Python之JavaScript逆向系列——通过IP代理高频获取全篇小说


Python之JavaScript逆向系列——通过IP代理高频获取全篇小说
目录
Python之JavaScript逆向系列——通过IP代理高频获取全篇小说
前言
大家好,本系列文章主要为大家提供的价值方向是网络信息获取,自动化的提取、收集、下载和记录互联网上的信息,加之自身分析,可以让价值最大化。整个内容中不会涉及到过为敏感的内容。
在这个AI+云计算+大数据时代,我们眼睛所看到的百分之九十的数据都是通过页面呈现出现的,不论是PC端、网页端还是移动端,数据渲染还是基于HTML+JavaScript进行的,而大多数的数据都是通过request请求后台API接口动态渲染的。而想成功的请求成功互联网上的开放/公开接口,必须知道它的【URL】、【Headers】、【Params】、【Body】等数据是如何生成的。我们需要了解浏览器开发者工具的功能,入门JS逆向,入门后还需要掌握例如如何【反编译js混淆】等内容,为了避免封本机IP,还需要对每次访问的IP进行代理,当我们拥有了JS逆向的能力后,根据JS所返回的动态请求参数信息便可以进行Python的具体信息获取操作,需要的知识点非常的多,故而本系列文章理论+实践会达到上百篇的文章,这篇文章是总篇,为了方便大家来直接查找所有知识点,建议之间关注收藏本篇,期望能给大家带来更高的价值。
环境准备
系统环境:win11
开发工具:
IP代理:
api工具:
数据库:MySQL5.7.32——阿里云RDS数据库
主要python库:requests、PyExecJS、parsel
正文
我们来下载一篇50万字的小说。
