和数据处理中。

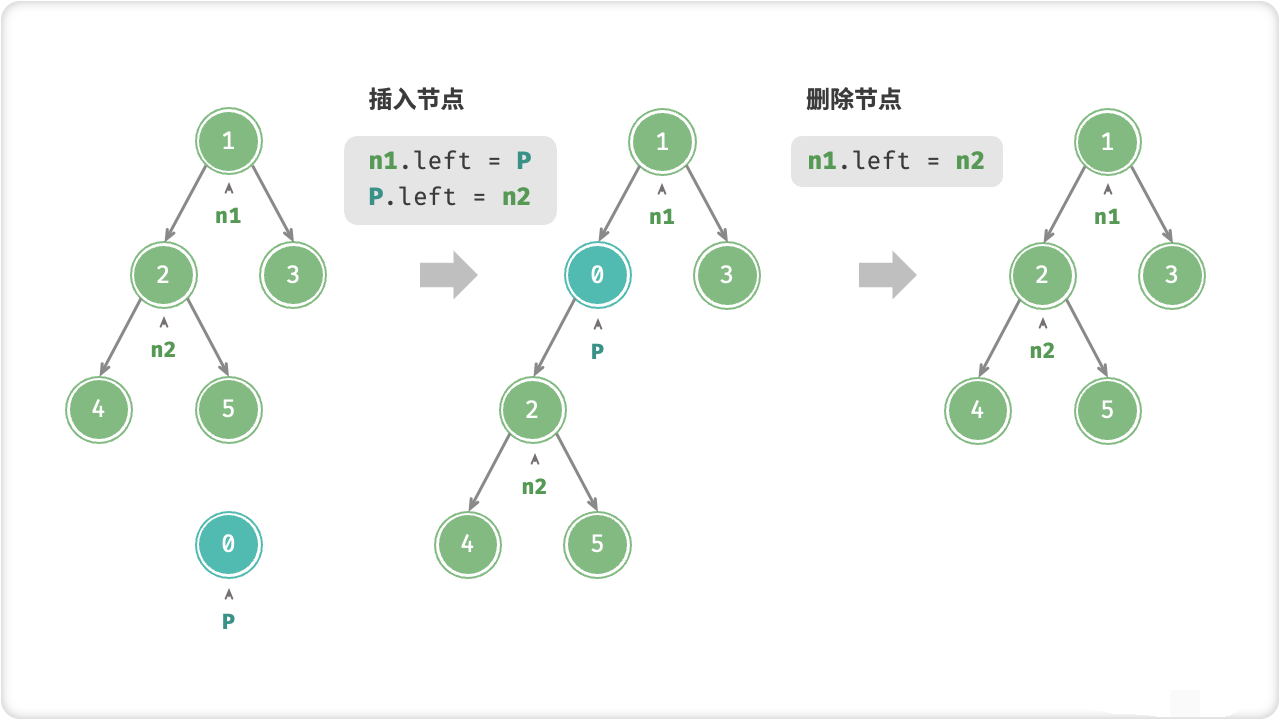
🔎2.二叉树基本操作
/* 二叉树节点类 */
class TreeNode {
int val; // 节点值
TreeNode? left; // 左子节点引用
TreeNode? right; // 右子节点引用
TreeNode(int x) { val = x; }
}
public class binary_tree {
[Test]
public void Test() {
/* 初始化二叉树 */
// 初始化节点
TreeNode n1 = new TreeNode(1);
TreeNode n2 = new TreeNode(2);
TreeNode n3 = new TreeNode(3);
TreeNode n4 = new TreeNode(4);
TreeNode n5 = new TreeNode(5);
// 构建引用指向(即指针)
n1.left = n2;
n1.right = n3;
n2.left = n4;
n2.right = n5;
Console.WriteLine("\n初始化二叉树\n");
PrintUtil.PrintTree(n1);
/* 插入与删除节点 */
TreeNode P = new TreeNode(0);
// 在 n1 -> n2 中间插入节点 P
n1.left = P;
P.left = n2;
Console.WriteLine("\n插入节点 P 后\n");
PrintUtil.PrintTree(n1);
// 删除节点 P
n1.left = n2;
Console.WriteLine("\n删除节点 P 后\n");
PrintUtil.PrintTree(n1);
}
}
🔎3.树的实现
public class Tree<T>
{
public Tree()
{
Deep = 1;
}
public int Deep { get; set; }
public string Name { get; set; }
public T Value { get; set; }
public Tree<T> Perent { get; set; }
private List<Tree<T>> Child = new List<Tree<T>>();
public void AddChild(Tree<T> tree)
{
if (GetByName(tree.Name) != null)
{
return;
}
tree.Perent = this;
tree.Deep = Deep + 1;
Child.Add(tree);
}
public void RemoveChild()
{
Child.Clear();
}
public Tree<T> GetByName(string name)
{
Tree<T> root = GetRootTree(this);
List<Tree<T>> list = GatAll(root);
var result = list.Where(c => c.Name == name).ToList();
if (result.Count <= 0)
{
return null;
}
else
{
return result[0];
}
}
public List<Tree<T>> GatAll(Tree<T> tree)
{
List<Tree<T>> list = new List<Tree<T>>();
list.Add(tree);
if (tree.Child == null)
{
return null;
}
list.AddRange(tree.Child);
foreach (var tree1 in tree.Child)
{
