Python案例|Pandas正则表达式


字符串的处理在数据清洗中占比很大。也就是说,很多不规则的数据处理都是在对字符串进行处理。Excel提供了拆分、提取、查找和替换等对字符串处理的技术。在Pandas中同样提供了这些功能,并且在Pandas中还有正则表达式技术的加持,让其字符串处理能力更加强大。
01、正则
正则就是正则表达式(Regular Expression)的简称,它是一种强大的文本处理技术。正则表达式描述了字符串匹配的模式(Pattern),可以用来检查一个字符串是否含有某种子字符串,对匹配成功的字符串可以进行提取、拆分、查找和替换等处理。大部分的编程语言支持正则表达式,匹配规则也基本相同,但不同编程语言的处理方式略有不同。
在实际工作中,用户需要的多条有用信息很可能会混杂在一起,要将这些杂乱的数据整理规范,很可能就需要正则表达式的加持。在Pandas中提供的很多关于文本处理的函数支持正则表达式,所以在讲解Pandas的文本处理函数之前,首先要详细了解正则表达式技术。
1●正则表达式的导入与创建
要在Python中使用正则表达式,首先要导入re库,它是Python的内置库,也就是说不需要用户安装; 接下来演示一下直接导入使用和通过编译后再使用两种方法。
1.直接导入使用
在导入re库之后,直接使用re.函数()的方式来使用正则表达式,例如使用re.findall()函数,示例代码如下:
import re #导入正则表达式库
print (re.findall(r' d','9527') ) #直接调用正则表达式函数使用
print (re.findall(r' d','5201314')) #直接调用正则表达式函数使用
运行结果如下:

2.通过编译使用
如果需要重复使用一个正则表达式对象,则可以将正则表达式预编译成正则表达式对象,这样效率更高。在导入re库后,将正则表达写入re.compile()函数,然后生成正则表达式对象,再调用这个对象中的函数进行处理,示例代码如下:
import re #导入正则表达式库
pat=re.compile(r'\d') #使用 compile 函数生成正则表达式对象
print(pat.findall('5201314')) #调用编译后的正则表达式对象中的函数使用
print (pat.findall('9527') ) #调用编译后的正则表达式对象中的函数使用
运行结果如下:
预编译的方式也可以直接写成一条代码,如re.compile(r'\d').findall('9527')。不管正则表达式采用何种调用方式,始终脱离不了以下三要素。
(1) 正则表达式字符串。如r'\d',单引号中的字符串表明匹配规则,\d是查找单个数字的意思。
(2) 正则表达式被匹配的字符串。如'9527',对'9527'执行r'\d' 的匹配,意思就是查找'9527'中有多少个单数字。
(3) 匹配成功后的处理方式。例如调用findall()函数,表示如果匹配成功,则将查找出来的单个数字存储在列表中。
在上面的三要素中,需要重点学习正则表达式字符串的编写规则,以及匹配成功后的处理方式。
2●正则表达式处理函数
本来应该先讲解正则表式的编写规则,但读者可能更希望正则表达式匹配成功后,能看到对应的处理结果,这样能有更直观的感受,所以本节先讲解正则表达式的常用函数。
本节在讲解正则表达式函数时,会分别讲解直接写法(re.函数())和预编译写法(regex.函数())两种形式,虽然这两种书写形式对应的函数名一样,功能也一样,但函数的参数略有差异。
在Python的正则表达式中,使用不同函数,其返回的数据类型也不一样,例如返回re.Match(匹配对象)、list(列表)、iterator(迭代器)、str(字符串)等,其中返回的re.Match匹配对象存储有更多信息。
1. 从开始位置匹配(match()函数)
如果希望从字符串的开始位置匹配,则可以使用match()函数。如果匹配成功,则match()函数返回的是一个re.Match匹配对象。
1) re.match()函数
re.match()函数的参数说明如下。
re.match(pattern, string, flags=0)
pattern: 匹配的正则表达式。
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,见表1。
■ 表1 常见正则表达式flags的匹配模式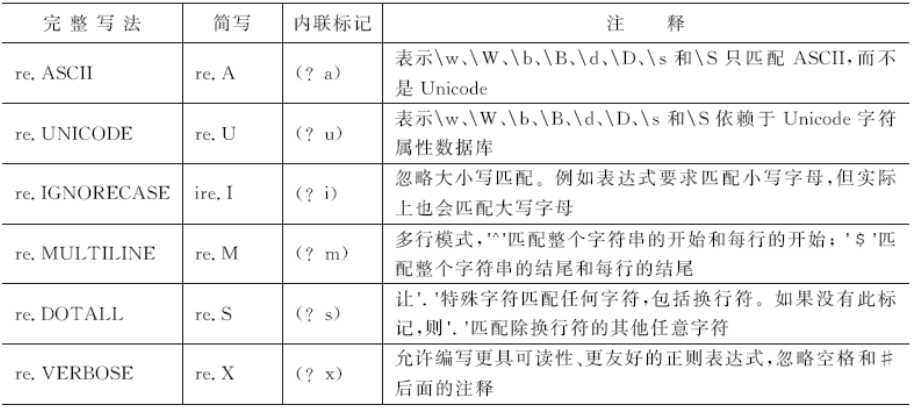
re.match()函数的示例代码如下:
import re #导入正则表达式库
print(re.match(r'apple','apple 苹果') ) #在'apple 苹果'字符串中以 apple'开头
print (re.match(r'苹果','apple 苹果')) #在'apple 苹果,字符串中以,苹果'开头运行结果如下:

2) regex.match()函数
regex.match()函数的参数说明如下。
regex.match(string[, pos[, endpos]])
string: 必选,被匹配的字符串。
pos: 可选,指定起始位置。
endpos: 可选,指定结束位置。
注意: regex为正则表达式对象的统称。
regex.match()函数的示例代码如下:
import re #导入正则表达式库
print(re.compile(r'apple').match('apple 苹果')) #在'apple 苹果'字符串中以apple'开头
print(re.compile(r'苹果') .match('apple 苹果')) #在'apple 苹果,字符串中以,苹果"开头通过运行结果发现,第1个测试匹配成功,返回re.Match对象,其中span=(0, 5)表示匹配成功的字符串的起止位置。第2个测试没有匹配成功,返回值为None。
还有一个与match()函数相似的fullmatch()函数,该函数完整匹配整个字符串。先演示一下re.fullmatch()函数,示例代码如下:
import re #导入正则表达式库
print (re.fullmatch(r'apple 苹果',apple 苹果')) #在 apple 苹果'字符串中匹配apple 苹果,
print (re.fullmatch (r'apple','apple 苹果') ) #在 apple 苹果,字符串中匹配
'apple'运行结果如下:

接下来演示regex.fullmatch()函数,示例代码如下:
import re #导入正则表达式库
print (re.compile(r'apple 苹果').fullmatch('apple 苹果')) #在'apple苹果'字符串中匹配'apple 苹果
print(re.compile(r'apple') .fullmatch('apple 苹果')) #在 apple 苹果'字符串中匹配'apple
运行结果如下:
通过上面的示例会发现,只有完整匹配了整个字符串,才能匹配成功,否则返回值为None,并且在示例中会发现,只有匹配的字符串与被匹配的字符串相等才可以成功。是不是匹配与被匹配的字符串一定要相等呢? 其实并非如此,可以写更复杂的正则表达式字符串,只要从开头到结尾都能匹配成功就可以。
2. 从任意位置匹配(search()函数)
match()函数必须从指定的起始位置开始匹配,如果希望从任意位置开始匹配,则可以使用search()函数。如果匹配成功,则返回re.Match配匹对象,否则返回值为None。
1) re.search()函数
re.search()函数的参数说明如下。
search(pattern, string, flags=0)
pattern: 匹配的正则表达式。
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,见表6-1。
re.search()函数的示例代码如下:
import re #导入正则表达式库
print (re.search(r'apple',3 个apple苹果')) #在3个apple 苹果'字符串中搜索apple"
print(re.search(r'apple',apple 苹果3 个')) #在3个apple 苹果'字符串中搜索apple"
print (re.search(r'梨子','apple 苹果3个')) #在'apple 苹果3 个1字符串中搜索'梨子2) regex.search()函数
regex.search()函数的参数说明如下。
regex.search(string[, pos[, endpos]])
string: 必选,被匹配的字符串。
pos: 可选,指定起始位置。
endpos: 可选,指定结束位置。
regex.search()函数的示例代码如下:
import re#导入正则表达式库
print(re.compile(r'apple').search('3 个apple苹果')) #在3个apple苹果'字符串中搜索'apple'
print(re.compile(r'apple').search('apple 苹果3个')) #在3个apple苹果'字符串中搜索'apple'
print(re.compile(r'梨子').search('apple 苹果3个')) #在apple苹果3 个1字符串中搜索,梨子|通过上面的示例会发现,只要被搜索的字符串包含要查找的字符串,最后都能匹配成功,并且返回re.Match对象。
注意: match()函数和search()函数在进行匹配时,可能有多个对象符合匹配要求,但只返回第1个匹配成功的re.Match对象。
3. 用列表存储匹配成功的值(findall()函数)
前面学习的match()函数和search()函数只返回第1次匹配成功的re.Match 对象,如果希望返回所有匹配成功的数据,则可以使用findall()函数,返回的结果是列表类型; 如果没有匹配成功,则返回空列表。
注意,findall()函数匹配出的数据只是从re.Match对象中提取出的信息之一。
1) re.findall()函数
re.findall()函数的参数说明如下。
re.findall(pattern,string,flags=0)
pattern: 匹配的正则表达式。
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,见表1。
re.findall()函数的示例代码如下:
txt='张三2李四3 王五 4 陈小兵 15 大龙' #被匹配的字符串
print (re.findall(r' D+\d+',txt)) #常规匹配
print (re.findall(r'(\D+)\d+',txt))#添加 1 组括号
print (re.findall(r'(\D+) (\d+)',txt)) #添加 1组以上括号
运行结果如下:

2) regex.findall()函数
regex.findall()函数的参数说明如下。
regex.findall(string[, pos[, endpos]])
string: 待匹配的字符串。
pos: 可选参数,指定字符串的起始位置,默认值为0。
endpos: 可选参数,指定字符串的结束位置,默认值为字符串的长度。
regex.findall()函数的示例代码如下:
import re #导入正则表达式库
txt='张三2李四3 王五 4 陈小兵 15 大龙' #被匹配的字符串
print (re.compile(r'\D+\d+') .findall(txt))#添加 1 组括号
print (re.compile(r'(\D+) d+') .findall(txt)) #常规匹配
print(re.compile(r'(\D+) (\d+)').findall(txt)) #添加1组以上括号
通过上面的示例会发现,findall()函数如果没有分组,则直接返回匹配成功的所有字符串; 如果只有1个分组,则将分组中的值返回到列表; 如果多于1个分组,则列表中的每个元素是元组,元组中的元素就是每个分组中的值。
注意: findall()函数中的正则表达式字符是'\D+\d+ ',表示匹配连续的非数字和连续的数字,后面在讲解正则表达式元字符时,会详细讲解\D与\d。
4. 用迭代器存储匹配成功对象(finditer()函数)
finditer()函数与findall()函数的功能类似,其主要区别在于findall()函数匹配成功后返回的是列表,列表中存储的是匹配成功的数据; 而finditer()函数匹配成功后返回的是迭代器,迭代器中存储的是匹配成功的re.Match对象。
1) re.finditer()函数
re.finditer()函数的参数说明如下。
re.finditer(pattern, string, flags=0)
pattern: 匹配的正则表达式。
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,见表1。
re.finditer()函数的示例代码如下:
import re #导入正则表达式库
txt='张三2李四3 王五 4 陈小兵 15 大龙' #被匹配的字符串
print (re.finditer(r'\D+\d+',txt)) #常规匹配
print (re.finditer(r'( D+)\d+'txt)) #添加 1组括号
print (re.finditer(r'(\D+) (\d+)',txt)) :#添加 1 组以上括号
运行结果如下:

2) regex.finditer()函数
regex.finditer()函数的参数说明如下。
regex.finditer(string[, pos[, endpos]])
string: 待匹配的字符串。
pos: 可选参数,指定字符串的起始位置,默认值为 0。
endpos: 可选参数,指定字符串的结束位置,默认值为字符串的长度。
regex.finditer()函数的示例代码如下:
import re #导入正则表达式库
txt='张三 2 李四3 王五 4 陈小兵 15 大龙' #被匹配的字符串
print (re.compile(r' D+ \d+') .finditer(txt))#常规匹配
print (re.compile(r'(\D+)\d+') .finditer(txt))print (re.compile(r'(\D+) #添加 1 组括号(\d+)').finditer(txt)) #添加1组以上括号运行结果如下:

通过上面的示例会发现,返回的是callable_iterator object(迭代器对象),迭代器中存储的是每个匹配成功的re.Macth对象。也就是说finditer()函数与findall()函数相比而言,能获取更多的信息。
finditer()函数匹配成功后,可以用循环语句读取迭代器中的数据,也可以用list()函数对迭代器进行转换,示例代码如下:
import re #导入正则表达式库
txt='张三2李四3 王五 4 陈小兵 15 大龙' #被匹配的字符串
print (list (re.compile(r'\D+\d+').finditer(txt))) #常规匹配运行结果如下:

观察运行结果可以发现,每次匹配成功后,返回的不是具体的值,而是re.Match对象。

- 点赞
- 收藏
- 关注作者
评论(0)