使用Filebeat和Logstash发送日志到Elasticsearch

如果你刚刚开始使用Elastic Stack,并且想知道Elastic架构是如何工作的,以及数据是如何在它们之间流动的,那么不要担心,我将详细解释数据流是如何工作的。
您必须已经配置了您的ELK实验室,也许您还配置了一些舰队服务器和策略,并且可能还配置了一些节拍。但是,您一定想知道日志是如何在它们之间流动的,或者整个日志解析体系结构是如何工作的。
为了理解它是如何工作的,首先让我们了解什么是Logstash Pipeline以及它是如何工作的。
Logstash Pipeline
Logstash是位于客户端(代理/配置了Beats的位置)和服务器(Elastic Stack/配置了Beats以发送日志的位置)之间的中间人。简而言之,Logstash被配置为接收通过代理/客户端发送的日志,并将其转发到Elasticsearch。这意味着Logstash负责数据收集(输入)、过滤(过滤器)和转发(输出)。整个过程称为管道(pipeline)。
优化:
Logstash是位于客户端(代理/配置了Beats的位置)和服务器(Elastic Stack/配置了Beats以发送日志的位置)之间的中间层。Logstash的主要作用是接收通过代理/客户端发送的日志,并将其转发到Elasticsearch进行存储和处理。它负责数据的收集(输入)、过滤(过滤器)和转发(输出)。这个完整的过程被称为管道(pipeline)。
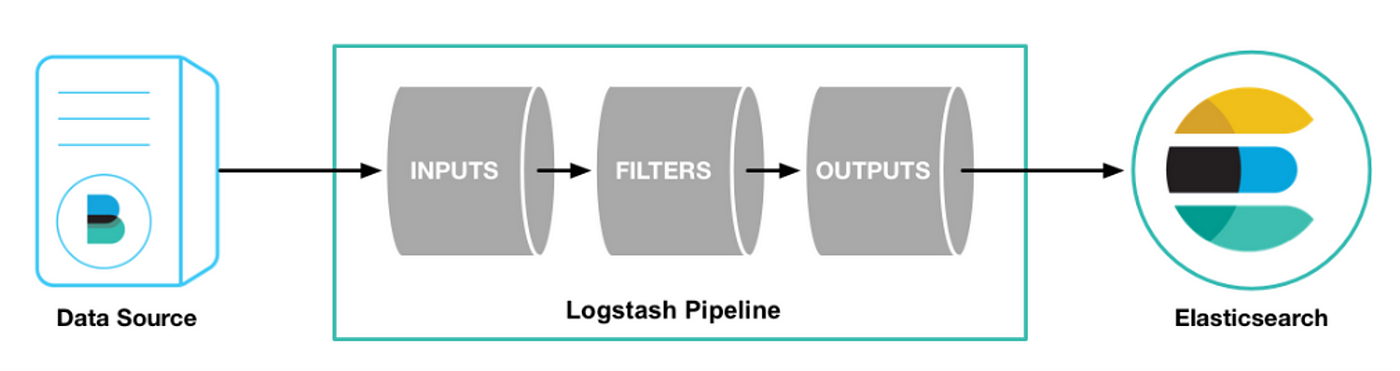
管道(pipeline)是我们在ELK堆栈中需要理解的最重要的概念。管道的每个组件(输入、过滤器、输出)可以通过使用插件来实现。一些常用的插件有:
输入(Input):
