大数据-Storm流式框架(一)

【摘要】 一、storm介绍Storm是个实时的、分布式以及具备高容错的计算系统Storm进程常驻内存(worker,supervisor,nimbus,ui,logviewer。。。)Storm数据不经过磁盘,在内存中处理Twitter开源的分布式实时大数据处理框架,最早开源于github2013年,Storm进入Apache社区进行孵化2014年9月,晋级成为了Apache顶级项目官网 ht...
一、storm介绍

- Storm是个实时的、分布式以及具备高容错的计算系统
- Storm进程常驻内存(worker,supervisor,nimbus,ui,logviewer。。。)
- Storm数据不经过磁盘,在内存中处理
- Twitter开源的分布式实时大数据处理框架,最早开源于github
- 2013年,Storm进入Apache社区进行孵化
- 2014年9月,晋级成为了Apache顶级项目
- 官网 http://storm.apache.org/
- 国内外各大网站使用,例如雅虎、阿里、百度
1、架构:
- Nimbus 1 主 运行于一台主机
- Supervisor N 从 运行于多台主机
- Worker M 进程 运行于一个Supervisor中
map reduce
2、编程模型
- DAG (有向无环图,Topology) 拓扑
- Spout 水龙头
- Bolt 闪电
- 数据流向
3、序列化
kryo 序列化,高效、数据量小
4、数据传输
- ZMQ(twitter早期产品)
- ZeroMQ 开源的消息传递框架,并不是一个MessageQueue
- Netty
- Netty是基于NIO的网络框架,更加高效。(之所以Storm 0.9版本之后使用Netty,是因为ZMQ的license和Storm的license不兼容。)
5、高可靠性
- 异常处理
- 消息可靠性保障机制
6、可维护性
StormUI图形化监控接口

二、Storm的应用场景
1、流式处理(异步 与 同步)
客户端提交数据进行结算,并不会等待数据计算结果
2、逐条处理
例:ETL(数据清洗)extracted transform load
3、统计分析
例:计算PV、UV、访问热点 以及 某些数据的聚合、加和、平均等
客户端提交数据之后,计算完成结果存储到Redis、HBase、MySQL或者其他MQ当中,客户端并不关心最终结果是多少。

4、实时请求应答服务(同步)
客户端提交数据请求之后,立刻取得计算结果并返回给客户端
5、Drpc
同步,storm的功能,分布式RPC
6、实时请求处理
例:图片特征提取

三、Storm比较及计算模型
1、storm和mapreduce的对比
Storm:进程、线程常驻内存运行,数据不进入磁盘,数据通过网络传递。
MapReduce:为TB、PB级别数据设计的批处理计算框架。

2、storm和spark streaming
- Storm:纯流式处理 基于记录
- 专门为流式处理设计
- 数据传输模式更为简单,很多地方也更为高效
- 并不是不能做批处理,它也可以来做微批处理,来提高吞吐
- Spark Streaming:微批处理
- 将RDD做的很小来用小的批处理来接近流式处理
- 基于内存和DAG可以把处理任务做的很快

3、storm计算模型
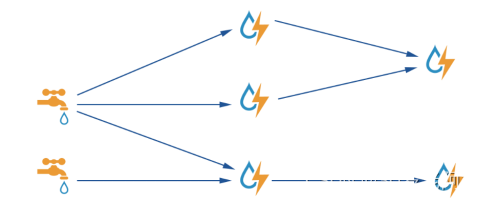


-
Topology – DAG有向无环图的实现
- 对于Storm实时计算逻辑的封装
- 即,由一系列通过数据流相互关联的Spout、Bolt所组成的拓扑结构
- 生命周期:此拓扑只要启动就会一直在集群中运行,直到手动将其kill,否则不会终止
- 区别于MapReduce当中的Job,MR当中的Job在计算执行完成就会终止
-
Tuple – 元组
- Stream中最小数据组成单元
- 看成map集合,类(属性和值)User username, password, birthday
- 类似于struct
-
Stream – 数据流
- 从Spout中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt,所形成的这些数据通道即叫做Stream
- Stream声明时需给其指定一个Id(默认为default)
- 实际开发场景中,多使用单一数据流,此时不需要单独指定StreamId
-
Spout – 数据源
- 拓扑中数据流的来源。一般会从指定外部的数据源读取元组(Tuple)发送到拓扑(Topology)中: 消息队列
- 一个Spout可以发送多个数据流(Stream)
- 可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过SpoutOutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
- Spout中最核心的方法是nextTuple,该方法会被Storm线程不断调用、主动从数据源拉取数据,再通过emit方法将数据生成元组(Tuple)发送给之后的Bolt计算
-
Bolt – 数据流处理组件
- 拓扑中数据处理均由Bolt完成。对于简单的任务或者数据流转换,单个Bolt可以简单实现;更加复杂场景往往需要多个Bolt分多个步骤完成
- 一个Bolt可以发送多个数据流(Stream)
- 可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流,发送数据时通过OutputCollector中的emit方法指定数据流Id(streamId)参数将数据发送出去
- Bolt中最核心的方法是execute方法,该方法负责接收到一个元组(Tuple)数据、真正实现核心的业务逻辑
Stream Grouping – 数据流分组(即数据分发策略)
- Shuffle grouping(随机分组):这种方式会随机分发tuple给bolt的各个task,每个bolt实例接收到的相同数量的tuple。
- Fields grouping(按字段分组):根据指定字段的值进行分组。比如说,一个数据流根据“word”字段进行分组,所有具有相同“word”字段值的tuple会路由到同一个bolt的task中。
- All grouping(全复制分组):将所有的tuple复制后分发给所有bolt task。每个订阅数据流的task都会接收到tuple的拷贝。
- Globle grouping(全局分组):这种分组方式将所有的tuples路由到唯一一个task上。Storm按照最小的task ID来选取接收数据的task。
- None grouping(不分组):在功能上和随机分组相同,是为将来预留的。
- Direct grouping(指向型分组):数据源会调用emitDirect()方法来判断一个tuple应该由哪个Storm组件来接收。只能在声明了是指向型的数据流上使用。
- Local or shuffle grouping(本地或随机分组):和随机分组类似,但是,会将tuple分发给同一个worker内的bolt task(如果worker内有接收数据的bolt task)。其他情况下,采用随机分组的方式。取决于topology的并发度,本地或随机分组可以减少网络传输,从而提高topology性能。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)