C++ | 探究拷贝对象时的一些编译器优化

前言
在传参和传返回值的过程中,一般编译器会做一些优化,减少对象的拷贝,这个在一些场景下还是非常有用的
- 经过深度探索类的六大天选之子学习,我们讲到了拷贝构造一些基本概念和调用形式
- 经过构造函数的初始化列表的学习,我们知道了原来祖师爷在构造函数里还藏着这么个东西
- 经过explicit关键字的学习,我们清楚了可以手动去禁用构造函数的隐式转换,本文继续细谈
- 经过类中的static成员的学习,我们认识到类中的这两个双胞胎还真是不可分离
本文,我们将在前面的基础上继续展开学习,去探究一下拷贝构造在拷贝对象时会发生一些编译器优化
- 之前我们在讲
explicit关键字的时候,我有提到下面这种写法会引发【隐式类型转换】,而且还画了对应的图示,中间会通过1构造产生一个A类型的临时对象,然后用再去调用拷贝构造完成拷贝。 - [x] 不过这一块编译器做了一个优化,将【构造 + 拷贝构造】直接转换为【构造】的形式,本模块我们就这一块来进行一个拓展延伸,讲一讲编译器在拷贝对象时期的一些优化
A aa1 = 1;
一、传值传参
首先来看到的场景是【传值传参】,对象均是使用上面
aa1
//传值传参
void func1(A aa)
{
}
💬请你思考一下这种形式编译器还会像上面那样去优化拷贝构造吗
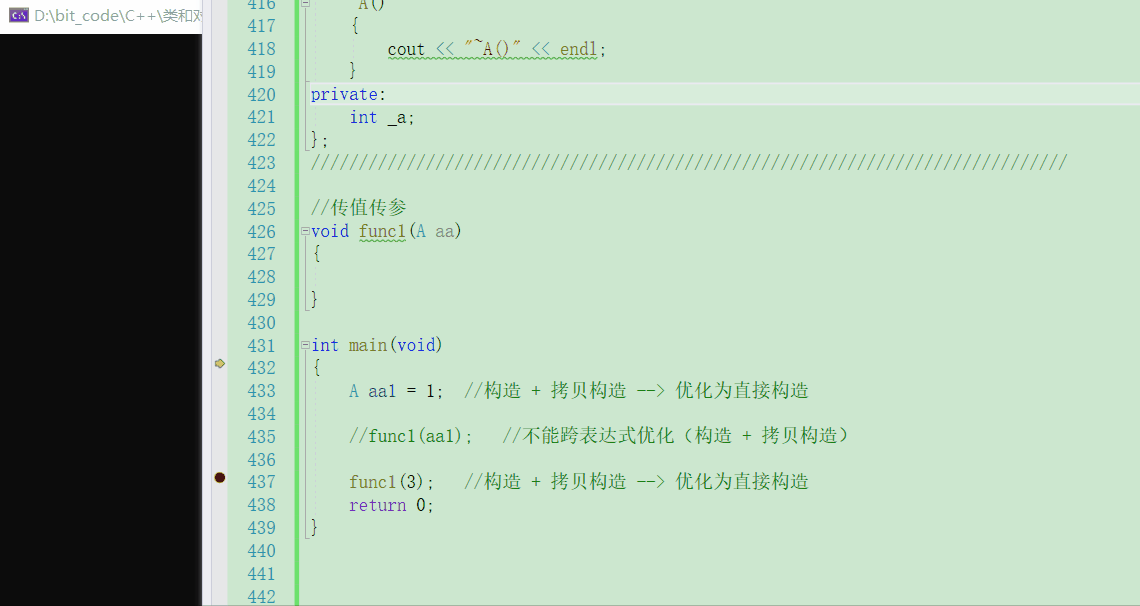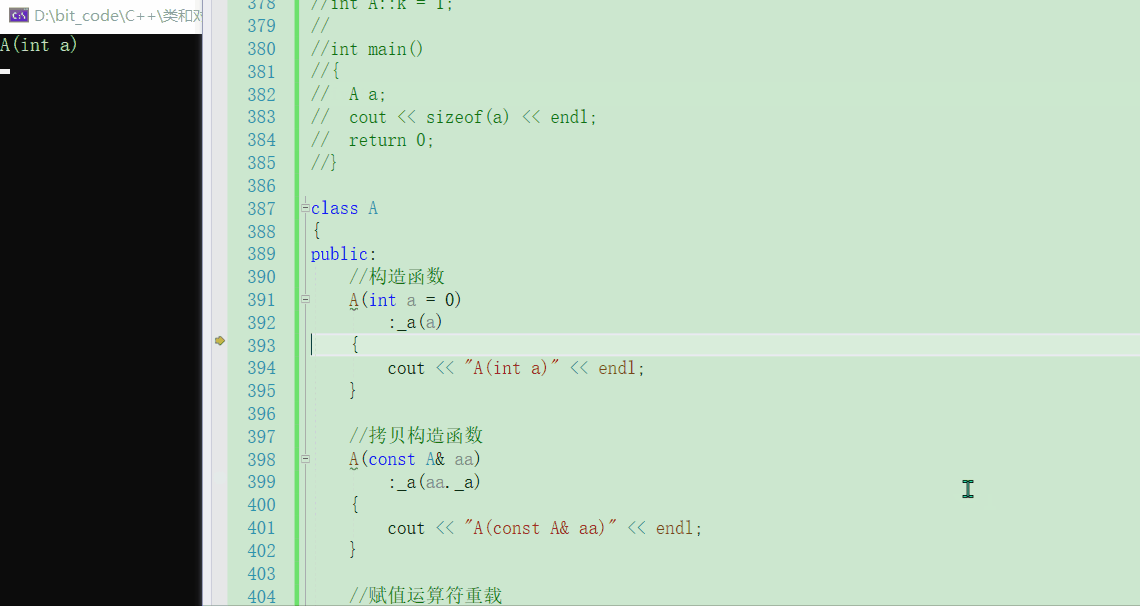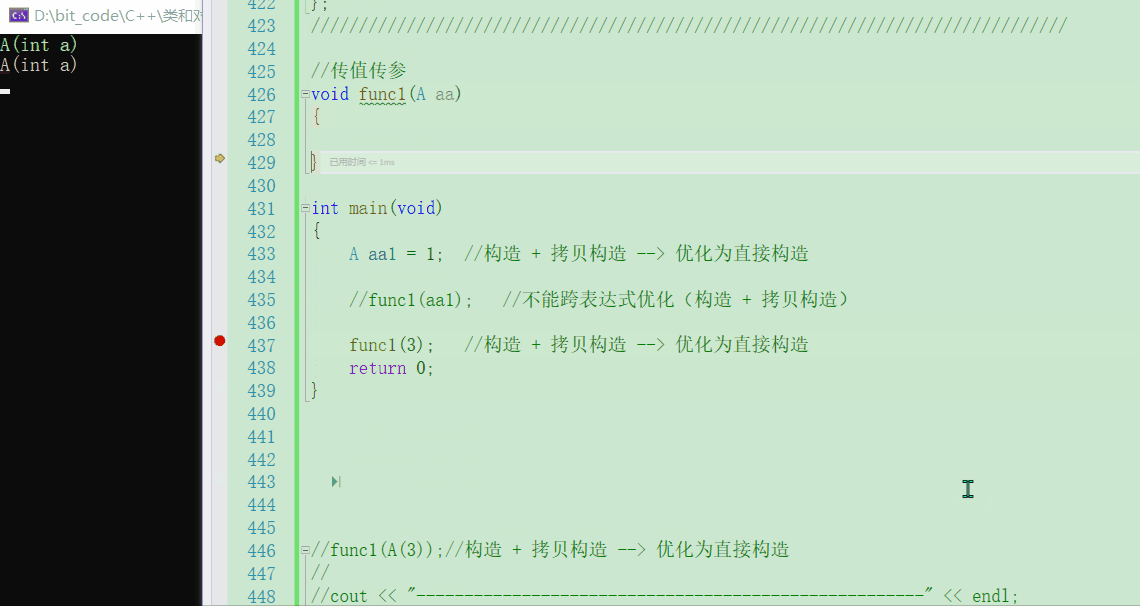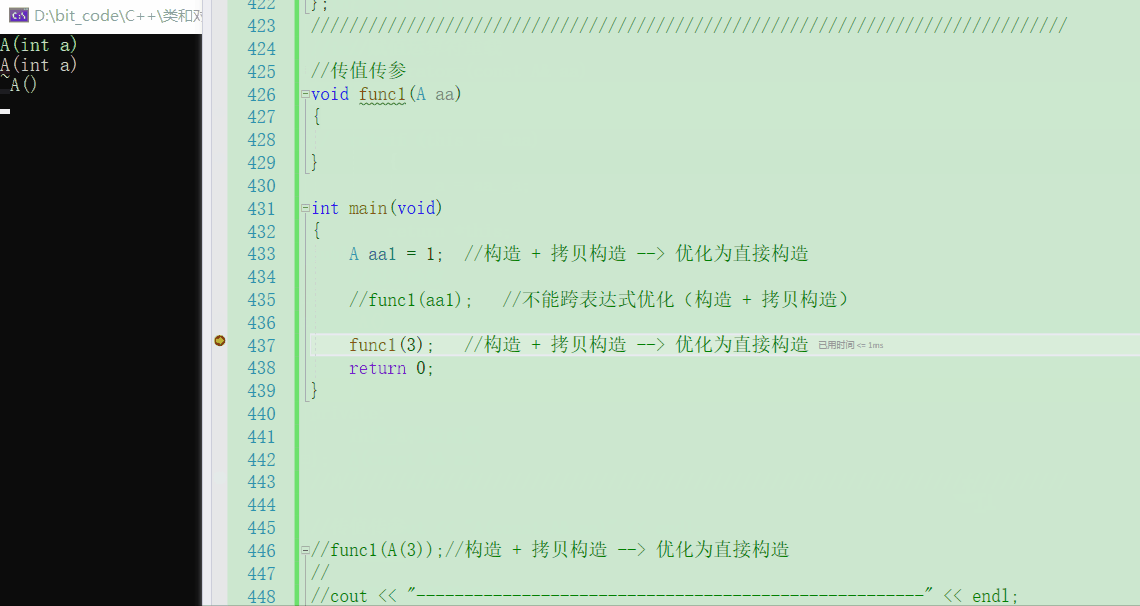
func1(aa1);
- 可以看到,还是发生了拷贝构造,为什么呢?因为对于这种形式编译器不会去随意优化,只有像上面在一个表达式内才会去进行一个优化。【这里的析构是针对函数内部的形参
aa,main函数中的aa1也会析构,不做展示】

💬那如果直接传入一个3呢,会做优化吗?
func1(3);
- 可以看到,若是直接传入3的话,就不会去调用拷贝构造了,这个其实和一开始我们讲得那个差不多,把构造 + 拷贝构造优化成了==直接构造==,【一开始的构造不用理他,为了构造出