File:可以直接通过文件读取日志
Beats:可以通过beats(如Filebeat、Metricbeat等)发送的事件处理日志
过滤器(Filter):
Grok:将信息从一种格式修改为另一种格式,特别是JSON格式
Mutate:修改事件字段,如重命名/删除/替换/修改等
Drop:丢弃一个事件
输出(Output):
Elasticsearch:可以将事件数据发送到Elasticsearch集群
File:可以将事件数据写入文件
注意:
可以定义多个管道(pipeline)
可以在同一个管道内定义多个输入源、过滤器和输出目标
现在,我们已经了解了一些基础知识,让我们继续设置我们的Filebeat和Logstash。我将在Debian Linux虚拟机上配置Filebeat。首先,我们需要在系统上安装Filebeat。如果您按照Elastic官方文档进行操作,应该不会有问题。您可以在您喜欢的系统上安装Filebeat。
由于我们想要将日志发送到Logstash,我们需要一些日志。您可以使用系统的默认日志,但在本示例中,我已经安装了NGINX,并将NGINX日志发送到Logstash。如果您愿意,您可以选择不同的服务。我已经配置了NGINX,并且它正在运行,日志生成到默认位置/var/logs/nginx。
我们的NGINX已经准备好并接收日志,让我们继续配置Filebeat将这些日志发送到Logstash。我已经在我的Debian虚拟机上设置了一个客户端来监控日志。在您系统上安装了Filebeat之后,
导航到/etc/filebeat/并配置filebeat.yml文件。进行以下更改:
优化:
我们的NGINX已经准备就绪并正在接收日志,现在我们可以继续配置Filebeat将这些日志发送到Logstash。我已经在我的Debian虚拟机上设置了一个用于监控日志的客户端。在您安装了Filebeat之后,
