Milvus 2.3.功能全面升级,核心组件再升级,超低延迟、高准确度、MMap一触开启数据处理量翻倍、支持GPU使用!

Milvus 2.3.功能全面升级,核心组件再升级,超低延迟、高准确度、MMap一触开启数据处理量翻倍、支持GPU使用!
1.Milvus 2.3版本全部升级简介
Milvus 2.3.0 不仅包含大量的社区呼声很高的新功能,还带来了诸如 GPU 支持、Query 架构升级、更强的负载均衡、调度能力、新的消息队列Arm 版本镜像、可观测性、运维工具升级等能力,这标志着 Milvus 2.x 系列从 production ready,走向成熟、可靠、生态繁荣、运维更友好的发展路径。

1.1 架构升级
1.1.1 GPU 支持
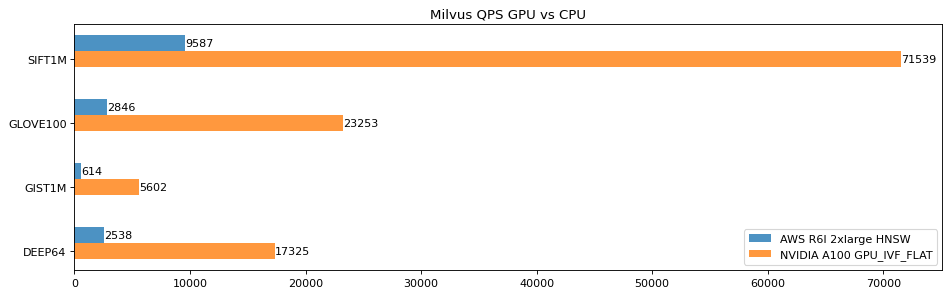
早在 Milvus 1.x 版本,我们就曾经支持过 GPU,但在 2.x 版本中由于切换成了分布式架构,同时出于对于成本方面的考虑,暂时未加入 GPU 支持。在 Milvus 2.0 发布后的一年多时间里,Milvus 社区对 GPU 的呼声越来越高,再加上 NVIDIA 工程师的大力配合——为 Knowhere(Milvus 索引引擎)增加了最新的 RAFT 算法支持,使得 Milvus 不仅加回了 GPU 支持,而且还以最快的速度支持了业界最新的算法。经测试,GPU 版本相较于 CPU HNSW 索引有了 3 倍以上的 QPS 提升,部分数据集有近 10 倍的提升。
下表是 GPU-IVF-FLAT 和 HNSW 在 Milvus E2E 上的 QPS 数据,host 的 size 是 8c32g,NVIDIA A100 GPU。NQ 为 100:

1.1.2 Arm64 支持
随着 Arm64 CPU 的普及程度越来越高,众多云厂商也纷纷发布了基于 Arm64 CPU 的实例。为此,从 Milvus 2.3.0 开始,Milvus 不仅会发布 Amd64 镜像,也会发布官方 Arm64 镜像,这一优化也能够帮助 macOS 用户更地开发测试 Milvus。
1.1.2 QueryNodeV2
QueryNode 是继 QueryCoord 之后,第二个重写的服务。
为什么要重写 QueryNode?老版本有哪些问题?展开来讲可以写成万字小作文。简单来说,QueryNode 承担了整个 Milvus 系统中最重要的检索服务,其稳定性、性能、扩展性对 Milvus 至关重要,但 QueryNodeV1 存在状态复杂、消息队列重复、代码结构不清晰、报错内容不直观等问题。在 QueryNodeV2 的新设计中,我们重新梳理了代码结构、将复杂的状态改为无状态的设计、移除了 delete 数据的消息队列减少了资源浪费,在后续持续的稳定性测试中,QueryNodeV2 的表现更加优异。
1.1.3 IndexCoord 和 Datacoord 合并
Indexcoord 和 Datacoord 在 2.3.0 版本中被合并,这简化了 Milvus 部署的复杂度,也降低了元信息在不同 coord 之间通信的成本。在接下来的版本中,datanode 和 indexnode 的部分功能也将被合并。
1.1.4 基于 NATs 的消息队列
Milvus 是基于日志的架构,消息队列的扩展性、性能、稳定性对 Milvus 而言至关重要。此前,为了快速完成 2.x,我们选择了业内主流的 Pulsar 和 Kafka 作为核心的 Log Broker。在实际运维的过程中,我们也发现了不少外置消息队列的局限性,一是在多 topic 场景下的稳定性问题,二是大量重复消息时的去重以及空载时的资源消耗问题,三是二者都与 Java 生态绑定较紧密 Go SDK 维护不是很积极。
在此情况下,一个更符合 Milvus 需求的 Log Broker 显得至关重要,经过调研和测试,我们选定 NATs + Bookeeper 的方式作为自研的 Log Broker,这更贴合 Milvus 的使用场景。目前,NATs Log Broker 还处于实验阶段,欢迎有兴趣的同学尝试以及反馈问题。
1.2 新功能