aa1对象】
💬接下去我传入一个A(3),会发生什么呢?
func1(A(3));
- 通过观察可以发现,和上面那个是一样的,其实读者去演算一下就可以很清楚,
A(3)就是一个很明显的有参构造,实例化出一个对象后那就是拷贝构造,但是这里因为编译器的优化,所以直接变成了一个构造

二、传引用传参
接下去来看到的场景是【传引用传参】,传入的值还是上面的这三种,只是会通过传引用来接收
- 之前的文章里有说过为什么在传参的时候最好使用【传引用传参】,原因就是在于可以减少拷贝,提高程序运行效率
//传引用传参
void func2(const A& aa) //不加const会造成权限放大
{
}
💬那通过引用接收aa1会发生什么呢?
func2(aa1);
- 通过观察可以发现,无论是【构造】还是【拷贝构造】,都不会去调用,这是为什么呢?
- [x] 原因就在于这里使用的是引用接收,那么形参部分的
aa就是aa1的别名,无需构造产生一个新的对象,也不用去拷贝产生一个,直接用形参部分这个就可以了,现在知道引用传参的好处了吧👈

💬那直接传3呢?又会发生什么?
func2(3);
- 观察得到,临时对象还是会去进行构造,不过因为引用接收的缘故,我里面的
aa就是这个临时对象的别名,所以无需调用拷贝构造,所以也是当回到主函数中才调用析构函数,此时析构的就是这个临时对象 - 这里要顺便提一句的是,因为这个临时对象,临时对象具有常性,所以在拷贝构造的参数中一定要使用
const做修饰,否则就会造成==权限放大==

💬那么A(3)也是和上面同样的道理
func2(A(3));
- 这里操作得有点快了,读者可以试着自己去慢慢调试观察,因为函数内部的对象
a是外部匿名对象的引用,所以可以看到在函数内部并没有去调用析构,而是在创建匿名对象这一行结束才去调用的析构,那这两个对象就一同被析构了

看完【传值传参】和【传引用传参】,我们来总结一下
- [x] 在为函数传递参数的时候,尽量使用引用传参,可以减少拷贝的工作
三、传值返回
接下去我们来讲讲函数返回时候编译器优化的场景,首先是【传值返回】
//传值返回
A func3()
{
A aa;
return aa;
}
💬若是直接去调用上面这个func3(),会发生什么呢?