请导航到/etc/filebeat/并配置filebeat.yml文件。进行以下更改:
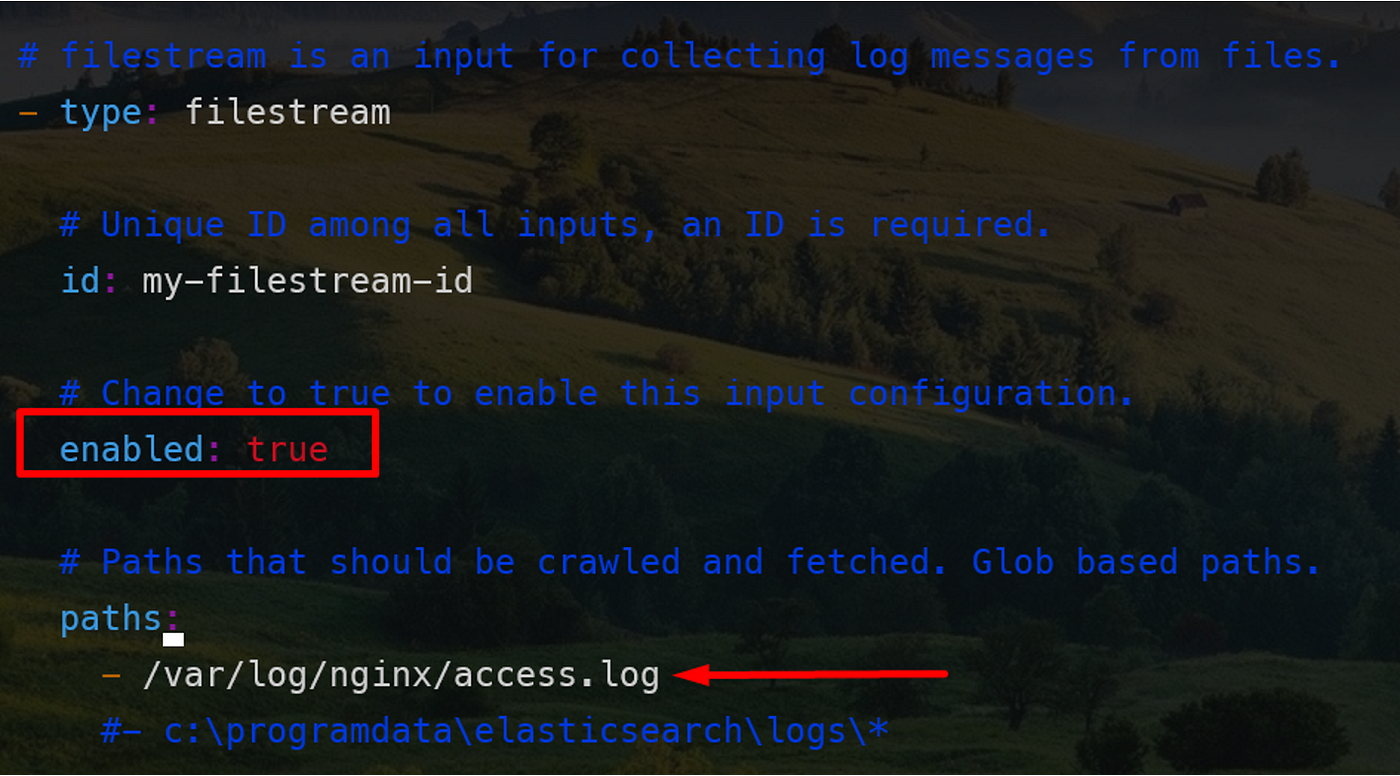
将enabled设置为true,并提供要发送到Logstash的日志的路径。将输出部分注释为elasticsearch,取消对Logstash输出部分的注释,并将Logstash的IP地址和默认端口设置为5044。

您现在已经成功地配置了filebeat,以便将日志发送到Logstash。现在,让我们启动filebeat。
执行命令systemctl start filebeat
你可能也想启用,这样你就不必每次登录时都启动它。
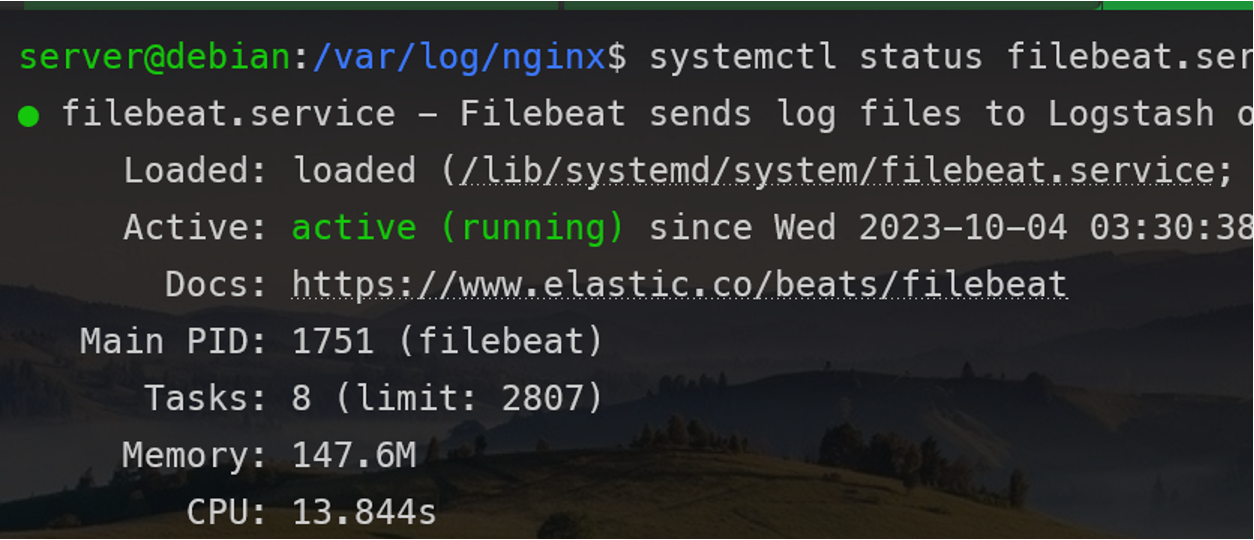
它已经开始运行了。
现在是配置Logstash的时候了。
导航到/etc/logstash/conf。创建一个名为nginx.conf的配置文件,或者根据自己的喜好命名。还记得我谈论Logstash管道的时候吗?
这是配置文件的基本格式。我们可以定义单个或多个输入源,也可以从文件中读取或直接访问日志。我建议您阅读此文档以了解更多细节:
https://elastic-stack.readthedocs.io/en/latest/pipelines.html#pipeline-configuration
这很有帮助。
我已将Logstash配置为监听端口5044,并通过节拍接收输入。
input {
beats {
port => 5044
}
}在过滤器中,您可以在第一次尝试时保留它,但您必须在将其发送到elasticsearch之前对其进行解析,以便Ksibana可以利用它进行有意义的可视化。当我使用nginx日志时,我有以下grok表达式;
