Java数组全套深入探究——进阶知识阶段3、sort自然排序


Java数组全套深入探究——进阶知识阶段3、sort自然排序
目录
示例——自定义自然排序(可以自己看看,这里涉及到的内容超出当前范围)
总篇链接:
数组学习的重要意义
数组是我们必须要掌握的数据结构之一,在以后会对我们有非常大的帮助。
- 提高程序效率:数组是一种高效的数据结构,可以快速地访问和修改数据。在实际的生产生活中,数组被广泛应用于各种需要高效数据处理的场景,如图像处理、科学计算、金融分析等。通过学习数组,学生们可以更加高效地处理数据,提高程序的执行效率。
- 增强编程能力:数组是编程中常用的数据结构之一,掌握数组的使用方法对于学生的编程能力提升非常重要。在实际编程过程中,数组的使用非常普遍,掌握数组的使用可以帮助学生更加熟练地进行编程,提高编程效率和代码质量。
- 培养逻辑思维:数组是一种抽象的数据结构,通过学习数组,学生们可以培养自己的逻辑思维能力。在实际的问题解决中,很多问题都可以转化为数组的处理问题,通过学习数组,学生们可以更加清晰地思考问题,并给出有效的解决方案。
对于学生们来说,学习数组可能是一项有些困难的任务,但只要坚持学习,就一定能够掌握它。以下是一些鼓励学生们学习数组的话:
- 数组是编程的基础,掌握数组的使用对于成为一名优秀的程序员非常重要。
- 学习数组可能有些困难,但只要坚持下去,就一定能够掌握它。
- 通过学习数组,你可以更加高效地处理数据,提高程序的执行效率,展现出你的编程能力。
- 数组的应用非常广泛,掌握数组的使用可以让你在未来的学习和工作中更加出色。
- 相信自己,你一定能够掌握数组的使用,成为一名优秀的程序员!
sort自然排序
自然排序(Natural Sort)是一种根据元素的自然顺序进行排序的算法。它常用于对包含文本数据的数组进行排序,以便按照人类可读的顺序排列元素。自然排序算法的具体过程如下:
首先,比较数组中的相邻元素。
如果相邻元素的自然顺序不正确(例如,按字母顺序或数字大小),则交换它们的位置。
继续遍历数组,重复上述比较和交换操作,直到整个数组按照自然顺序排列。
示例:
考虑以下待排序的字符串数组:["file10.txt", "file1.txt", "file2.txt", "file20.txt", "file3.txt"]
使用自然排序对数组进行排序的过程如下:
第1轮:
比较 "file10.txt" 和 "file1.txt",交换位置:["file1.txt", "file10.txt", "file2.txt", "file20.txt", "file3.txt"]