list.AddRange(GatAll(tree1));
}
return list.Distinct().ToList();
}
public Tree<T> GetRootTree(Tree<T> tree)
{
if (tree.Perent == null)
{
return tree;
}
return GetRootTree(tree.Perent);
}
public int GetDeep(Tree<T> tree)
{
List<Tree<T>> list = GetDeepTree(tree);
return list.Max(c => c.Deep);
}
public List<Tree<T>> GetDeepTree(Tree<T> tree)
{
List<Tree<T>> list = new List<Tree<T>>();
if (tree.Child.Count <= 0)
{
list.Add(tree);
}
else
{
foreach (var tree1 in tree.Child)
{
if (tree1.Child.Count <= 0)
{
list.Add(tree1);
}
else
{
foreach (var tree2 in tree1.Child)
{
list.AddRange(GetDeepTree(tree2));
}
}
}
}
return list;
}
}
🔎4.常见二叉树类型
🦋4.1 完美二叉树
满二叉树是一种特殊的二叉树,每个节点要么没有子节点(为叶子节点),要么有两个子节点,且所有叶子节点都在同一层级上。满二叉树的节点数为 ,其中 为树的高度。满二叉树具有以下特点:
- 第 层最多有 个节点;
- 深度为 的满二叉树共有 个节点;
- 对于任意非叶子节点,它的度数为 2。
满二叉树的一个例子如下所示:
1
/ \
2 3
/ \ / \
4 5 6 7

其中,根节点为 1,它的两个子节点为 2 和 3,2 又有两个子节点 4 和 5,3 也有两个子节点 6 和 7。这棵满二叉树的高度为 3。
满二叉树在计算机科学中应用广泛,例如堆排序、线段树、哈夫曼树等算法和数据结构中都会用到。
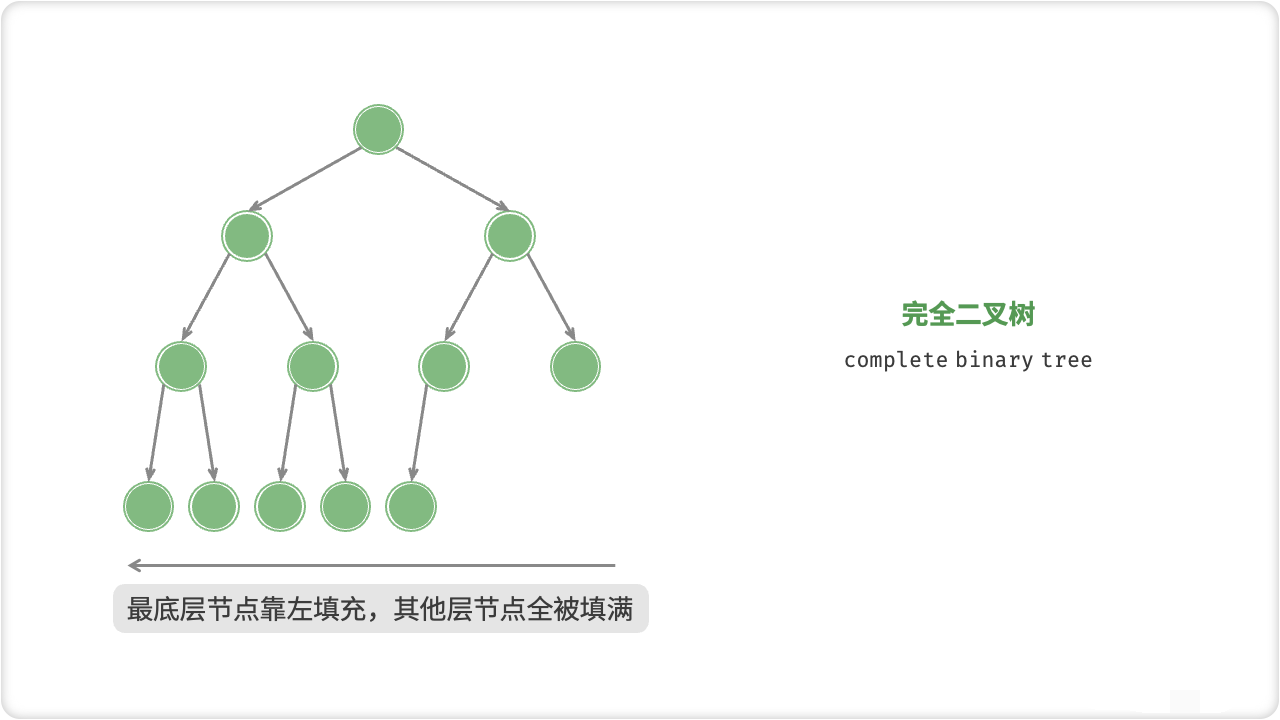
🦋4.2 完全二叉树
完全二叉树是一种特殊的二叉树,它满足以下两个条件:
-
它的深度为k(k>=1),且其第1至k-1层结点都是满的。
-
第k层所有的结点都集中在该层最左边的若干个位置上。
其中,第k层可以有1~2^(k-1)个结点,而1至k-1层结点数都是满的,即2^i-1个(i=1,2,…,k-1)。
完全二叉树的特点以及性质:
-
对于根节点所在的层数,各节点按从上到下、从左到右的顺序进行编号,则序号为i的节点,其左儿子的编号一定为2i,右儿子的编号一定为2i+1;
-
对于序号为i的节点,其父节点的编号为i/2(下取整);
-
对于n个节点的完全二叉树,深度为log2n+1(这里的log以2为底)。
完全二叉树的应用:
-
堆(heap)是一种特殊的完全二叉树,常用于维护序列中的最小值或最大值;
-
在哈夫曼编码中,可以使用完全二叉树来构建哈夫曼树,从而对字符进行编码。
🦋4.3 完满二叉树
完满二叉树是一棵二叉树,其中每个非叶子节点都有两个子节点,并且所有叶子节点都在同一层。换句话说,完满二叉树是一个深度为d且恰好有2^d−1个节点的二叉树。
例如,下面就是一棵完满二叉树:
1
/ \
2 3
/ \
4 5
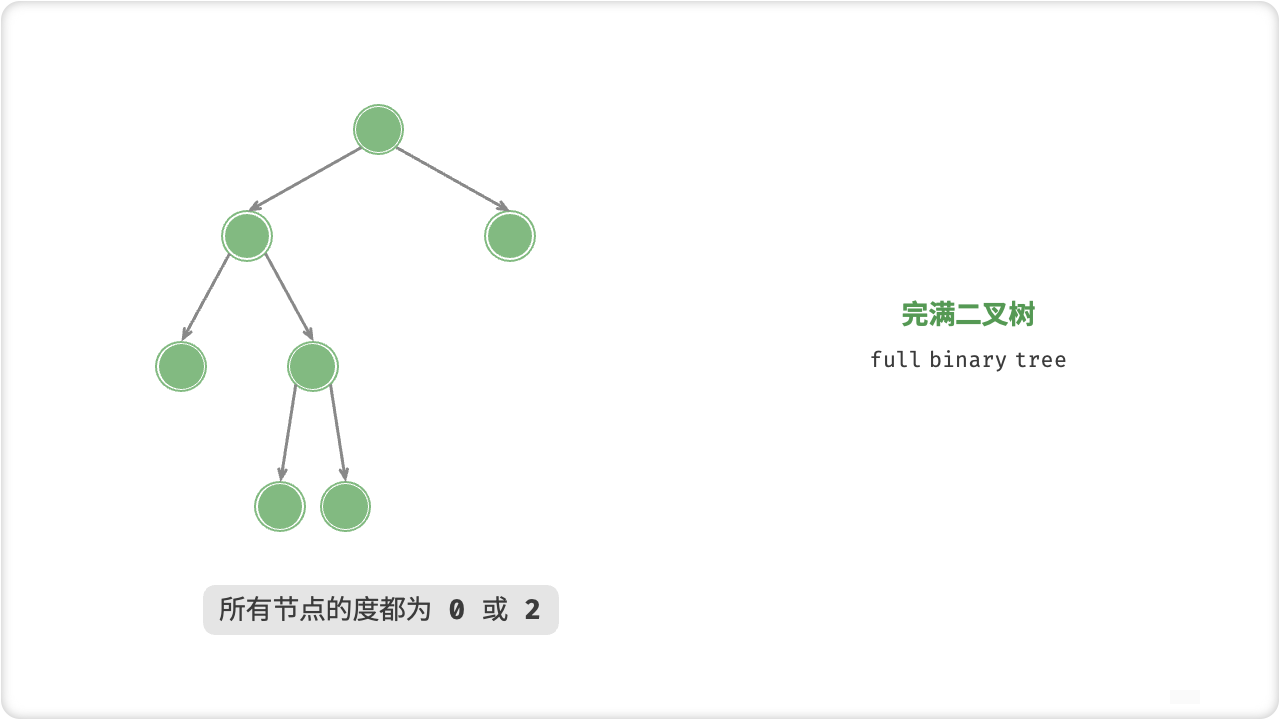
完满二叉树在数据结构和算法中非常常见,因为它的结构良好且易于实现。它的一个特殊用途是在堆排序中使用。
🦋4.4 平衡二叉树