- Upsert 功能
支持用户通过 upsert 接口更新或插入数据。已知限制,自增 id 不支持 upsert;upsert 是内部实现是 delete + insert 所以性能上会有一定损耗,如果明确知道是写入数据的场景请继续使用 insert。
1.2.1 Range Search 功能
支持用户通过输入参数指定 search 的 distance 进行查询,返回所有与目标向量距离位于某一范围之内的结果。例如:
search_params = {"params": {"nprobe": 10, "radius": 10, "range_filter" : 20}, "metric_type": "L2"}
res = collection.search(
vectors, "float_vector", search_params, topK,
"int64 > 100", output_fields=["int64", "float"]
)
该例子中就会返回距离在 10~20 之间的向量。需要注意的是不同的 metric 计算距离的方式不同,所以值域、排序逻辑各异,需要详细了解每个 metric 的特点之后再使用此功能。此外,RangeSearch 依然具有最大返回结果不超过 16384 条的限制。
1.2.2 Count 接口
为了计算 collection 中的数据行数,很多用户会使用 num_entities 接口,但是此接口需要手动调用 flush 之后才能计算准确,但频繁 flush 会造成大量小文件刷盘,对 Milvus 的性能和稳定性都有较大影响。所以在此版本中提供了 count(*) 表达式,可以实时计算准确的 collection 行数。count 操作较为消耗资源,不建议大量并发调用。
1.2.3 Cosine metrics
Cosine 距离在大模型领域有着广泛的应用,尤其是在大模型领域,Cosine Metrics 几乎是衡量向量近似度的事实标准。Milvus 2.3.0 版本原生支持了 Cosine 距离,用户不再需要通过向量归一化计算 IP metrics 来使用 cosine 距离。
1.2.4 查询返回原始向量
出于查询性能的考虑,之前的版本中 Milvus 不支持返回原始向量,此版本中补齐了该功能。需要注意的是,返回原始向量会有二次查询产生,所以对性能会产生较大影响,如果是性能 critical 场景,建议使用 HNSW、IVFFLAT 等包含原始向量的索引。
目前,部分量化的索引,如 IVFPQ,IVFSQ8 不支持获取原始向量,关于具体哪些索引支持返回原始向量请参考 https://github.com/zilliztech/knowhere/releases.
1.2.5 ScaNN 索引
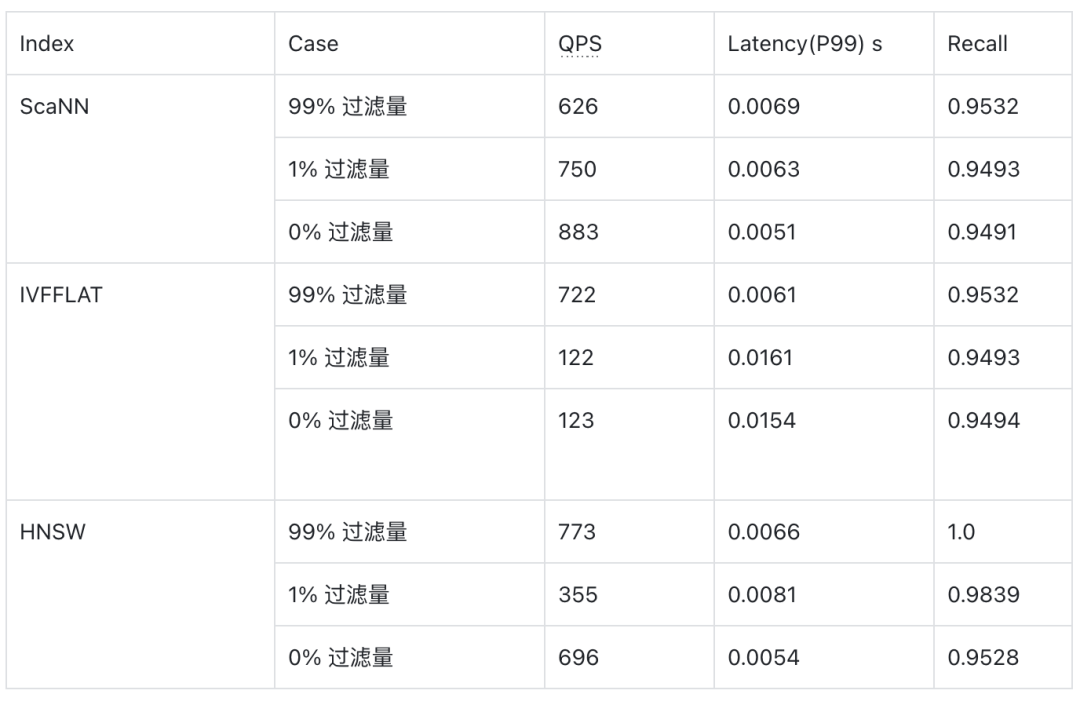
Milvus 目前支持了 Faiss 中的 FastScan 算法,在各项 benchmark 中有着不俗的表现,对比 HNSW 有 20% 左右提升,约为 IVFFlat 的 7 倍,同时构建索引速度更快。ScaNN 在算法上跟 IVFPQ 比较类似,聚类分桶,然后桶里的向量使用 PQ 做量化,区别是 ScaNN 对于量化比较激进,搭配上 SIMD 计算效率较高,但是精度损失会比较大,需要有原始向量做 refine 的过程。
下表是 ScaNN、HNSW 和 IVFFLAT 在 Cohere1M(768 维)的数据集下的性能表现,数据来自于 VectorDBBench。
1.2.6 Iterator
Pymilvus 中提供了 iterator 接口,可以通过迭代器的方式拉取数据,Query 和 Range Search 场景下,通过迭代器可以获取超过 16384 条数据限制的数据。Iterator 类似于 ES 的 scroll 接口和关系数据库中的 cursor,比较适合后台批量处理数据。
- Json Contains
Milvus 2.3.0 支持了 Json 数组 contains 表达式,可以支持判断一个 json 数组是否包含了一个元素或者一组元素。详细文档请参考 https://milvus.io/docs/json_data_type.md。
