J2EE基础知识点储备

一、前言
对于后端开发求职者来说,J2EE是必备技能,此篇博文通过梳理工作过程中常用、面试时高频面点相关内容,特输出此文,希望能够帮助求职者往前迈进一步。
二、Java 基础
2.1 jdk 1.8 新特性(核心是Lambda 表达式)
-
接口的默认方法(给接口添加一个非抽象的方法实现,只需
default关键字即可)。采用接口的默认方法,还是为了解决java不能多继承的原因。 -
Lambda 表达式(使代码变得异常简洁)
Lambda 表达式其实是一种函数值编程,都是直接调用函数,而且编译器可以自动推导出参数的类型。Collections.sort(names, (a, b) -> b.compareTo(a)); //字符串按字母从后往前排 -
使用
::关键字来传递方法或者构造函数引用。Converter<String, Integer> converter = Integer::valueOf; //方法的引用 PersonFactory<Person> personFactory =Person::new; //构造函数的引用 -
可以直接在lambda表达式访问外层的局部变量
final int num = 1; Converter<Integer,String> stringConverter = (from) -> String.valueOf(from + num); stringConverter.convert(2); // 3
2.2 java 存在内存泄露和内存溢出的应用场景
- 静态集合类,使用
Set、Vector、HashMap等集合类的时候要特别注意,当这些类被定义成静态的时候,由于他们的生命周期跟应用程序一样长,这时候就有可能发生内存泄露。
class StaticTest {
private static Vector v = new Vector(10);
public void init() {
for (int i=1; i< 100; i++) {
Object obj = new Object();
v.add(obj);
obj = null;
}
}
}
在上面的代码中,循环申请object对象,并添加到Vector中,然后设置object=null(就是清除栈中引用变量object),但是这些对象被vector引用着,必然不能被GC回收,造成内存泄露。因此要释放这些对象,还需要将它们从vector中删除,最简单的方法就是将vector=null,清空集合类中的引用。
- 监听器:在
java编程中,我们都需要和监听器打交道,通常一个应用中会用到很多监听器,我们会调用一个控件,诸如addxxxListener()等方法来增加监听器,但往往释放的时候却没有去删除这些监听器,从而增加内存泄露的机会。

注意⚠️:对于物理连接,一般把这些代码放在spring容器中,避免内存泄露。

2.3 匿名内部类是什么?如何访问在其外面定义的变量?
匿名内部类是什么?
- 匿名内部类没有访问修饰符;
- 当所在方法的形参需要被匿名内部类使用,那么这个形参类型就必须为
final; - 匿名内部类没有构造方法,因为它连名字都没有何来构造方法;
如何访问在其外面定义的变量?
当所在方法的形参需要被匿名内部类使用,那么这个形参类型就必须为final。
三、J2EE 基础
3.1 servlet 生命周期
Servlet接口定义了5个方法,其中前三个方法与servlet生命周期有关:
void init(ServletConfig config);Void service(ServletRequest req, ServletResponse resp);Void destory();java.lang.String getServletInfo();ServletConfig getServletConfig();
Web容器加载servlet并将其实例化后,servlet生命周期开始,容器运行其init()方法进行servlet的初始化;请求到达时调用servlet的service()方法,service()方法会根据需要调用与请求对应的doGet或doPost等方法;当服务器关闭或项目被卸载时,服务器会将servlet实例销毁,此时会调用servlet的destroy()方法。
Servlet的生命周期分为5个阶段:加载、创建、初始化、处理客户请求、卸载。
- 加载:容器通过类加载器使用
servlet类对应的文件加载servlet;- 创建:通过调用
servlet构造函数创建一个servlet对象;- 初始化:调用
init方法初始化;- 处理客户请求:每当有一个客户请求,容器会创建一个线程来处理客户请求;
- 卸载:调用
destroy()方法让servlet自己释放其占用的资源;
3.2 保存会话状态方式,有哪些区别?
