探索未来的视觉革命:卷积神经网络的崭新时代(二)

🍋引言
本节介绍一下GoogleNet,首先说一下它的背景历史,GoogleNet是由Google研究员Christian Szegedy等人于2014年提出的深度卷积神经网络架构。它在当时的ImageNet图像分类挑战赛中取得了惊人的成绩,将错误率大幅度降低,标志着深度学习领域的一次巨大突破。
🍋GoogleNet的架构
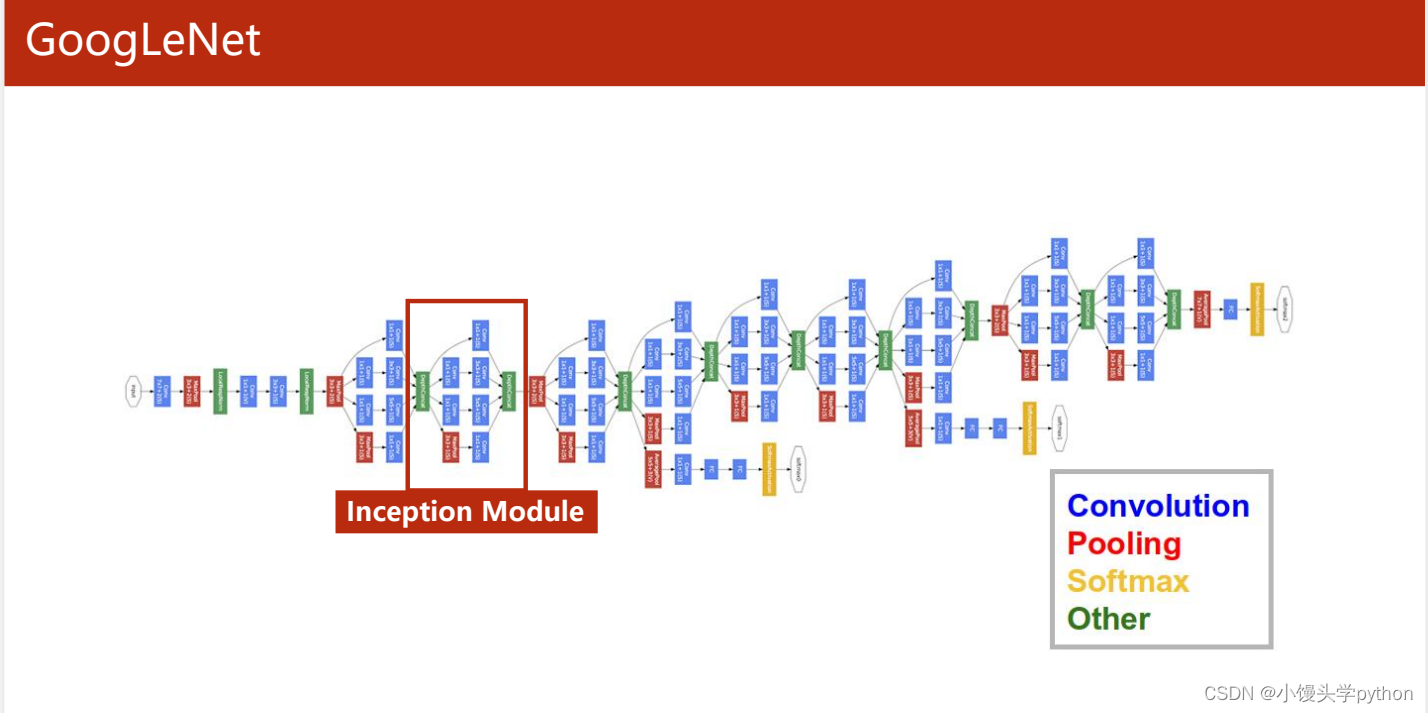
GoogleNet之所以引人注目,是因为它采用了一种全新的架构,即Inception架构。这个架构采用了多尺度卷积核,允许网络同时学习不同尺度的特征。这里解释一下就是类似于多条路一起跑,看看哪个好Inception模块将不同大小的卷积核组合在一起,从而有效捕获图像中的各种特征,无论是边缘、纹理还是高级抽象的特征。
