探索未来的视觉革命:卷积神经网络的崭新时代(一)

🍋引言
当谈到深度学习和计算机视觉时,卷积神经网络(Convolutional Neural Networks,CNNs)一直是热门话题。CNNs是一类专门设计用于处理图像数据的深度学习神经网络,已经在许多领域取得了重大成功,如图像分类、目标检测、人脸识别和自动驾驶。本文将探讨卷积神经网络的基本原理、应用领域以及一些最新趋势。
🍋卷积神经网络的基本原理
卷积层(Convolutional Layer):卷积层是CNN的核心组件,用于提取图像的特征。它通过在输入图像上滑动卷积核,对每个位置进行卷积运算,从而生成特征图。这些特征图捕获了不同位置的局部特征。
池化层(Pooling Layer):池化层用于减小特征图的尺寸,减少计算负担,同时保留最重要的信息。常见的池化操作包括最大池化和平均池化。
全连接层(Fully Connected Layer):全连接层将卷积层和池化层的输出连接在一起,用于执行最终的分类或回归任务。这一层通常包括多个神经元,每个神经元对应一个类别或回归目标。
激活函数(Activation Function):在卷积层和全连接层之间,通常会应用非线性激活函数,如ReLU(Rectified Linear Unit),以引入非线性特性,增强网络的表达能力。
🍋全连接网络 VS 卷积神经网络
在开始学习卷积神经网络前,我们先来回顾一下全连接网络,正如名字,全连接代表了每一层的属于都对后面的输出有影响,当然它们之间是相互影响关联的,下图可以看出,后面会展示卷积神经网络可以拿来对比一下。
它们之间的差异主要体现在结构性的差异上
- 全连接网络:在全连接网络中,每个神经元与前一层中的每个神经元相连接。这意味着每个神经元都受到前一层中所有神经元的影响,导致参数数量迅速增加。
- 卷积神经网络(CNN):CNN使用卷积层,其中神经元仅与输入数据的局部区域相连接,而不是与整个输入相连接。这减少了参数数量,使CNN在处理图像等大型数据时更加高效。
🍋卷积神经网络
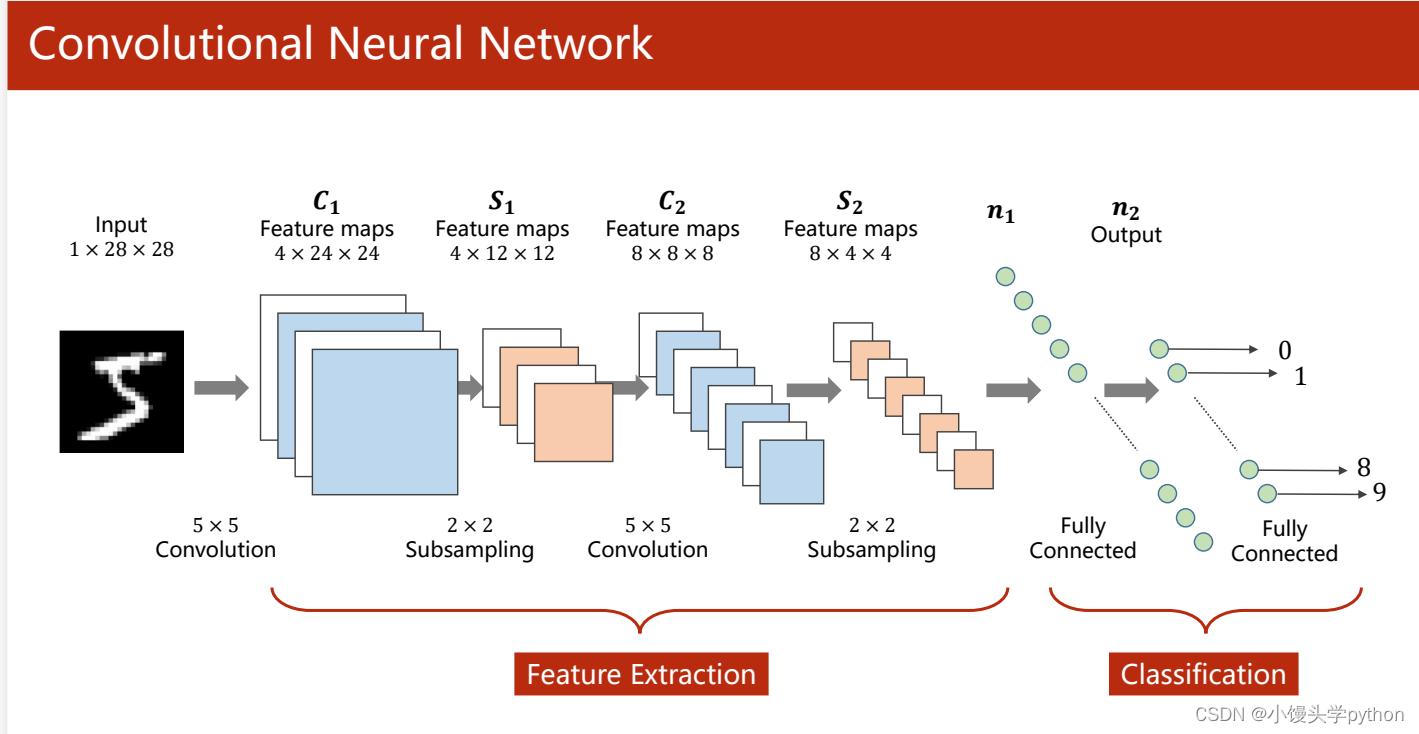
下图清楚的展示了一个卷积网络,大概的流程是
- input的1×28×28经过卷积层5×5的卷积
- 变为4×24×24的Features maps