由于http协议本身是无状态的,服务器为了区分不同的用户,就需要对用户会话进行跟踪,简单的说就是为用户进行登记,为用户分配唯一的id,下一次用户在请求中包含此id,服务器据此判断到底是哪一个用户。
- URL重写:在
url中添加用户会话信息作为请求参数,或者将唯一的会话id添加到url结尾以标识一个会话。 - 设置表单隐藏域:将和会话跟踪相关的字段添加到隐藏表单域中,这些信息不会在浏览器中显示但是提交表单时会提交给服务器。
这两种方式很难处理跨越多个页面的信息传递,因为如果每次都要修改url或则在页面中添加隐式表单域来存储用户会话相关信息,事情将变得非常麻烦。
html5中可以使用web storage技术通过javaScript来保存数据,例如可以使用localStorage和sessionStroage来保存用户会话的信息,也能够实现会话跟踪。
3.3 cookie 和 session 的区别
session在服务器端,cookie在客户端(浏览器);Session的运行依赖session id, 而session id是存在cookie中的,也就是说,如果浏览器禁止了cookie,同时session也会失效(但是可以通过其它方式实现,比如在url中传递session id);Session可以放在文件、数据库或内存中都可以;- 用户验证一般会用
session; Cookie不是很安全,别人可以分析存在本地的cookie并进行cookie欺骗,考虑到安全应当使用session;Session会在一定时间内保存在服务器上,当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie;- 单个
cookie保存的数据不能超过4k,很多浏览器都限制一个站点最多保存20个cookie。
3.4 web.xml中标签加载顺序
加载顺序:context-param -> listener -> filter -> servlet
(1)tomcat加载应用程序都是从读取web.xml文件开始的。读web.xml的核心就是从读节点开始listener>filter>servlet。其实还有一个<context-param>这个标签是提供应用程序上下文信息(可以写在任意位置)。因此加载的顺序是:context-param---->listener---->filter----->servlet
3.4.1 各个标签的简单说明
context-param加载上下文的配置文件(主要是java bean)

-
listener监听器
通过监听器的通配符,将配置信息加载到spring容器中。还有一般事务写在spring(业务逻辑层),事务的启动也是靠listener。 -
filter过滤器
Struts就是依靠过滤器来实现action的访问。 -
servlet是我们的后台程序java类。


3.5 页面传值方法
- 表单传值,通过
request根据参数取值;- 直接在地址栏输入页面的地址,在后面加
?,然后把要传的参数及值写在后面,若有多个用&隔开;- 在
form中还可以用hidden(隐藏);
四、SSH三大框架
4.1 Struts
4.1.1 struts2 工作流程:
- 用户发出
http请求;tomcat读取web.xml配置文件;- 通过过滤器读取
Struts.xml配置文件至内存;- 根据
web.xml配置,该请求被核心控制器FilterDispatcher接收(拦截这些请求交由Struts.xml处理);struts.xml配置接收到这些请求,找到需要调用的action类和方法,并通过依赖注入方式,将值注入action(到对应的servlet中进行处理);action调用业务逻辑组件处理业务逻辑,比如基本的数据增删改查、其他的业务处理;action执行完毕,根据struts.xml中的配置找到对应的返回结果result,并跳转到相应页面;
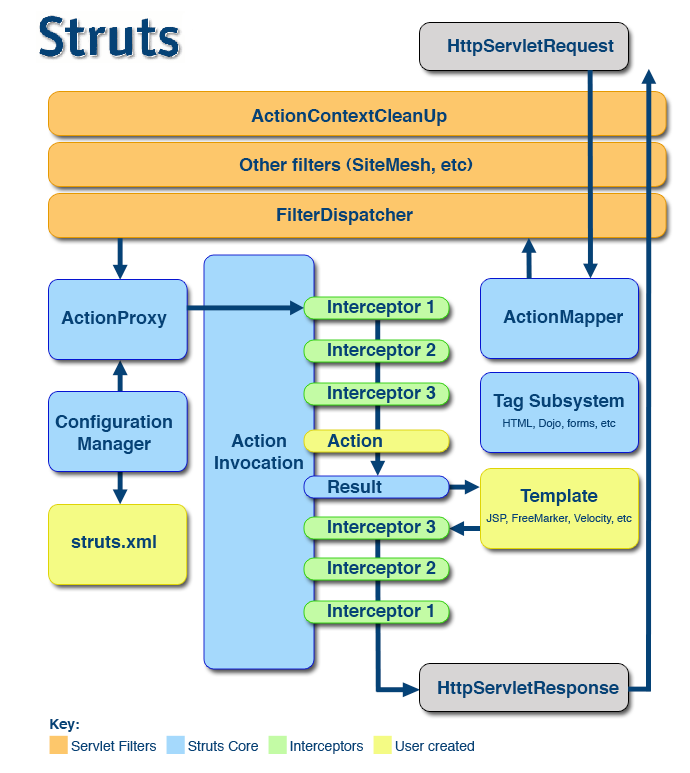
4.1.2 struts2 与 struts1 的区别
从action类上分析:
1.