GoogleNet的架构包括多个Inception模块,这些模块由卷积层、池化层、全连接层和辅助分类器组成。此外,GoogleNet采用了1x1卷积核来减少模型的参数数量,从而减小了计算复杂度。上图的图例可以看到一些简单的标识,以及在网络中的分布
刘二二人这里提到了一点,观察网络的共同点,发现有一部分出现的频率很大,如下图红框中所示
🍋1×1 convolution
这解释1×1的卷积前,我们先来看看Inception模型图示,不难发现,每条路都有一个共同的点那就是都经过了1×1的卷积。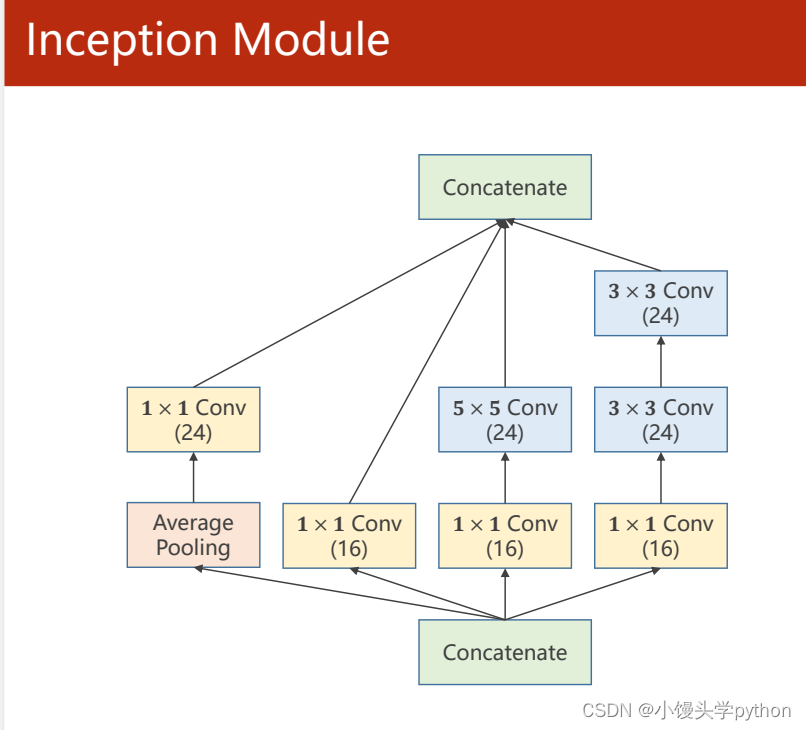