- CDC 支持
Change Data Capture 是数据库系统中很通用的功能,可以用于跨机房主备数据同步、增量数据备份、数据迁移等场景,得益于 Milvus 基于日志的架构很容易实现此功能。Milvus 的 CDC 代码在 https://github.com/zilliztech/milvus-cdc.
1.3 Enhancement
1.3.1 MMap 技术提升数据容量
MMap 是 Linux 内核提供的技术,可以将一块磁盘空间映射到内存,这样一来我们便可以通过将数据加载到本地磁盘再将磁盘 mmap 到内存的方案提升单机数据的容量,经过测试使用 MMap 技术后数据容量提升了 1 倍而性能下降在 20% 以内,大大节约了整体成本,对于成本敏感的用户欢迎试用此功能。
1.3.2 filter 场景性能提升
对于标量向量的混合查询场景,Milvus 的执行计划是先执行标量过滤再执行向量检索,这就意味着标量过滤之后会有大量的数据被过滤掉,如果过滤掉的数据过多会引起向量索引性能急剧下降,通过优化 HNSW 索引的数据过滤策略,2.3.0 中优化了此场景中的性能。除此之外,通过引入手动的向量化执行技术,标量数据过滤的速度也得到了大幅提升。
1.3.3 Growing 索引
Milvus 的数据分为两类,分别为已索引的数据和流式数据。对于已索引的数据自然可以使用索引加速查询,但流式数据只能使用逐行暴力检索,对性能影响较大,为了解决此类问题在 2.3.0 中加入了 Growing index,自动为流式数据建立实时索引,保障查询性能。
1.3.4 多核环境资源利用率提升
向量近似计算是计算密集型的任务,CPU 使用率是非常重要的指标,在 CPU 核数较多的情况下可能会出现 CPU 使用率无法超过 70% 的情况,经过优化 Milvus 2.3.0 能够更加充分利用好 CPU 资源实现性能提升。
1.4 稳定性
- New load balance
在 2.1.0 版本中,Milvus 支持了内存多副本,用户可以通过多副本的方式提升 QPS。经过半年多的生产实践,收到了很多来自社区的反馈,其中主要集中在添加副本后 QPS 没有立刻提升、节点下线后系统恢复稳定时间较长、节点之间负载不均衡、CPU 使用率不高等问题。这些问题归因到一起可以认为是负载均衡逻辑鲁棒性低,故障恢复能力较弱的问题,经过重新设计的负载均衡算法,采用基于负载的动态负载均衡算法,能够及时的发现节点上下线、负载不均衡等现象及时调整请求调度。经过测试可以在秒级发现故障、负载不均衡、节点上线等事件,及时调整负载。
1.5 可运维性
- 动态配置
修改配置是运维、调优数据库中的常见操作,从此版本开始 Milvus 支持动态修改配置项而无需重启集群,支持的方式有两种一是修改 etcd 中的 kv,二是直接修改 Milvus.yaml 配置文件。需要注意的是并不是所有的配置项都支持动态配置,详见 Milvus 文档 https://milvus.io/docs。
- Tracing 支持
通过 tracing 发现系统中的瓶颈点,是调优的重要手段,从 2.3.0 开始 Milvus 支持 Opentelemetery tracing 协议,支持此协议的 tracing collector 例如 jaeger 都可以接入观测 Milvus 的调用路径。
- Error Code 增强
团队重新梳理了 Milvus 的 error code 以及设计了新版 error code 的架构,这次升级后,Milvus 的报错会更清晰。
1.6 工具升级
- Birdwatcher tool 升级
配套的 Birdwatcher 在这几个月中经过持续的演进,增加了众多功能,例如:
- 支持 restful API,更方便集成到其他诊断系统中
- 支持 pprof 命令,更方便的与 go pprof tool 集成
- 增加 storage analysis 命令分析存储占用
- 与 2.3.0 的 event log 模式集成,支持通过结构化的数据分析 Milvus 内部事件,提升分析日志效率
