【C++杂货铺】缺省参数、函数重载

一、缺省参数
1.1 定义
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
//缺省参数
void fun(int a = 10)
{
cout << a << endl;
}
int main()
{
fun(2);//传参了,使用显式传递的值
fun();//没有传参,使用缺省参数
}

上面代码在fun函数的形参部分给了缺省值10,这意味着在调用fun函数的时候可以传参,也可以不传参,如果传参了那形参a就使用显式传的值,如果没有传参那形参a就使用缺省值10。
1.2 缺省参数分类
- 全缺省参数
void text(int a = 5, int b = 15, int c = 25)//全缺省,所有参数都给了缺省值
{
cout << a << ' ';
cout << b << ' ';
cout << c << ' ';
cout << endl;
}
int main()
{
text(1, 2, 3);
text(1, 2);
text(1);
text();
return 0;
}

对于全缺省参数在传参的时候,参数是按照从左往右的顺序进行缺省的,不能跳着缺省,即:让第一个形参和第三个形参都使用显式传递值,而让第二个参数使用缺省值,这种做法是不被允许的。以上的代码为例:当一个参数也没传的时候,形参全部使用缺省值;只传一个参数的时候,这个参数会赋值给第一个形参,后面两个形参使用缺省值;传两个参数的时候,会把第一个实参赋值给第一个形参,把第二个实参赋值给第二个形参,最后一个形参使用缺省值;传三个参数的时候,所有形参都是用实参传过来的值。这里要与参数压栈区分,参数压入栈桢的顺序是从右往左。
- 半缺省参数
void text(int a, int b = 15, int c = 25)//半缺省,只有部分参数给了缺省值
{
cout << a << ' ';
cout << b << ' ';
cout << c << ' ';
cout << endl;
}
int main()
{
text(1, 2, 3);
text(1, 2);
text(1);
return 0;
}
注意:
半缺省参数必须从右往左依次给缺省值,即:第一个形参和第二个形参给了缺省值,而第三个形参没有给缺省值,这种情况是不被允许的。也不能隔着给,即:第三个形参和第一个形参给了缺省值,而第二个形参没有给缺省值,这种情况也是不被允许的。
1.3 缺省参数只能出现在函数声明中
为了避免出现不一致的情况,要求缺省参数不能在函数声明和定义中同时出现,并且只能出现在函数的声明中。为什么不能只出现在函数的定义中?
因为在预处理阶段会把头文件展开,一般函数的声明就放在头文件中。如果只在函数的定义中给了缺省值,那头文件展开后,函数的声明语句中并没有缺省参数,此时如果在调用该函数的时候没有传参希望使用它的缺省值,那在程序编译的过程中就会出现问题,即:函数的声明没给出缺省值,意味着需要显式传参,但在调用该函数的时候却没有传参。
二、函数重载
在自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了。比如:有人说,我们国家有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是男足。前者是“谁也赢不了!”,后者是“谁也赢不了!”但是大家懂的都懂,前者意思是谁都赢不了我们,而后者的意思是我们赢不了别人。
2.1 定义
函数重载是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数或类型或类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
2.2 构成重载的几种情况
- 参数类型不同:
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
int main()
{
cout << Add(1, 2) << endl;
cout << Add(1.0, 2.0) << endl;
}

上面的代码定义了两个同名的Add函数,但是它们的参数类型不同,第一个两个参数都是int型,第二个两个参数都是double型,在调用Add函数的时候,编译器会根据所传实参的类型自动判断调用哪个函数。至于编译器为什么能这么做稍后再说。
- 参数个数不同:
void fun()
{
cout << "f()" << endl;
}
void fun(int a)
{
cout << "f(int a)" << endl;
}
int main()
{
fun();
fun(1);
return 0;
}

