使用按位运算符创建内存对齐的数据结构

内存对齐是计算机编程中的一个重要概念,它确保了高效的内存访问,并有可能在各种性能关键型系统和应用中产生可观的性能提升。
内存对齐的一个示例用例是在 Linux 中使用直接 I/O。在 Linux 中打开带有该 O_DIRECT 标志的文件会指示 Linux 内核完全绕过页面缓存并将数据结构直接写入磁盘。这对于具有大量写入工作负载和高带宽数据传输要求的应用程序特别有用,但它需要对齐的内存缓冲区才能工作(否则内核会静默回退到缓冲 I/O)。
内存对齐可能有用的另一个用例是保持原子性和保护并发操作的完整性。内存对齐可确保没有其他指令可以中断已在运行的 CPU 操作,因为 CPU 对对齐的内存字进行原子操作。在处理并发时,此方法可实现无锁数据结构,并大大减少读取和写入操作期间数据损坏的可能性。
对齐内存块
假设我们有一个 16 KiB 的内存块,需要将其对齐在 512 字节的地址边界上(即,一个可以被数字 512 整除的内存地址)。
新块的初始化方式如下:
blockSize := 16 << 10 // 16 KiB
block := make([]byte, blockSize)
我们可以通过查看 &block0 和检查返回的地址来确定块是否正确对齐。让我们想象一下,驻 &block0 留在 address 0xc0003bccf0 。在二进制文件中,它看起来像:
1100 0000 0000 0000 0011 1011 1100 1100 1111 0000
为了确保块是对齐的,我们需要证明这个内存地址可以被 512 整除(即除以 512 时它的余数是 0)。
512的二进制是
512 = 0000 0010 0000 0000
内存地址 0xc0003bccf0 肯定不是 512 字节对齐的,因为其最后 9 位中有多个字节:
1100 0000 0000 0000 0011 1011 1100 1100 1111 0000
问题是,我们如何通过代码得出这个结论?这就是按位运算符可以提供帮助的地方。我们可以创建一个由 9 个尾随 1 位和所有前导 0 位组成的位掩码。然后,我们可以在内存地址和位掩码之间执行按位 AND。如果内存地址正确对齐,则结果将为 0。如果内存地址未对齐,则结果将是 (0, 512) 范围内的正值。
考虑下面的两个例子:1536 可以被 512 整除,余数为 0,而 3563 不能整除,余数为 491。通过使用位掩码,我们可以很容易地识别这一点:
0110 0000 0000 -> 1536
0001 1111 1111 -> bitmask
─────────────────
0000 0000 0000 -> 0
└── 1536 & bitmask == 0
1101 1110 1011 -> 3563
0001 1111 1111 -> bitmask
─────────────────
0001 1110 1011 -> 491
└── 3563 & bitmask == 491
将内存地址 0xc0003bccf0 转换为二进制,并使用位掩码执行按位 AND。
1100 0000 0000 0000 0011 1011 1100 1100 1111 0000
0000 0000 0000 0000 0000 0000 0000 0001 1111 1111
────────────────────────────────────────────────────
0000 0000 0000 0000 0000 0000 0000 0000 1111 0000 -> 240
结果表明,我们的对齐方式偏离了 240 字节(我们的内存地址位于前面的 512 字节边界前 240 字节)。如果地址正确对齐,我们应该得到一个零,但我们没有。
这种对齐检查可以在 Go 中执行,如下所示:
alignment := int(uintptr(unsafe.Pointer(&block[0])) & uintptr(bitmask))
前面的 512 字节对齐地址是越界的,因此我们不能为了对齐它而将块向后移动 240 字节。但是,我们可以前进到下一个 512 字节的边界,因为它位于我们的内存块内。
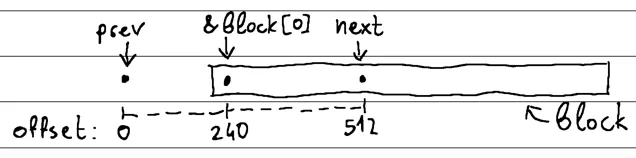
要弄清楚向前推进指针的字节数,我们可以依靠另一个重要的见解:
两个 N 对齐偏移量之间的距离正好 N 是字节。
位于两个 512 字节对齐边界之间的第 240 个字节。这意味着下一个字节对齐的偏移量位于字节之后 x + 240 = 512 :
x + 240 = 512
x = 512 - 240
x = 272
如果我们将内存块的起始位置从 &block0 更改为 , &block272 我们将落在一个 512 字节对齐的边界上:
offset := alignmentSize - alignment
block = block[offset:]
然而,这种变化是有问题的,因为我们最初的要求是维护一个能够容纳 16 KiB 数据的块,但在对齐后,我们最终的容量减少了, 16 KiB - 272 B 这违反了我们最初的要求。
知道初始对齐方式可以与 (0, 512) 字节范围内的值相差无几,我们可以通过修改定义 block 来纠正这个问题,如下所示:
alignmentSize := 512 // bytes
blockSize := 16 << 10 // 16 KiB
block := make([]byte, blockSize + alignmentSize)
额外的 alignmentSize 将给我们足够的回旋余地。然后,为了将指针前进到正确的位置,同时将总容量保持在 16 KiB,我们可以使用以下类型的 blocklow:high:max 切片表达式:
offset := alignmentSize - alignment
block = block[offset : offset+blockSize: offset+blockSize]
这样,我们就满足了所有要求:
- &block0 现在指向一个内存地址,该地址 0xc0003bce00 可以被 512 整除,因此是 512 字节对齐的。
- 内存块保留了 16 KiB 的全部容量。
package main
import (
"unsafe"
)
func main() {
alignmentSize := 512 // bytes
bitmask := alignmentSize - 1
blockSize := 16 << 10 // 16 KiB
block := make([]byte, blockSize+alignmentSize)
alignment := int(uintptr(unsafe.Pointer(&block[0])) & uintptr(bitmask))
offset := 0
if alignment != 0 {
offset = alignmentSize - alignment
}
block = block[offset : offset+blockSize : offset+blockSize]
}
创建对齐的内存分配器
让我们来探讨另一个用例,我们有一个任意大小的内存缓冲区,我们想设计一个基于竞技场的分配器,该分配器在该缓冲区上运行,并确保任何新添加的数据都是 4 字节对齐的(即,每个新添加的数据段从可被 4 整除的偏移量开始)。初始数据插入应从偏移量 0 开始。

从一个能够容纳 1 KiB 数据的空缓冲区开始。
bufferSize := 1 << 10 // 1 KiB
buffer := make([]byte, bufferSize)
定义了一个 struct 来概述基于竞技场的分配器。
type Arena struct {
buffer []byte
offset int // next available offset
}
包含 struct 两个字段。该 buffer 字段包含我们的 []byte 切片,该字段包含下一个 4 字节对齐的偏移量,该 offset 偏移量为数据插入打开。知道数据插入应该从 offset 0 开始,我们初始化 Arena 0 结构作为初始偏移量并传递我们之前创建的。 buffer
arena := &Arena{buffer, 0}
接下来,我们使用 faker 包生成一些测试数据。它 faker.Word() 的方法旨在从流行的占位符文本 Lorem Ipsum 中返回一个随机单词。每个单词占用 1 到 14 个字节(这些字节对应于最短和最长可能单词的长度)。
randomData := []byte(faker.Word())
将 string 转换为 []byte 使用原始内存缓冲区。AS randomData 为我们提供了一个随机的字节序列,我们可以用来 copy() 将该数据移动到我们的缓冲区中。我们只需要知道哪个偏移量是开放的,可以插入。
dataSize := len(randomData)
copy(buffer[offset:offset+dataSize:offset+dataSize], randomData)
虽然我们可以直接从 arena.offset 现场获得电流偏移,但从长远来看,这是不切实际的。我们最好使用 Arena 方法,该方法封装了逻辑,既可以通知我们当前可以插入的偏移量,也可以根据插入的数据的大小计算和存储下一个对齐的偏移量。
func (a *Arena) Alloc(dataSize int) (int, error) {
currOffset := a.offset
var nextOffset int // TODO: About to implement
if nextOffset > len(a.buffer) {
return currOffset, errors.New("arena is full")
}
a.offset = nextOffset
return currOffset, nil
}
假设我们第一次调用返回 faker.Word() 长度为 11 个字节的单词 consequatur 。应用于我们的内存缓冲区时,它最终应该占用偏移量, 0, 10 并 arena.Alloc() 应 12 计算为下一个可用的插入偏移量。
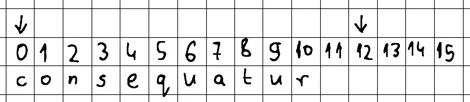
内存缓冲区只能容纳 N 个元素,从一个 N 字节对齐的偏移量开始,直到到达下一个 N 字节对齐的偏移量。

因此,找到随后的 N 字节对齐偏移量就像将 N 添加到我们刚刚穿过的对齐偏移量一样简单:
alignment := 4 // bytes
nextOffset := prevOffset + alignment // 8 + 4 = 12
最终可以起草我们 Alloc() 方法的初始工作版本。
const (
alignment = 4 // in bytes
bitmask = alignment - 1
)
func (a *Arena) Alloc(dataSize int) (int, error) {
currOffset := a.offset
landingOffset := currOffset + dataSize - 1
distance := landingOffset & bitmask // distance from previous 4-byte aligned offset