func3();
- 这个其实和传值传参的第一个是一样的,因为在函数中对象和返回不是处于同一个表达式,所以编译器不会产生优化,调试结果如下
- 再补充一句,这里我们可以看到两个析构,第一个是func3()函数内部的局部对象
aa的析构,第二个则是对返回的时候对那个临时对象的一个析构

💬此处在函数调用的地方我使用一个对象去做了接收,那在上面【构造 + 拷贝构造】的基础上就会再多出一个【拷贝构造】,即为【构造 + 拷贝构造 + 拷贝构造】
A aa2 = func3();
- 不过通过调试可以看出,只进行了一次拷贝构造,这里其实就存在编译器对于【拷贝构造】的一个优化工作,将两个拷贝构造优化成了一个拷贝构造

这里可能比较抽象,我画个图来解说一下
- [x] 可以看到,因为这是一个传值返回,所以一定会在构造产生临时对象。第一个是因为
aa与A不是同一个表示式,所以不会引发编译器的优化;对于第二个来说,因为又拿了一个A的对象作为接收,所以又会产生一个拷贝构造。在这里编译器就要出手了,它会觉得两个拷贝构造过于麻烦,所以会直接优化成一个
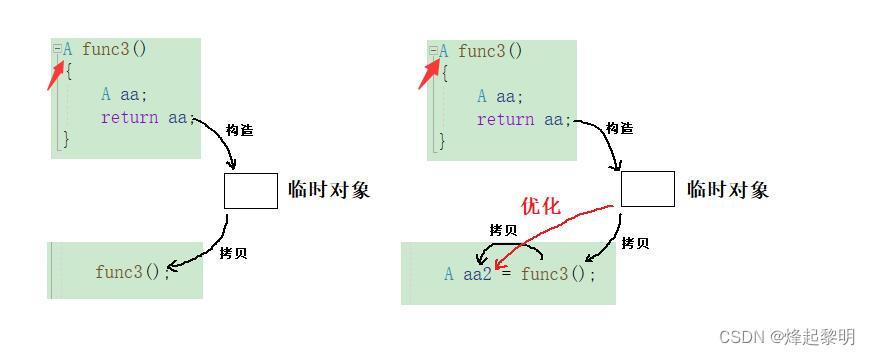
拷贝构造和赋值重载的辨析
- 学习过【拷贝构造】和【赋值重载】的同学应该可以知道,它们的形式很像,若是一个对象还没有被实例化出来,使用
=便是拷贝构造;若是一个对象已经实例化出来了,使用=便是赋值重载
A aa2;
aa2 = func3();
- 仔细观察便可以发现,在拷贝构造完成之后又去进行了一次【赋值重载】,那看上面的代码其实就很明显了,那若是一个【拷贝构造】+【赋值重载】的话,编译器其实不会去做一个优化,那这其实相当于干扰了编译器

四、传引用返回【❌】
然后来说说【传引用返回】,不过若是你知道引用返回的一些机制的话,就可以清楚我下面这样其实是错误的,因为
aa属于局部变量,出了当前作用域会销毁,所以不可以使用传引用返回,具体以下细述
A& func4()
{
A aa;
return aa;
}
💬首先来看下直接调用的结果会是怎样的
func4();
- 可以看到因为传引用返回了,所以就减少了中间的一份临时对象的拷贝,也就没有去调用拷贝构造
