知识融合:概述、方法

操千曲而后晓声,观千剑而后识器。 ——《文心雕龙》
🍀知识融合概述
🍀知识融合定义
知识融合(Knowledge Fusion)的概念最早出现1983年发表的文献中,并在20世纪
90年代得到研究者的广泛关注。
在维基百科中“知识融合”的定义是,“对来自多源的不同概念、上下文和不同表达等
信息进行融合的过程”。除此之外,有一些专家提出知识融合的目标是产生新的知识,是对
松耦合来源中的知识进行集成,构成一个合成的资源,用来补充不完全的知识和获取新知
识。还有一些专家认为,知识融合是知识组织与信息融合的交叉学科,它面向需求和创新,
通过对众多分散、异构资源上的知识进行获取、匹配、集成、挖掘等处理,获取隐含的或
有价值的新知识,同时优化知识的结构和内涵,提供知识服务。
总之,知识融合是一个不断发展变化的概念。尽管以往研究人员的具体表述不同、所
站角度不同、强调的侧重点不同,但这些论述中还是存在很多共性。这些共性反映了知识
融合的固有特征,可以将知识融合与其他类似或相近的概念区分开来。知识融合一般通过
冲突检测、真值发现等技术消解知识集成过程中的冲突,再对知识进行关联与合并,最终
形成一个一致的结果。
知识融合的研究工作开始于本体对齐,初期主要针对本体类别的语义相似性的匹配的
研究。但随着 Web 2.0和语义Web 技术的不断发展,越来越多的语义数据具有丰富实例和
相对薄弱的本体模式,促使本体对齐的研究工作慢慢地从概念层转移到数据层。不同数据
源的实体可能会指向现实世界的同一个对象,这时需要使用实体对齐将不同数据源中相同
对象的数据进行融合。
🍀知识融合的任务
由于数据源不同,构建方式不同等其他因素所在,所以导致知识的质量会有一定的分歧,例如重复、缺失、不明确等问题,以下的几个典型的问题:
- 相同的实体有不同的名称:laptop和notebook等
- 同名指代不同实体:苹果(公司、水果、歌曲等)
- 实体定义的粒度不同:飞机、飞机类型、飞机型号
- 相同的属性在不同的知识库有不同的判别能力
- 相同的类别在不同的知识库中具有不同数量的属性
- 缩写名词、单位、大小写、空格、录入错误等不同
正因为不同的太多了,所以需要将其统一融合为一个知识图谱,要不然就会尴尬了,下图是知识融合任务执行流程
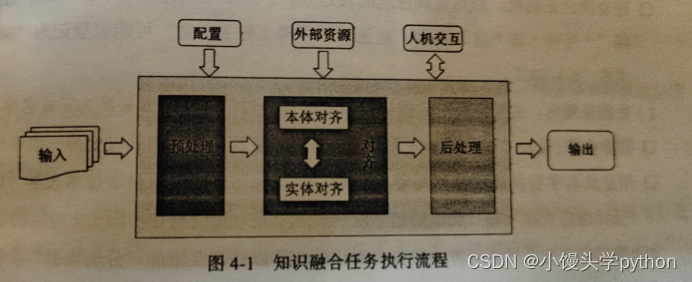
- 输入:无论是结构化还是半结构化的数据,只有能转换为DRF数据都可以作为输入
- 预处理:这部分就是做数据的清理把那些无效冗余数据通通搞掉
- 对齐:这部分包括本体对齐任务和实体对齐任务
本体对齐侧重发现概念层等价或相似的类
本体对齐任务通过本体概念之间的相似性度量发现异构本体间的对齐关系
实体对齐通常是在本体对齐的基础上进行的,因为实体的对应关系需要建立在本体中概念的对应关系之上
后面在知识融合方法上会详细讲到
- 后处理:通过冲突检测、真值发现等技术消解知识图谱融合过程中的冲突,再对知识进行关联与合并,对匹配结果进行抽取及评估,最终形成一个一致的结果
🍀知识融合的方法
接下来简单介绍一下本体对齐方法和实体对齐方法
🍀本体对齐方法
a. 基于规则的方法:
手工制定规则: 通过人工定义一些规则来指导本体对齐,例如同一属性、同义词等。
语言技术: 使用自然语言处理(NLP)技术,如词嵌入,来理解和比较本体中的文本描述。
b. 基于相似性的方法:
相似性度量: 利用相似性度量方法,如编辑距离、余弦相似度等,比较本体中概念和属性之间的相似性。
结构相似性: 比较本体的结构,如子类关系、属性等,来确定相似性。
c. 基于机器学习的方法:
监督学习: 使用已标注的本体对齐样本进行训练,以学习对齐模型。
半监督学习: 利用部分标注数据进行训练,减轻标注成本。
d. 基于语义推理的方法:
本体推理: 利用本体中定义的语义关系进行推理,从而找到潜在的对齐关系。
推理引擎: 使用专门的推理引擎执行推理操作。
🍀实体对齐方法
a. 基于相似性的方法:
字符串匹配: 使用字符串相似性度量(如编辑距离、Jaccard相似度)来比较实体名称的相似性。
语义相似性: 使用语义相似性度量,如词向量,来捕捉实体之间的语义关系。
b. 基于图匹配的方法:
图匹配算法: 将本体表示为图,利用图匹配算法来找到实体之间的对应关系。
子图匹配: 在图中寻找相似的子图结构,以确定实体的对齐关系。
c. 基于学习的方法:
机器学习: 使用机器学习方法,如支持向量机(SVM)、深度学习等,从数据中学习实体对齐的模型。
迁移学习: 利用一个本体中的已知对齐信息来帮助在另一个本体中进行对齐。
d. 基于规则的方法:
手工规则: 制定一些启发式规则,如相同属性、相同类型等,来进行实体对齐。
本体规则: 利用本体中定义的语义规则,如同义词关系、属性关系等。
- 点赞
- 收藏
- 关注作者
评论(0)