那么1×1的卷积究竟有什么魔力呢?我们先从下方的图示了解一下运算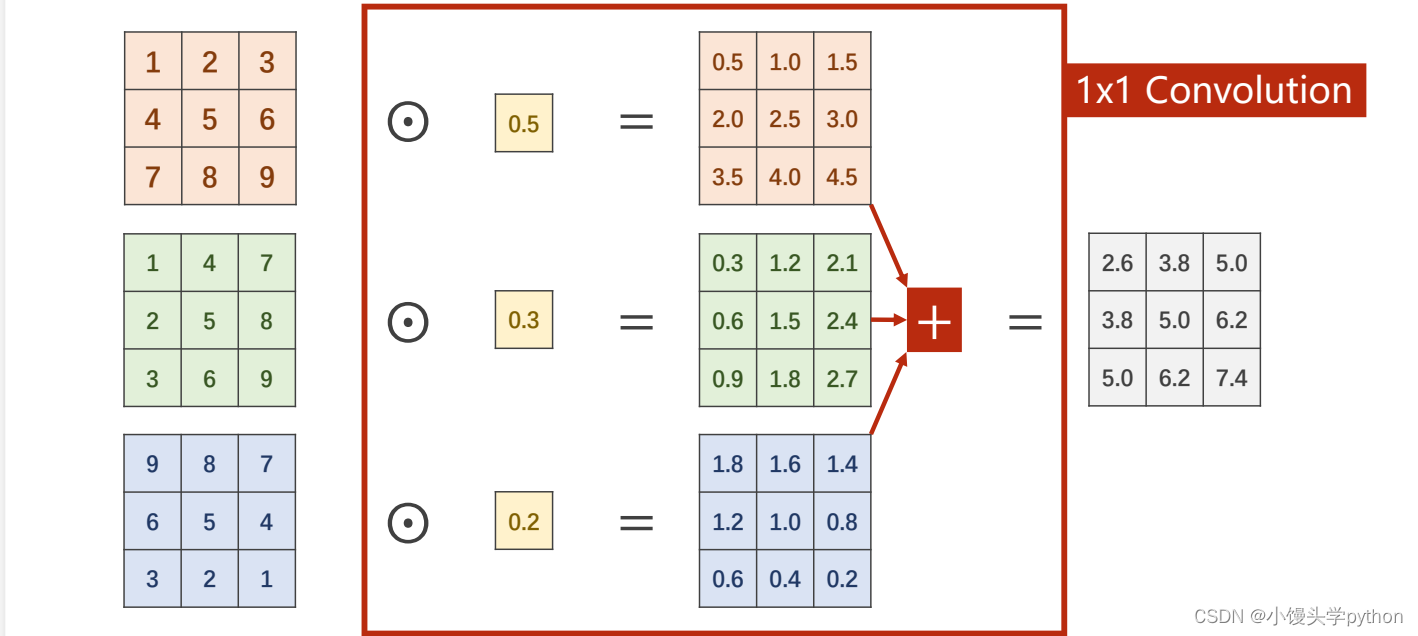
其实就是每个相乘再相加,接下来我们通过一组数据进行对比一下,1×1卷积的作用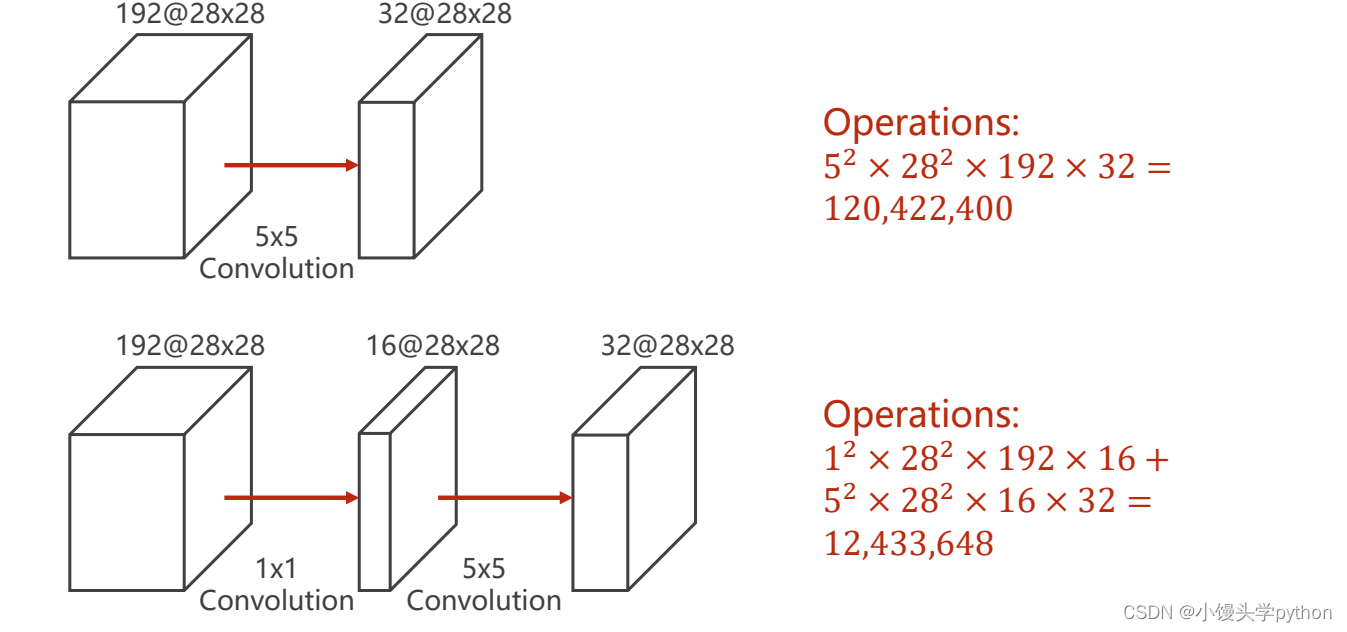
同样都是从192 Channel到32 Channel,前者使用了一个5×5的卷积,后者在5×5的卷积前加了一个1×1的卷积,运算值居然是原来的十分之一,那么从这里我们就清楚了它的主要功能。
通道降维(channel dimension reduction):通过应用 1×1 卷积,可以减小特征图的通道数量,从而降低模型的计算负担。这对于减小模型的参数数量和计算复杂度很有帮助。通道降维有时也称为特征压缩。
