数据分析实战│价格预测挑战


文本分析是指对文本信息的表示及特征项的选取,商品文本的描述能够反映特定立场、观点、价值和利益。考虑到网上海量的商品数量,对产品的定价难度很大,因此可以使用商品描述帮助商户定价。比如,服装具有较强的季节性价格趋势,受品牌影响很大,而电子产品则根据产品规格波动。因此,根据商品提供的文本信息进行合理地定价,能够有效地帮助商家进行商品的销售。
01、问题描述及数据挖掘目标
本案例给出物品的商品描述、商品类别和品牌等信息,并结合之前的商品价格来给新商品定价格。
02、数据导入和预处理
导入数据处理阶段使用的库函数,numpy和pandas用于数据处理
import numpy as np
import pandas as pd使用pandas库的read_csv函数导入数据,示例代码中的csv路径和本地csv路径保持一致。
1) 数据导入
train data=pd.read csv( ../data/4/train.csv'sep='\t')
test data = pd.read csv('../data/4/test.csv', sep='\t')可以观察数据的信息,得到当前数据的字段含义:
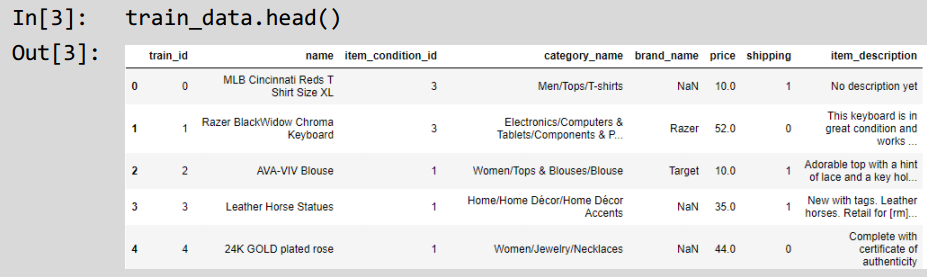
观察可知,数据由8个字段构成,其中train_id表示训练序号,name表示商品名称,item_condition_id表示当前的物品状态,category_name表示商品类别,brand_name表示品牌名称,price表示商品价格,shipping表示是否需要邮费和item_description表示商品描述。
2) 数据预处理
首先观察数据中的缺失值和异常值,然后针对不同字段数据进行预处理操作。
观察数据发现category_name和brand_name两个特征不足200000,即存在缺失值,因此需要对缺失值进行处理。同理,测试集合也存在类似缺失值问题,需要拼接训练集合和测试集合对数据进行数据预处理。拼接代码如下所示:
In[5]: df = pd.concat([train data, pre data], axis=0)两个缺失值字段都为字符串类型的字段,给缺失值填充标识符的代码如下所示。
In[6]
df=df.drop(['price'train id'], axis=1)test iddf['category_name']=df['category_name'].fillna( 'MISs').astype(st
df['brand name']=df['brand name'].fillna( 'MISS').astype(str)df['shipping']=df['shipping'].astype(str)dfr'item condition id'=dfr'item condition id'].astype(str)对category_name和brand_name两个特征填充缺失值标志,同时将整数的字符数据变成相应的字符串数据表示并提取训练过程中需要的预测值。
In[7]: y train = np.log1p(train datal'price'])03、数据探索和模型构建
通过前面的数据预处理过程,数据都变成了字符串数据类型,因此可以采用自然语言处理的相关方法处理。首先构建方法让文本信息向量化,为进一步分析提供依据,代码如下所示。
In[8]:from sklearn.feature extraction.text import CountVectorizer,
TfidfVectorizer
default preprocessor = CountVectorizer().build preprocessor()
def build preprocessor 1(field):
field_idx = list(df.columns).index(field)
return lambda x: default preprocessor(x[field idx7)上面的方法可以对相应特征字段的文字内容向量化,同时需要使用各个字段的向量信息变成产品的表示,因此直观地将所有的特征信息表示拼接成最后的商品表示。我们调用sklearn中的FeatureUnion来拼接商品的特征,代码如下所示。
In[9]:from sklearn.pipeline import FeatureUnion
vectorizer=FeatureUnion([
('name',CountVectorizer(ngram range=(1,2),max features=50000,
preprocessor=build preprocessor 1('name'))),
('category name',CountVectorizer(token pattern='.+
preprocessor=build preprocessor 1('category name')))
('brand name',CountVectorizer(token pattern='.+
preprocessor=build preprocessor 1('brand name'))).
('shipping',CountVectorizer(token pattern=' d+'
preprocessor=build preprocessor 1('shipping')))
('item condition id',CountVectorizer(token pattern=' d+'
preprocessor=build preprocessor 1('item condition id')))('item description',TfidfVectorizer(ngram range=(1,3),
max features=100000,preprocessor=build preprocessor_1('item description'))),
)]上述操作将每个对应字段的文字信息变成向量表示,考虑到产品的描述信息往往会很多,因此我们在处理的过程中为了过滤掉部分无用信息,使用tfidf对文本进行向量化处理,保证了文本表示的质量。
得到商品的向量表示后,通过岭回归线性模型来对商品特征进行分析拟合,下面引入岭回归算法。
In[10]: from sklearn.linear model
import Ridge
ridgeClf = Ridge(solver='auto',fit intercept=True,alpha=0.5.
max_iter=100,normalize=False,tol=0.05)alpha对应岭回归正则化项的大小,alpha越大,对向量表示的正则化越强。我们使用FeatureUnion得到的对象vectorizer,再将商品信息转换为向量表示。同时,按照数据原始划分将数据变成的训练数据和测试数据。
In[11]: X = vectorizer.fit transform(df.values)
nrow train = train data.shape[0]
X train = X[:nrow train]
X test = XInrow train:]使用岭回归算法对数据进行拟合,学习模型中相应的参数。
In[11]: ridgeClf.fit(X train, y train)同时,我们使用训练好的模型分析测试数据,预测商品的价格大小。
In[12]: test price = ridgeClf.predict(x test)预测结果评价,通过MSLE进行评估,使用sklearn.metrics中的mean_squared_log_error来实现。
In[13]:from sklearn.metrics import mean squared log error
true_price=pd.read csv("../data/4/label test.csv"sep="\t").price.tolist()
mean squared log error(true price, test price)
0ut[13]: 3.006566863415081数据输出得到的test_price是模型对测试商品的预测价格,得到的预测价格越精确,对于商家定价的帮助就越大。该模型是相对简单的模型,对于文本信息没有考虑文本本身的性质,只是简单考虑特征的统计信息。并且将每个特征信息进行拼接,取得的效果不会很好。更进一步的方法,可以使用神经网络对文本进行建模。商品定价回归不同于文本分类,并不是截取单个关键字就可以对价格进行分析,并且关键词之间有较强的关联:比如苹果+手机产生的价格远远高于他们各自价格相加。同时对于拥有大量信息的冗长文本,使用神经网络在输入端提取特征是一个很好的选择。同时,商品信息中有普通的数值特征、商品分类特征、商品名称+商标的短文本以及商品详细长文本的信息。相较于将所有特征都转换为文字类特征,普通数字特征可以使用多层全连接网络形成数字特征表示,并且结合注意力机制得到有意义的文本内容表示。同时,对商品名称和商品品牌的文本内容拼接起来,能够防止商品名称和商品品牌内容过短的问题并能够有效抑制特征缺失的问题,形成统一的文本表示特征。

- 点赞
- 收藏
- 关注作者
评论(0)