深入理解线性回归模型的评估与优化方法

🍀引言
线性回归是机器学习领域中最基础的模型之一,它在许多实际问题中都具有广泛的应用。然而,在使用线性回归模型时,仅仅构建模型是不够的,还需要对模型进行评估和优化,以确保其在实际应用中表现出色。本篇博客将深入探讨线性回归模型的评估与优化方法,同时使用Python进行实际演示。
🍀模型评估方法
模型评估是了解模型性能的关键步骤,它帮助我们了解模型在新数据上的表现。在线性回归中,常用的评估指标包括均方误差(Mean Squared Error,MSE)、均方根误差(Root Mean Squared Error,RMSE)等。
本文主要介绍三种评估方法,除此之外介绍一些其他的概念,最后上代码
🍀均方误差(MSE)
均方误差是预测值与真实值之间差异的平方的平均值。数学公式如下:
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2MSE=n1∑i=1n(yi−y^i)2
其中,n nn 是样本数量,y i y_iyi 是真实值,y ^ i \hat{y}_iy^i 是模型预测值。
🍀均方根误差(RMSE)
均方根误差是均方误差的平方根,它具有与原始数据相同的单位。计算公式如下:
R M S E = M S E RMSE = \sqrt{MSE}RMSE=MSE
🍀绝对平均误差(MAE)
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|MAE=n1∑i=1n∣yi−y^i∣
其中,n nn 是样本数量,y i y_iyi 是真实值,y ^ i \hat{y}_iy^i 是模型预测值。
相比于MSE,MAE对异常值更加稳健,因为它使用了绝对值。在某些应用场景中,更关注预测值与真实值的绝对差异可能更为合适。
本文主要介绍以上三个评估方法,读者若感兴趣还可以自行查阅
🍀模型优化策略
线性回归模型的性能可能因为多种原因而不佳,因此优化策略变得至关重要。以下是一些常见的优化策略:
🍀特征工程
特征工程是提高模型性能的关键步骤。通过添加、删除、组合特征,以及进行数据转换,我们可以为模型提供更多有用的信息。例如,在房价预测问题中,除了房屋面积,考虑到房间数量、地理位置等特征可能会提升模型表现。
🍀正则化
正则化是防止模型过拟合的一种方法。岭回归(Ridge Regression)和Lasso回归(Lasso Regression)是常用的正则化技术,它们通过对模型参数的大小进行惩罚来控制模型的复杂度。
🍀数据标准化
将特征数据进行标准化可以确保不同特征的尺度一致,有助于模型的训练过程。标准化可以消除特征之间的量纲影响,提高模型的稳定性和收敛速度。
🍀代码演示
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
x = np.array([1,2,3,4,5])
y = np.array([1,3,2,3,5])
lin_reg = LinearRegression()
lin_reg.fit(x.reshape(-1,1),y)
lin_reg.score(x.reshape(-1,1),y)
运行结果如下
# 均方误差
def MSE(y_true,y_predict):
return np.sum((y_true-y_predict)**2)/len(y_true)
运行结果如下
# 均根方误差
from math import sqrt
def RMSE(y_true,y_predict):
return sqrt(np.sum((y_true-y_predict)**2)/len(y_true))
运行结果如下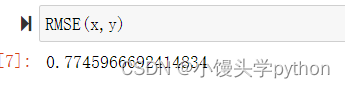
# 绝对平均误差
def MAE(y_true,y_predict):
return np.sum(np.absolute(y_true-y_predict))/len(y_true)
运行结果如下
🍀疑问?
这时会有小伙伴产生疑问,评估数值越大越好还是越小越好呢?
对于大部分模型评估指标来说,确实是越大越好,因为这意味着模型在预测上更准确、更接近真实值。然而,要根据具体的评估指标和任务类型来判断。
均方误差(MSE) 和 均方根误差(RMSE):对于这两个指标,数值越小越好,因为它们衡量了模型预测值与真实值之间的差异,越小表示模型的预测越接近真实值。
绝对平均误差(MAE):同样地,MAE数值越小越好,因为它衡量了平均绝对差异,即预测值与真实值之间的绝对距离。
决定系数(R-squared):在决定系数中,数值越接近1越好,因为它表示模型对因变量变化的解释能力,越接近1表示模型能够更好地解释数据的变化。
总体而言,当我们评估模型时,我们通常希望评估指标的数值越小越好(如MSE、RMSE、MAE),或者越大越好(如R-squared)。然而,在某些情况下,具体的任务和问题背景可能会影响哪个方向更适合。例如,如果我们更关注异常值,可能会更倾向于使用MAE,因为它不会受到异常值的影响。在选择评估指标时,务必要结合问题的实际情况来进行判断。

挑战与创造都是很痛苦的,但是很充实。

- 点赞
- 收藏
- 关注作者
评论(0)