- 支持修改 / 查看 etcd 中的配置
可以说,升级后的 Birdwatcher 功能众多,对需要深度运维 Milvus 的用户很有帮助。未来,Birdwatcher 还会增加更加有用的命令,欢迎大家试用。
- Attu 升级
全新设计了 Attu 界面,用户体验更友好:
1.7 Break Change
- 移出 Time travel 功能
由于 Time travel 功能几乎没有用户使用,且 time travel 功能对 Milvus 的系统设计提出了较大挑战,先暂时废弃。
- 移出 CentOS7 支持
由于 centos 官方对 centos7 的支持即将到期,而且 centos8、centos9 仅有 stream 版本,官方并未提供正式的 docker 镜像,所以 Milvus 放弃对 centos 的支持,改为使用 Amazonlinux 发行版进行替代。此外,基于 ubuntu20.04 的镜像依旧是 Milvus 的主推版本。
- 删除了部分索引和 Metrics 支持
我们删除了包括 Annoy 索引和 RHNSW 索引,以及 binary 向量下的 Taninato、Superstructure 和 substructure 距离。
2.Knowhere核心组件再升级[深度解读],低延迟、高准确度
熟悉我们的朋友都知道,在 Milvus 和 Zilliz Cloud 中,有一个至关重要的组件——Knowhere。
Knowhere 是什么?如果把向量数据库整体看作漫威银河护卫队宇宙,那么 Knowhere 就是名副其实的总部,它的主要功能是对向量精确搜索其最近邻或通过构建索引进行低延迟、近似的最近邻搜索(ANNS)。
Knowhere 2.x 版本自 2022 年 7 月开始重构,经过多次方案讨论、设计、开发和测试的迭代,终于随着 Milvus 2.3 和各位见面了。对于用户而言,相较于 1.x 版本,Knowhere 2.x 版本提供了更规范的接口以及更丰富的功能,例如支持 GPU 索引、Cosine 相似性类型、ScaNN 索引和 ARM 架构等。对于开发者来说,升级后的 Knowhere 可以更方便地增加新的索引算法,利于后期维护。
接下来我将详细为大家介绍 Knowhere 2.x 的新功能、优化及设计理念。

2.1 支持 GPU 索引
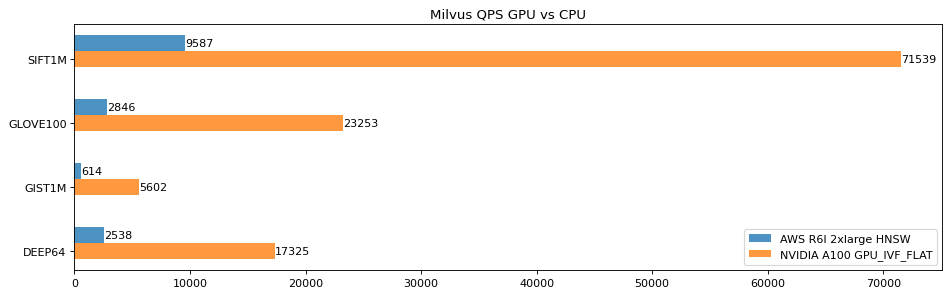
Zilliz 一直都非常欢迎外部开发者提出想法和贡献代码,此前,英伟达(Nvidia)公司在 Knowhere 2.x 版本贡献了其向量搜索库 RAFT 中的 GPU_FLAT 和 GPU_IVFPQ 索引。GPU 强劲的算力在一些场景下可以显著地加速索引搜索的过程。相较于 CPU 版本,Milvus 端到端性能在 Nvidia A100 上的吞吐量有了显著提升(SIFT1M 近 70 倍)。GPU 索引详细内容请访问 https://milvus.io/docs/install_standalone-gpu-docker.md。
2.2 支持 Cosine 相似性类型
在 Knowhere 1.x 版本上,如果想使用 Cosine 相似性类型,用户需要使用 Inner Product 相似性类型并在插入向量前进行归一化操作,使得其在数学上是等价的。这不仅对于用户有更高理论知识的要求,也增加了使用的成本和接入的难度。
Knowhere 2.x 版本原生支持 Cosine 距离并在库内部自动归一化传入向量并适配对应的索引类型,大大减少了理解成本,提升了用户体验。
2.3 支持 ScaNN 索引
Faiss 实现的 ScaNN,又名 FastScan,使用更小的 PQ 编码和相应的指令集可以更为友好地访问 CPU 寄存器,从而使其拥有优秀的索引性能。该索引在 Cohere 数据集,Recall 约 95% 的时候,Milvus 使用 Knowhere 2.x 版本端到端的 QPS 是 IVF_FLAT 的 7 倍,HNSW 的 1.2 倍。
2.4 支持 ARM 架构