- 再经过2×2的池化层变为4×12×12的Features maps
- 再经过5×5的卷积层变为8×8×8的Features maps
- 最后经过2×2的池化层,变为8×4×4的Features maps
- 这个部分是特征提取。经过特征提取后,进行分类器部分,这里主要是通过全连接将其转化为一维向量,最后再变为十维的输出

这里再进行一些必要的说明,全连接会导致原有的空间结构丧失,卷积神经网络可以保留原有的空间结构
池化的目的是减小尺寸减低计算复杂度,降低过拟合的风险,保留关键信息(常用的Maxpooling就是取局部最大)
convolution+subsampling=Feature Extraction
这里我们进行一下简单的扩展(栅格图像和矢量图像)
栅格图像是以像素为基础的,适用于复杂的图像和照片,但受限于分辨率和放大时的失真。矢量图像是基于数学形状的,适用于图标、标志和需要无损缩放和编辑的应用。
我们使用卷积神经网络处理的图像通常情况是栅格图像
这些栅格图像由像素组成,每个像素都有自己的颜色信息,通常表示为红、绿、蓝(RGB)或灰度值。CNN的卷积层通过在图像上滑动卷积核来识别特征,这些卷积核与图像的局部区域相连接,从而有效地捕获图像中的各种特征,如边缘、纹理和形状。
