昇腾CANN 7.0 黑科技:大模型推理部署技术解密

【摘要】 近期,随着生成式AI大模型进入公众视野,越来越多的人意识到抓住AI的爆发就是抓住未来智能化变革的契机。AI基础设施如何快速部署使用,以及如何提升推理性能,逐渐成为众多企业关注的焦点。CANN作为最接近昇腾AI系列硬件产品的一层,通过软硬件联合设计,打造出适合昇腾AI处理器的软件架构,充分使能和释放昇腾硬件的澎湃算力。针对大模型推理场景,CANN最新发布的CANN 7.0版本有机整合各内部组件...
近期,随着生成式AI大模型进入公众视野,越来越多的人意识到抓住AI的爆发就是抓住未来智能化变革的契机。AI基础设施如何快速部署使用,以及如何提升推理性能,逐渐成为众多企业关注的焦点。
CANN作为最接近昇腾AI系列硬件产品的一层,通过软硬件联合设计,打造出适合昇腾AI处理器的软件架构,充分使能和释放昇腾硬件的澎湃算力。针对大模型推理场景,CANN最新发布的CANN 7.0版本有机整合各内部组件,支持大模型的量化压缩、分布式切分编译、分布式加载部署,并在基础加速库、图编译优化、模型执行调度等方面针对大模型进行极致性能优化。
自动并行切分实现大模型分布式部署:
针对LLM模型巨大的计算和内存开销,CANN提供自动并行切分能力,实现大模型在昇腾集群的分布式部署。自动并行切分过程可以分为5个步骤:
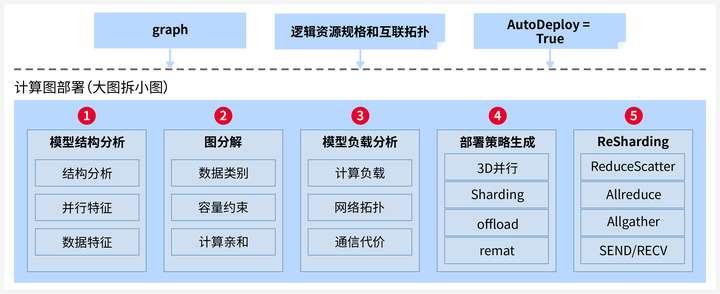
自动切分的策略以物理集群信息和模型结构为输入,进行负载切分优化的空间建模,通过策略生成-策略应用-性能模拟的多轮迭代,进而搜索得到优化的切分部署策略。
KV Cache机制减少重复推理计算:
LLM模型推理计算的过程可以分为prompt处理和后续输出token的自回归计
算。前者有大量数据的矩阵乘,是典型的计算密集型处理,而后者随着LLM的执行,会积累越来越多的对话内容,基于历史输出计算得到新的token输出。以“盘古是一个语言模型”为例,输入内容后,每一个token都会生成对应的Q、K和V向量,在attention部分进行矩阵乘和softmax等计算。在这个过程中,用户prompt加上已经输出的token都要作为下一次迭代的输入,都要重新计算相应的QKV,这造成了大量的重复计算。
为此,业界提出了KV Cache方法,将已经出现的token所计算得出的K和V向量保存在内存,仅计算最新一个token的QKV,再进行矩阵乘和softmax计算,本质上是以空间换时间。
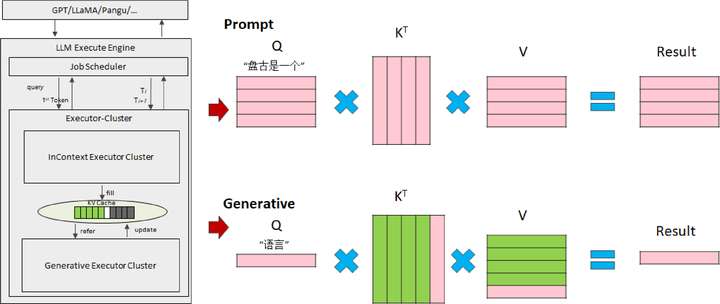
目前,CANN已经全面支持KV Cache,并实现了KV Cache的分布式存储、更新和复位,有效加速自回归阶段计算。
量化技术有效降低内存占用:
量化是AI领域的常见技术,在大模型时代,量化还有不同的特点和要求。LLM的权重分布相对均匀,而FM数据存在很多离群点。传统量化算法中,直接抛弃离群点或将所有离群点纳入量化范围,均会导致精度损失,为此CANN支持仅Weight量化,INT8量化场景相比FP16可降低50%权重内存空间占用。
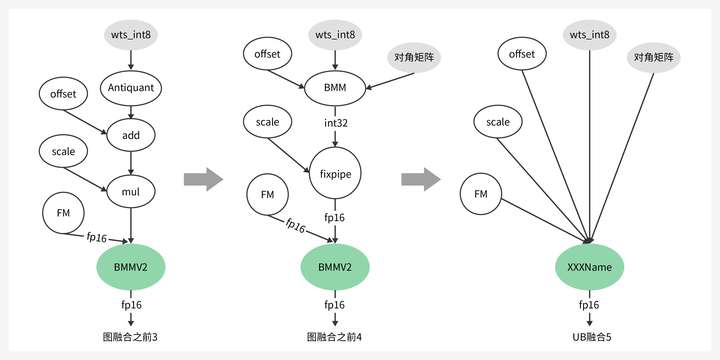
同时支持KV Cache量化,KV Cache本质上是空间换时间,随模型层数、sequence length的线性增长,KV Cache量化可降低一半存储。
FlashAttention融合算子降低访存开销:
LLM模型中大量使用了Multi-Head Atten-tion结构,这不仅带来了巨大的计算量,保存数据所需的内存容量也是计算系统的关键瓶颈。对此,业界提出了FlashAttention融合算子,其原理是对attention处理过程进行切分和计算等价,使得attention的多个步骤可以在一个算子中完成,并且通过多重循环、每次处理一小部分数据,以近似流式的方式访问HBM,减少了HBM访问的总数据量,并能够将计算和数据搬运更好的重叠隐藏。