filter {
grok {
# Match nginx headers
match => {
"message" => '%{IP:client_ip} - - \[%{HTTPDATE:access_time}\] "%{WORD:http_method} %{URIPATH:request_page} HTTP/%{NUMBER:http_version}" %{NUMBER:response_code} %{NUMBER:response_size} "-" "%{GREEDYDATA:user_agent}"'
}
}
}您可以使用Kibana的Dev工具来验证您的grok模式是否正常工作。你可以在管理栏下找到它。
如果您想了解更多关于grok的信息,我建议您阅读以下文档:https://logz.io/blog/logstash-grok/
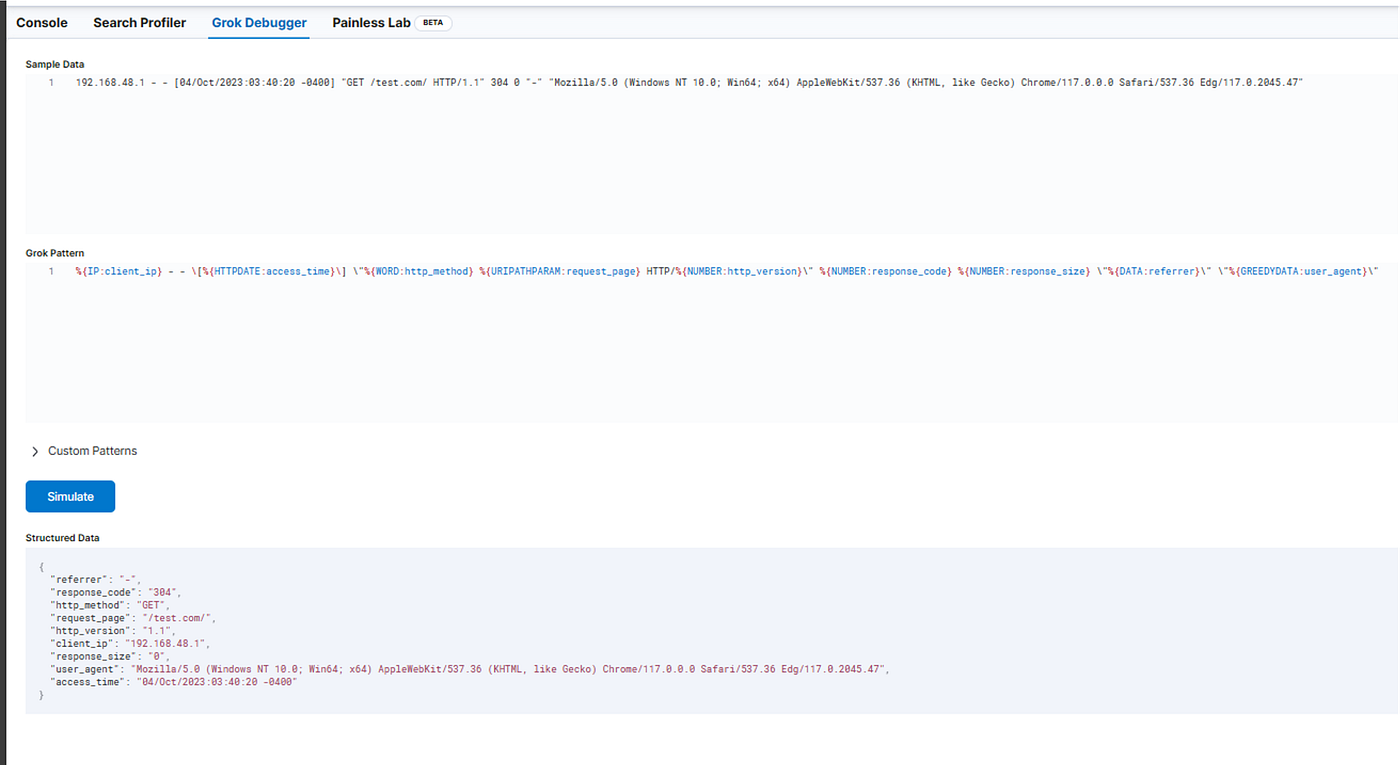
我已经验证了我的模式,它工作正常。
注意:模式可能会有所不同,对于相同的服务,相同的模式可能无法正常工作。因此,您必须考虑根据日志编写自己的模式。
我们配置的最后一部分是输出部分。我们必须提供主机的IP、索引名、弹性用户和密码,您可能还需要设置两个属性ssl和ssl_certificate_verification。这也可以为您节省很多时间,因为我已经花费了几个小时试图解决与SSL证书相关的错误。
output {
elasticsearch {
hosts => ["https://192.168.48.134:9200"]
index => "filebeat-test-%{+YYYY.MM.dd}"
user => "elastic"
password => "changeme"