比较 "file10.txt" 和 "file2.txt",不交换位置。
比较 "file20.txt" 和 "file2.txt",交换位置:["file1.txt", "file2.txt", "file10.txt", "file20.txt", "file3.txt"]
比较 "file20.txt" 和 "file3.txt",不交换位置。
第2轮:
排除已排序好的最后一个元素 "file3.txt",继续比较前面的元素。
比较 "file10.txt" 和 "file20.txt",交换位置:["file1.txt", "file2.txt", "file20.txt", "file10.txt", "file3.txt"]
...(以此类推)
重复上述步骤,直到整个数组排序完成。最终排序后的数组为:["file1.txt", "file2.txt", "file3.txt", "file10.txt", "file20.txt"]
通过使用自然排序,我们得到了按照自然顺序排列的文件名列表。请注意,自然排序不是基于简单的字符编码进行排序,而是考虑到了人类可读的顺序,例如将 "file2.txt" 排在 "file10.txt" 之前,以及将 "file10.txt" 排在 "file20.txt" 之前。这使得排序结果更符合人类的预期和理解。
示例——系统自带自然排序
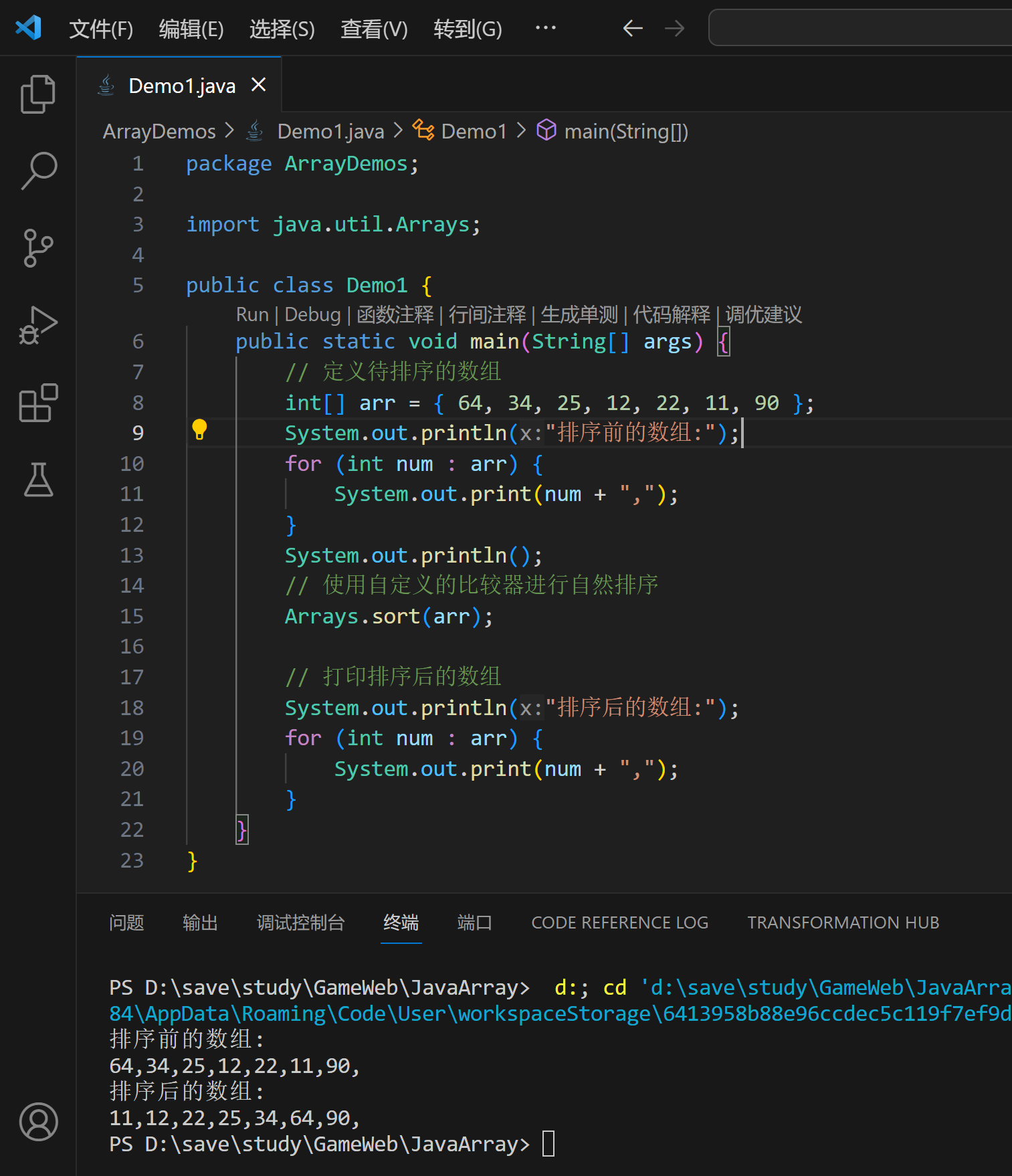
以下是使用Java语言对数组[64, 34, 25, 12, 22, 11, 90]进行自然排序的示例代码,并附带了注释:
示例——自定义自然排序(可以自己看看,这里涉及到的内容超出当前范围)
import java.util.Arrays;
import java.util.Comparator;
public class Demo1 {
public static void main(String[] args) {
// 定义待排序的数组
int[] arr = {64, 34, 25, 12, 22, 11, 90};
System.out.println("排序前的数组:");
for (int num : arr) {
System.out.print(num + ",");
}
System.out.println();
// 将整型数组转换为字符串数组,以便进行自然排序
String[] strArr = Arrays.stream(arr)
.mapToObj(Integer::toString)