平衡二叉树(AVL树)是一种特殊的二叉搜索树,它的高度平衡性比一般的二叉搜索树更好,可以使得树的高度保持在O(logn)。平衡二叉树的本质是二叉搜索树,所以它具有二叉搜索树的所有特点,即左子树上的所有节点的值都比根节点小,右子树上的所有节点的值都比根节点大。
平衡二叉树的特点:
- 任意节点的左、右子树高度差的绝对值不超过1。
- 本质是二叉搜索树,具有二叉搜索树的所有特点。
- 插入、删除节点时需要保持树的平衡,需要调整各个节点的高度,以满足平衡二叉树的特点。
平衡二叉树的优点:
- 时间复杂度比较稳定,不会出现退化成链表的情况,最多只有O(logn)层。
- 查找、插入、删除操作的时间复杂度均为O(logn)。
平衡二叉树的缺点:
- 添加或删除节点时需要保持树的平衡,需要进行频繁的旋转操作,因此操作效率相对较低。
- 需要存储额外的平衡因子或者高度信息,增加了存储的开销。

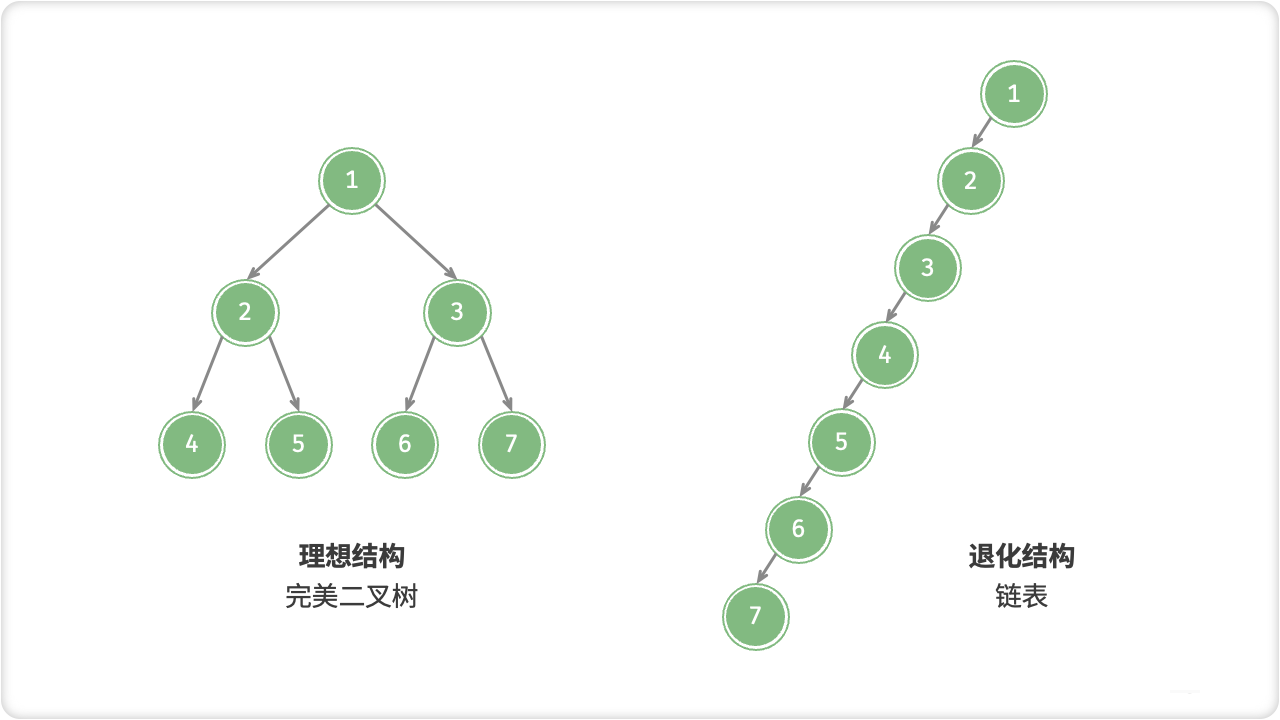
🦋4.5 二叉树的退化
当二叉树的每层节点都被填满时,达到“完美二叉树”;而当所有节点都偏向一侧时,二叉树退化为“链表”。
-
完美二叉树是理想情况,可以充分发挥二叉树“分治”的优势。
-
链表则是另一个极端,各项操作都变为线性操作,时间复杂度退化至 O(n) 。
🔎5.二叉树遍历
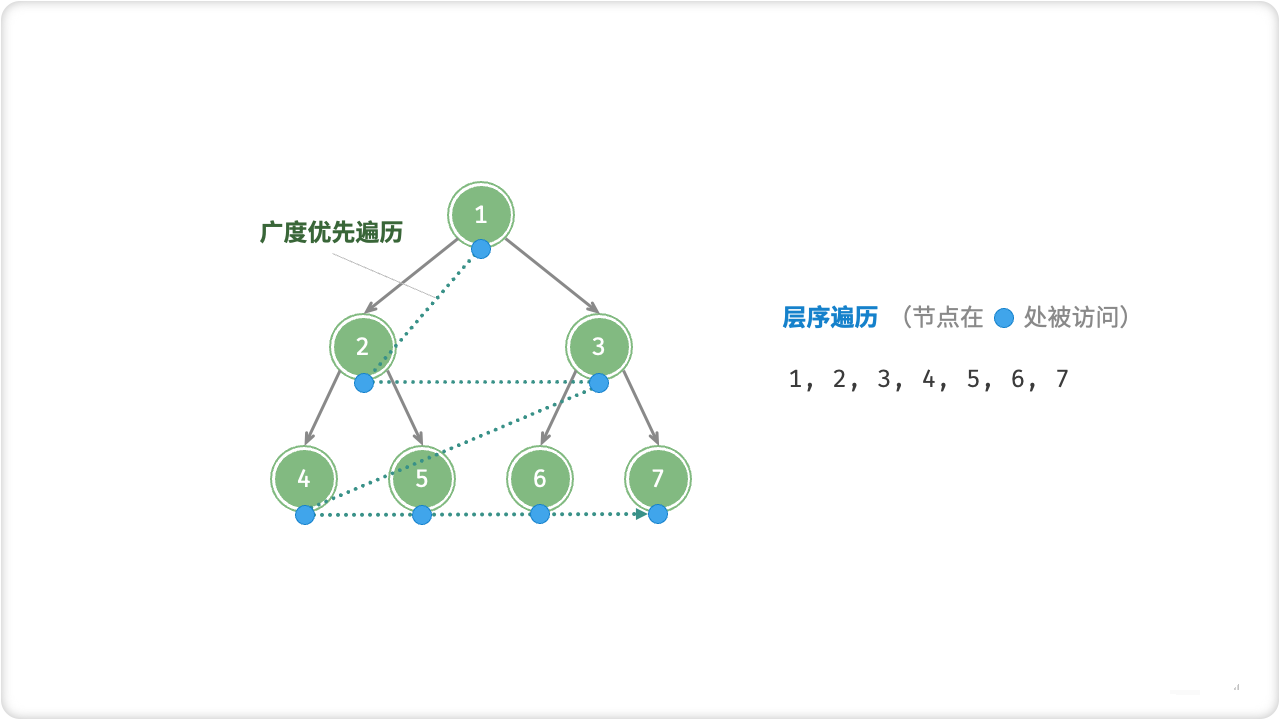
🦋5.1 层序遍历
二叉树层序遍历是二叉树的一种遍历方式,也叫广度优先遍历。它按照从上到下、从左到右的顺序遍历二叉树的所有节点,可以得到二叉树所有节点的层次信息。层序遍历可以用来实现二叉树的序列化和反序列化,也可以用来解决一些树的问题,如二叉树的最小深度、二叉树的最大深度、二叉树的宽度等问题。
二叉树层序遍历的实现需要用到队列这一数据结构,具体实现方法如下:
首先,我们将根节点入队。接下来,进入一个循环,每次取出队首的节点,并将该节点的左右子节点入队。然后再从队列中取出下一个节点,直到队列为空。在过程中,我们需要将每个节点的值存储下来,以便于最后输出。
层序遍历的时间复杂度为 ,其中 是二叉树的节点数。这是因为我们需要遍历每个节点且每个节点仅会入队一次。而空间复杂度为 ,其中 是二叉树的最大宽度。因为在最坏情况下,队列中存储的节点数最多不会超过二叉树的最大宽度,即二叉树最后一层的节点数。
public class binary_tree_bfs {
/* 层序遍历 */
public List<int> levelOrder(TreeNode root) {
// 初始化队列,加入根节点
Queue<TreeNode> queue = new();
queue.Enqueue(root);
// 初始化一个列表,用于保存遍历序列
List<int> list = new();
while (queue.Count != 0) {
TreeNode node = queue.Dequeue(); // 队列出队
list.Add(node.val); // 保存节点值
if (node.left != null)
queue.Enqueue(node.left); // 左子节点入队
if (node.right != null)
queue.Enqueue(node.right); // 右子节点入队
}
return list;
}
[Test]
public void Test() {
/* 初始化二叉树 */
// 这里借助了一个从数组直接生成二叉树的函数
TreeNode? root = TreeNode.ListToTree(new List<int?> { 1, 2, 3, 4, 5, 6, 7 });
Console.WriteLine("\n初始化二叉树\n");
PrintUtil.PrintTree(root);
List<int> list = levelOrder(root);