- 参数类型顺序不同:
// 3、参数类型顺序不同
void Text(int a, char b)
{
cout << "Text(int a,char b)" << endl;
}
void Text(char b, int a)
{
cout << "Text(char b, int a)" << endl;
}
int main()
{
Text(1, 'a');
Text('a', 1);
return 0;
}
- 有缺省参数的情况
void fun()
{
cout << "f()" << endl;
}
void fun(int a = 10)
{
cout << "f(int a)" << endl;
}
int main()
{
//fun();//无参调用会出现歧义
fun(1);//调用的是第二个
return 0;
}
上面代码中的两个fun函数根据函数重载的定义他俩是构成函数重载的,编译可以通过,因为第一个没有参数,第二个有一个整型参数,属于上面的参数个数不同的情况。但是fun函数存在一个问题:在无参调用的时候会产生歧义,因为对两个fun函数来说,都可以不传参。
注意:
返回值的类型与函数是否构成重载无关。即:函数名相同,形参列表形相同,返回值不同不会构成函数重载。
2.3 C++支持函数重载的原理
上面说到,编译器会自动根据参数的类型去判断应该调用哪个函数,那编译器究竟是如何做到的呢?要回答这个问题会涉及到一些编译链接的知识,遗忘的同学可以去看看我之前的文章:【C语言进阶】编译链接。
其实这里涉及到函数签名的概念,函数签名包含了一个函数的信息,包括函数名、它的参数类型、他所在的类和名称空间以及其他信息。函数签名用于识别不同的函数,就像签名用于识别不同的人一样,函数的名字只是函数签名的一部分。对于函数名相同,参数列表不同的函数,编译器和链接器处理符号的时候,它们使用某种名称修饰的方法(不同的编译器会有所不同),使得每个函数签名对应一个修饰后名称。编译器在汇编过程中,会将函数和变量的名字进行修饰,形成符号名,也就是说C++的源代码编译后的目标文件中所使用的符号名是相应的函数和变量的修饰后名称。C++编译器和链接器都使用符号来标识和处理函数和变量,所以对于不同函数签名的函数,即使函数名相同,编译器和链接器都认为他们是不同的函数。