.toArray(String[]::new);
// 使用自定义的比较器进行自然排序
Arrays.sort(strArr, new NaturalComparator());
// 打印排序后的数组
System.out.println("排序后的数组:");
for (String str : strArr) {
System.out.print(Integer.parseInt(str) + " ");
}
}
}
// 自定义比较器实现自然排序
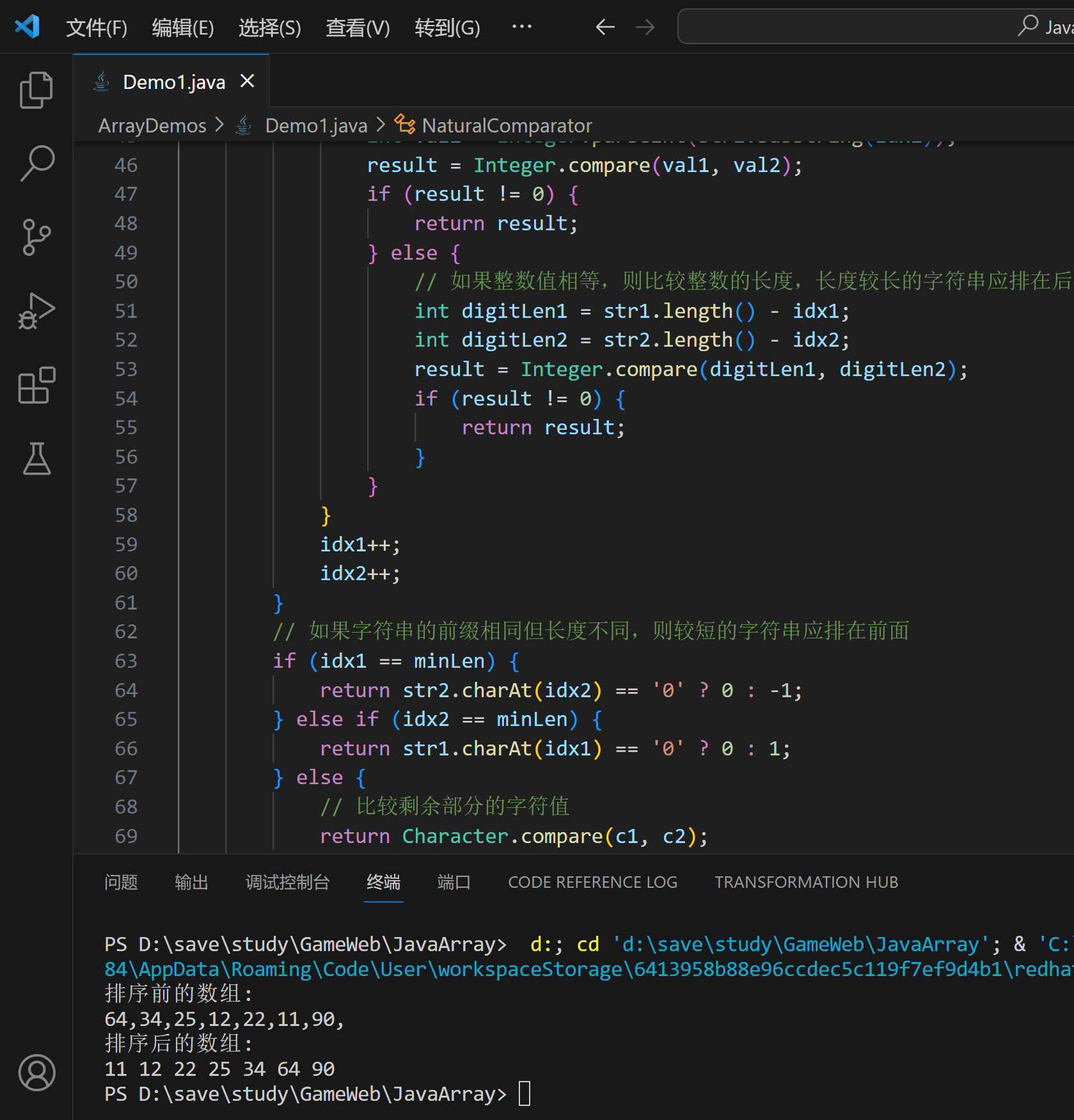
class NaturalComparator implements Comparator<String> {
@Override
public int compare(String str1, String str2) {
int idx1 = 0, idx2 = 0;
int len1 = str1.length(), len2 = str2.length();
int minLen = Math.min(len1, len2);
char c1=' ', c2=' ';
int result;
while (idx1 < minLen && (c1 = str1.charAt(idx1)) == (c2 = str2.charAt(idx2))) {
if (Character.isDigit(c1) && Character.isDigit(c2)) {
// 如果当前字符是数字,则比较整数值
int val1 = Integer.parseInt(str1.substring(idx1));
int val2 = Integer.parseInt(str2.substring(idx2));
result = Integer.compare(val1, val2);
if (result != 0) {
return result;
} else {
// 如果整数值相等,则比较整数的长度,长度较长的字符串应排在后面
int digitLen1 = str1.length() - idx1;
int digitLen2 = str2.length() - idx2;
result = Integer.compare(digitLen1, digitLen2);
if (result != 0) {
return result;
}
}
}
idx1++;
idx2++;
}
// 如果字符串的前缀相同但长度不同,则较短的字符串应排在前面