Console.WriteLine("\n层序遍历的节点打印序列 = " + string.Join(",", list));
}
}
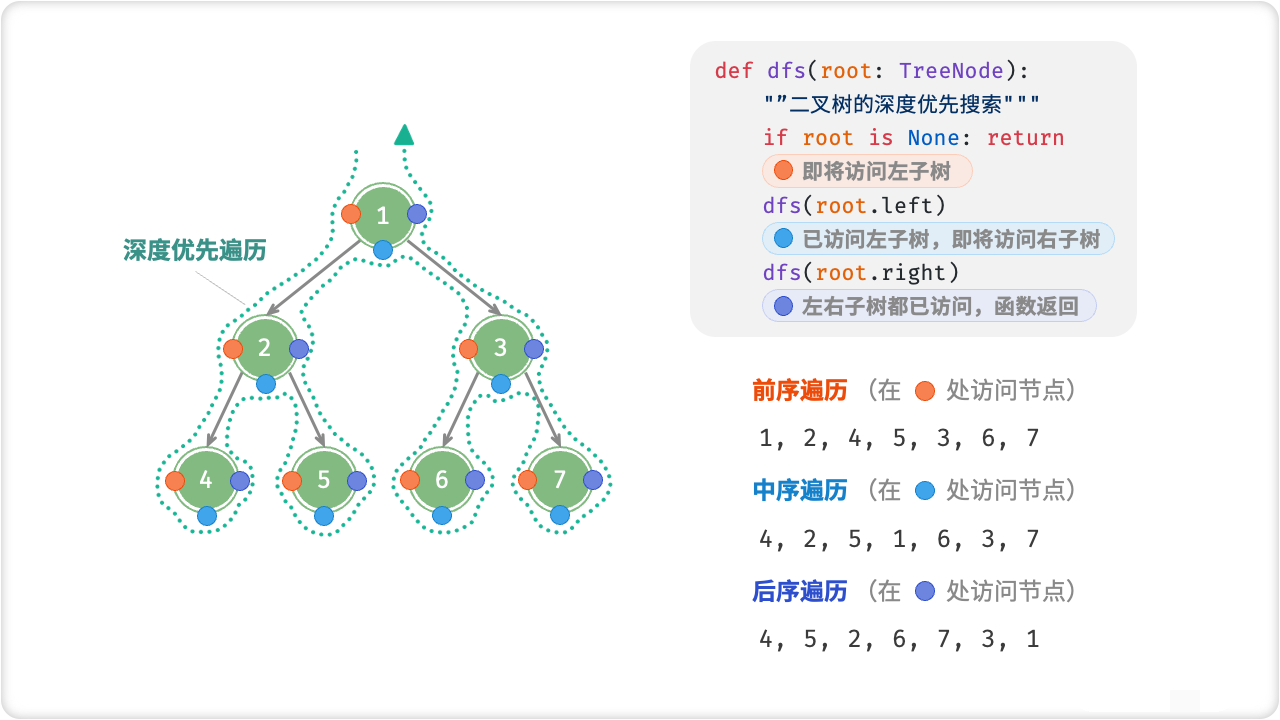
🦋5.2 前序、中序、后序遍历
在二叉树中,遍历指的是按照一定顺序依次访问树中所有节点的过程。常见的二叉树遍历方式包括前序遍历、中序遍历和后序遍历。
- 前序遍历(Preorder Traversal):先访问根节点,再遍历左子树,最后遍历右子树。
- 中序遍历(Inorder Traversal):先遍历左子树,再访问根节点,最后遍历右子树。
- 后序遍历(Postorder Traversal):先遍历左子树,再遍历右子树,最后访问根节点。
注:以上三种遍历方式的顺序均为节点的访问顺序,即访问左、右子树部分时仍然按照对应遍历方式的顺序进行。例如,在前序遍历中,先访问左子树的根节点,然后遍历左子树的左子树,最后是左子树的右子树。
public class binary_tree_dfs {
List<int> list = new();
/* 前序遍历 */
void preOrder(TreeNode? root) {
if (root == null) return;
// 访问优先级:根节点 -> 左子树 -> 右子树
list.Add(root.val);
preOrder(root.left);
preOrder(root.right);
}
/* 中序遍历 */
void inOrder(TreeNode? root) {
if (root == null) return;
// 访问优先级:左子树 -> 根节点 -> 右子树
inOrder(root.left);
list.Add(root.val);
inOrder(root.right);
}
/* 后序遍历 */
void postOrder(TreeNode? root) {
if (root == null) return;
// 访问优先级:左子树 -> 右子树 -> 根节点
postOrder(root.left);
postOrder(root.right);
list.Add(root.val);
}
[Test]
public void Test() {
/* 初始化二叉树 */
// 这里借助了一个从数组直接生成二叉树的函数
TreeNode? root = TreeNode.ListToTree(new List<int?> { 1, 2, 3, 4, 5, 6, 7 });
Console.WriteLine("\n初始化二叉树\n");
PrintUtil.PrintTree(root);
list.Clear();
preOrder(root);
Console.WriteLine("\n前序遍历的节点打印序列 = " + string.Join(",", list));
list.Clear();
inOrder(root);
Console.WriteLine("\n中序遍历的节点打印序列 = " + string.Join(",", list));
list.Clear();
postOrder(root);
Console.WriteLine("\n后序遍历的节点打印序列 = " + string.Join(",", list));
}
}
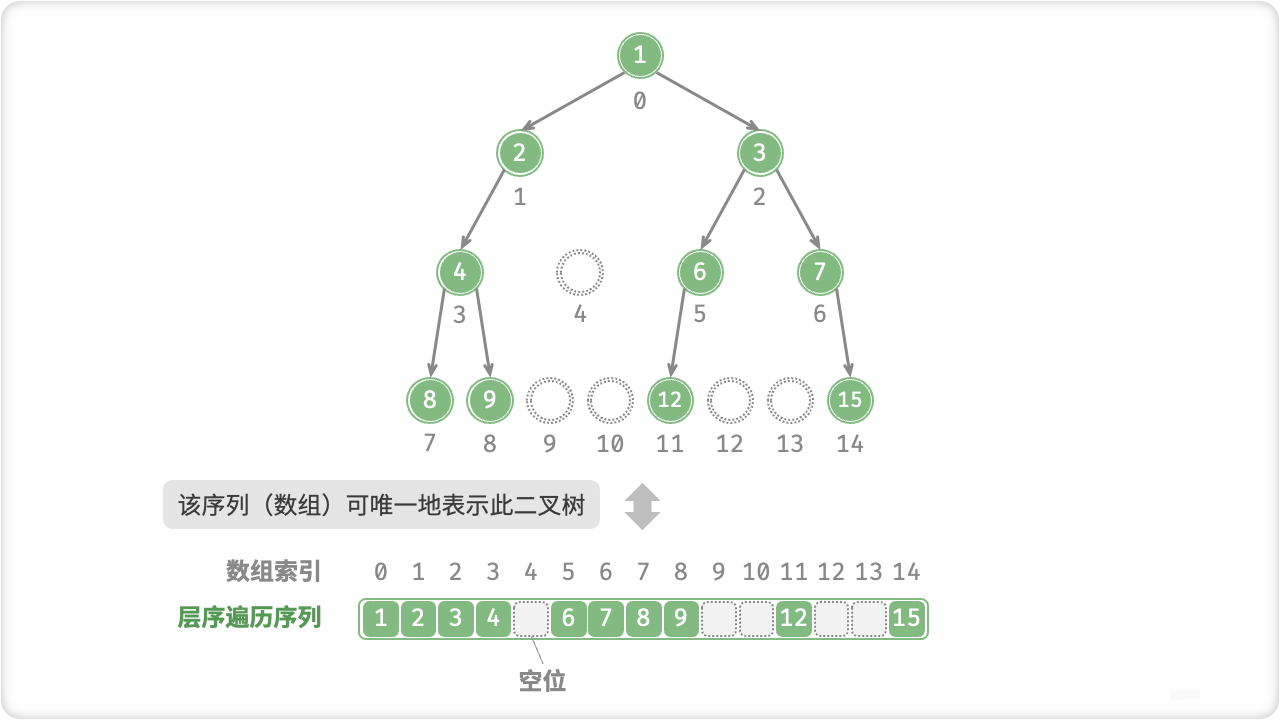
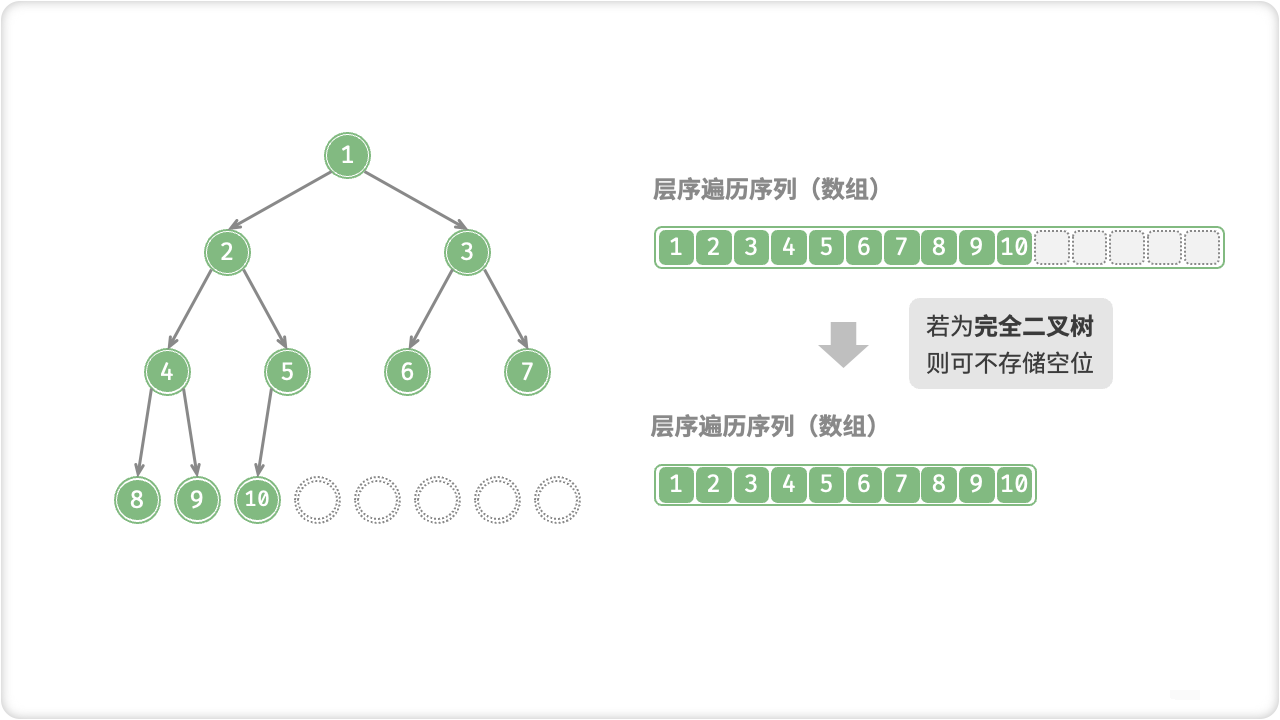
🔎6.二叉树数组表示
🦋6.1 完美二叉树
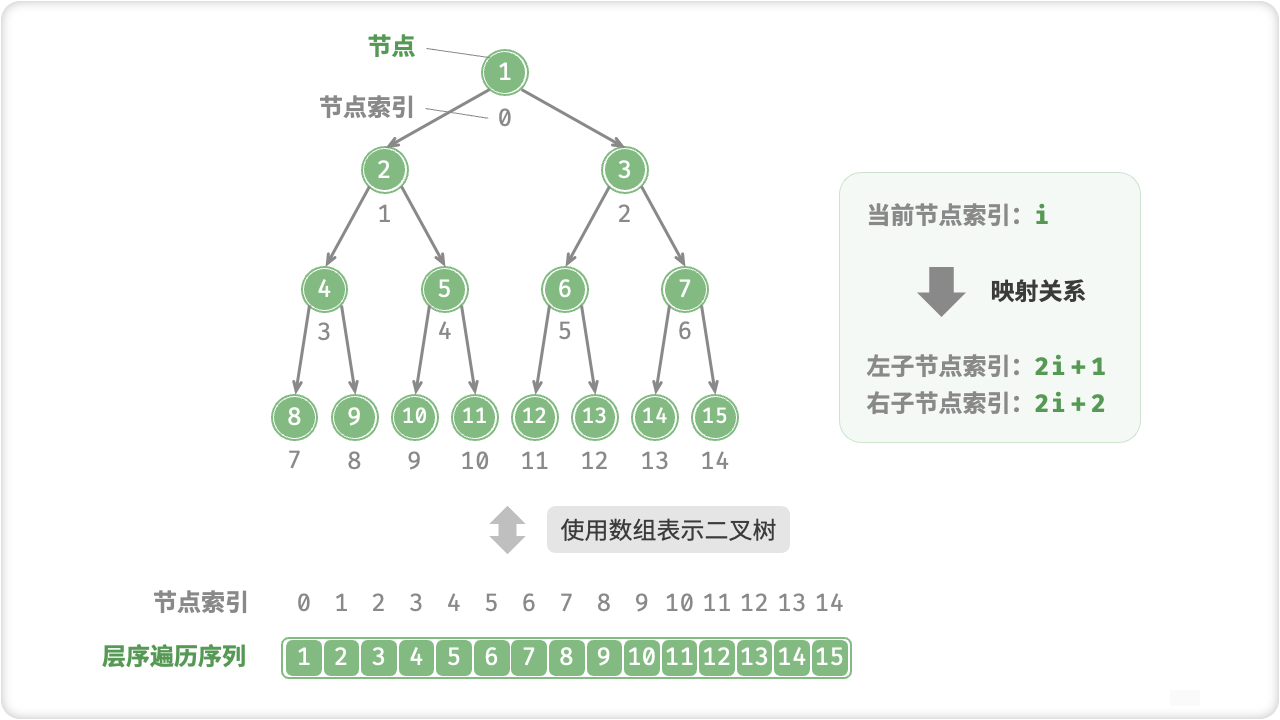
🦋6.2 任意二叉树
/ 使用 int? 可空类型 ,就可以使用 null 来标记空位