#cacert => ""
ssl => true
ssl_certificate_verification => false
}
}如果您已经配置好了,那么就可以开始了,保存您的配置并启动您的Logstash。
您可能希望检查日志,看看发生了什么。tail -f /var/logstash/logsatsh-plain.log

如果您看到这种情况,那么您的Logstash配置没有任何错误,但是,如果您注意到任何错误,那么您必须尝试解决导致错误的问题。在进入Kibana仪表板之前,最好检查一下Elasticsearch日志,看看是否工作正常,并且正在通过Logstash接收日志。
它很好,正在接收日志。现在,我们去看看基巴纳的仪表盘。
登录Kibana后,首先要检查的是堆栈管理下的索引模式。
您还将看到类似的索引,记住我们已经将索引命名为filebeat-test-%{+YYYY.MM。Dd},这就是。
在成功加载索引之后,您必须添加Data视图,如果向下滚动,您可以在Kibana下方找到它。点击数据视图,你会看到如下提示:

为数据视图命名并选择索引模式,您可能希望将其命名为filebeat*,因为您希望索引为filebeat,尽管它是在何时创建的,如果您选择filebat-test-2023.10.03*,则只会加载一个索引,并且不会获取实时数据,因为新索引将在不同的数据下。所以,你必须避免这种情况。
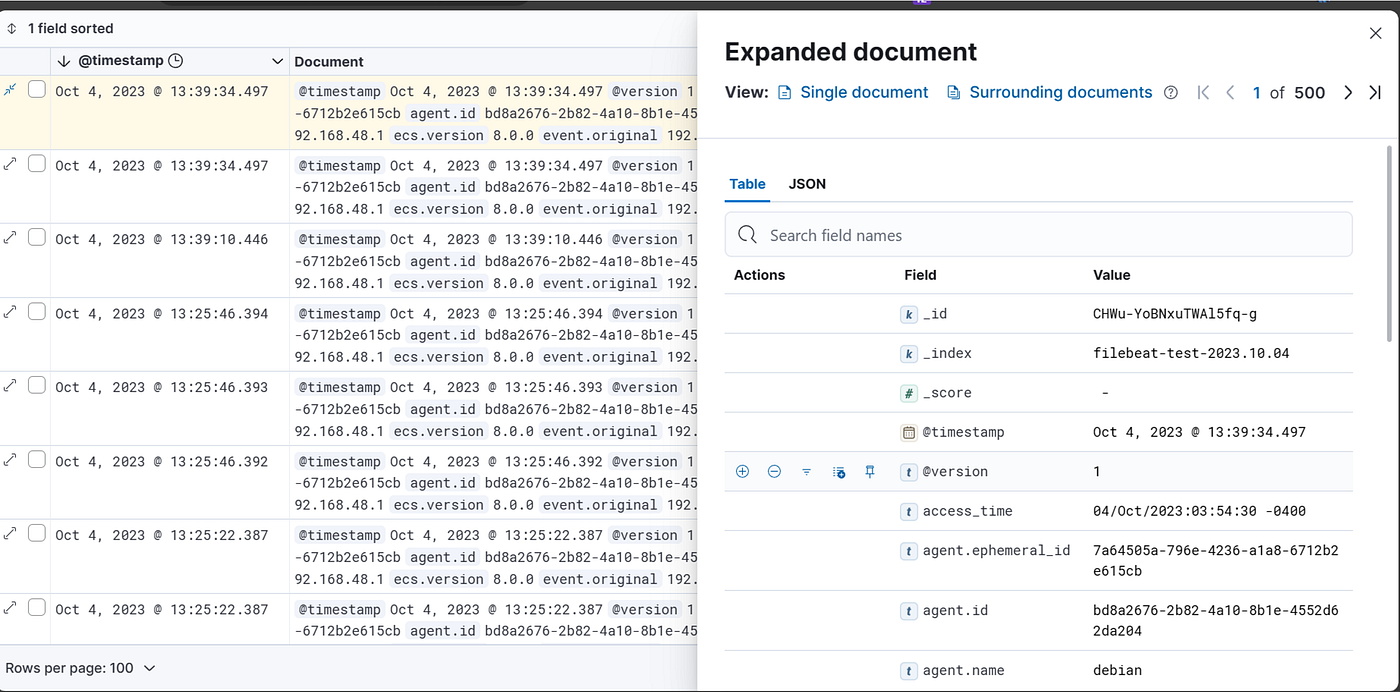
成功创建数据视图后,前往Analytics下的Discover
我已经选择了我的数据视图,你可以从左上角选择它。您可以从右上角选择日志的时间,如果您想查看更多关于日志的信息,则可以展开日志以查看更详细的信息。

- 点赞
- 收藏
- 关注作者
评论(0)