通道混合(channel mixing):1×1 卷积可以将不同通道之间的信息进行混合。它通过学习权重来组合输入通道的信息,以产生更丰富的特征表示。这有助于模型更好地捕获特征之间的关联。
非线性变换:虽然 1×1 卷积核的大小为 1x1,但通常会包括非线性激活函数,如ReLU(Rectified Linear Unit)。这使得 1×1 卷积可以执行非线性变换,有助于模型更好地捕获复杂的模式。
如果使用代码进行每条路的编写可以参考下图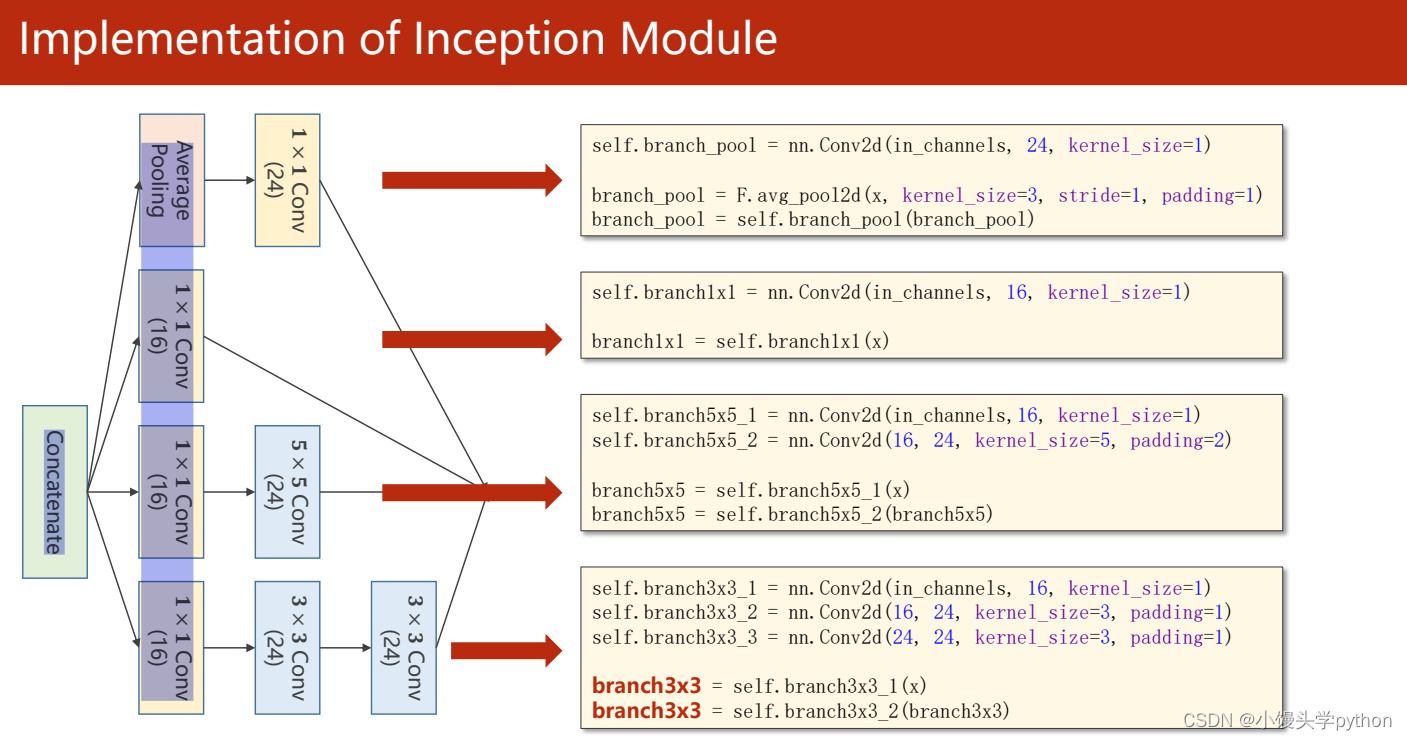
最后一个老师说空间不足,这里需要补充一句
branch3×3 = self.branch3×3_3(branch3×3)
之后需要将它们使用cat拼接起来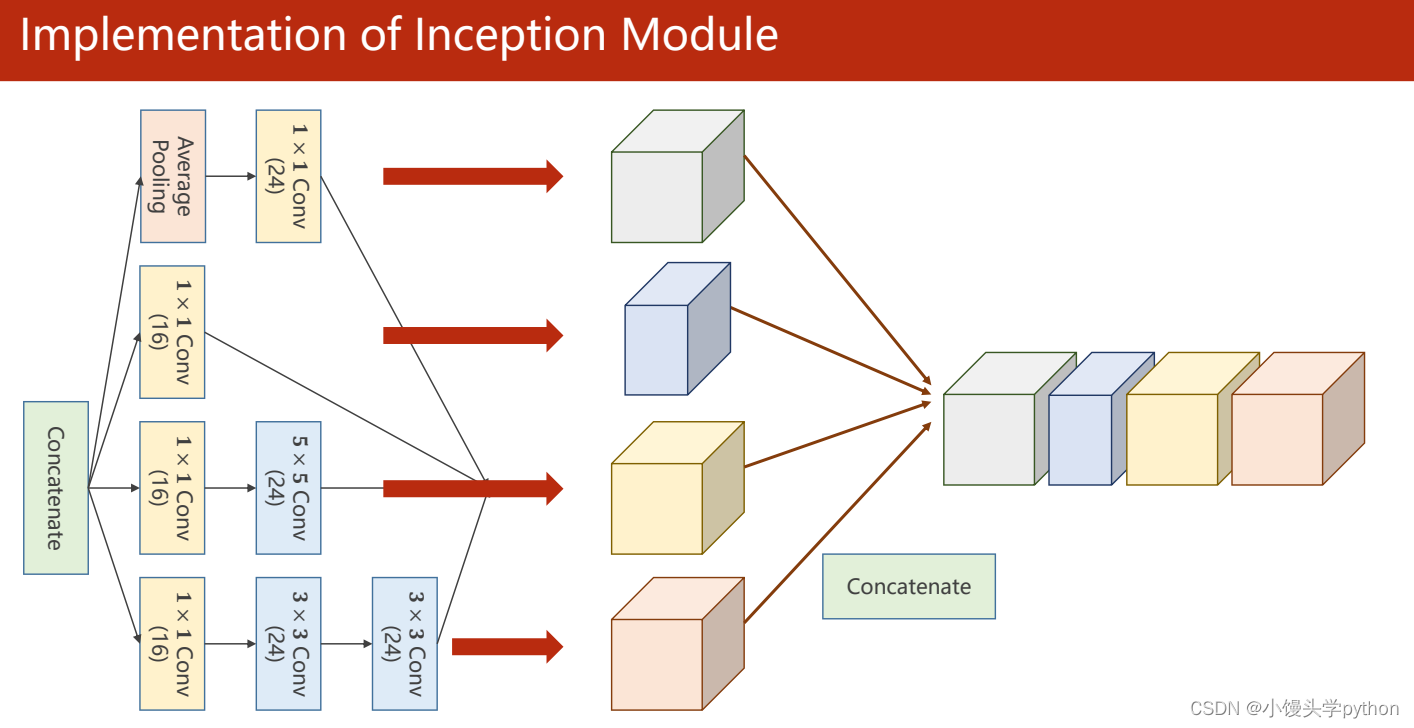
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)
这里说明一下拼接的作用,Inception模块中的拼接操作的主要作用是将不同尺度和类型的特征融合在一起,以丰富特征表示并提高网络性能。这是GoogleNet取得成功的一个关键因素,使其在图像分类等任务中表现出色。
完整的代码如下:
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels,16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)

之后我们需要定义网络层
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
🍋如何有效避免梯度消失?