int?[] tree = { 1, 2, 3, 4, null, 6, 7, 8, 9, null, null, 12, null, null, 15 };
/* 数组表示下的二叉树类 */
public class ArrayBinaryTree {
private List<int?> tree;
/* 构造方法 */
public ArrayBinaryTree(List<int?> arr) {
tree = new List<int?>(arr);
}
/* 节点数量 */
public int size() {
return tree.Count;
}
/* 获取索引为 i 节点的值 */
public int? val(int i) {
// 若索引越界,则返回 null ,代表空位
if (i < 0 || i >= size())
return null;
return tree[i];
}
/* 获取索引为 i 节点的左子节点的索引 */
public int left(int i) {
return 2 * i + 1;
}
/* 获取索引为 i 节点的右子节点的索引 */
public int right(int i) {
return 2 * i + 2;
}
/* 获取索引为 i 节点的父节点的索引 */
public int parent(int i) {
return (i - 1) / 2;
}
/* 层序遍历 */
public List<int> levelOrder() {
List<int> res = new List<int>();
// 直接遍历数组
for (int i = 0; i < size(); i++) {
if (val(i).HasValue)
res.Add(val(i).Value);
}
return res;
}
/* 深度优先遍历 */
private void dfs(int i, string order, List<int> res) {
// 若为空位,则返回
if (!val(i).HasValue)
return;
// 前序遍历
if (order == "pre")
res.Add(val(i).Value);
dfs(left(i), order, res);
// 中序遍历
if (order == "in")
res.Add(val(i).Value);
dfs(right(i), order, res);
// 后序遍历
if (order == "post")
res.Add(val(i).Value);
}
/* 前序遍历 */
public List<int> preOrder() {
List<int> res = new List<int>();
dfs(0, "pre", res);
return res;
}
/* 中序遍历 */
public List<int> inOrder() {
List<int> res = new List<int>();
dfs(0, "in", res);
return res;
}
/* 后序遍历 */
public List<int> postOrder() {
List<int> res = new List<int>();
dfs(0, "post", res);
return res;
}
}
public class array_binary_tree {
[Test]
public void Test() {
// 初始化二叉树
// 这里借助了一个从数组直接生成二叉树的函数
List<int?> arr = new List<int?> { 1, 2, 3, 4, null, 6, 7, 8, 9, null, null, 12, null, null, 15 };
TreeNode root = TreeNode.ListToTree(arr);