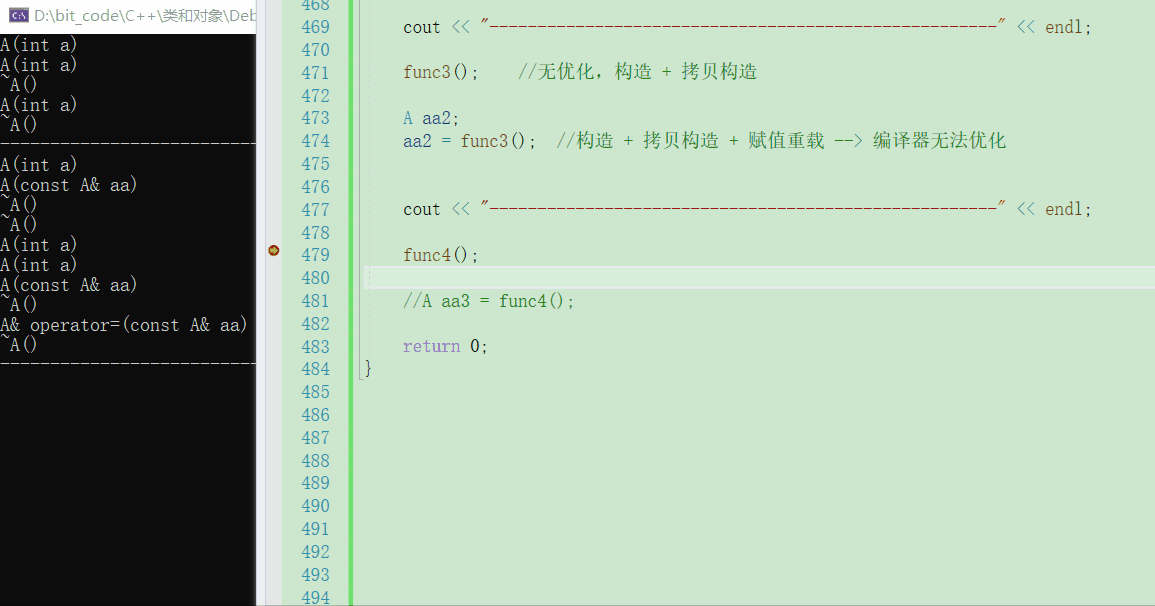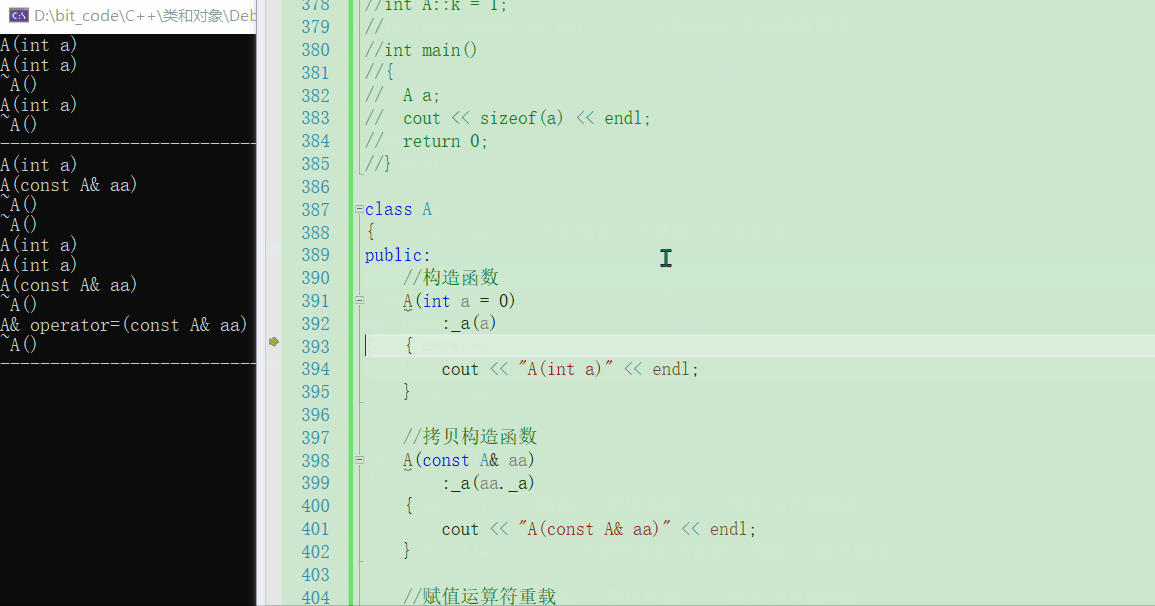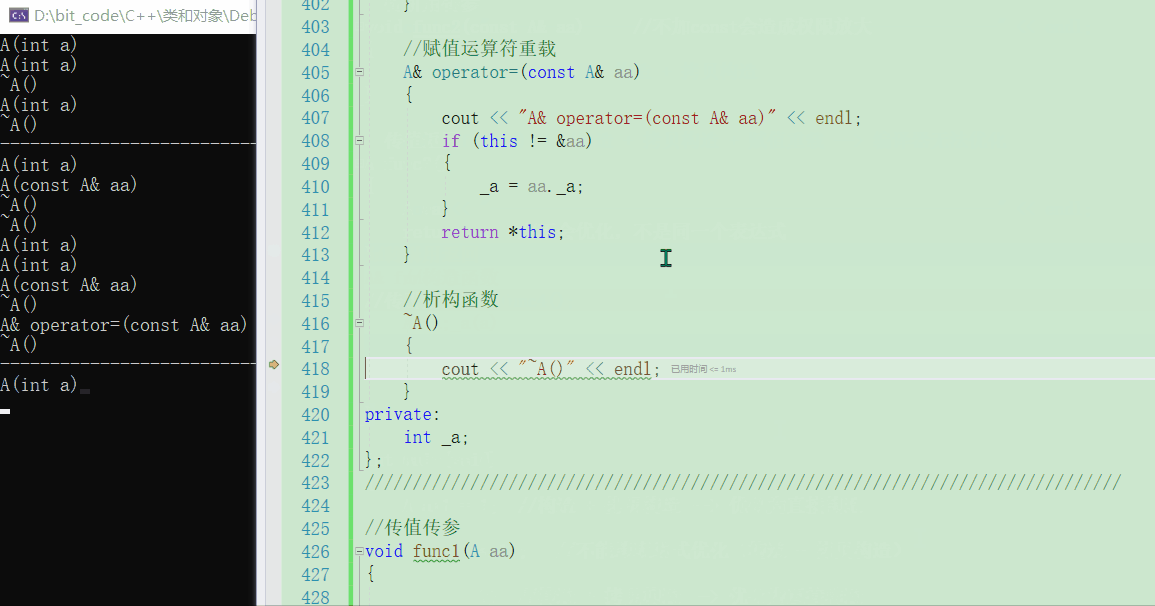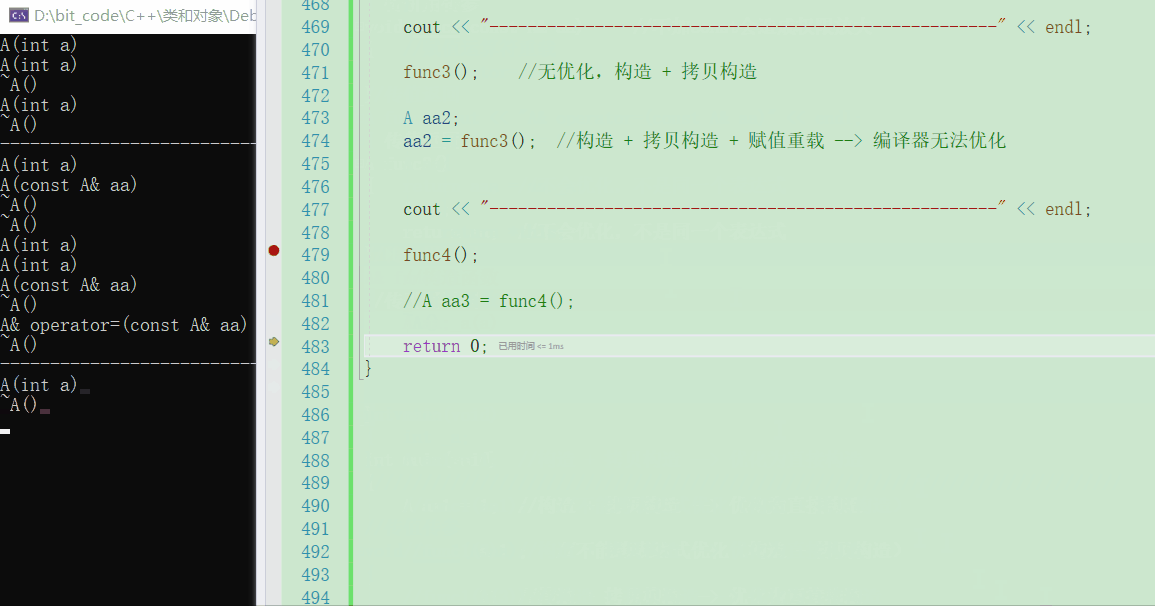
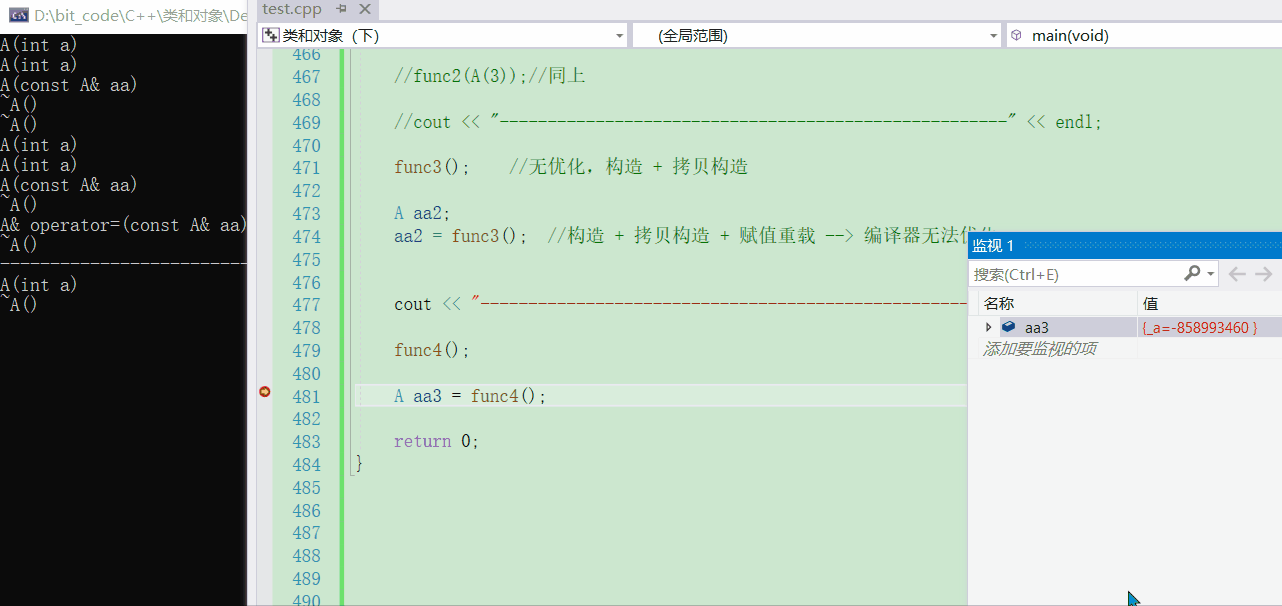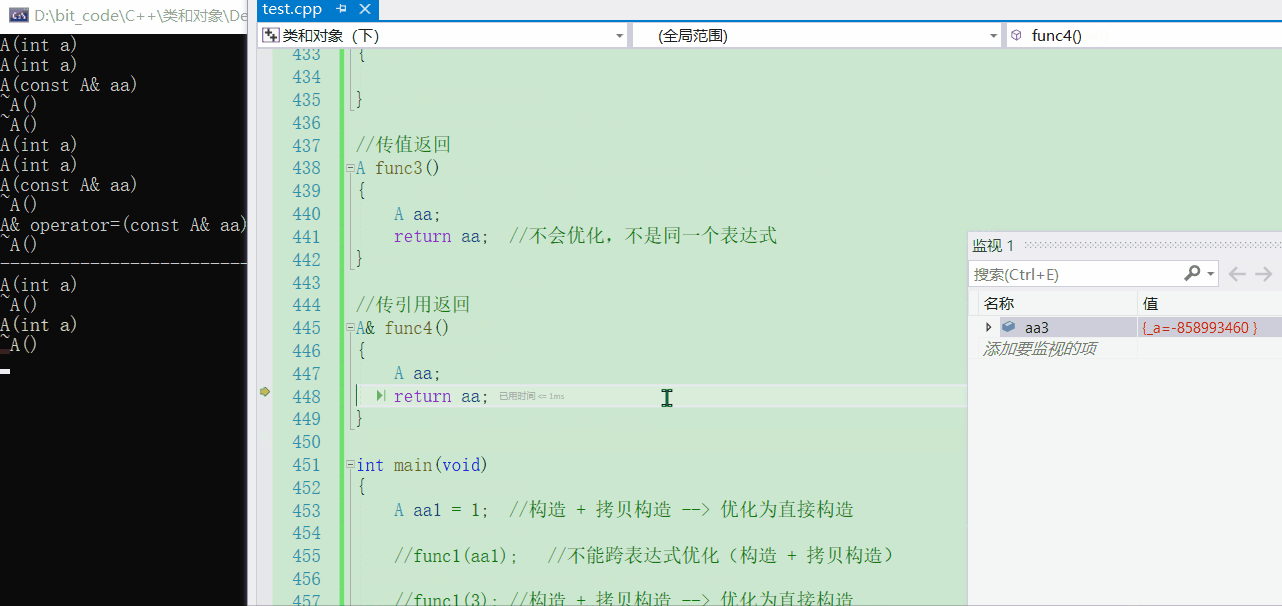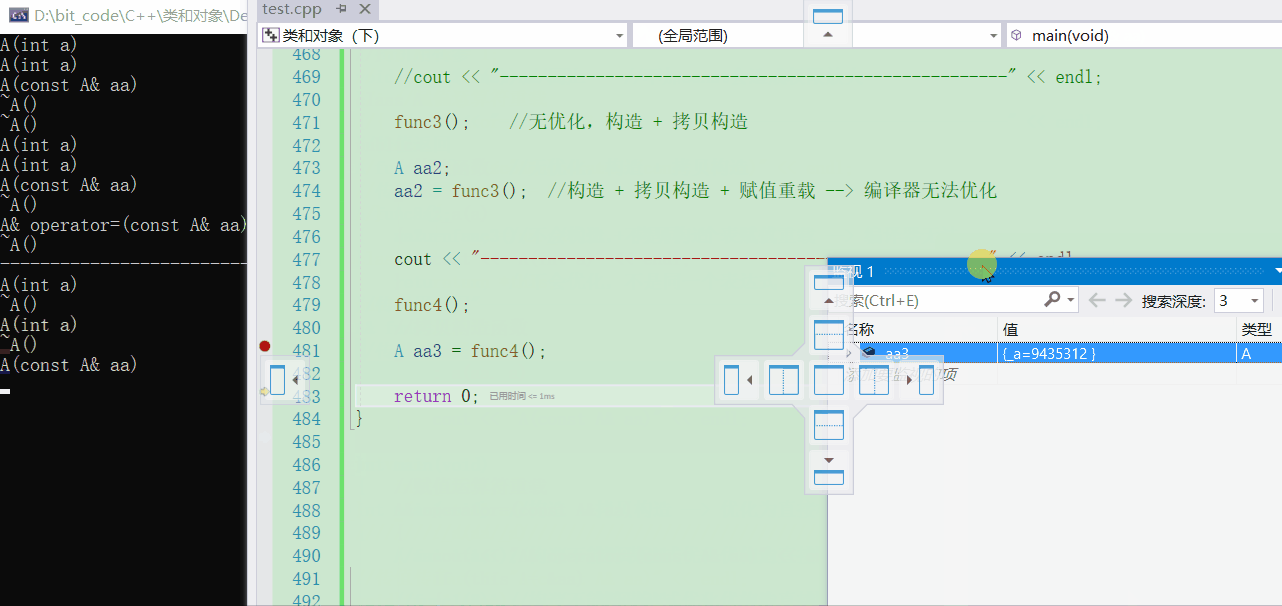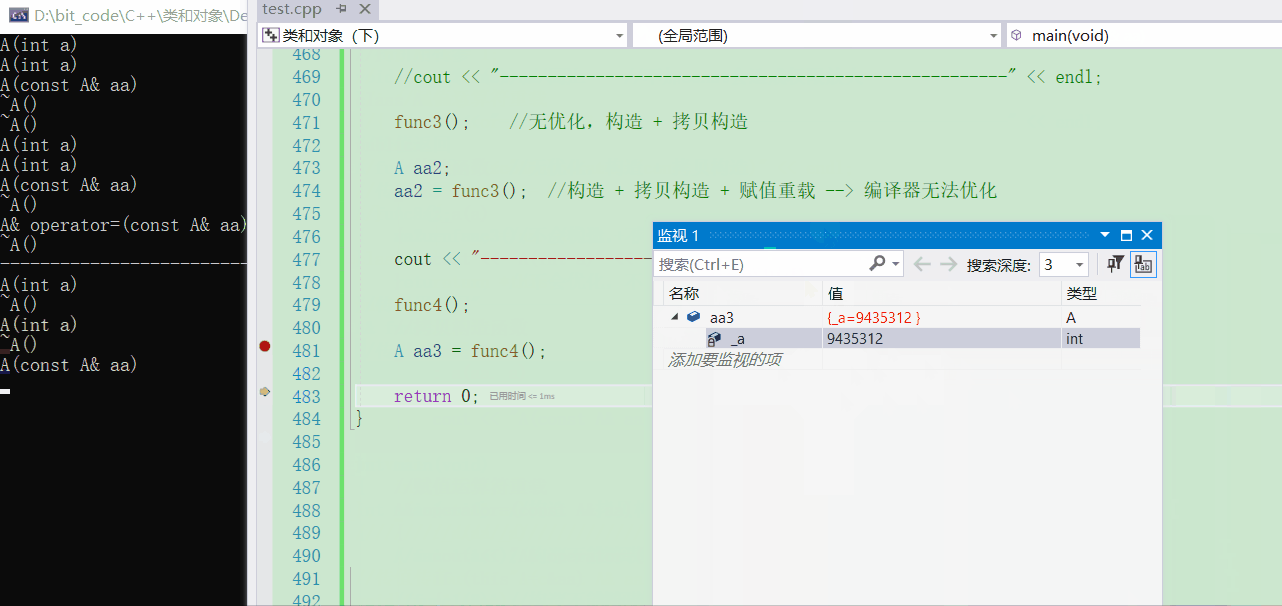
💬那我若是用一个返回值去接收的话,此时就可以看出引用返回临时对象的问题了
A aa3 = func4();
- 可以看到,最后在拷贝构造结束后,对象aa3内部的
_a就是一个随机值
- 若是使用传值返回的话,去观察就可以发现并不是一个随机值
A func4()

五、传匿名对象返回
还记得上面讲到的【匿名对象】吗,也可以使用它返回哦,效率还不低呢!