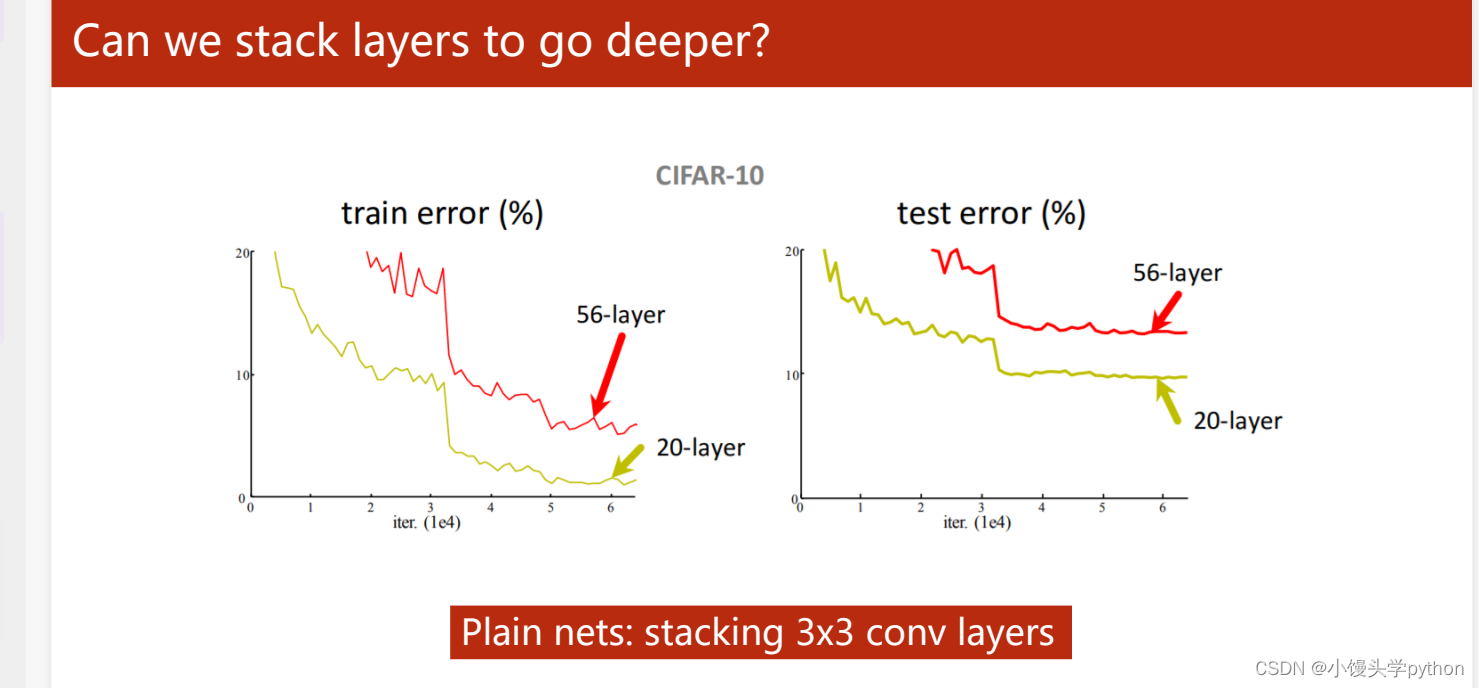
这里我们引入Residual net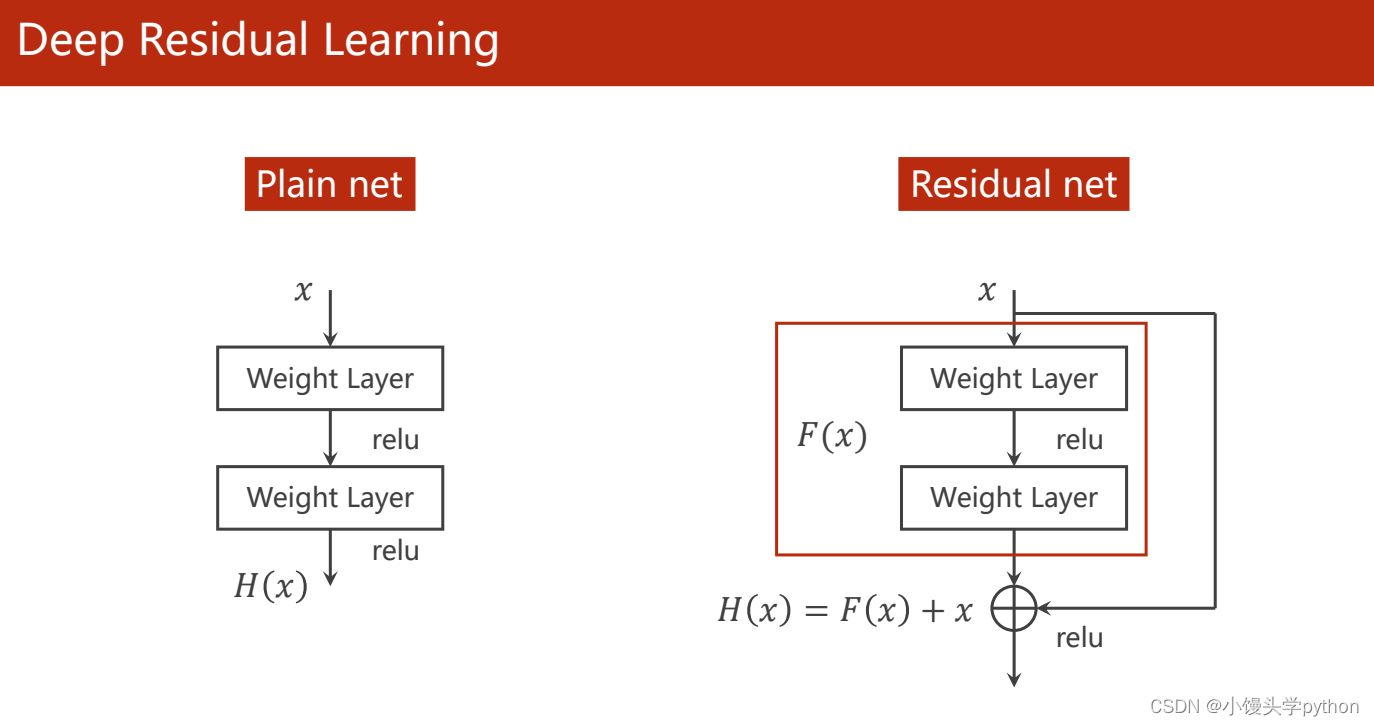
完整的结构与代码如下
🍋总结
GoogleNet是深度学习领域的一项重要成就,它的Inception架构为图像分类和计算机视觉任务提供了高效的解决方案。在Python中,我们可以轻松使用深度学习框架来构建和应用GoogleNet模型。同时文本还介绍了一种避免梯度消失的方法。
视频结尾老师讲述了一些学习方法,主要有四点如下
- 理论《深度学习》
- 阅读pytorch文档(通读一遍)
- 复现经典论文(代码下载,读代码,写代码)
- 扩充视野
本文根据b站刘二大人《PyTorch深度学习实践》完结合集学习后加以整理,文中图文均不属于个人。

挑战与创造都是很痛苦的,但是很充实。

- 点赞
- 收藏
- 关注作者
评论(0)