Python之JavaScript逆向系列——4、Body


Python之JavaScript逆向系列——4、Body
目录
前言
大家好,本系列文章主要为大家提供的价值方向是网络信息获取,自动化的提取、收集、下载和记录互联网上的信息,加之自身分析,可以让价值最大化。整个内容中不会涉及到过为敏感的内容。
在这个AI+云计算+大数据时代,我们眼睛所看到的百分之九十的数据都是通过页面呈现出现的,不论是PC端、网页端还是移动端,数据渲染还是基于HTML+JavaScript进行的,而大多数的数据都是通过request请求后台API接口动态渲染的。而想成功的请求成功互联网上的开放/公开接口,必须知道它的【URL】、【Headers】、【Params】、【Body】等数据是如何生成的。我们需要了解浏览器开发者工具的功能,入门JS逆向,入门后还需要掌握例如如何【反编译js混淆】等内容,为了避免封本机IP,还需要对每次访问的IP进行代理,当我们拥有了JS逆向的能力后,根据JS所返回的动态请求参数信息便可以进行Python的具体信息获取操作,需要的知识点非常的多,故而本系列文章理论+实践会达到上百篇的文章,这篇文章是总篇,为了方便大家来直接查找所有知识点,建议之间关注收藏本篇,期望能给大家带来更高的价值。
环境准备
系统环境:win11
开发工具:
IP代理:
api工具:
数据库:MySQL5.7.32——阿里云RDS数据库
主要python库:requests、PyExecJS、parsel
正文
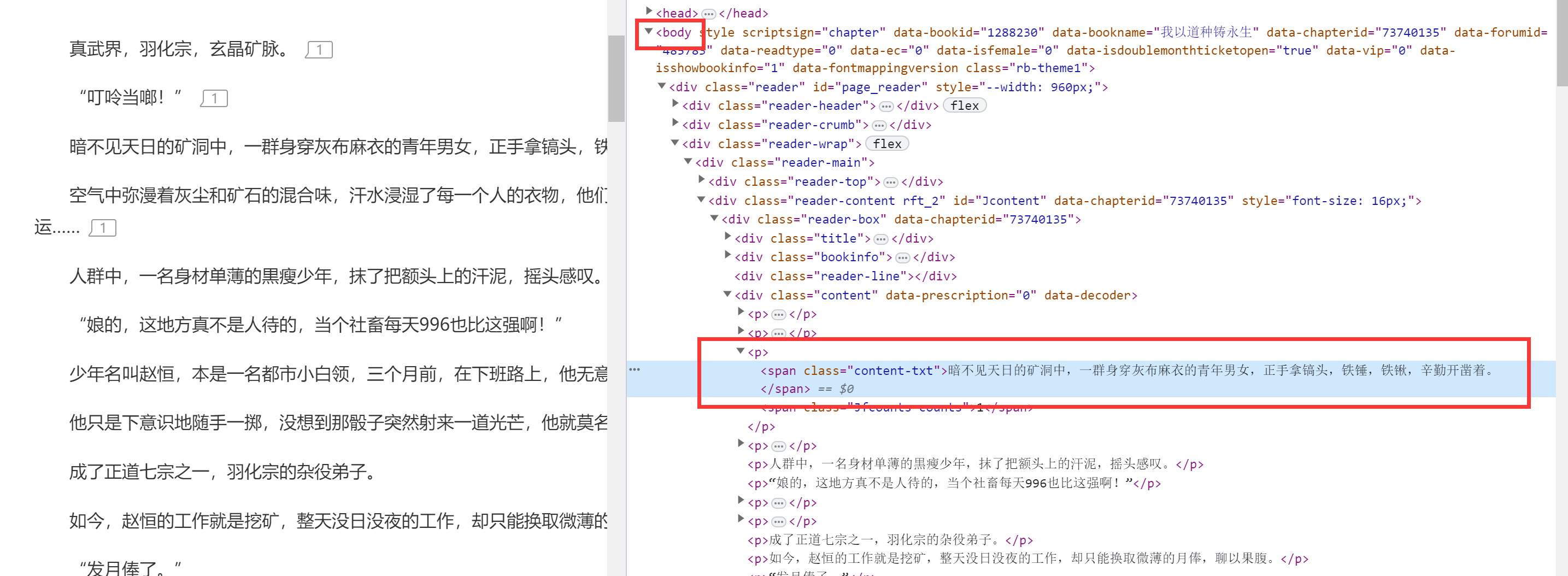
body也就是正文内容,我们实际请求页面成功之后便会返回一个页面的所有信息,其中我们需要的内容基本都在body里面,例如我们需要在一个小说网站内获取小说的内容,可以看到当前的情况:
![]()
我们仅需要从body里面获取信息即可。需要使用到【parsel】库来筛选数据。
parsel语法
Python的`parsel`库是一个用于处理HTTP请求和解析HTTP响应的强大工具。它提供了许多功能,包括发送HTTP请求、解析响应体、解析HTML和XML文档等。下面是一个简单的示例,展示如何使用`parsel`库来发送HTTP请求并解析响应。
首先,你需要安装`parsel`库。可以使用pip命令进行安装:
pip install parsel然后,你可以使用以下代码来发送HTTP请求并解析响应:
这个例子展示了如何使用`parsel`库的基本功能。以下是一些更高级的功能,可以帮助你更好地使用`parsel`库:
* 发送HTTP POST请求:可以使用`urlopen`函数发送POST请求,并传递一个字典作为请求体。例如:
from parsel import Parser, urlopen, Request
p = Parser()
url = "http://example.com/api"
data = {"key1": "value1", "key2": "value2"}
request = Request(url=url, method="POST", data=data)
response = urlopen(request)
doc = p.parse(response.text)* 解析HTML和XML文档:`parsel`库还提供了解析HTML和XML文档的功能。可以使用`Selector`类来选择和提取HTML或XML文档中的元素。例如:
* 使用正则表达式提取数据:`parsel`库还提供了使用正则表达式提取数据的功能。可以使用`re`模块在解析过程中使用正则表达式匹配数据。例如:
import re
from parsel import Parser, urlopen, Selector, re_type_matches_named_group
doc = Selector(text=urlopen("http://example.com/page.html").text)
data = doc.text_content().strip() # 提取文本内容,移除前后的空白字符
match = re.search(r"your-regex-pattern", data) # 使用正则表达式匹配数据
if match and re_type_matches_named_group(match): # 如果匹配成功并且使用了命名捕获组,提取匹配到的值
print(match.group('named-group')) # 输出匹配到的值名称为'named-group'的值这只是`parsel`库的一些基本功能和使用方法。你可以查阅官方文档以获取更多详细信息和示例代码。
获取示例
根据parsel完成的一个示例,这里没有完整的内容,但是能根据语法进行一定的分析,这几篇文章都是理论,让我们后面更好的去实际操作。

- 点赞
- 收藏
- 关注作者
评论(0)