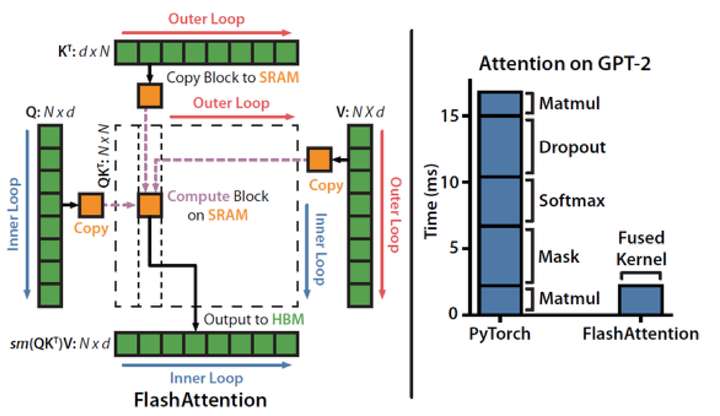
来源:https://arxiv.org/pdf/2205.14135.pdf
CANN针对昇腾AI处理器的HBM和缓存大小,以及数据搬运通路,优化实现FlashAttention融合算子,充分利用片上缓存,提升Attention处理性能可达50%。
Auto Batching调度提升算力利用率:
面对input阶段compute-bound、output阶段memory-bound的计算特征,以及LLM业务的时延需求,CANN支持多个input和output计算集群的异构部署,并支持LLM计算任务的auto batching调度,提升AI算力利用率。它的原理是将不同的服务请求尽可能地聚合处理:在input阶段通过单batch和预置的多种sequence length模型推理,尽量降低每个请求的启动开销;在output阶段以iteration粒度调度多个服务,尽可能拼成batch处理,以提升计算密度,平衡计算和访存。
支持Torch.Compile计算图提高编程效率:
为了使开发者能够更简单的将LLM在昇腾平台运行推理,CANN实现了PyTorch的计算图支持。开发者只需要使用PyTorch原生的torch.-compile接口,CANN使能的NPU后端就会对PyTorch生成的FX Graph进行接管,基于trace逻辑将AtenIR转换为AIR,再进行端到端的图编译深度优化,从而降低推理阶段的内存需求、提升计算性能,同时最大程度的减少开发者的修改工作。
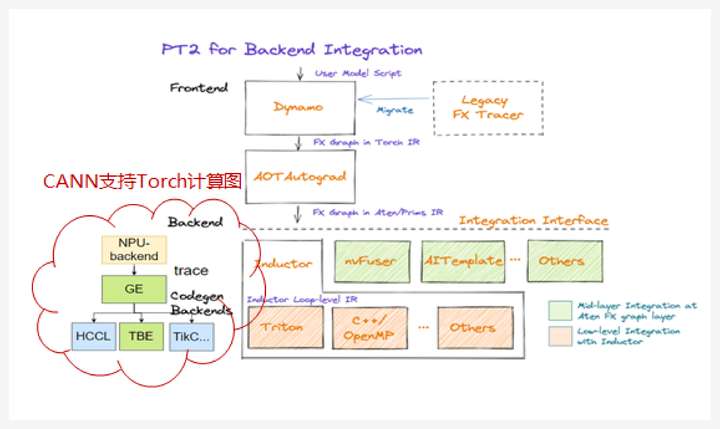
来源:https://pytorch.org/get-started/pytorch-2.0/
这里有一个CANN大模型推理上手的示例。在编译阶段使用ATC工具对pb或onnx模型进行编译,命令参数与CV等经典AI模型类似,只是增加了集群信息和切分信息的输入。打开集群开关以及并行切分开关,同时传入集群配置文件和切分方式的配置文件,ATC就会在编译过程中自动实现模型的切分和通信算子插入。
atc --model=./matmul2.pb
--soc_version=Ascend910
--output=test910_parallel
--distributed_cluster_build=1
--cluster_config=./numa_config_910_2p.json
--enable_graph_parallel="1"
--graph_parallel_option_path=./parallel_option.json
在执行阶段,通过LoadGraph接口载入om离线模型,CANN会将各个模型切片载入到相应的昇腾AI处理器device上,然后再使用既有的RunGraph接口即可执行推理。
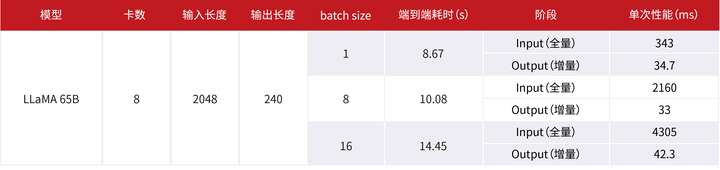
经过计算/通信并行、图优化、算子调优等优化,LLAMA 65B推理性能可较优化前提升一倍以上,端到端耗时可以达到8s左右,仍有提升空间。
总而言之,在大模型技术日新月异不断迭代的时代背景下,昇腾CANN将会持续深耕大模型优化&加速技术,比如继续探索面向在线服务的调度优化,缩短服务时延;基于计算图的weight预取与Cache驻留优化,提升访存性能;亲和FlashAttention业界最新融合算子,提升计算性能;支持更丰富的量化计算组合、模型稀疏,降低内存占用...随着大模型规模化商业落地,以昇腾CANN为核心的昇腾AI基础软硬件平台,将持续提升大模型推理部署场景的核心竞争力,为客户提供最优选择!

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)