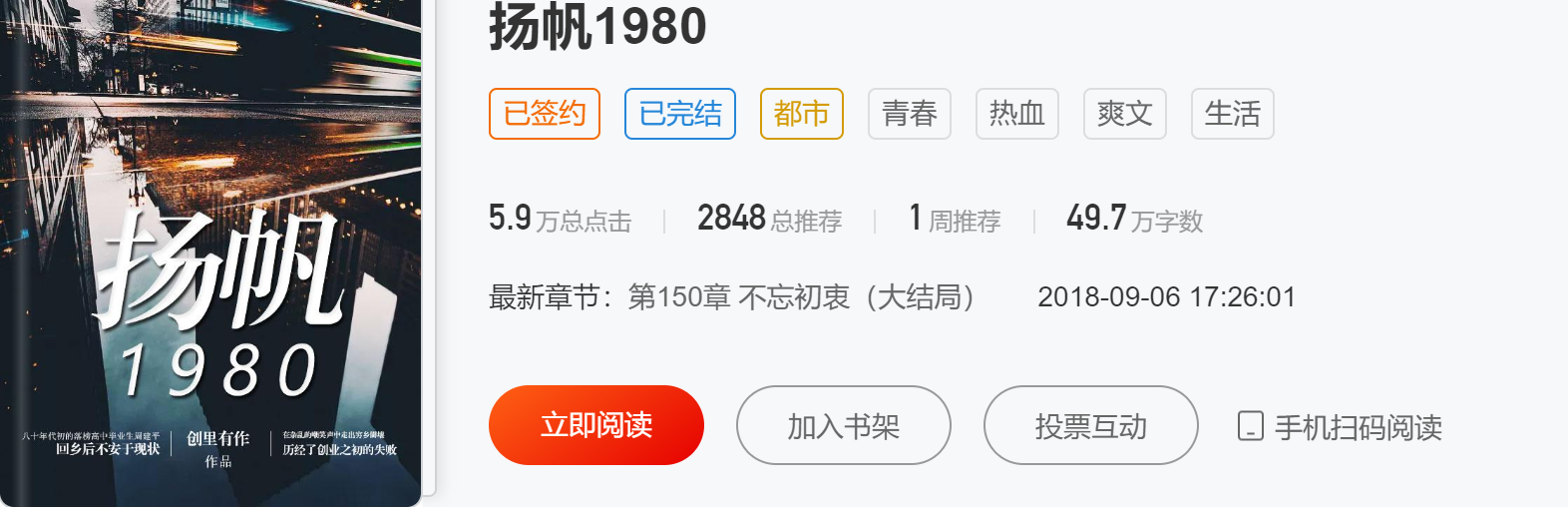
1、网络数据分析
我们打开网络,先找到目录,大战getChapterList可以获取所有的连接地址。
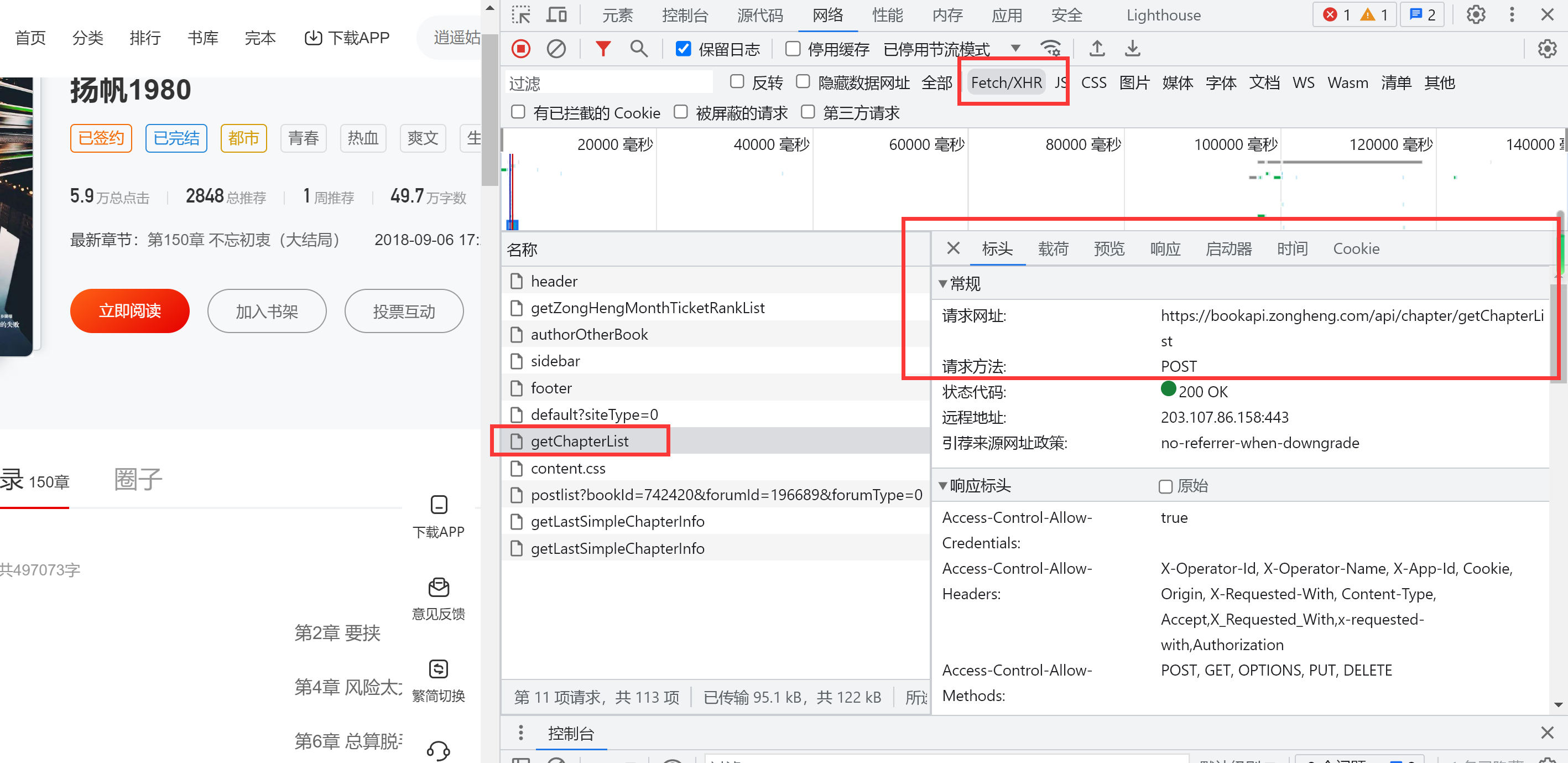
2、获取标题列表与文章id
可以说对应的接口给了所有的东西,很方便
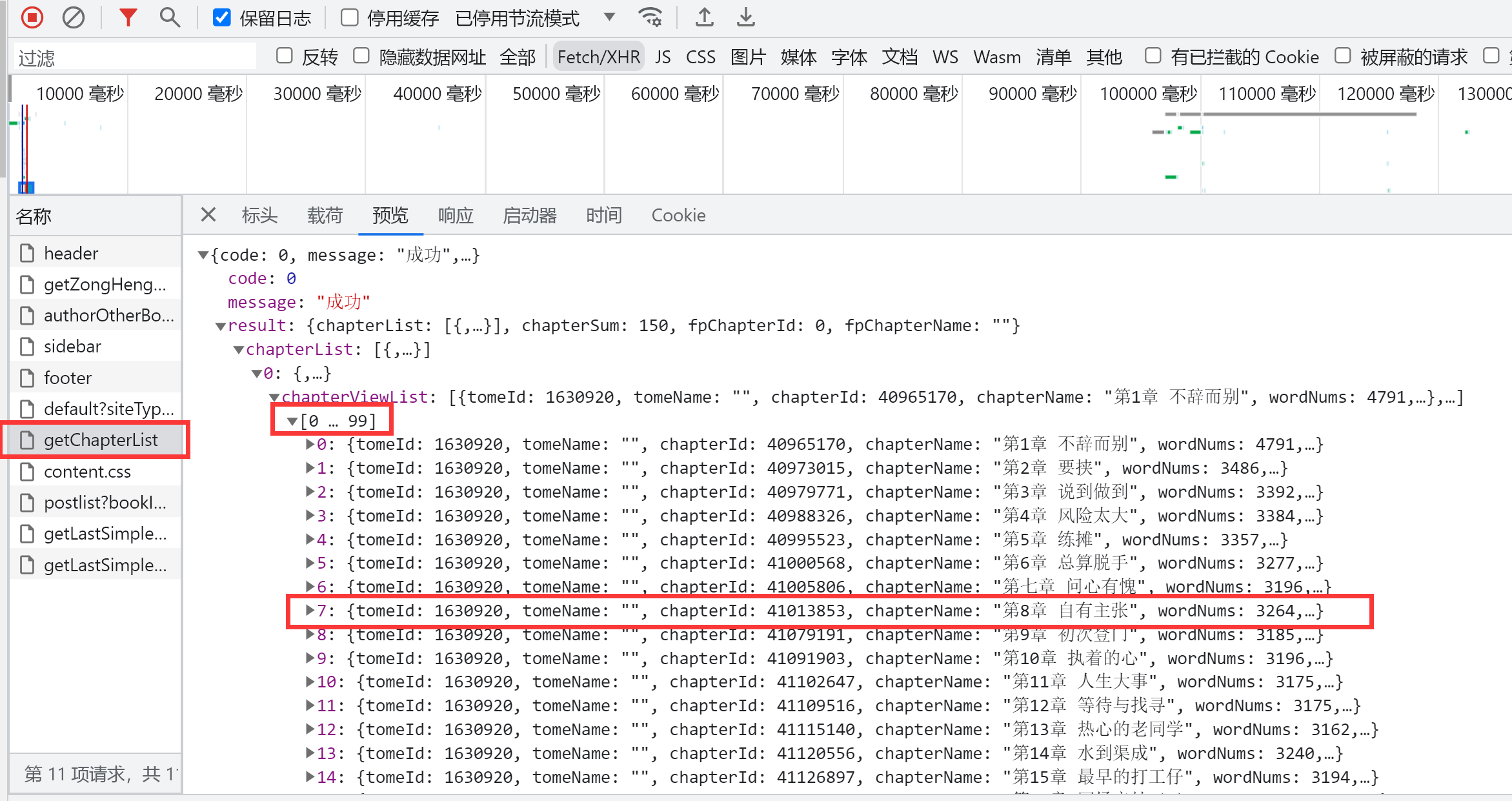
3、确认请求路径与方法
在表头丽可以看到请求网址以及请求方法,这里是post
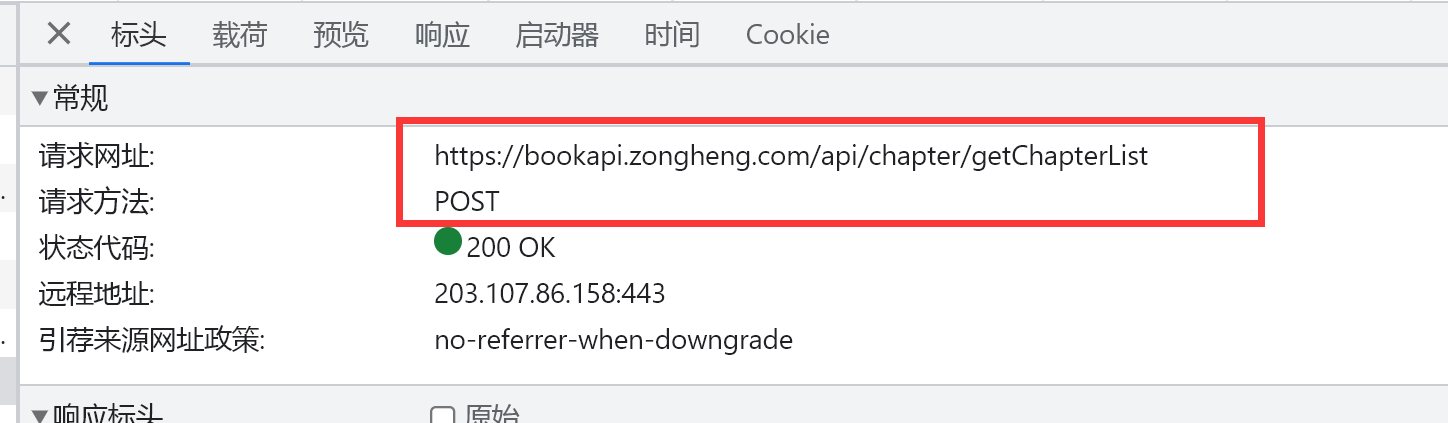
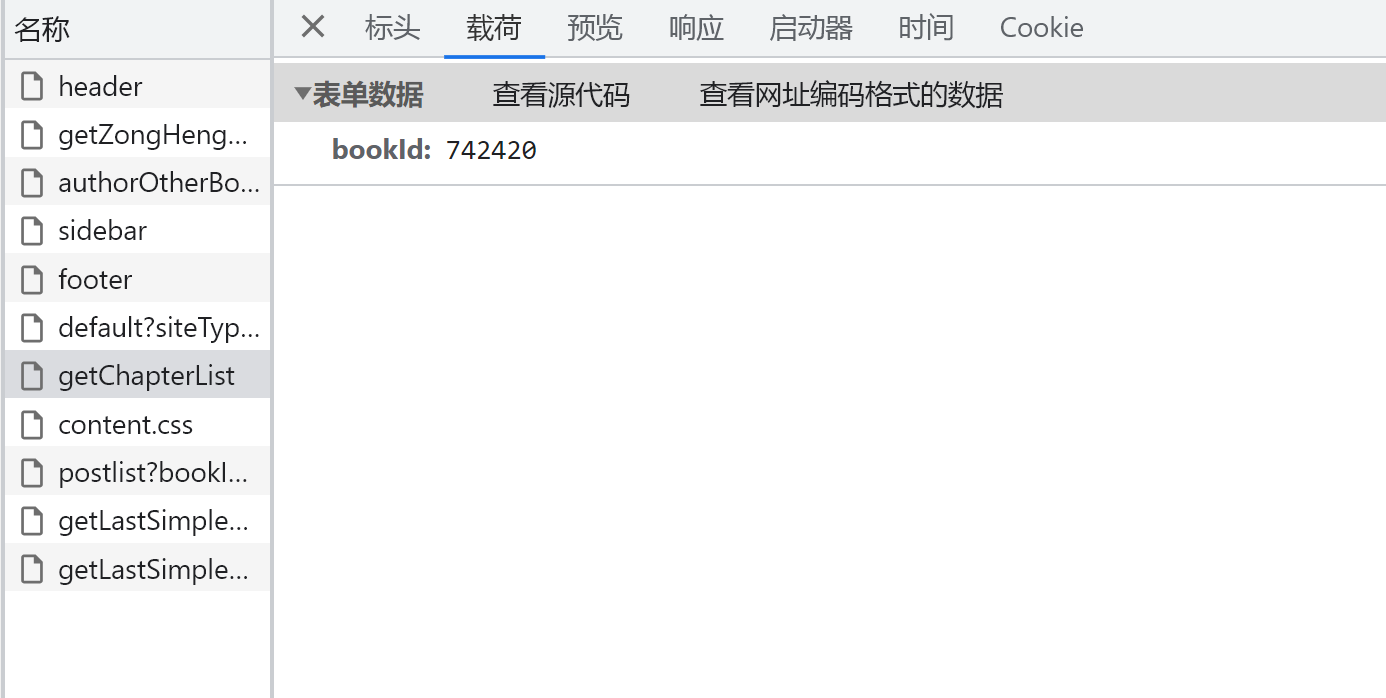
4、参数确定
这里可以在荷载丽看到传递的是文章id
5、根据api获取文章列表
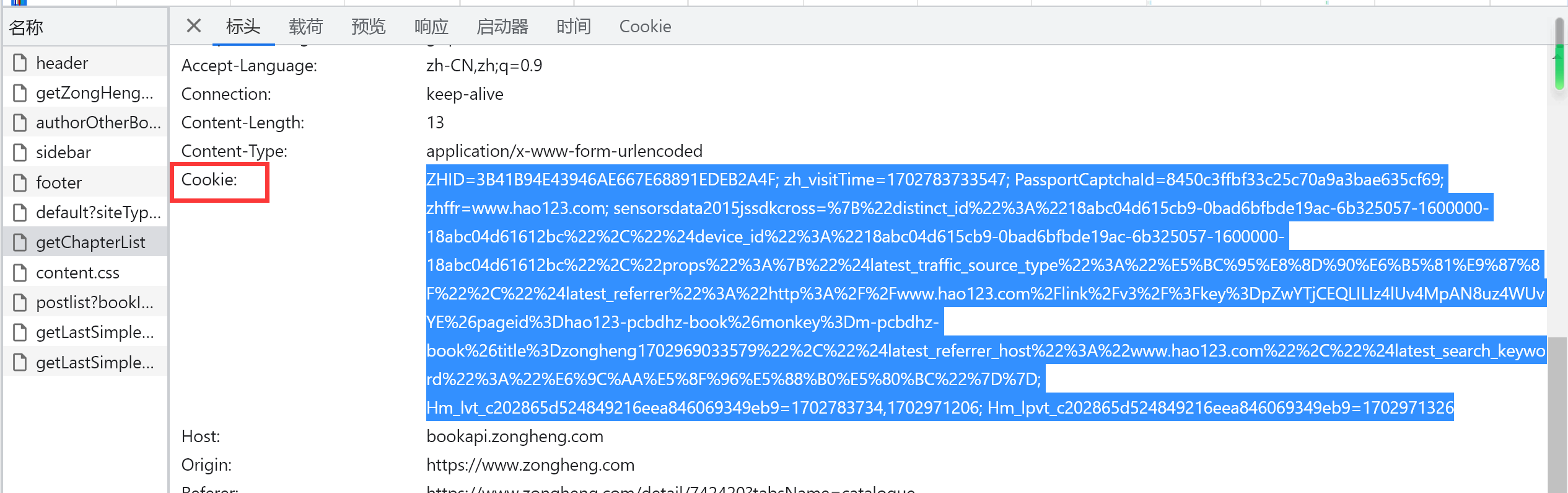
请求的时候需要提供一个cookie,所以我们需要再标头中找到cookie
![]()
请求示例代码:
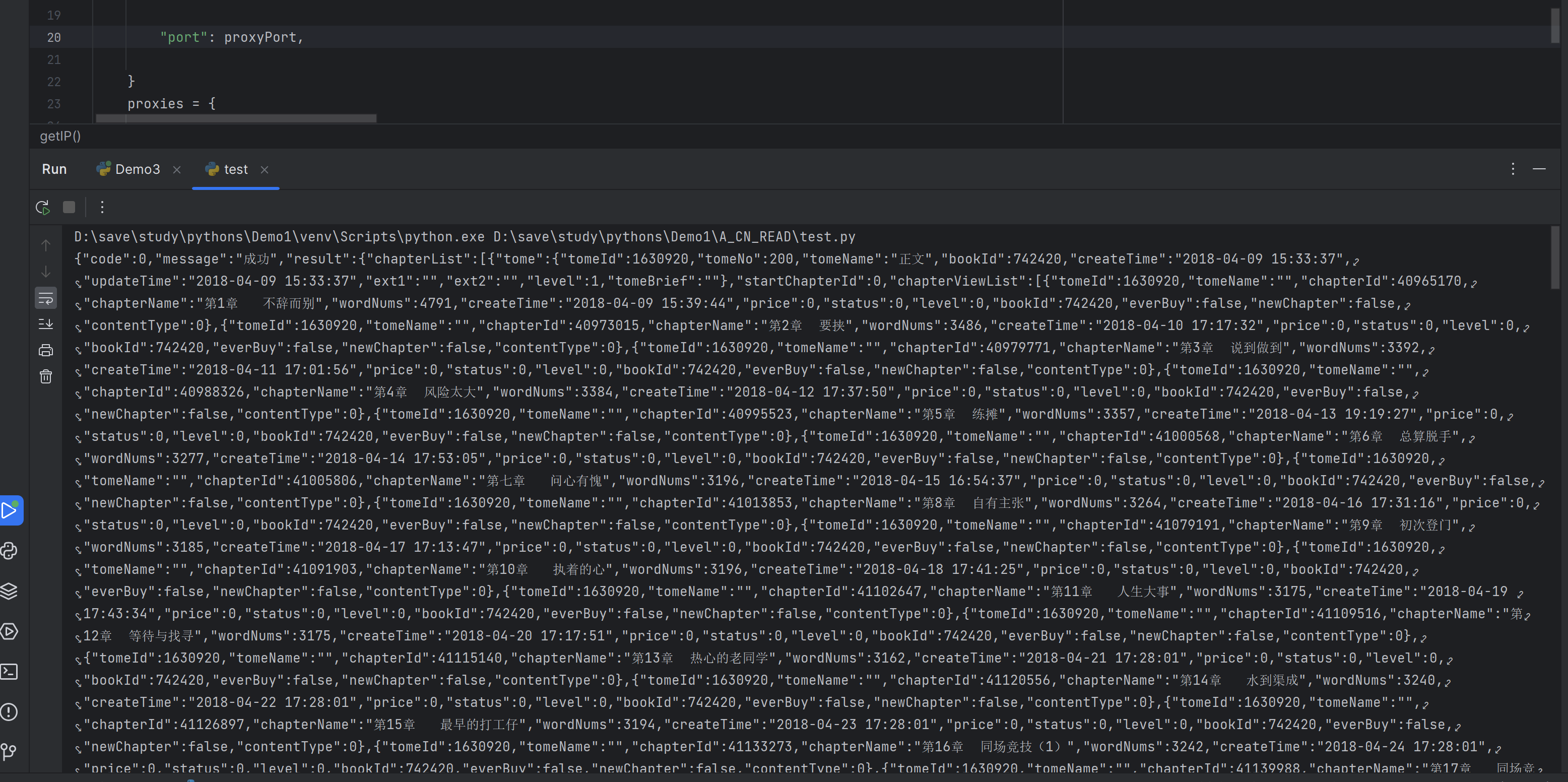
访问成功效果:
6、筛选具体的需求信息
需求文章id以及文章名称
import requests
import json
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36",