🍋卷积层
下图展示了卷积层的基本元素,由input Channel、width、height、output Channel组成,这里取其中的一个Patch,然后将其在进行上下左右的平移。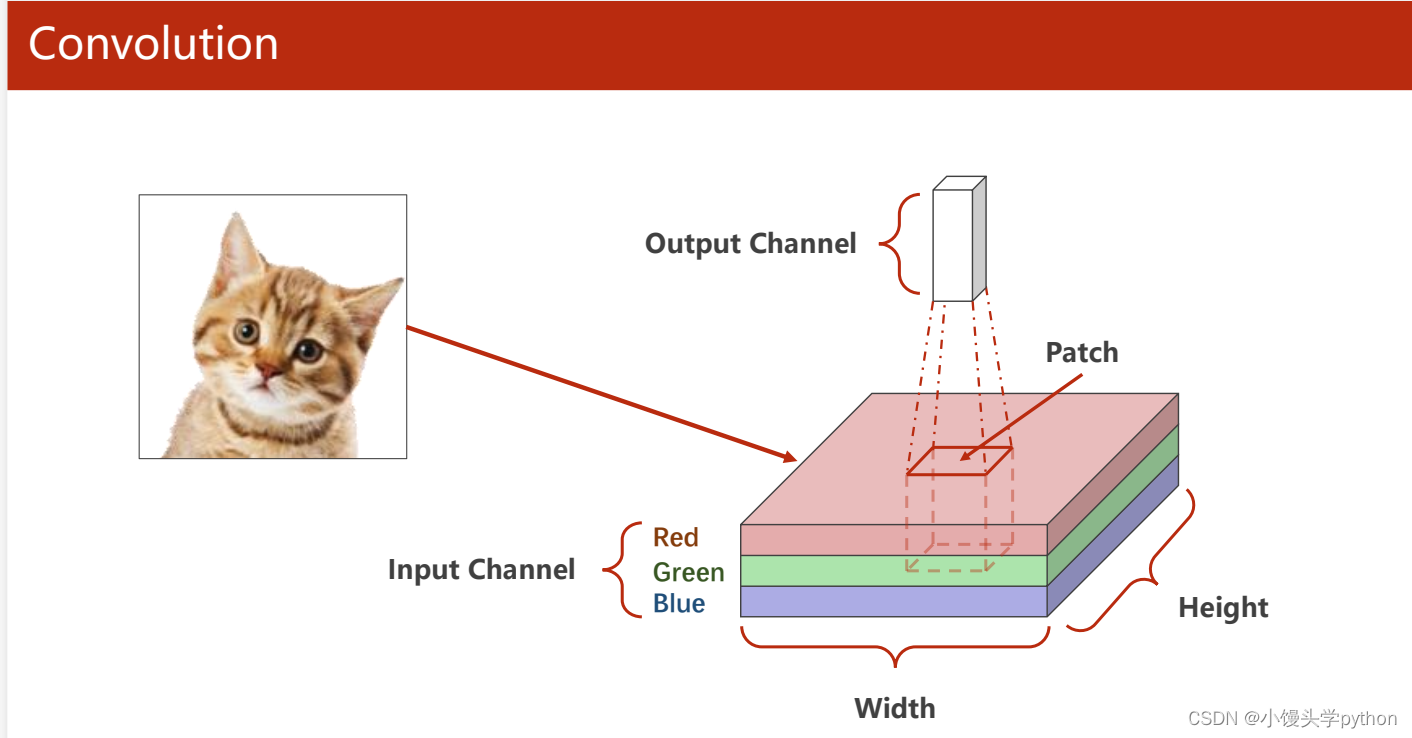
或许大家对上图不是很清楚,那么我们来看看下图,或许可以更直观的理解卷积运算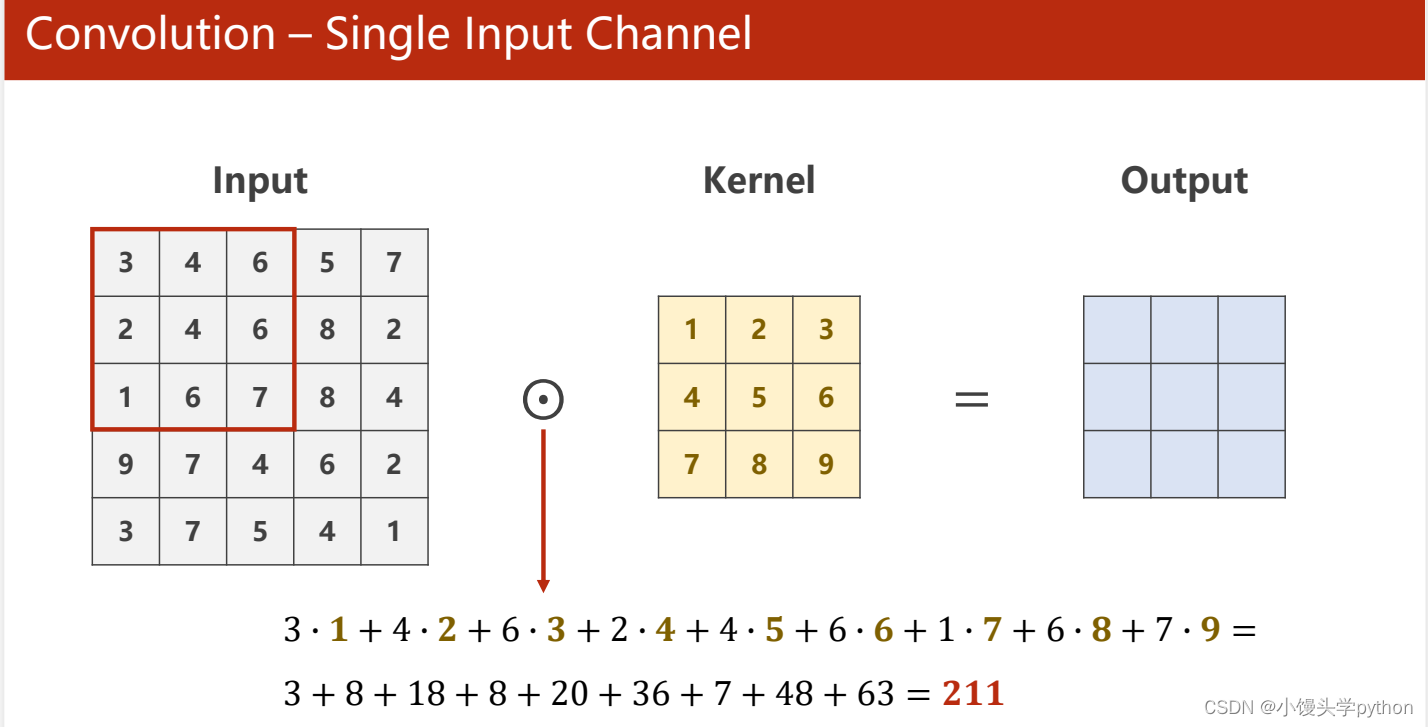
这里是input 是1×5×5,经过1×3×3的卷积核运算,变为1×3×3的output
注意:这里input的Channel与卷积核的Channel的一致的,最终就会得到如下的output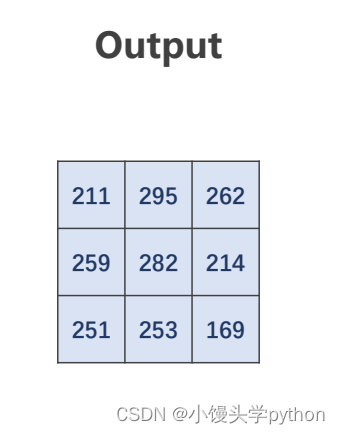
那么如果是Channel=3呢,会有什么变化,卷积核与output会产生什么变化,下图清楚的展示流程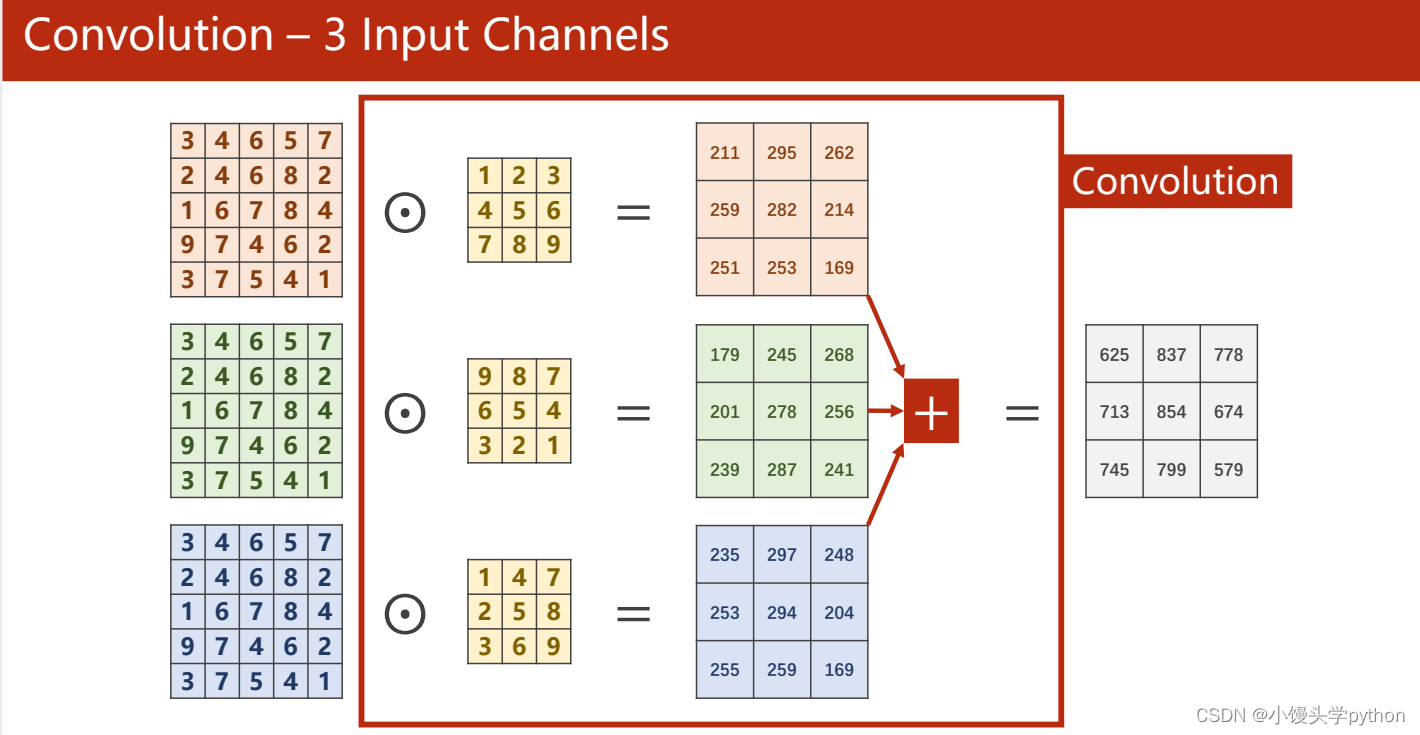