//匿名对象返回
A func5()
{
return A(); //返回一个A的匿名对象
}
💬先调用一下看看会怎么样
func5();
- 可以看到本质还是传值返回,照理来说会构造出一个临时对象然后在拷贝构造,但是却没有调用拷贝构造,原因就是匿名对象起到的作用,对于
A()你可以就把它看做是一个表达式,一个【构造】+【拷贝构造】就被优化成了==直接构造==
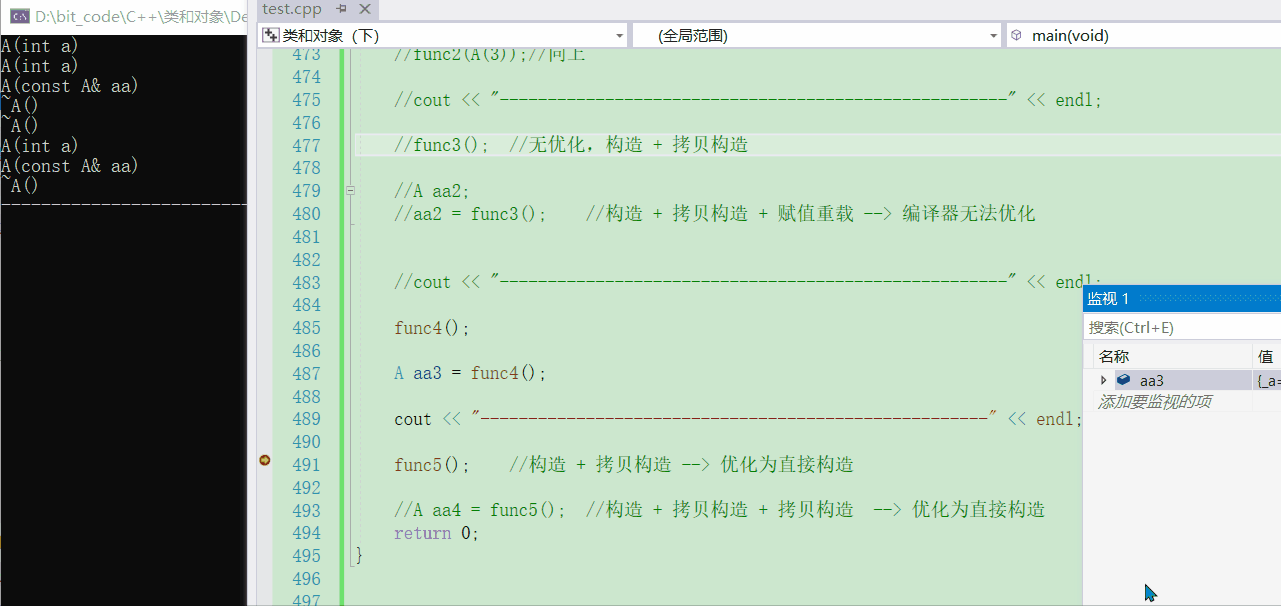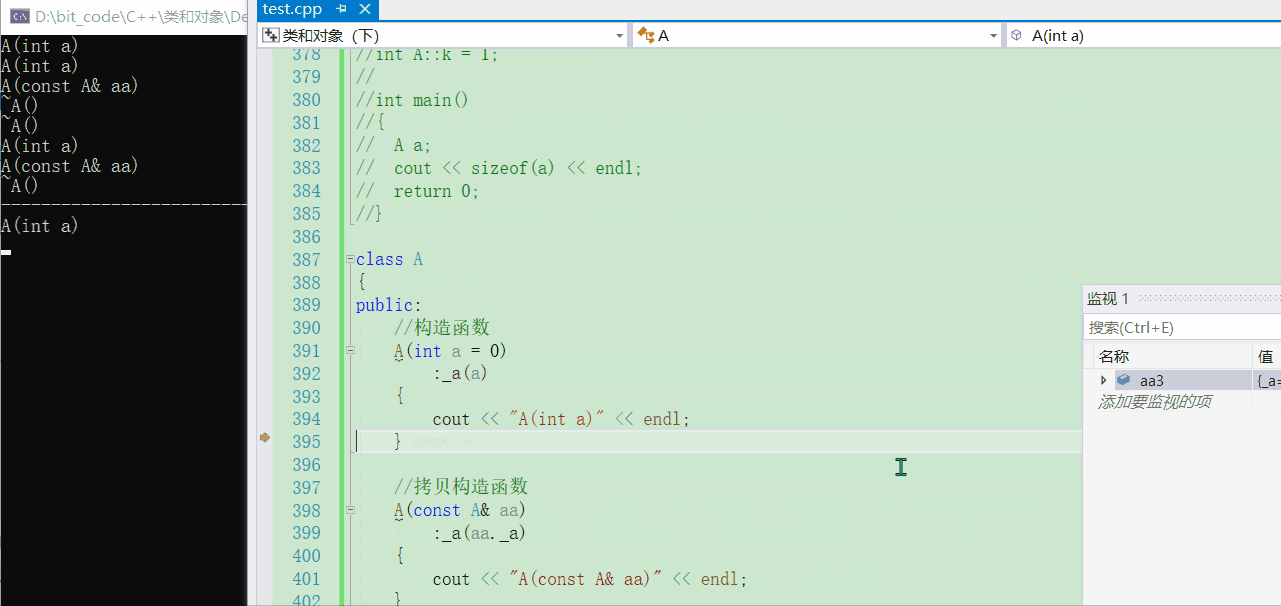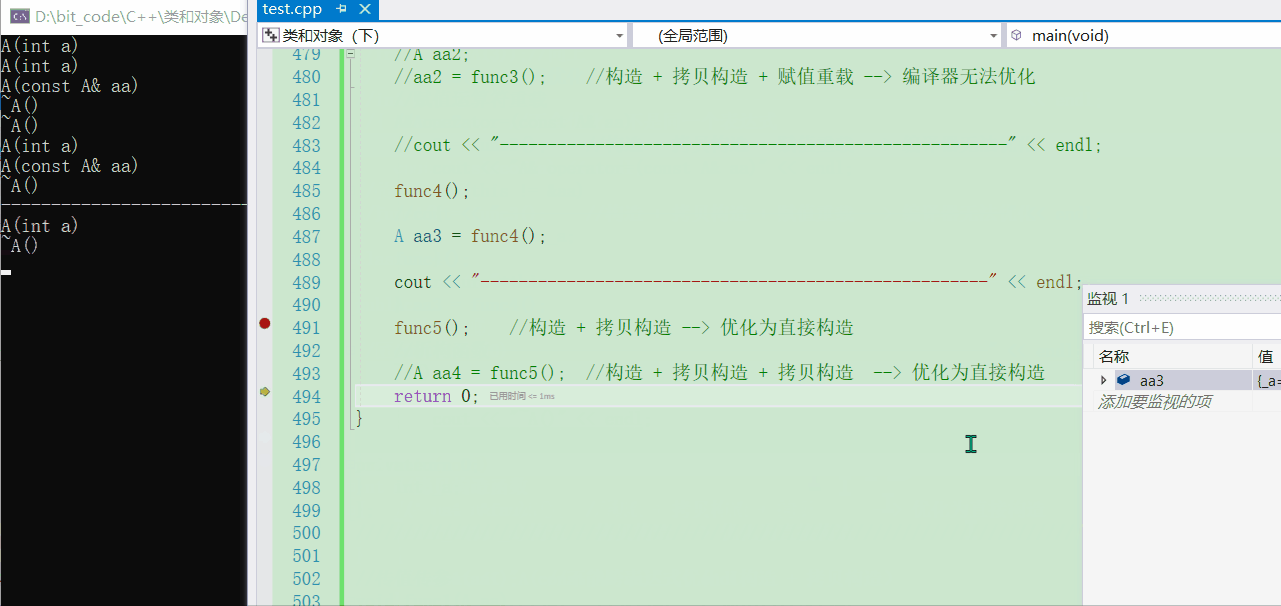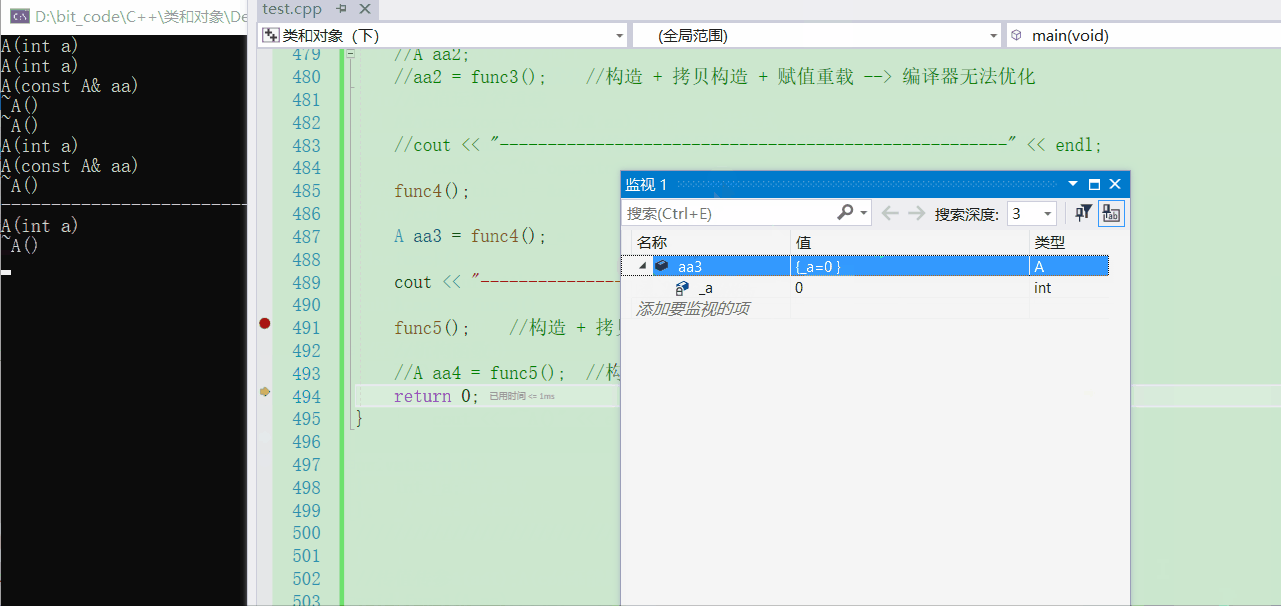