Struts1要求Action类继承一个抽象基类。Struts1的一个普遍问题是使用抽象类编程而不是接口。
Struts 2Action类可以实现一个Action接口,也可实现其他接口,使可选和定制的服务成为可能。Struts2提供一个ActionSupport基类去实现常用的接口。Action接口不是必须的,任何有execute标识的POJO对象(就是简单的javabean)都可以用作Struts2的Action对象。
从Servlet依赖分析:
Struts1 Action依赖于Servlet API,因为当一个Action被调用时,HttpServletRequest和HttpServletResponse被传递给execute方法。Struts 2 Action不依赖于容器,允许Action脱离容器单独被测试。如果需要,Struts2 Action仍然可以访问初始的request和response。但是,其他的元素减少或者消除了直接访问HttpServetRequest和HttpServletResponse的必要性。
从action线程模式分析:
Struts1 Action是单例模式并且必须是线程安全的,因为仅有Action的一个实例来处理所有的请求。单例策略限制了Struts1 Action能做的事,并且要在开发时特别小心。Action资源必须是线程安全的或同步的。Struts2 Action对象为每一个请求产生一个实例,因此不存在线程安全问题。(实际上,servlet容器给每个请求产生许多可丢弃的对象,并且不会导致性能和垃圾回收问题)
4.2 Spring
IOC容器的加载过程?
- 创建
IOC配置文件的抽象资源; - 创建一个
BeanFactory; - 把读取配置信息的
BeanDefinitionReader,这里是XmlBeanDefinitionReader配置给BeanFactory; - 从定义好的资源位置读入配置信息,具体的解析过程由
XmlBeanDefinitionReade来完成,这样完成整个载入bean定义的过程;
说明
XmlBeanFactory,ClasspathXmlApplicationContext是IOC容器实现的两种方式,XmlBeanFactory是基本的IOC容器的实现,ApplicationContext实现的IOC容器可以提供很多个高级特性(IOC容器的加载主要以ApplicationContext实现。)SpringIOC容器管理了我们定义的各种Bean对象及其相互关系,Bean对象在Spring实现中是以BeanDefinition来描述;
4.2.1 IOC 容器的实现过程
IOC容器的初始化过程(定义各种bean对象以及bean对象间的关系),整个过程分成resource的定位、载入和解析。IOC容器的依赖注入,Bean的名字通过ApplicationContext容器,getbean获得对应的bean。
4.2.2 Spring IOC的理解
传统创建对象的缺陷:
传统创建对象,通过关键字new获得。但是如果在不同的地方创建很多相同的对象,不仅占用很大的内存,同时影响性能。
改进思路:
仿造工厂模式,需要什么对象,直接拿过来,按照用户需求,组装相应的产品。以后不再通过new获取对象,而是需要什么对象,就在spring容器中取就行了。这就是将创建对象这个行为,进行控制反转,交由容器去完成。什么时候需要这些对象,再通过依赖注入的方式去获取这些对象。
依赖注入的几种方式
-
注解方式注入
<!-- applicationContext.xml --> <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-3.0.xsd"> <!-- 打开Spring的Annotation支持 --> <context:annotation-config/> <!-- 设定Spring 去哪些包中找Annotation --> <context:component-scan base-package="org.zttc.itat.spring"/> </beans>// 等价于<bean id="userDAO" class="cn.edu.ujn.dao.impl.UserDAO"> // 公共创建bean的annototion @Component("userDAO") // 一般用于DAO的注入,Spring3新增注解方式 @Repository("userDAO") @Scope("prototype") public class UserDAO implements IUserDAO { ...... } @Component("userService") //@Service一般用于业务层 @Service("userService") public class UserService implements IUserService { private IUserDAO userDAO; public IUserDAO getUserDAO() { return userDAO; } // 默认通过名称进行注入,在JSR330中提供了@Inject来进行注入,需导入相应的包 @Resource public void setUserDAO(IUserDAO userDAO) { this.userDAO = userDAO; } ... } @Component("userAction") //MVC的控制层一般使用@Controller @Controller("userAction") @Scope("prototype") public class UserAction extends ActionSupport { ...... }
注:项目较大时,按照模块进行划分,模块中再按层划分,而非按层(MVC)进行划分;中小型项目按层划分。
2. Setter方法注入
applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<!--
创建如下bean等于完成了:HelloWorld helloWorld = new HelloWorld()
-->
<bean id="helloWorld" class="org.zttc.itat.spring.model.HelloWorld" scope="prototype"/>