如果堆叠起来,那会变为下图所示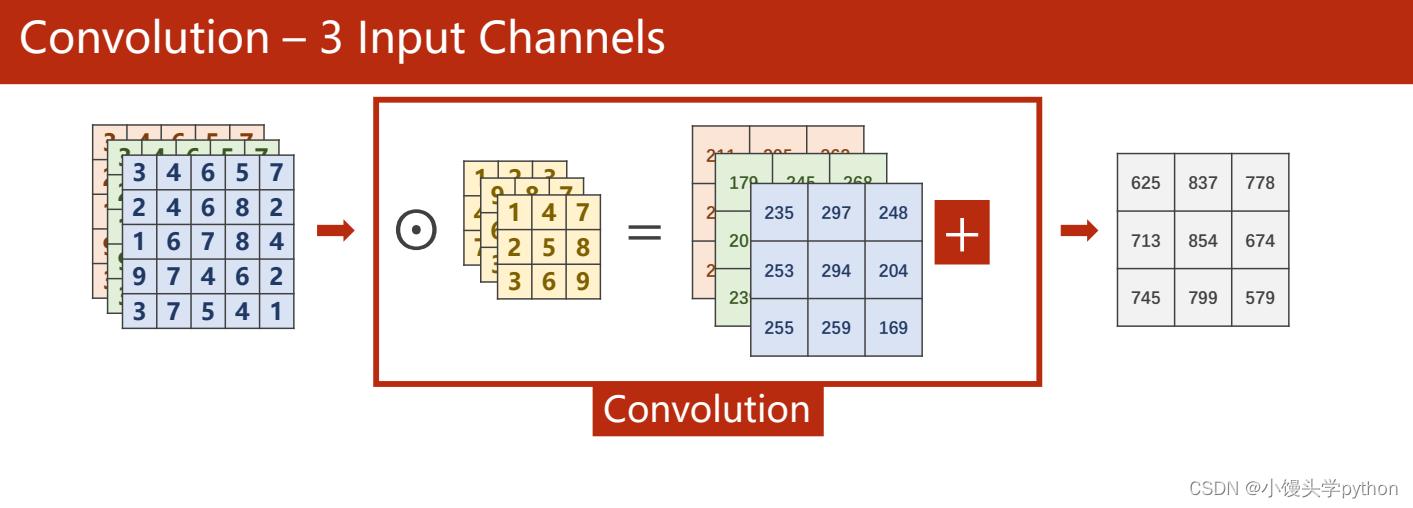
那么我们再扩展一下,如果有n个Input Channel、m个Output Channel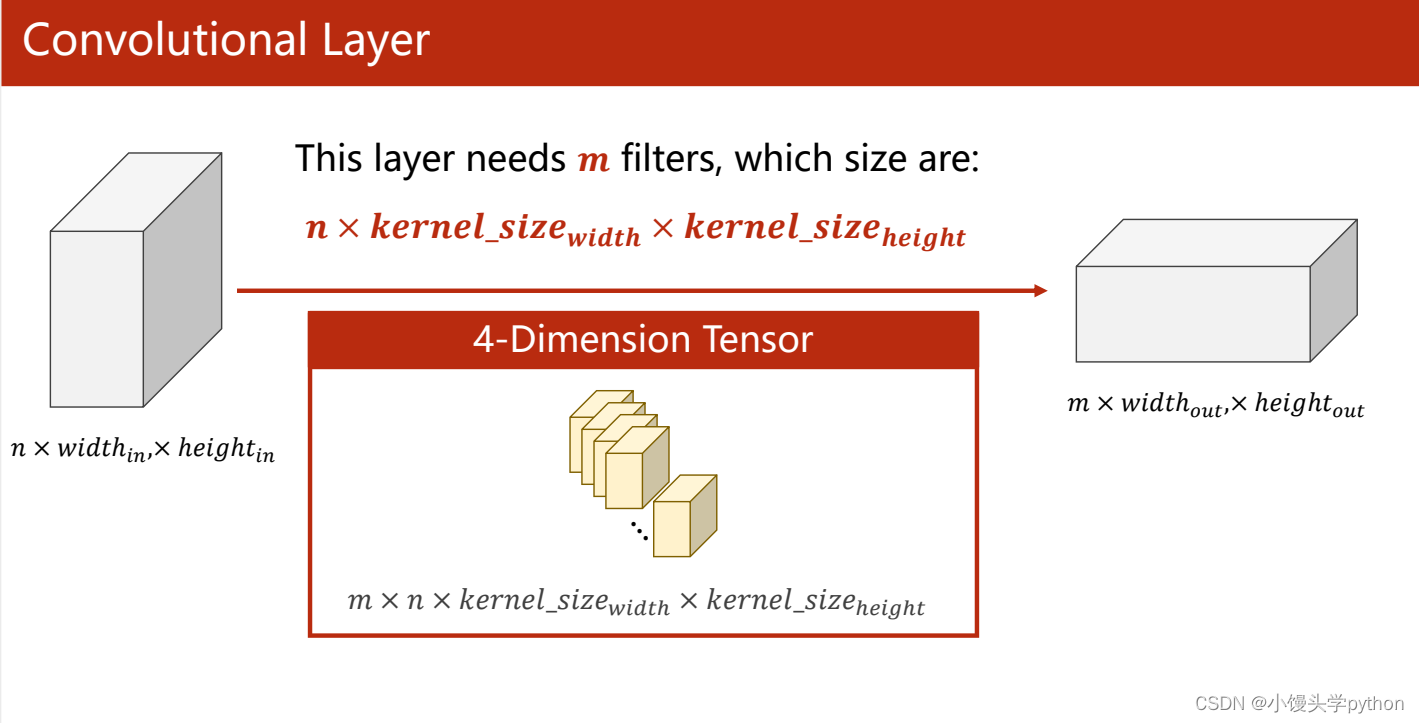
注意:这里input Channel的值与卷积核的Channel相同,Output Channel与卷积核的数量相同
使用Pytorch进行演示的话
import torch
in_channels, out_channels= 5, 10
width, height = 100, 100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channels,
width,
height)
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)

运行代码如下
接下来再简单介绍一下两个Conv2d的两个可选参数
🍋padding
当padding=1代表为input做一层0填充这样的Output就会和input拥有相同的尺寸了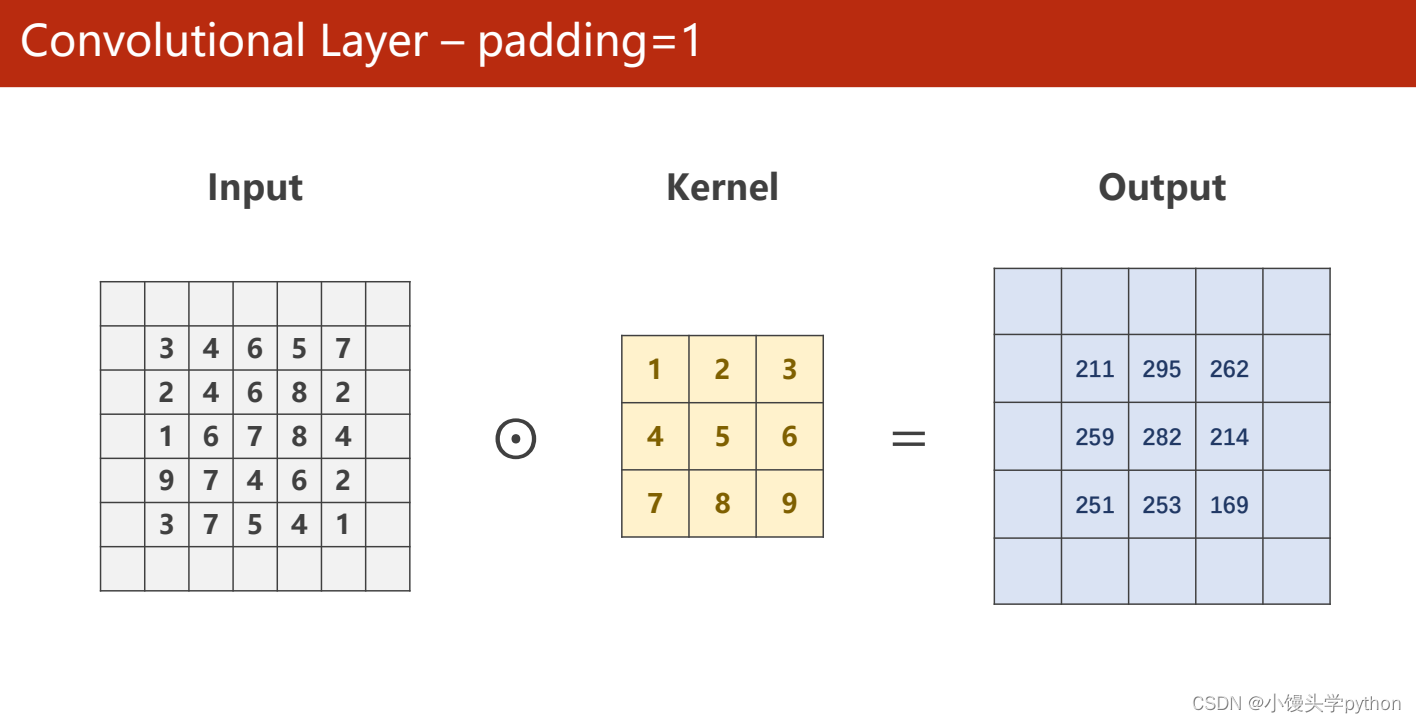