prevOffset := landingOffset - distance // previous 4-byte aligned offset
nextOffset := prevOffset + alignment // next 4-byte aligned offset
if nextOffset > len(a.buffer) {
return currOffset, errors.New("arena is full")
}
a.offset = nextOffset
return currOffset, nil
}
但有一种更优雅的方法来使用按位运算符完成相同的任务。让我们看一下 、 bitmask prevOffset landingOffset 和 nextOffset 的二进制表示。
3 = 0000 0011 // bitmask
8 = 0000 1000 // prev 4-byte aligned offset
10 = 0000 1010 // landing offset
12 = 0000 1100 // next 4-byte aligned offset
这里有一个巧妙的技巧:通过翻转位掩码并应用带有着陆偏移量的按位 AND,我们可以轻松确定先前对齐的偏移量,而无需执行任何额外的算术运算。
0000 1010 -> 10 (our landing offset)
1111 1100 -> -4 (our flipped bitmask -> ^3 = -4)
────────────
0000 1000 -> 8
└── 10 & ^3 = 8
这在代码中表达的时间也短得多:
// before
landingOffset := currOffset + dataSize - 1
distance := landingOffset & bitmask
prevOffset := landingOffset - distance
// after
prevOffset := (currOffset + dataSize - 1) & ^bitmask
与其单独应用一元按位补码运算符和标准按位, ^ 不如使用 Go bitclear 运算符 &^ ; & 它产生相同的结果:
prevOffset := (currOffset + dataSize - 1) &^ bitmask
此操作可以看作是向下舍入到最接近的 N 字节对齐偏移量。但是,最接近的 N 字节对齐偏移量被占用,我们的目标是达到下一个可用偏移量(可以这么说,四舍五入)。知道在到达下一个 N 字节对齐偏移量之前,我们可以存储不超过 N 个元素,因此我们当然可以加 N 到 prevOffset 来计算 nextOffset 。但是,我们也可以通过简单地越过下一个 N 字节对齐的边界然后向下舍入来直接计算它。
要越过边界,我们只需要将位掩码添加到 N 我们的 landingOffset 边界,然后应用位掩码即可获得正确的偏移量。
landingOffset := currOffset + dataSize - 1
nextOffset := (landingOffset + alignment) &^ bitmask
这相当于:
nextOffset := (currOffset + dataSize - 1 + alignment) & ^bitmask
进一步简化这一点
nextOffset := (currOffset + dataSize + bitmask) & ^bitmask
最终代码
package main
import (
"errors"
"github.com/go-faker/faker/v4"
)
const (
// alignment = 4 /* bytes */; bitmask = alignment - 1
bitmask = 3
)
type Arena struct {
buffer []byte
offset int // next offset open for insertion
}
func (a *Arena) Alloc(dataSize int) (int, error) {
currOffset := a.offset
nextOffset := (currOffset + dataSize + bitmask) &^ bitmask
if nextOffset > len(a.buffer) {
return currOffset, errors.New("not enough memory")
}
a.offset = nextOffset
return currOffset, nil
}
func main() {
bufferSize := 1 << 10 // 1 KiB
buffer := make([]byte, bufferSize)
arena := &Arena{buffer, 0}
for {
// insert data until we run out of memory
randomData := []byte(faker.Word())
dataSize := len(randomData)
offset, err := arena.Alloc(dataSize)
if err != nil {
return // out of memory, stop inserting data
}
copy(buffer[offset:offset+dataSize:offset+dataSize], randomData)
}
}

- 点赞
- 收藏
- 关注作者
评论(0)