<!-- 创建了一个User对象user,id为1,username为悟空,如果要注入值不使用ref而是使用value -->
<bean id="user" class="org.zttc.itat.spring.model.User">
<property name="id" value="2"/>
<property name="username" value="八戒"/>
</bean>
<bean id="userDao" class="org.zttc.itat.spring.dao.UserDao"></bean>
<bean id="userJDBCDao" class="org.zttc.itat.spring.dao.UserJDBCDao"></bean>
<!-- autowire=byName表示会根据name来完成注入,
byType表示根据类型注入 ,使用byType注入如果一个类中有两个同类型的对象就会抛出异常
所以在开发中一般都是使用byName
虽然自动注入可以减少配置,但是通过bean文件无法很好了解整个类的结果,所以不建议使用autowire-->
<bean id="userService" class="org.zttc.itat.spring.service.UserService">
<!-- name中的值会在userService对象中调用setXX方法来注入,诸如:name="userDao"
在具体注入时会调用setUserDao(IUserDao userDao)来完成注入
ref="userDao"表示是配置文件中的bean中所创建的DAO的id -->
<property name="userDao" ref="userDao"></property>
</bean>
<!-- 对于UserAction而言,里面的属性的值的状态会根据不同的线程得到不同的值,所以应该使用多例 -->
<bean id="userAction" class="org.zttc.itat.spring.action.UserAction" scope="prototype">
<property name="userService" ref="userService"/>
<property name="user" ref="user"/>
<property name="id" value="12"/>
<!-- 同样可以注入列表,但是也不常用 -->
<property name="names">
<list>
<value>aaa</value>
<value>bbb</value>
<value>ccc</value>
</list>
</property>
</bean>
<!-- 以下是使用构造函数来注入,不常用,基本都是使用set方法注入 -->
<!-- <bean id="userAction" class="org.zttc.itat.spring.action.UserAction" scope="prototype">
<constructor-arg ref="userService"/>
</bean> -->
</beans>
public class UserAction{
private UserService userService;
public String login(){
userService.valifyUser(xxx);
}
public void setUserService(UserService userService){
this.userService = userService;
}
}
3. 构造方法注入
public class UserAction{
private final UserService userService;
public String login(){
userService.valifyUser(xxx);
}
public UserAction(UserService userService){
this.userService = userService;
}
}
三种注入方式对比
- 注解方式注入:适用于中小型项目,不适合大型项目。因为大型项目中存在很多的包、类,书写较复杂,且不易明白项目的整体结构。
- Setter 注入:对于习惯了传统
javabean开发的程序员,通过setter方法设定依赖关系更加直观。如果依赖关系较为复杂,那么构造子注入模式的构造函数也会相当庞大,而此时注入模式则更为简洁。- 构造器注入:在构造期间完成一个完整的、合法的对象。 所有依赖关系在构造函数中集中呈现。依赖关系在构造时由容器一次性设定,组件被创建之后一直处于相对“不变”的稳定状态。只有组件的创建者关心其内部依赖关系,对调用者而言,该依赖关系处于“黑盒”之中。如果用到了第三方类库,可能要求我们的组件提供一个默认的构造函数,此时构造器注入模式也不适用。
4.2.3 AOP 切面编程
很多项目上相应的业务处理上上需要事务和日志的管理,然而许多业务上的事务、日志代码又都是一样的,这样就造成了代码重复。
改进思路:
让这些重复的代码抽取出来,让专门的一个类进行管理。
AOP的实现:
在需要的地方加上通知(可以在目标代码前后执行),将相同的业务交由代理类去执行(比如日志、事务),然后再执行目标类,实现了代码复用。
静态代理的缺陷:
相同的业务交由代理类去处理,那么需要日志管理,就要创建一个日志代理类,需要事务管理,就要创建事务代理类……,这样会造成代理类的无限膨胀。
改进措施:
根据这些类,动态创建代理类。所以在这个过程,要实现两个步骤:
1.通过反射机制产生代理类;
2. 代理类要实现一个统一的接口,该接口可对目标类实现额外功能的附加,如在目标类前面加日志、事务等。
基于注解的AOP实现逻辑如下:
package org.zttc.itat.spring.proxy;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
@Component("logAspect")//让这个切面类被Spring所管理
@Aspect//申明这个类是一个切面类
public class LogAspect {
/**
* execution(* org.zttc.itat.spring.dao.*.add*(..))