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)
运行结果如下
🍋stride
这个参数是步长的意思,可以减少特征图的尺寸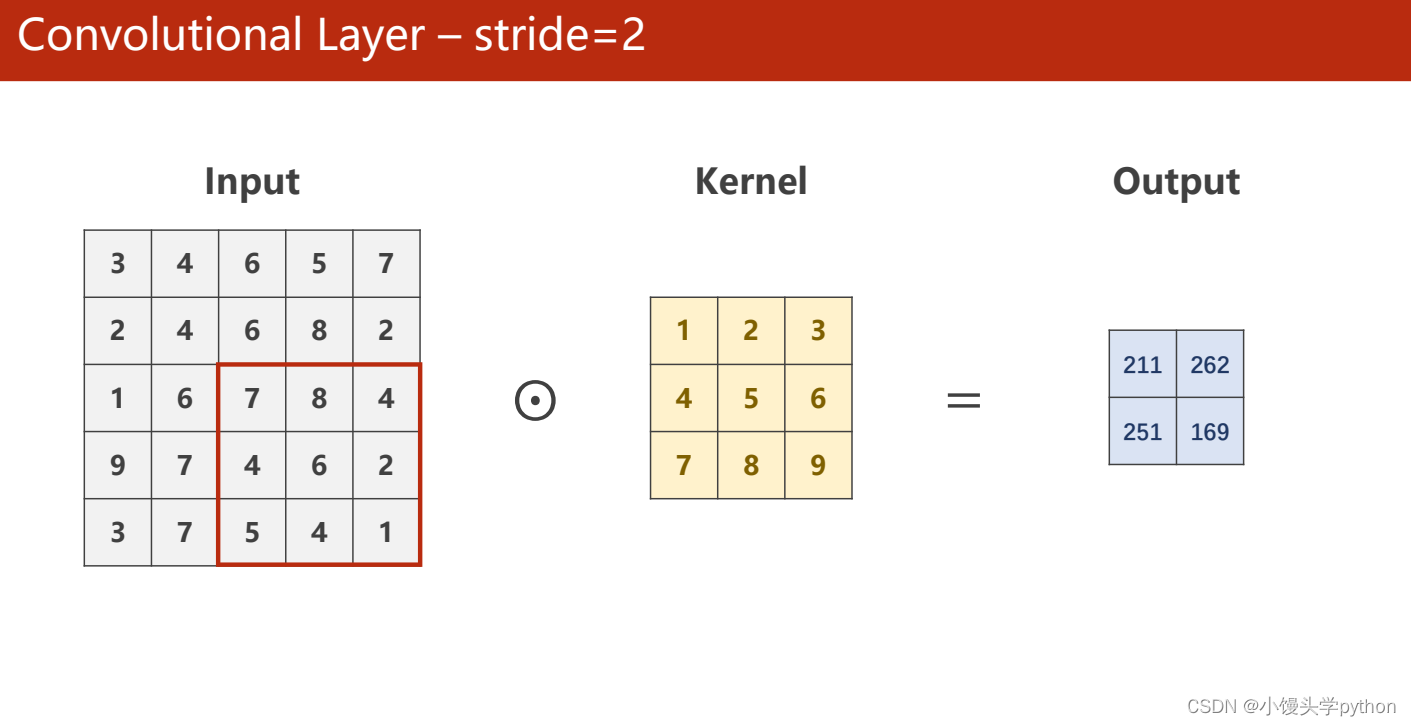
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)
运行结果如下=
🍋池化层
池化层上面已经简单介绍了,这不就不一一赘述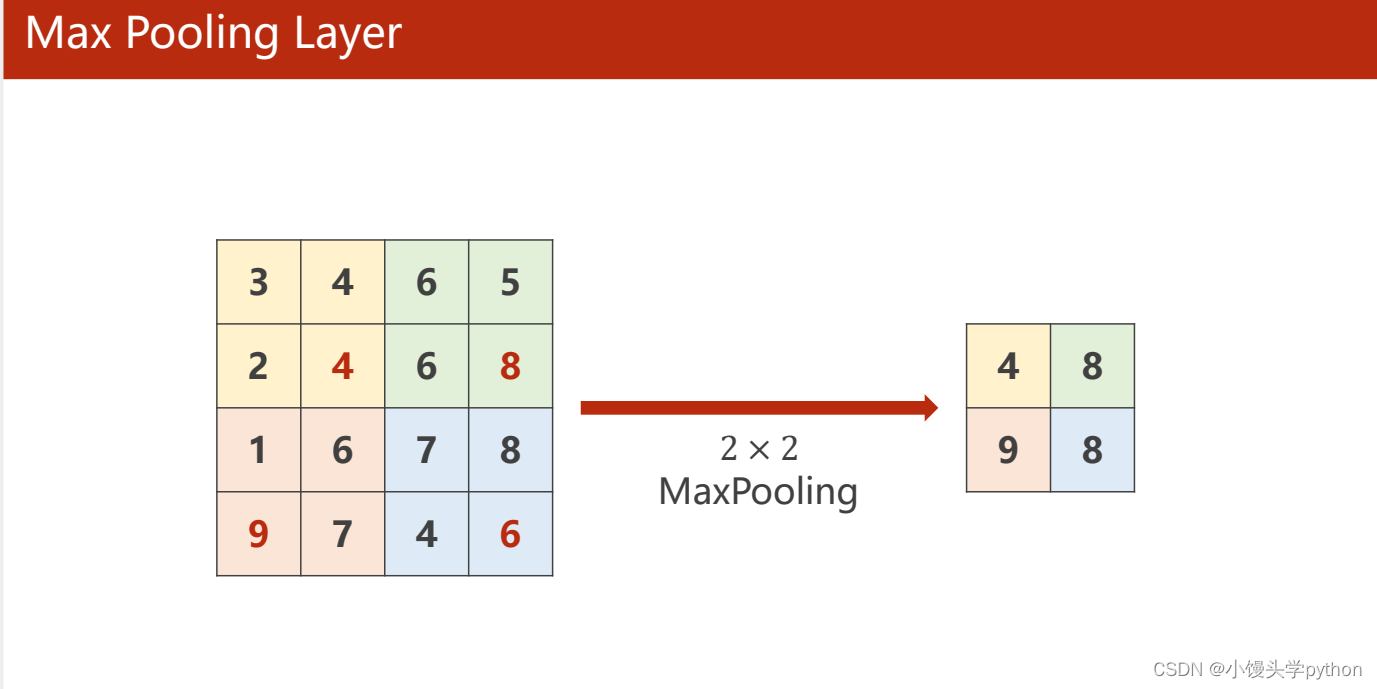
import torch
input = [3,4,6,5,
2,4,6,8,
1,6,7,8,
9,7,4,6,
]
input = torch.Tensor(input).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)
output = maxpooling_layer(input)
print(output)