ARM 架构对比 x86 架构,虽然其性能弱于后者,但因为更简单的设计和指令集,ARM 架构的能效和功耗更低,所以价格更为便宜。在 AWS 云平台相同 CPU 规格,如 1 vCPU,16GB 内存的情况下,ARM 实例比 x86 实例的价格低 15% 左右。Knowhere 2.x 版本支持了 ARM 架构,使得用户可以在此架构上运行和搭建上层服务。
2.5 支持 Range Search
最近邻问题包括 K 近邻问题 (KNN) 和范围搜索 (Range Search)。前者解决的问题是给定一个向量集合 X,参数 k 和查询向量 q,索引返回在向量集合 X 中由相似性类型定义的离查询向量 q 最 “近” 的 k 个向量。范围搜索则不给定参数 k,它需要给定一个范围 (radius),索引返回在向量集合 X 中与查询向量 q 的距离在范围内的所有向量。
Knowhere 2.x 为库中的多个索引提供了范围搜索的功能,例如 HNSW,DiskANN 还有 IVF 系列等。不同于 K 近邻问题,范围搜索返回向量的数目是预先不可知的。这对于结果的返回也提出了更高的要求,试考虑查询范围取查询向量 q 与向量集合 X 中最远向量的距离,结果将尝试返回整个向量集合。对此,Milvus 提供了对查询结果分页的功能,具体可参考 https://milvus.io/docs/within_range.md。
2.7 优化过滤查询
在向量查询中,可能存在有部分向量已经被删除的情况。或者在标量与向量的混合查询中,有一部分向量已经被标量查询先行过滤,例如数据库中有日期的标量列,并且用户只希望在满足特定日期的向量中进行查询。在大部分向量被过滤的场景下,Knowhere 2.x 针对 HNSW 的过滤向量查询进行了优化,使其相较于之前版本有至多 6 到 80 倍的性能提升。
2.8 优化代码结构和编译
Knowhere 2.x 版本简化了 C++ 类之间的继承关系,减少了函数调用;使用代理模式来规范新索引的接入,使得错误使用的风险更低;重构了 Config 模块,使用起来更为方便快捷;使用 conan 作为包管理工具,简化和加速了编译流程;使用 Folly 中的线程池来获得对于线程更为精准的把控。
2.9 支持 MMAP
MMAP (Memory Mapping) 将文件或设备映射到内存,即进程的地址空间。一些用户可能数据量较大但苦于没有足够的内存空间放置索引。用户之前可以尝试使用磁盘索引 DiskANN,现在也可以尝试使用 MMAP。用户选择开启后,Milvus 和 Knowhere 2.x 会自动将大文件进行内存映射,从而可以在内存不足的情况下使用大索引数据。
2.10 支持从索引获得原始向量
用户在搜索完成后,可能需要通过返回的 ID 取得原始向量,进一步进行定制化的计算或筛选。在之前版本的 Milvus 中,需要通过从例如 S3 或其他远程存储中获得。Knowhere 2.x 版本支持从索引中直接获得原始向量。因为索引本身已经被加载到内存(除 DiskANN 以外),该操作的延时会远低于从 S3 获取。值得注意的是并不是所有索引都支持,例如 IVFPQ 对原始向量进行了量化处理,从而丢失了这一信息。具体索引支持的表格详见 https://github.com/zilliztech/knowhere/releases/tag/v2.2.0。
3.Milvus MMap 一触开启
在 Milvus 2.3 中,Milvus 新增了 MMap 的功能,开启 MMap 后,可以保证相同规格的实例能够处理更大量的数据,同时对内存的大小要求会转移到磁盘上,从而大幅降低成本。
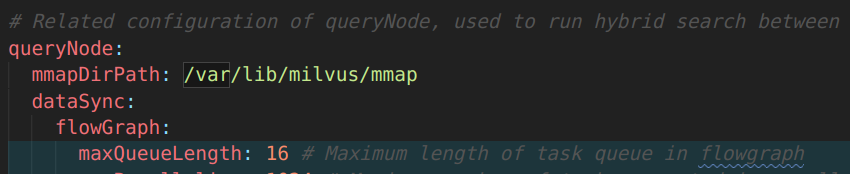
在 Milvus 2.3 中,可以通过修改 milvus.yaml 来启动 MMap 功能:在 queryNode配置项下新增 mmapDirPath 项,将其值设为任意合法路径即可:
接下来,让我们深入了解一下 MMap。
3.1 MMap简介
MMap(Memory-mapped files)是一种在操作系统中实现文件和内存之间映射的技术,通过 MMap 我们可以将一个文件的内容直接映射到进程的地址空间中,使得文件的内容在内存中可以被视为一段连续的内存区域,而不必进行显式的文件读取或写入操作。MMap 提供了一种高效、方便的文件访问方式,尤其在处理大型文件或需要随机访问文件内容的情况下非常有用。