* 第一个*表示任意返回值
* 第二个*表示 org.zttc.itat.spring.dao包中的所有类
* 第三个*表示以add开头的所有方法
* (..)表示任意参数
*/
@Before("execution(* org.zttc.itat.spring.dao.*.add*(..))||" +
"execution(* org.zttc.itat.spring.dao.*.delete*(..))||" +
"execution(* org.zttc.itat.spring.dao.*.update*(..))")
public void logStart(JoinPoint jp) {
//得到执行的对象
System.out.println(jp.getTarget());
//得到执行的方法
System.out.println(jp.getSignature().getName());
Logger.info("加入日志");
}
/**
* 函数调用完成之后执行
* @param jp
*/
@After("execution(* org.zttc.itat.spring.dao.*.add*(..))||" +
"execution(* org.zttc.itat.spring.dao.*.delete*(..))||" +
"execution(* org.zttc.itat.spring.dao.*.update*(..))")
public void logEnd(JoinPoint jp) {
Logger.info("方法调用结束加入日志");
}
/**
* 函数调用中执行
* @param pjp
* @throws Throwable
*/
@Around("execution(* org.zttc.itat.spring.dao.*.add*(..))||" +
"execution(* org.zttc.itat.spring.dao.*.delete*(..))||" +
"execution(* org.zttc.itat.spring.dao.*.update*(..))")
public void logAround(ProceedingJoinPoint pjp) throws Throwable {
Logger.info("开始在Around中加入日志");
pjp.proceed();//执行程序
Logger.info("结束Around");
}
}
4.2.4 动态代理的实现
动态代理主要实现了两个功能:
- 实现
InvocationHandler接口中的invoke方法(主要是被代理类实例、方法、方法参数),该方法就是对被代理对象加的额外操作,如添加日志、权限等。- 在运行时产生一个代理实例(通过反射)。
代码实现如下:
Proxy.newProxyInstance(ClassLoad loader, Class[] interfaces,InvocationHandler h)
// 要代理的真实对象
RealSubject rs = new RealSubject();
// 要代理哪个真实对象,就将该对象传进去,最后是通过该真实对象来调用其方法
InvocationHandler invocationHandler = new DynamicSubject(rs);
Class cl = rs.getClass();
Subject subject = (Subject) Proxy.newProxyInstance(cl.getClassLoader(), cl.getInterfaces(), invocationHandler);
// 代理对象执行方法
subject.request();
过程如下:
- 通过被代理类实例反射获得类类型;
- 然后将这个类类型进行加载(
ClassLoad loader),实现代理类的接口方法(Class[] interfaces),实现代理的invoke方法;