运行结果如下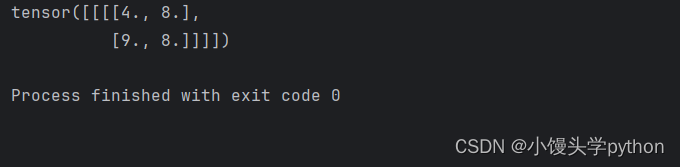
🍋完整代码
下图可以清楚的展示了一整个卷积流程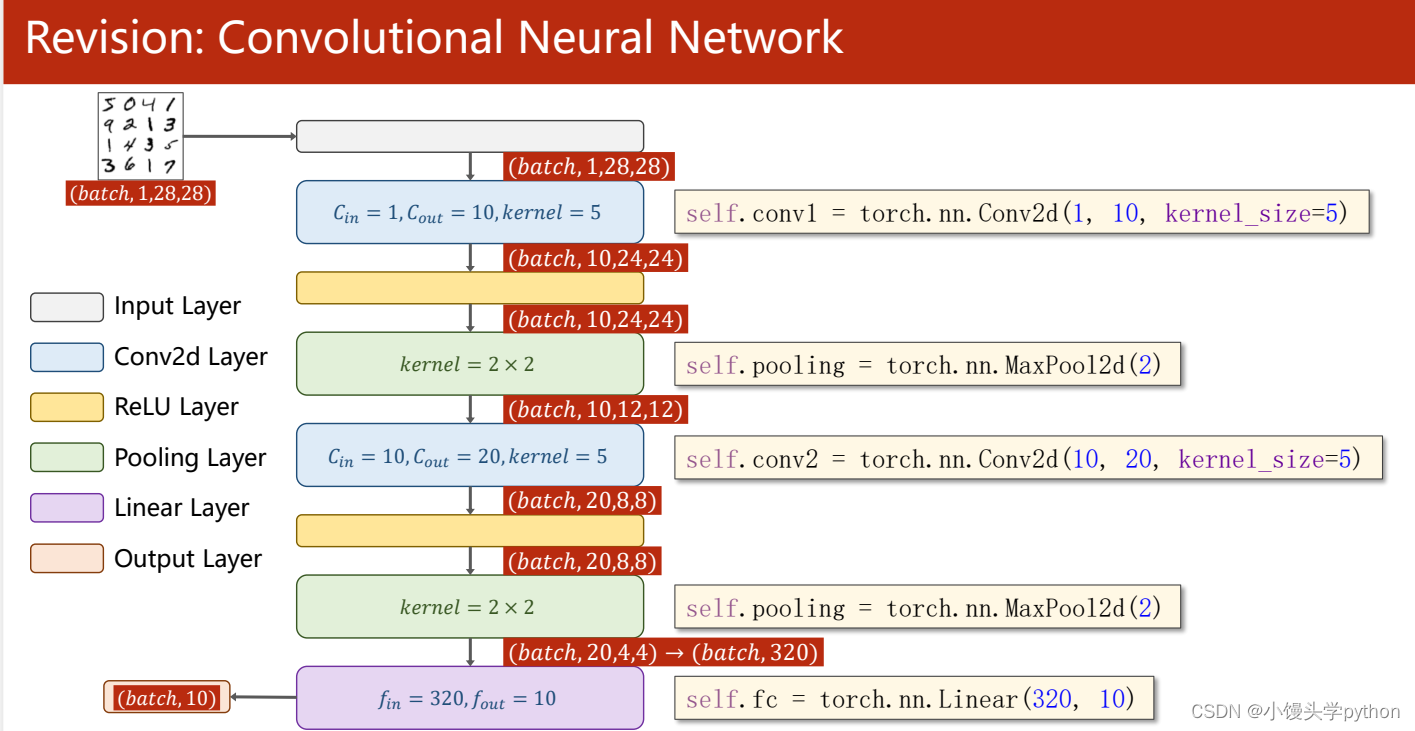
具体代码如下
import torch
import torch.nn.functional as F
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
batch_size = x.size(0)
x = self.pooling(F.relu(self.conv1(x)))
x = self.pooling(F.relu(self.conv2(x)))
x = x.view(batch_size, -1) # flatten
x = self.fc(x)
return x
model = Net()
如果有GPU的话,我们可以使用GPU计算
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
训练和测试代码如下
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))