"Cookie": "ZHID=3B41B94E43946AE667E68891EDEB2A4F; zh_visitTime=1702783733547; PassportCaptchaId=8450c3ffbf33c25c70a9a3bae635cf69; zhffr=www.hao123.com; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218abc04d615cb9-0bad6bfbde19ac-6b325057-1600000-18abc04d61612bc%22%2C%22%24device_id%22%3A%2218abc04d615cb9-0bad6bfbde19ac-6b325057-1600000-18abc04d61612bc%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E5%BC%95%E8%8D%90%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22http%3A%2F%2Fwww.hao123.com%2Flink%2Fv3%2F%3Fkey%3DpZwYTjCEQLILIz4lUv4MpAN8uz4WUvYE%26pageid%3Dhao123-pcbdhz-book%26monkey%3Dm-pcbdhz-book%26title%3Dzongheng1702969033579%22%2C%22%24latest_referrer_host%22%3A%22www.hao123.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%7D; Hm_lvt_c202865d524849216eea846069349eb9=1702783734,1702971206; Hm_lpvt_c202865d524849216eea846069349eb9=1702971326"
}
def getIP():
url = "http://zltiqu.pyhttp.taolop.com/getip?count=1&neek=*****&type=1&yys=0&port=1&sb=&mr=1&sep=1"
result = requests.get(url, headers=headers)
resIP = result.text.split(":")
proxyHost = resIP[0]
proxyPort = resIP[1].replace("\r\n", "")
proxyMeta = "%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
}
proxies = {
"http": proxyMeta,
"https": proxyMeta
}
return proxies
# 访问路径
url = "https://bookapi.zongheng.com/api/chapter/getChapterList"
# 文章id
bookId = 742420
data = {
"bookId": bookId
}
main_re = requests.post(url, headers=headers, proxies=getIP(), data=data)
main_json = json.loads(main_re.text)
chapterViewList = main_json["result"]["chapterList"][0]["chapterViewList"]