总结:其实动态代理就是通过反射产生代理实例(Proxy.newProxyInstance),然后通过invoke实现额外功能的附加和代理方法的聚合。通过被代理类动态生成代理类解决了上面为各个被代理类创建相应的代理类,造成类膨胀的问题。
动态代理实现步骤:
- 创建一个实现接口
InvocationHandler的类,它必须实现invoke方法; - 创建被代理的类以及接口(通过被代理类的实例进行反射获得);
- 调用
Proxy的静态方法,创建一个代理类new ProxyInstance(ClassLoad loader, Class[] interfaces,InvocationHandler h)。 - 通过代理类返回的实例,去调用被代理类的方法;
4.2.5 jdk代理 和 CGlib动态代理 的区别
1. jdk动态代理
- 只能代理实现了接口
InvocationHandler的类;- 没有实现
InvocationHandler接口的类不能实现jdk的动态代理;
2. CGlib动态代理(通过继承实现)
- 针对类实现代理;
- 对指定目标类产生一个子类,通过方法拦截技术拦截所有父类方法的调用。(其实就是覆写父类的方法,可见
final修饰的类都不可能实现GCLIB代理)
4.3 Hibernate
4.3.1 Hibernate执行过程
- 应用程序先调用
Configuration类,该类读取Hibernate配置文件(链接数据库)及映射文件(java对象个数据库表中对象的一一映射)中的信息;- 并用这些信息生成一个
SessionFactory对象;- 然后从
SessionFactory对象生成一个Session对象;- 并用
Session对象生成Transaction对象;
4.3.2 Hibernate一级缓存与二级缓存之间的区别(比较mybatis的一二级缓存)
hibernate的session提供了一级缓存的功能,默认总是有效的,当应用程序保持持久化实体,修改持久化实体时,session并不会立即把这种改变提交到数据库,而是缓存在当前的session中,除非显示调用了session的flush()方法或通过close()方法关闭session。通过一级缓存,可以减少程序与数据库的交互,从而提高数据库访问的性能。
sessionFactory级别的二级缓存是全局性的,所有的session可以共享这个二级缓存。不过二级缓存默认是关闭的,需要显示开启并指定需要使用哪种二级缓存实现类(可以使用第三方提供的实现)。一旦开启了二级缓存并设置了需要使用二级缓存的实体类,sessionFactory就会缓存访问过的该实体类的每个对象,除非缓存的数据超出了指定的缓存空间。
4.3.3 Hibernate 常见优化策略
- 采用合理的缓存策略(二级缓存、查询缓存);
- 采用合理的
session管理机制;- 尽量使用延迟加载特性(
mybatis的延迟加载);- 设定合理的批处理参数;
- 如果可以,选用
UUID作为主键生成器;- 如果可以,选用基于版本号的乐观锁代替悲观锁;
- 在开发过程中,开启
Hibernate_show_sql选项查看生成的sql,从而了解低层的状况;开发完成后关闭此选项;- 考虑数据库本身的优化,合理的索引,恰当的数据分区策略等都会对持久层的性能带来可观的提升,但是这些需要专业的
DBA(数据库管理员)提供支持。
4.3.4 hibernate中 get 和 load 的区别(涉及到一个懒加载问题也就是延迟加载)
get和load方法是根据id去获得对应数据。区别如下:
- 执行
get()方法时就发送sql语句(不支持延迟加载),并且查询的数据存在内存中,在数据库中查不到记录时不会抛出异常,返回一个null。hibernate在查询数据的时候(数据在内存或缓存中,就不需要在从数据库中查询了),数据并不存在内存中而是通过cglib动态产生的一个代理对象,只有对数据进行操作的时候,才加载到内存中,实现了延迟加载,节省了内存开销,提高服务器性能。用到数据时再发sql语句,在数据库中查不到记录会抛异常。
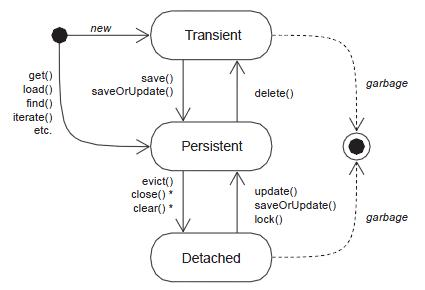