一个简单的 C 语言例子如下:
void* map = mmap(NULL, size, PROT_READ, MAP_SHARED, fd, offset)
后续通过 map 指针读取数据时,会直接读取到 fd 所对应的文件的内容。如果读取的区域不在内存中,操作系统会将对应的 page 及相邻 page 缓存到 page cache 中,而不常访问的 page 可能会被换出。
在 Milvus 中开启 MMap 后,数据不会直接 load 到内存中,当发生查询时,数据会被动态地从磁盘加载到内存中,并且系统也会动态地将不常用的数据淘汰掉。由于 Milvus 查询集群中的数据都是 immutable 的,当数据被从内存中淘汰时,并不会发生写磁盘的操作。
3.2 性能,成本与系统的上限
由于需要存储向量数据,向量数据库对内存容量会有较高的要求。想要在有限的内存下处理更多数据,并且对性能不是非常敏感的用户就可以通过 MMap 功能实现。系统会根据负载和使用情况从内存中淘汰掉一些数据,从而可以在相同的内存容量下处理更多数据。
- 寻求空间与时间的平衡点
天下没有免费的午餐,而 MMap 的代价就是性能。根据我们的测试,在内存充足时,经过 warm up 后,数据都在内存中,此时系统的性能不会有明显的降级。而当数据量不断增加,性能则会随之逐渐下降。因此我们推荐只有那些对性能不敏感的用户去使用 MMap 功能。
如大家所知,数据的访问模式会极大地影响性能。Milvus 的 MMap 功能也尽量考虑了局部性对性能的影响。对于数据部分,通常是在过滤与读取时会被访问,并且都是顺序访问,因此标量数据会被直接按顺序写入到磁盘。对于变长类型,我们做了更多的优化,如下图所示,3 个字符串分别是:
- Vector
- Database
- Milvus
变长类型会经过扁平化,写入到连续的区域中,在内存中我们会维护一个 offsets 数组来索引数据。这样就能保证数据访问的局部性,同时也能消除单独存储每个变长数据的 overhead。
而对于向量索引,就需要更细致一些的优化了。以最常用的 HNSW 为例,HNSW 可以分为两个部分:
- 存储图中点之间连接关系的邻接表
- 原始向量数据
由于向量本身是比较大的,通常为连续的上百,或上千个 float32,因此访问单个向量本身就可以利用到局部性。而邻接表的访问模式在查询过程中则是较为随机的。向量数据通常会比邻接表要大得多,因此我们选择了只对向量数据做 MMap,而邻接表则保留在内存中,在节省大量内存的情况下保证性能不会下降太多。
- Zero Copy
为了让 MMap 能够提高系统处理数据量的上限,我们首先需要保证,在整个数据加载流程中内存用量峰值一定是远低于实际数据量的。而 Milvus 在之前的版本中,QueryNode 加载数据时会将数据全量读入,数据在整个过程中会被复制。在 MMap 功能的开发过程中,我们将这一过程改为了流式的,并去掉了很多不必要的复制,大幅降低了数据加载过程中的内存开销。
经过这些优化,MMap 才能真正提升系统的能力上限,经测试,在 Milvus 2.3 中开启 MMap 后, Milvus 可以处理约 2 倍左右的数据量。
目前 MMap 功能还处于 Beta 的状态,后续我们会对整个系统的内存使用做更多优化,来实现在单个节点上支撑更大的数据量。同时也会在使用方式上做出更多迭代,支持更细粒度的控制,支持动态的更改 collection,甚至 field 的加载模式。
4.Milvus GPU 版本使用指南
Milvus 2.3 正式支持 NVIDIA A100!
作为为数不多的支持 GPU 的向量数据库产品,Milvus 2.3 在吞吐量和低延迟方面都带来了显著的变化,尤其是与此前的 CPU 版本相比,不仅吞吐量提高了 10 倍,还能将延迟控制在极低的水准。
不过,正如我前面提到的,鲜有向量数据库支持 GPU,这其中除了有技术门槛较高的因素外,还涉及诸多不确定性的问题。那么,Milvus 为什么要做一件充满挑战的事情?