print(chapterViewList)
7、根据文章列表确认每篇文章地址
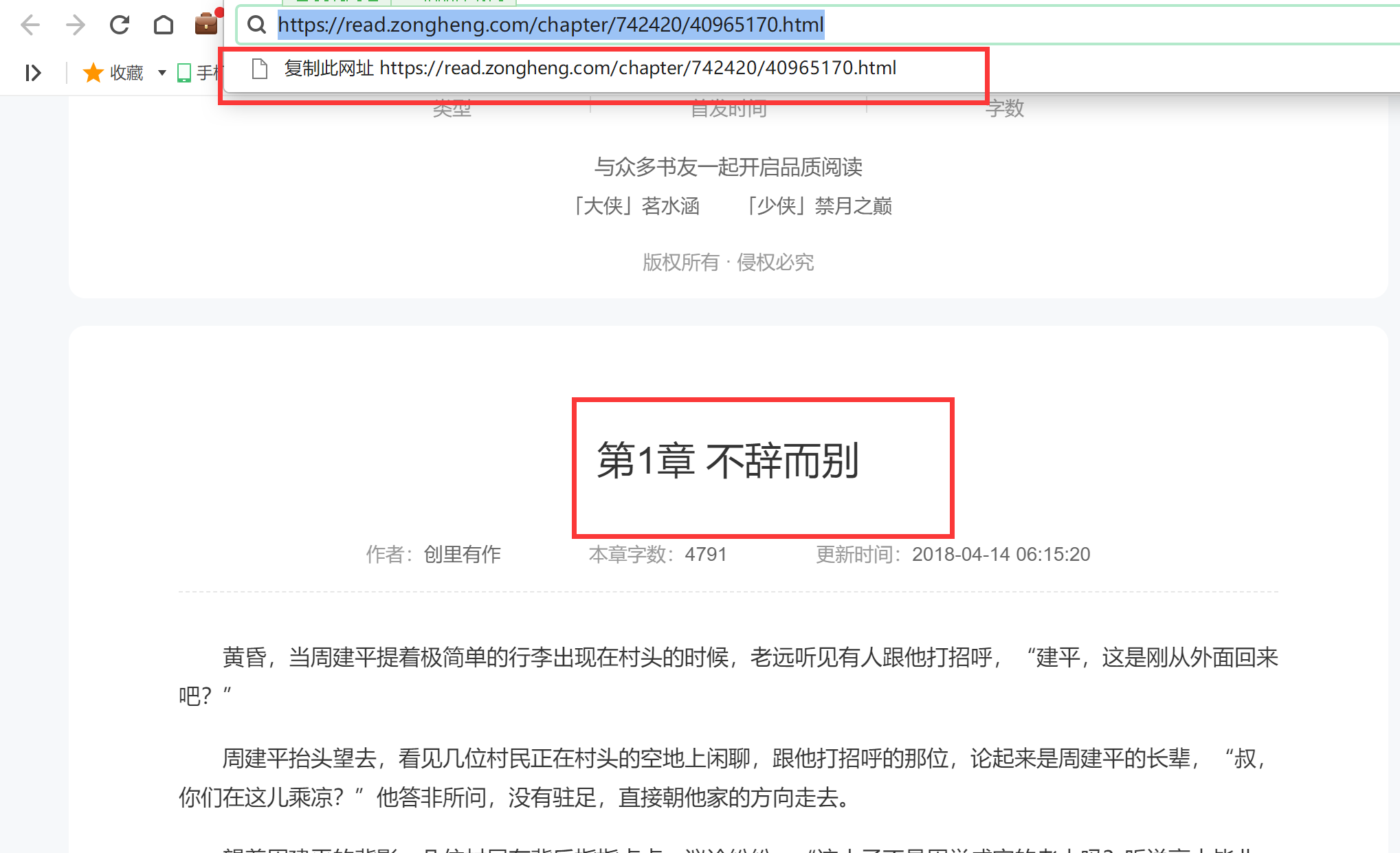
随意打开一篇文章:
![]()
可以看到小说的id以及小说每篇文章的id,这两个信息我们都已经有了。
8、循环遍历文章并下载到本地
下面是执行的代码,如果你需要搞其它的文章,在对应的网址上找到小说ID提换一下即可。
import time
import requests
import json
import parsel
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.5735.289 Safari/537.36",
"Cookie": "ZHID=3B41B94E43946AE667E68891EDEB2A4F; zh_visitTime=1702783733547; PassportCaptchaId=8450c3ffbf33c25c70a9a3bae635cf69; zhffr=www.hao123.com; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2218abc04d615cb9-0bad6bfbde19ac-6b325057-1600000-18abc04d61612bc%22%2C%22%24device_id%22%3A%2218abc04d615cb9-0bad6bfbde19ac-6b325057-1600000-18abc04d61612bc%