4.3.5 实体对象生命周期
1. translent(瞬时态)
实体对象在内存中的存在,与数据库中的记录无关,通过session的save()或saveOrUpdate()方法变成持久态;
2. Persisent(持久态)
该状态下的实体对象与数据库中的数据保持一致;
3. Detached(托管状态)
操作托管态的数据不能影响到数据库的修改;
五、SSM(Springmvc + spring + mybatis)
5.1 SpringMVC 实现原理
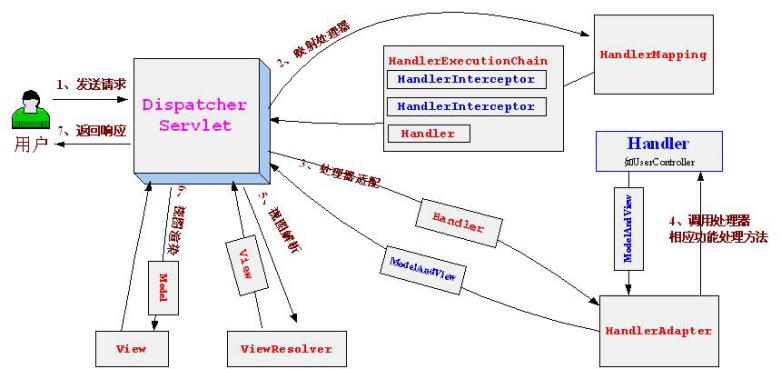
Springmvc工作流程:(面试的时候一定要会画Springmvc的运行图,结合图讲比较好)
- 用户发起请求到前端控制器DispatcherServlet;
- 前端控制器请求处理器映射器HandlerMapping查找
Handler(通过xml或注解方式查找);- 处理器映射器HandlerMapping向前端控制器返回Handler;
- 前端控制器调用处理器适配器HadlerAdapter去执行Handler;
- 处理器适配器去执行Handler ;
- Handler执行完成给适配器返回ModelAndView;
- 处理器适配器向前端控制器返回ModelAndView;
- 前端控制器请求视图解析器去进行视图解析(将逻辑视图转化成完整的视图地址);
- 然后进行视图渲染填充到request域展现给用户;
5.2 mybatis 实现原理
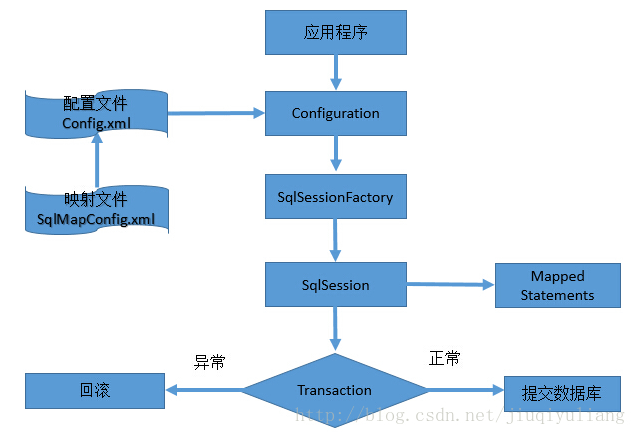
- 应用程序到
mybatis的全局配置文件sqlMapConfig.xml读取配置信息(如:别名设定、包、全局变量定义、mapper扫描(把mapper.xml和mapper.java放在同一个目录下,就不需要配置了))- 然后创建会话工厂(链接数据库);
- 通过会话工厂打开会话,dao层和数据库就实现了通道;
- 通过类的反射加载类的实例,然后就可实现对数据的操作;
六、两大框架对比
6.1 SSH 与 Spring+SpringMVC+mybatis 的区别
Spring+SpringMVC+Mybatis是以spring为主体,实现了springmvc与spring的无缝连接,在层次处理上比SSH更具优势。- 两者都是基于
ORM框架;Hibernate的ORM实现POJO和数据库表之间的映射,以及sql自动生成和执行;Mybatis着力点在于POJO与sql之间的映射关系(主要是输入输出映射)。然后通过映射配置文件。将sql所需的参数,以及返回的结果字段映射到指定POJO。
Mybatis优势:
- 可以进行更为细致的
sql优化,可以减少查询字段;Mybatis较Hibernate容易掌握;
Hibernate优势:
Hibernate的DAO层开发比mybatis简单,因为mybatis需要维护sql和结果映射;hibernate对对象的维护和缓存比mybatis好,对增删改查的对象维护也方便。hibernate数据库移植性要比mybatis好,因为mybatis对不同的数据库要写不同的sql语句;hibernate有更好的二级缓存机制,还可以使用第三方缓存。Mybatis本身提供的缓存机制不佳。
6.2 struts2 与springmvc 的实现原理,以及两者的区别?
- 核心控制器:
springmvc是servlet, 而struts2是filter(处理所有的请求,对特殊请求进行统一处理);- 控制器实例:
struts2是基于对象的,每一次请求都会实例化一个action,每个action都会注入属性,而springmvc是基于方法设计就像servlet一样,只有一个实例(采用的是单例模式);- 管理方式:大部分公司的核心框架采用的是
spring,而springmvc又是spring的一个模块,所以管理起来更加简单,而且提供了全注解方式进行管理。Struts2采用xml很多的配置参数来管理;


- 点赞
- 收藏
- 关注作者
评论(0)