💬如果用返回值去接收呢?编译器会优化到何种程度
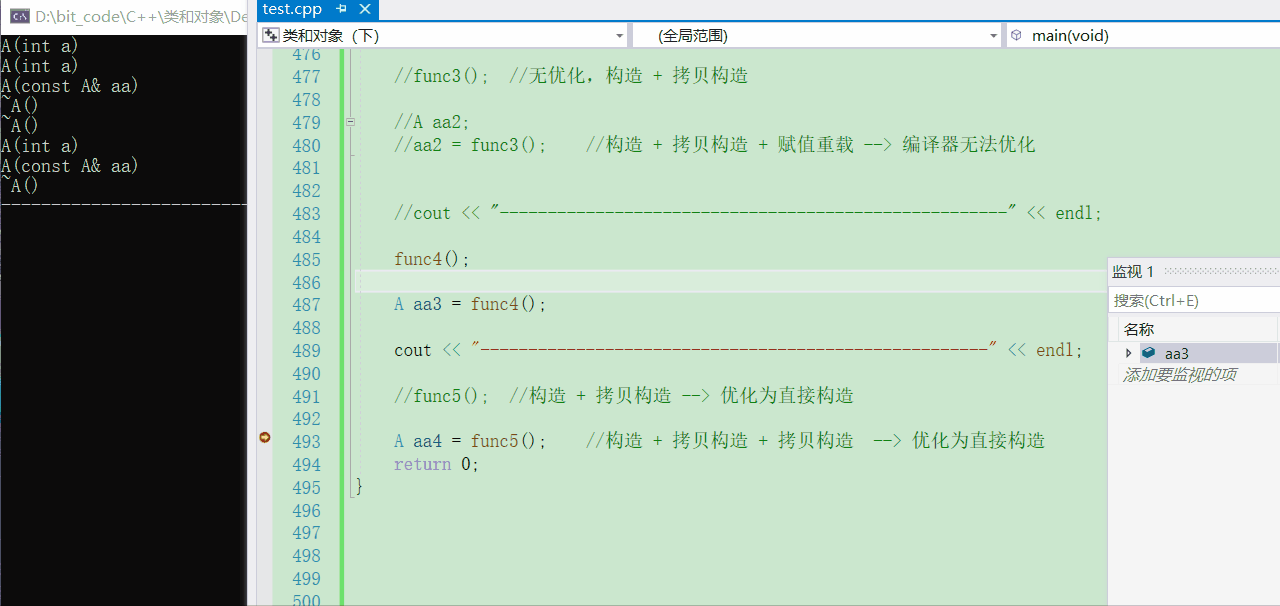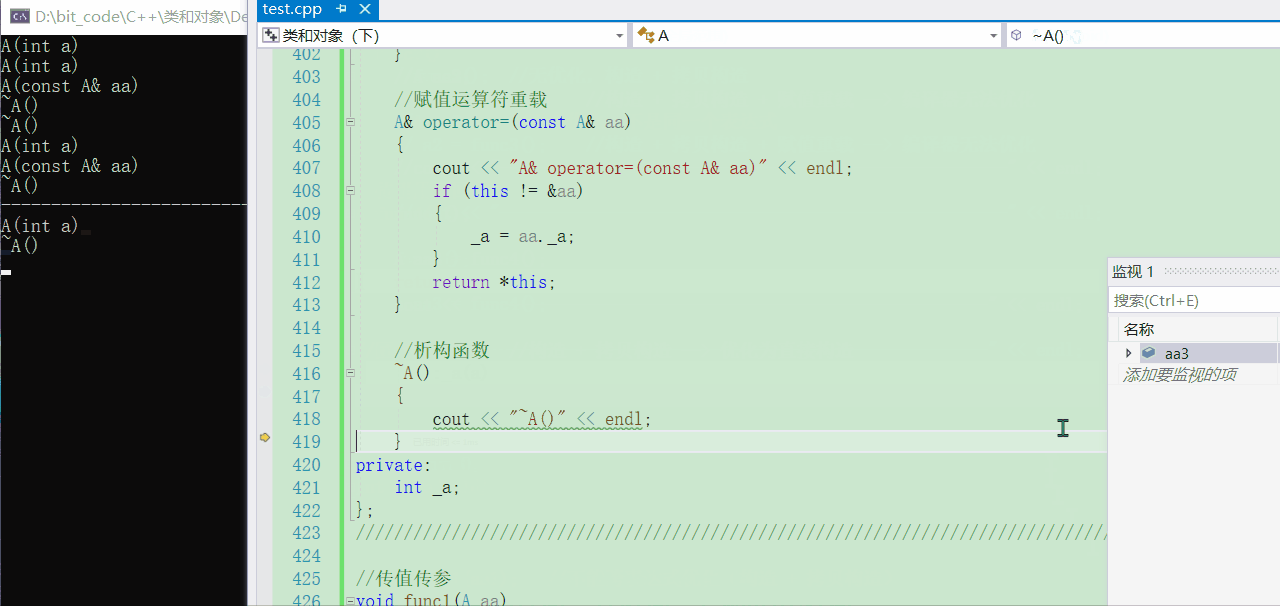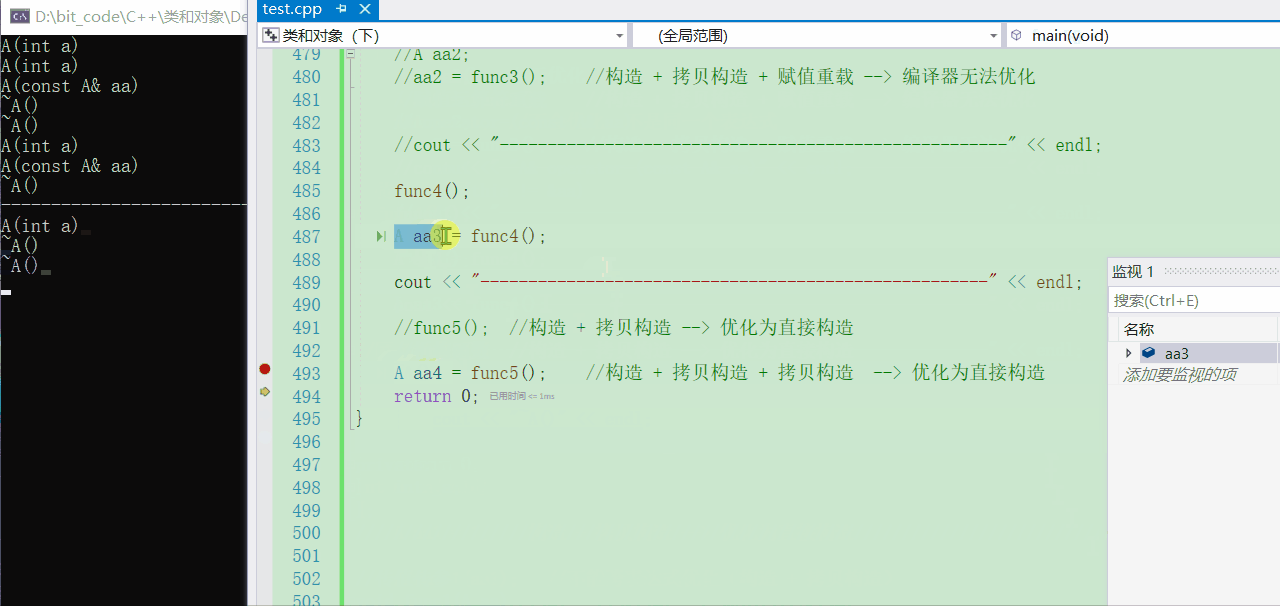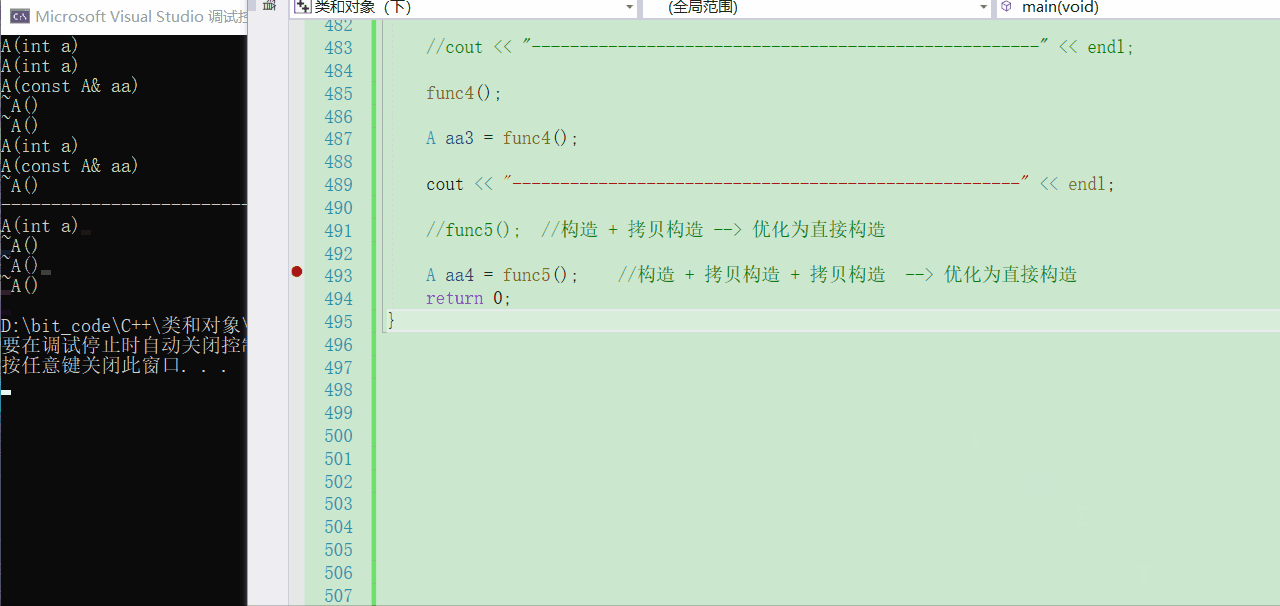
A aa4 = func5();
- 可以看到,竟然也是只有一个构造。照道理分析来看的话应该是【构造 + 拷贝构造 + 拷贝构造】,不过在匿名对象返回那里已经优化成【直接构造】了,然后再外面的【构造 + 拷贝构造】由引起来编译器的优化,==所以最终就只有一个构造了==
- 可以看到,最后我还去调了三次析构函数,第一次就是当然就是
aa4,第二次是aa3,第三次便是一开始就有的aa1了,通过这么调试观察,希望你能真正看懂编译器的思维
而且可以观察到匿名对象返回也不会造成随机值现象,因为本质使用的还是【传值返回】,这里不可以使用【传引用返回】,因为匿名对象构建出来的也是一个临时对象,具有常性,会造成==权限放大==

六、总计与提炼
看完了上面这一些系列拷贝对象时编译器的优化,我们来做一个总结
函数传参总结
- [x] 尽量使用
const+&传参,减少拷贝的同时防止权限放大
对象返回总结
- [x] 接收返回值对象,尽量拷贝构造方式接收,不要赋值接收【会干扰编译器优化】
- [x] 函数中返回对象时,尽量返回匿名对象【可以增加编译器优化】
以上就是本文要介绍的所有内容,感谢您的阅读:rose:

- 点赞
- 收藏
- 关注作者
评论(0)