由于Windows下的修饰规则过于复杂,而Linux下g++的修饰规则简单易懂,所以下面我将利用g++演示经过修饰后的名称。以下面这段代码为例:
#include <stdio.h>
int Add(int left, int right)
{
printf("int Add(int left, int right)\n");
return left + right;
}
double Add(double left, double right)
{
printf("double Add(double left, double right)\n");
return left + right;
}
int main()
{
Add(1,2);
Add(1.0,2.0);
return 0;
}
先用g++ text.cpp -o text.out这条指令对上面的代码进行编译生成一个可执行程序tetx.out,再用objdump -S text.out指令查看修饰后名称。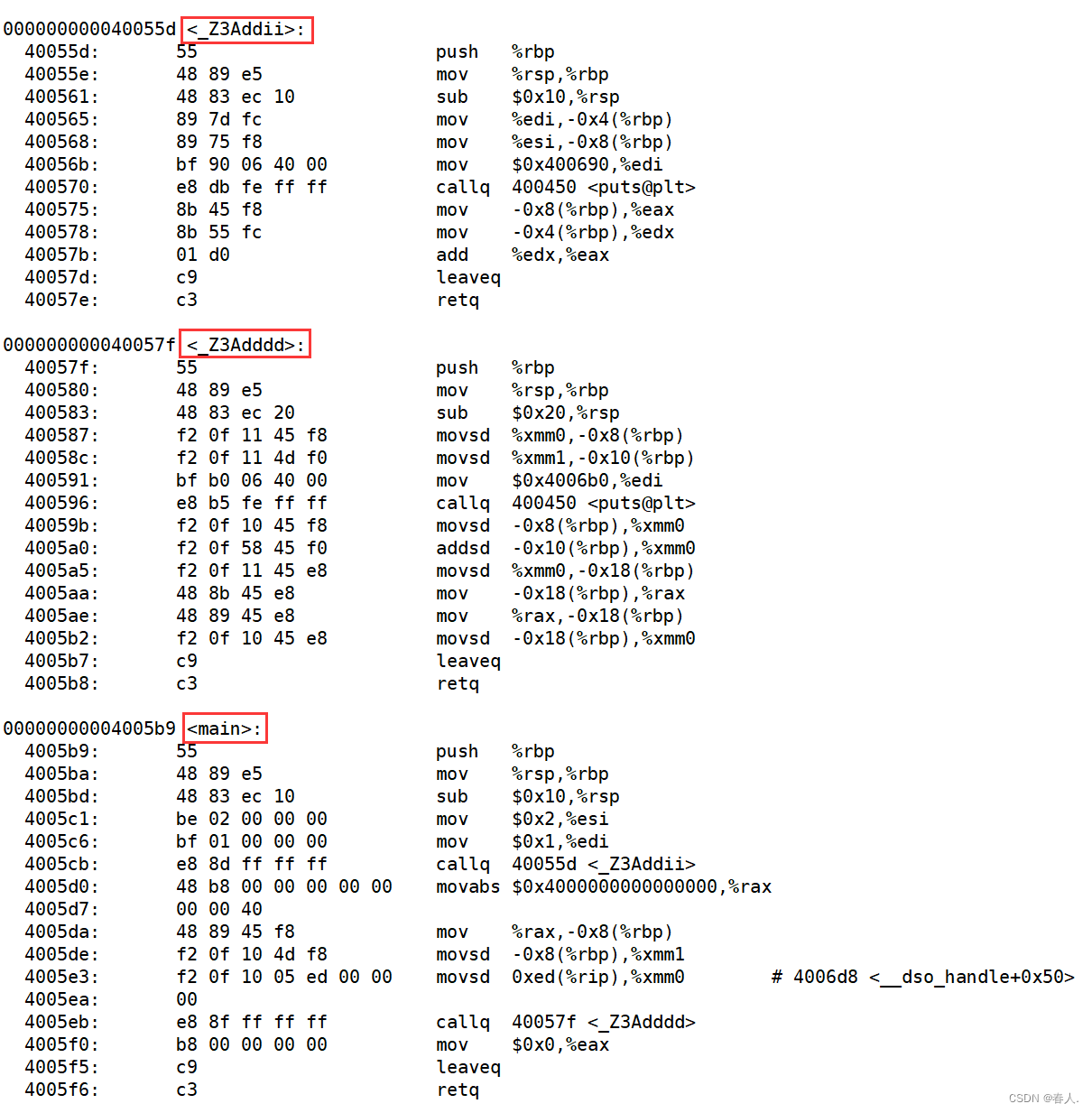
其中_Z是固定的前缀;3表示函数名的长度;Add就是函数名;i是int的缩写,两个i表示两个参数都是int类型,d是double的缩写,两个d表示两个参数都是double类型。C++就是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。通过分析可以发现,修饰后的名称中并不包含任何于函数返回值有关的信息,因此也验证了上面说的返回值的类型与函数是否构成重载无关。
再来看看C语言编译器gcc的处理结果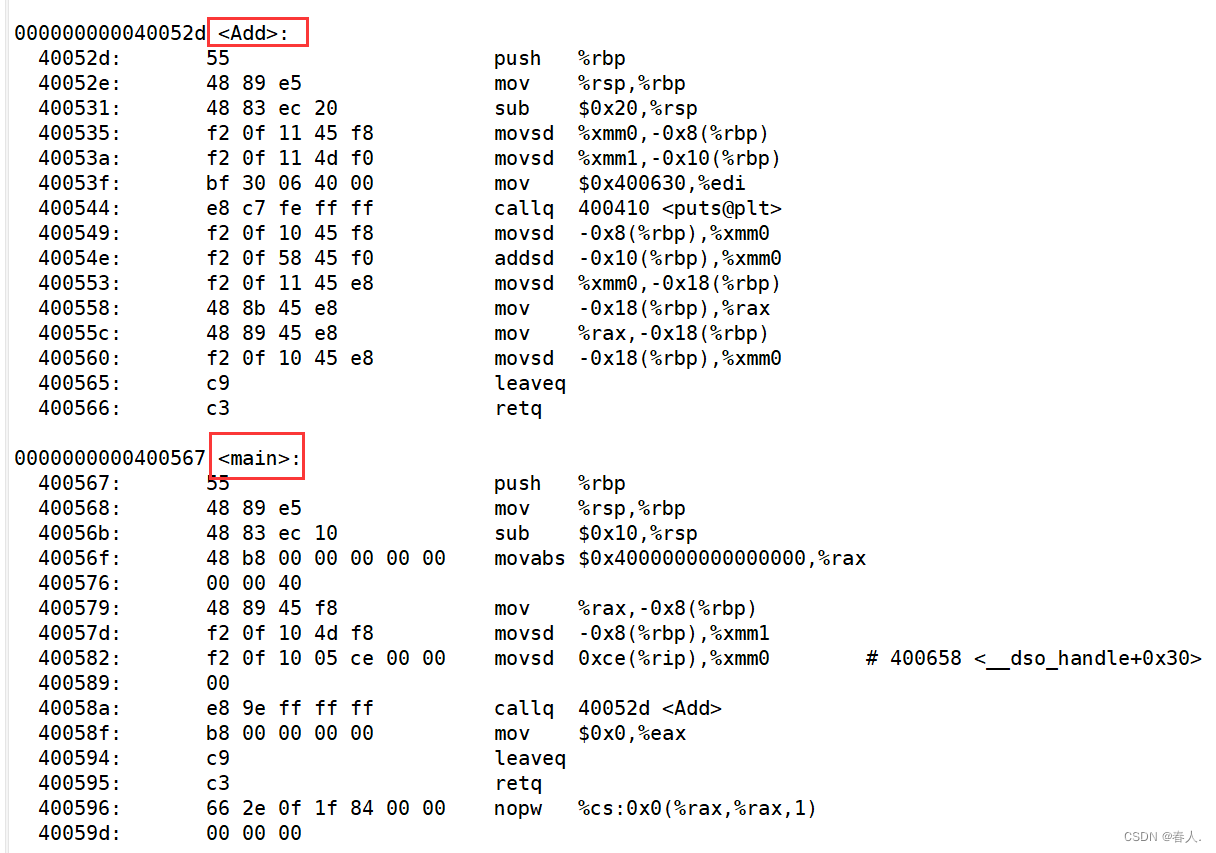
可以看出经过gcc编译后,函数名字的修饰没有发生改变。这也就是为什么C语言不支持函数重载,因为同名函数没办法区分。
今天的分享到这里就结束啦!如果觉得文章还不错的话,可以三连支持一下,您的支持就是春人前进的动力!

- 点赞
- 收藏
- 关注作者
评论(0)