Console.WriteLine("\n初始化二叉树\n");
Console.WriteLine("二叉树的数组表示:");
Console.WriteLine(arr.PrintList());
Console.WriteLine("二叉树的链表表示:");
PrintUtil.PrintTree(root);
// 数组表示下的二叉树类
ArrayBinaryTree abt = new ArrayBinaryTree(arr);
// 访问节点
int i = 1;
int l = abt.left(i);
int r = abt.right(i);
int p = abt.parent(i);
Console.WriteLine("\n当前节点的索引为 " + i + " ,值为 " + abt.val(i));
Console.WriteLine("其左子节点的索引为 " + l + " ,值为 " + (abt.val(l).HasValue ? abt.val(l) : "null"));
Console.WriteLine("其右子节点的索引为 " + r + " ,值为 " + (abt.val(r).HasValue ? abt.val(r) : "null"));
Console.WriteLine("其父节点的索引为 " + p + " ,值为 " + (abt.val(p).HasValue ? abt.val(p) : "null"));
// 遍历树
List<int> res = abt.levelOrder();
Console.WriteLine("\n层序遍历为:" + res.PrintList());
res = abt.preOrder();
Console.WriteLine("前序遍历为:" + res.PrintList());
res = abt.inOrder();
Console.WriteLine("中序遍历为:" + res.PrintList());
res = abt.postOrder();
Console.WriteLine("后序遍历为:" + res.PrintList());
}
}
🔎7.二叉搜索树
二叉搜索树,也称为二叉查找树(Binary Search Tree,BST),是一种特殊的二叉树。它的特殊之处在于,对于每个节点,它的左子树中的所有节点值都小于它本身的值,而它的右子树中的所有节点值都大于它本身的值。因此,二叉搜索树可以用来实现动态的查找、插入和删除操作。
二叉搜索树的性质:
- 对于任意节点,它的左子树中的所有节点值都小于它自己的值;
- 对于任意节点,它的右子树中的所有节点值都大于它自己的值;
- 左右子树分别也是二叉搜索树。
基本操作:搜索、插入、删除。搜索操作的时间复杂度为 O(log n),其中 n 是树中节点的个数。插入和删除操作的时间复杂度也是 O(log n)。
注意:二叉搜索树不一定是平衡的,如果存在极端情况,比如插入完全有序的序列,二叉搜索树可能会退化成一条链,此时时间复杂度就会退化为 O(n)。为了解决这个问题,可以采用平衡二叉搜索树,比如 AVL 树和红黑树。

class BinarySearchTree {
TreeNode? root;
public BinarySearchTree() {
// 初始化空树
root = null;
}
/* 获取二叉树根节点 */
public TreeNode? getRoot() {
return root;
}
/* 查找节点 */
public TreeNode? search(int num) {
TreeNode? cur = root;
// 循环查找,越过叶节点后跳出
while (cur != null) {
// 目标节点在 cur 的右子树中
if (cur.val < num) cur =