if (idx1 == minLen) {
return str2.charAt(idx2) == '0' ? 0 : -1;
} else if (idx2 == minLen) {
return str1.charAt(idx1) == '0' ? 0 : 1;
} else {
// 比较剩余部分的字符值
return Character.compare(c1, c2);
}
}
}
对比选择排序、冒泡排序、自然排序
选择排序、冒泡排序和自然排序是三种常见的排序算法,它们之间有一些区别和特点。
选择排序(Selection Sort):
基本思想:在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
时间复杂度:选择排序的时间复杂度为 O(n^2),其中 n 是待排序序列的长度。这是因为每次都需要在未排序序列中找到最小(或最大)元素,需要进行 n-1 次比较和交换操作。
空间复杂度:选择排序的空间复杂度为 O(1),因为它只需要一个额外的存储空间用于临时存储最小(或最大)元素。
冒泡排序(Bubble Sort):
基本思想:通过相邻元素之间的比较和交换,使得每一轮排序过程中最大(或最小)的元素"冒泡"到序列的一端。重复进行多轮排序,直到整个序列有序。
时间复杂度:冒泡排序的时间复杂度为 O(n^2),其中 n 是待排序序列的长度。在最坏情况下,需要进行 n-1 轮比较和交换操作。
空间复杂度:冒泡排序的空间复杂度为 O(1),因为它只需要一个额外的存储空间用于临时存储交换的元素。
自然排序(Natural Sort):
基本思想:按照元素的自然顺序进行排序,例如对于字符串可以按照字母顺序排序,对于数字可以按照数值大小排序。自然排序通常用于处理混合类型的数据,例如字符串和数字的混合列表。
时间复杂度:自然排序的时间复杂度取决于具体的实现方式,但通常也是 O(n^2) 或更高。因为自然排序需要对不同类型的数据进行比较和转换,所以相对于选择排序和冒泡排序来说更加复杂。
空间复杂度:自然排序的空间复杂度也取决于具体的实现方式,但通常也是 O(1) 或更高。可能需要额外的存储空间用于存储转换后的数据或进行其他操作。
总结:
选择排序、冒泡排序和自然排序都是简单的排序算法,适用于小规模数据的排序。
选择排序和冒泡排序的时间复杂度和空间复杂度都是 O(n^2) 和 O(1),但它们在实现方式和交换操作上有所不同。
自然排序适用于处理混合类型的数据,但实现相对复杂,时间复杂度和空间复杂度可能较高。

- 点赞
- 收藏
- 关注作者
评论(0)