回想 Milvus 决定支持 GPU 的场景,很多细节仍旧历历在目。当时,随着 LLM 的兴起,用户对于向量数据库的性能提出了更高的要求,尤其是在一些对性能、延迟有着极高要求的场景,只通过 CPU 索引来支撑的难度越来越高,而 GPU 有着非常强大的并行处理能力。
因此,我们决定在 Milvus 2.3 版本中支持 GPU。幸运的是,**来自 NVIDIA 的小伙伴给予了我们诸多支持,他们主动给我们提供了 Rapid Raft GPU 索引接入 Milvus 的支持代码。**在 NVIDIA 和 Milvus 团队的共同努力下,Milvus GPU 版本如约而至。
接下来,我们就来看看如何使用 Milvus GPU 版本。
4.1 CUDA 驱动安装
首先,在我们的宿主机环境中,需要检查系统中是否已经正确的识别 NVIDIA 显卡,在命令行中输入:
在输出的设备中,看到 NVIDIA 字段,则说明该系统中已经安装了 NVIDIA 显卡。
00:00.0 Host bridge: Intel Corporation 440FX - 82441FX PMC [Natoma]
00:01.0 ISA bridge: Intel Corporation 82371SB PIIX3 ISA [Natoma/Triton II]
00:01.3 Non-VGA unclassified device: Intel Corporation 82371AB/EB/MB PIIX4 ACPI (rev 08)
00:03.0 VGA compatible controller: Amazon.com, Inc. Device 1111
00:04.0 Non-Volatile memory controller: Amazon.com, Inc. Device 8061
00:05.0 Ethernet controller: Amazon.com, Inc. Elastic Network Adapter (ENA)
00:1e.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)
00:1f.0 Non-Volatile memory controller: Amazon.com, Inc. NVMe SSD Controller
以上是我的环境中的输出,可以看到其中识别到一张 NVIDIA T4 显卡。
接下来,可以去 NVIDIA 官方网站,添加 repo installer。
https://developer.nvidia.com/cuda-downloads
以 ubuntu 20.04 为例:
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
这里需要注意,如果宿主机没有 cuda 的需要,可以不安装 cuda;如果是 server 版本的操作系统,可以安装 headless 版本驱动;如果是 desktop 版本的系统,可以安装普通版本。
- server
sudo apt install nvidia-headless-535
sudo apt install nvidia-utils-535
- desktop
sudo apt install nvidia-driver-535
sudo apt install nvidia-utils-535
安装完成之后,需要重启一下系统,使得驱动生效。重启完成,可以输入:
如果可以看到详细的显卡状态,即表示驱动安装 OK。
Milvus GPU 版本镜像使用 cuda 11.8 打包,如果是 NVIDIA Tesla 系列专业显卡,需要的最小驱动版本 >=450.80.02;如果是游戏显卡,需要驱动版本 >=520.61.05。
Milvus GPU 镜像支持 Compute Capability 为 6.1、7.0、7.5、8.0 的 NVIDIA 显卡,查看显卡型号对应的 Compute Capability,请参阅 https://developer.nvidia.com/cuda-gpus。NVIDIA Container Toolkit 安装则参考 https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