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E5%BC%95%E8%8D%90%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22http%3A%2F%2Fwww.hao123.com%2Flink%2Fv3%2F%3Fkey%3DpZwYTjCEQLILIz4lUv4MpAN8uz4WUvYE%26pageid%3Dhao123-pcbdhz-book%26monkey%3Dm-pcbdhz-book%26title%3Dzongheng1702969033579%22%2C%22%24latest_referrer_host%22%3A%22www.hao123.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%7D; Hm_lvt_c202865d524849216eea846069349eb9=1702783734,1702971206; Hm_lpvt_c202865d524849216eea846069349eb9=1702971326"
}
def getIP():
while True:
url = "http://zltiqu.pyhttp.taolop.com/getip?count=1&neek=*****&type=1&yys=0&port=1&sb=&mr=1&sep=1"
result = requests.get(url, headers=headers)
resIP = result.text.split(":")
proxyHost = resIP[0]
proxyPort = resIP[1].replace("\r\n", "")
proxyMeta = "%(host)s:%(port)s" % {
"host": proxyHost,
"port": proxyPort,
}
proxies = {
"http": proxyMeta,
"https": proxyMeta
}
if len(proxies["http"].split(".")) == 4:
return proxies
else:
time.sleep(2)
print("2s后重试")
# 访问路径
url = "https://bookapi.zongheng.com/api/chapter/getChapterList"
# 文章id
bookId = 742420
data = {
"bookId": bookId
}
main_re = requests.post(url, headers=headers, proxies=getIP(), data=data)
main_json = json.loads(main_re.text)
chapterViewList = main_json["result"]["chapterList"][0]["chapterViewList"]
bookInfos = []
for index in chapterViewList:
title = "{0} 字数:{1}".format(index["chapterName"], index["wordNums"])
info_url = "https://read.zongheng.com/chapter/{0}/{1}.html".format(bookId, index["chapterId"])