cur.right;
// 目标节点在 cur 的左子树中
else if (cur.val > num)
cur = cur.left;
// 找到目标节点,跳出循环
else
break;
}
// 返回目标节点
return cur;
}
/* 插入节点 */
public void insert(int num) {
// 若树为空,则初始化根节点
if (root == null) {
root = new TreeNode(num);
return;
}
TreeNode? cur = root, pre = null;
// 循环查找,越过叶节点后跳出
while (cur != null) {
// 找到重复节点,直接返回
if (cur.val == num)
return;
pre = cur;
// 插入位置在 cur 的右子树中
if (cur.val < num)
cur = cur.right;
// 插入位置在 cur 的左子树中
else
cur = cur.left;
}
// 插入节点
TreeNode node = new TreeNode(num);
if (pre != null) {
if (pre.val < num)
pre.right = node;
else
pre.left = node;
}
}
/* 删除节点 */
public void remove(int num) {
// 若树为空,直接提前返回
if (root == null)
return;
TreeNode? cur = root, pre = null;
// 循环查找,越过叶节点后跳出
while (cur != null) {
// 找到待删除节点,跳出循环
if (cur.val == num)
break;
pre = cur;
// 待删除节点在 cur 的右子树中
if (cur.val < num)
cur = cur.right;
// 待删除节点在 cur 的左子树中
else
cur = cur.left;
}
// 若无待删除节点,则直接返回
if (cur == null)
return;
// 子节点数量 = 0 or 1
if (cur.left == null || cur.right == null) {
// 当子节点数量 = 0 / 1 时, child = null / 该子节点
TreeNode? child = cur.left != null ? cur.left : cur.right;
// 删除节点 cur
if (cur != root) {
if (pre.left == cur)
pre.left = child;
else
pre.right = child;
} else {
// 若删除节点为根节点,则重新指定根节点
root = child;
}
}
// 子节点数量 = 2
else {
// 获取中序遍历中 cur 的下一个节点
TreeNode? tmp = cur.right;
while (tmp.left != null) {
tmp = tmp.left;
}
// 递归删除节点 tmp
remove(tmp.val);
// 用 tmp 覆盖 cur
cur.val = tmp.val;
}
}
}
public class binary_search_tree {
[Test]
public void Test() {
/* 初始化二叉搜索树 */
BinarySearchTree bst = new BinarySearchTree();
// 请注意,不同的插入顺序会生成不同的二叉树,该序列可以生成一个完美二叉树
int[] nums = { 8, 4, 12, 2, 6, 10, 14, 1, 3, 5, 7, 9, 11, 13, 15 };