4.2 Milvus GPU 可配环境变量
Milvus GPU 版本目前仅支持单个 Milvus 进程单个显卡,Milvus GPU 版本默认使用 device 0 显卡。如果需要使用多卡,可以通过启动多个 Milvus 进程或者容器,然后配合 CUDA_VISIBLE_DEVICES 环境变量来实现多卡部署。
容器环境下,可以通过 -e 来设置该环境变量:
sudo docker run --rm -e NVIDIA_VISIBLE_DEVICES=3 milvusdb/milvus:v2.3.0-gpu-beta
在 docker-compose 环境中,可以通过 device_ids 字段来设置,参考 https://docs.docker.com/compose/gpu-support/
注意,为单个 Milvus 进程或者单个容器配置了多张卡可见,Milvus 也只能使用其中的一张卡。
KNOWHERE_STREAMS_PER_GPU 环境变量可以用来设置 cuda stream 的并发数。适当的调大此参数,有可能获得更好的性能,但是,也会带来更多的显存开销。
KNOWHERE_GPU_MEM_POOL_SIZE 环境变量可以用来设置显存池大小。如果不设置改环境变量,Milvus 会自动分配当前 GPU 的一半内存作为显存池,如果在服务的过程中,出现显存池容量不足,那么 Milvus 会自动尝试再次增加显存池大小,默认上限是整个显存大小。
export KNOWHERE_GPU_MEM_POOL_SIZE=2048;4096
以上设置显存池初始大小为 2048 MB,最大显存池大小为 4096 MB。
如果在一张卡上部署 2 个 Milvus 进程,那么,此环境变量一定需要合理的分配,否则 Milvus 会出现显存竞争崩溃的情况。
03.
Milvus GPU 编译
本地编译 Milvus GPU 版本需要依赖英伟达提供的 cuda-toolkit,在安装 cuda-toolkit 请先完成 NVIDIA 驱动的安装:
sudo apt install --no-install-recommends cuda-toolkit
本地编译 Milvus GPU 之前,我们需要先安装部分依赖软件以及工具:
sudo apt install python3-pip libopenblas-dev libtbb-dev pkg-config
安装 conan:
pip3 install conan==1.59.0 --user
expoprt PATH=$PATH:~/.local/bin
安装较新版本的 cmake>=3.23,参考 https://apt.kitware.com。golang 的安装可以参考 https://go.dev/doc/install。
启动 milvus standalone 模式:
cd bin
sudo ./milvus run standalone
在配置好 nvidia-docker 或者 docker 替代品的情况下,可以很方便地使用 Milvus 提供的 docker-compose.yml 文件来完成容器化部署。
用户可以从 milvus repo 中获取 docker-compose.yml 文件,地址 https://github.com/milvus-io/milvus/blob/master/deployments/docker/gpu/standalone/docker-compose.yml
至此,便可完成 standalone 模式的 Milvus 部署。
如果用户宿主机有多张显卡,可以通过修改 docker-compose.yml 中的 device_ids 字段来修改映射到 Milvus 的显卡。
*更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

- 点赞
- 收藏
- 关注作者
评论(0)