child_re = requests.get(info_url, headers=headers, proxies=getIP())
sel = parsel.Selector(child_re.content.decode("utf-8"))
dataList = sel.css(".content p::text").getall()
strInfo = "{0}\n".format(title)
for i in dataList:
strInfo += "{0}\n".format(i)
bookInfos.append(strInfo)
print(strInfo)
break
with open("扬帆1980.txt", "w", encoding="utf-8") as f:
for index in bookInfos:
f.write(index)
f.flush()
f.close()
150章,正好。

![]()
如果获取动态IP失败会等待2s之后重试,没有开多线程,所以需要等一会。
最终成果:
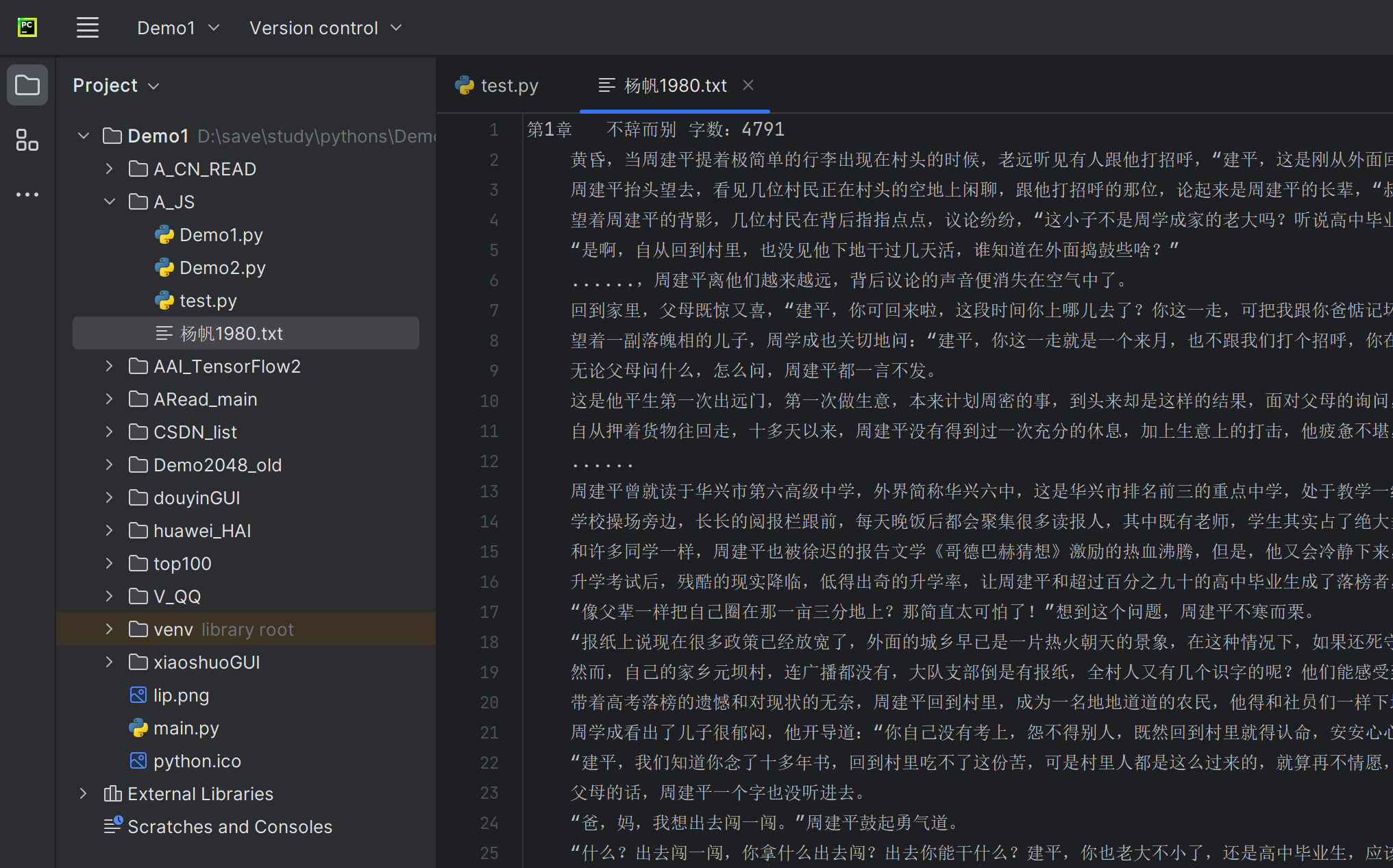
![]()
总结
这里涉及到的是json数据的处理,HTML页面元素的获取,文本信息的IO流操作等操作,相对难度就有一些了,我给了完整的代码示例,这里一定要使用IP代理,否则访问不过几十次就会封掉你本地的IP访问权限,看看我之前的文章,或者直接在环境准备中找到我使用的IP代理工具即可解决这种问题。

- 点赞
- 收藏
- 关注作者
评论(0)