foreach (int num in nums) {
bst.insert(num);
}
Console.WriteLine("\n初始化的二叉树为\n");
PrintUtil.PrintTree(bst.getRoot());
/* 查找节点 */
TreeNode? node = bst.search(7);
Console.WriteLine("\n查找到的节点对象为 " + node + ",节点值 = " + node.val);
/* 插入节点 */
bst.insert(16);
Console.WriteLine("\n插入节点 16 后,二叉树为\n");
PrintUtil.PrintTree(bst.getRoot());
/* 删除节点 */
bst.remove(1);
Console.WriteLine("\n删除节点 1 后,二叉树为\n");
PrintUtil.PrintTree(bst.getRoot());
bst.remove(2);
Console.WriteLine("\n删除节点 2 后,二叉树为\n");
PrintUtil.PrintTree(bst.getRoot());
bst.remove(4);
Console.WriteLine("\n删除节点 4 后,二叉树为\n");
PrintUtil.PrintTree(bst.getRoot());
}
}
🔎8.优点和缺点
二叉树是一种重要的数据结构,其优点和缺点如下:
优点:
-
二叉树的结构简单,易于理解和实现。
-
二叉树的查询效率高,时间复杂度为O(log n)。
-
二叉树的节点数目不受限制,可以存储大量数据。
-
二叉树支持插入、删除、查找等操作,方便数据的动态管理。
缺点:
-
二叉树的平衡性不好,容易出现极端情况,导致查询效率下降。
-
二叉树的插入、删除操作需要进行大量的节点移动,时间复杂度较高。
-
二叉树的节点数目过多,会占用大量的存储空间。
-
二叉树不支持动态扩容,需要事先确定节点数目。
🔎9.应用场景
二叉树是一种常见的数据结构,在许多应用程序中使用。下面是一些二叉树的应用场景:
-
二叉搜索树 (BST):它是一种特殊的二叉树,其中每个节点都包含一个键,并且左子树上的每个键都小于父节点的键,右子树上的每个键都大于父节点的键。BST可以用于实现高效的查找,插入和删除操作。
-
堆:它是一种二叉树,其中每个节点都比它的子节点更大(大根堆)或更小(小根堆)。堆可以用于实现高效的优先队列,例如在操作系统中调度进程时。
-
表达式树:它是一种二叉树,用于表示一个算术表达式。每个叶节点表示一个操作数,每个内部节点表示一个运算符。表达式树可以用于计算表达式的值。
-
平衡树:它是一种特殊的二叉树,旨在确保树的高度相对较小,从而提高查找,插入和删除的效率。例如,AVL树和红黑树就是平衡树。
-
前缀树:也称为Trie树,它是一种多叉树,用于存储字符串集合。前缀树可以用于实现高效的字符串匹配,最长前缀查找和自动完成等操作。
这只是二叉树的一部分应用场景,实际上在数据结构和算法中,二叉树被广泛应用。
🚀感谢:给读者的一封信
亲爱的读者,
我在这篇文章中投入了大量的心血和时间,希望为您提供有价值的内容。这篇文章包含了深入的研究和个人经验,我相信这些信息对您非常有帮助。
如果您觉得这篇文章对您有所帮助,我诚恳地请求您考虑赞赏1元钱的支持。这个金额不会对您的财务状况造成负担,但它会对我继续创作高质量的内容产生积极的影响。
我之所以写这篇文章,是因为我热爱分享有用的知识和见解。您的支持将帮助我继续这个使命,也鼓励我花更多的时间和精力创作更多有价值的内容。
如果您愿意支持我的创作,请扫描下面二维码,您的支持将不胜感激。同时,如果您有任何反馈或建议,也欢迎与我分享。

再次感谢您的阅读和支持!
最诚挚的问候, “愚公搬代码”

- 点赞
- 收藏
- 关注作者
评论(0)