🍋卷积神经网络的应用领域
图像分类:CNNs可以识别图像中的对象、动物、人物等,因此被广泛用于图像分类任务。有名的例子包括ImageNet图像分类竞赛中的深度卷积网络。
目标检测:CNNs可以帮助检测图像中的物体,并确定它们的位置。这在自动驾驶、视频监控和医学图像分析中都有重要应用。
人脸识别:CNNs可以识别和验证人脸,这在手机解锁、社交媒体标签和安全监控中都有广泛应用。
自然语言处理:CNNs不仅仅用于图像处理,还可以用于文本分类和自然语言处理任务,如情感分析和垃圾邮件检测。
医学图像分析:CNNs有助于分析医学影像,如X光片、MRI扫描和CT扫描,用于诊断和疾病检测。
🍋总结
卷积神经网络是深度学习的关键技术之一,它在图像处理和其他领域中取得了巨大的成功。随着技术的不断发展,我们可以期待看到更多令人兴奋的进展和应用。如果你对这个领域感兴趣,可以看看刘二大人讲的
本文根据b站刘二大人《PyTorch深度学习实践》完结合集学习后加以整理,文中图文均不属于个人。

挑战与创造都是很痛苦的,但是很充实。

- 点赞
- 收藏
- 关注作者
评论(0)