使用BeautifulSoup4解析HTML实战(二)

🍀分析网站
本节我们尝试爬取一个手办网站,如下
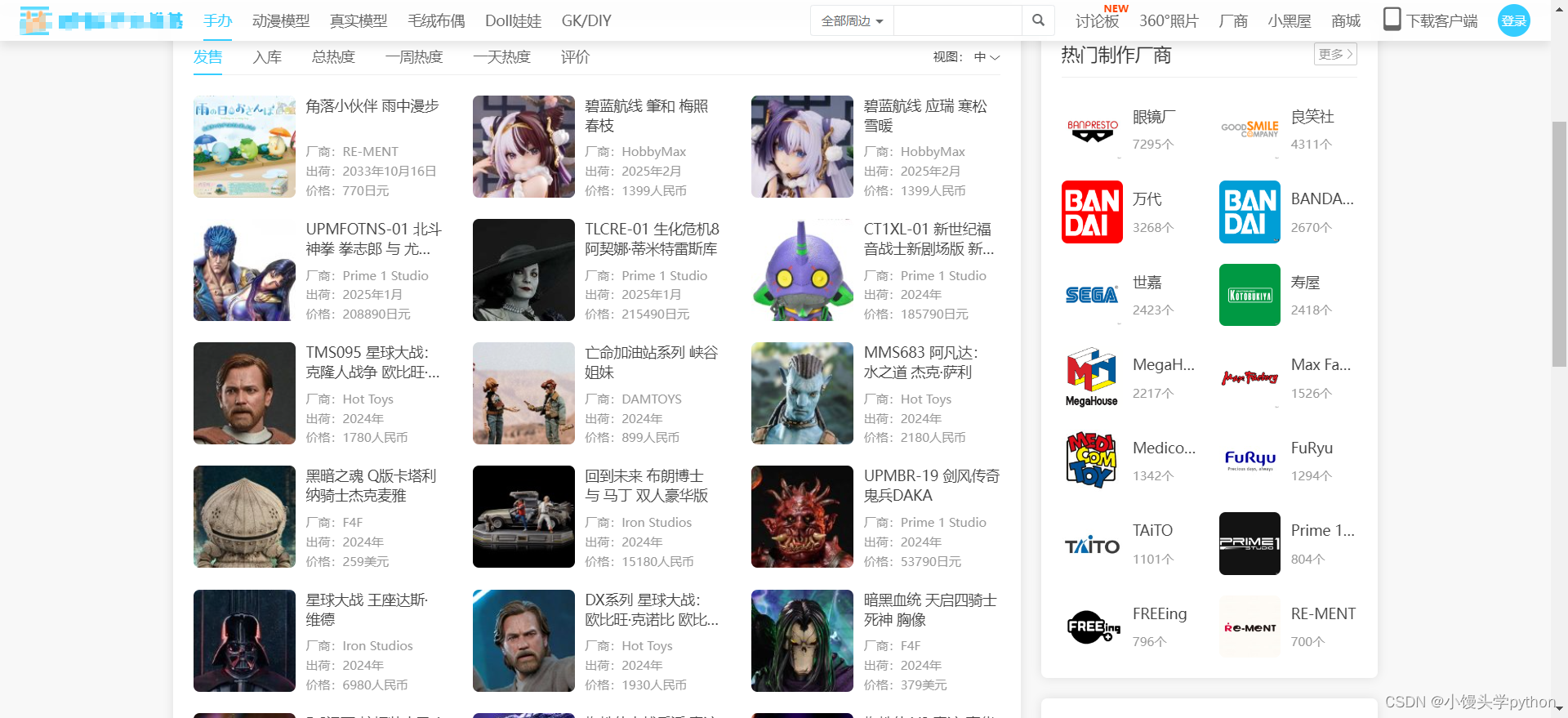
我们的目的是爬取每个手办的名称、厂商、出荷、价格
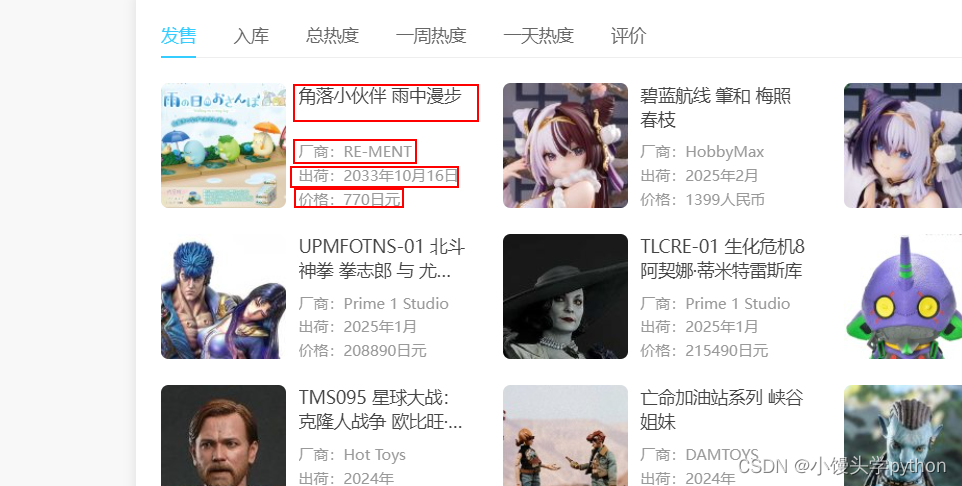
鼠标右键检查后,我们经过分析可以得出,我们想要获得的数据在一个class="hpoi-detail-grid-right"的div标签中,另外在此div下包含另外两个div,第一个div中的a标签含有我们想要的手办名称,第二个div标签中的span标签含有我们想要的手办厂商等
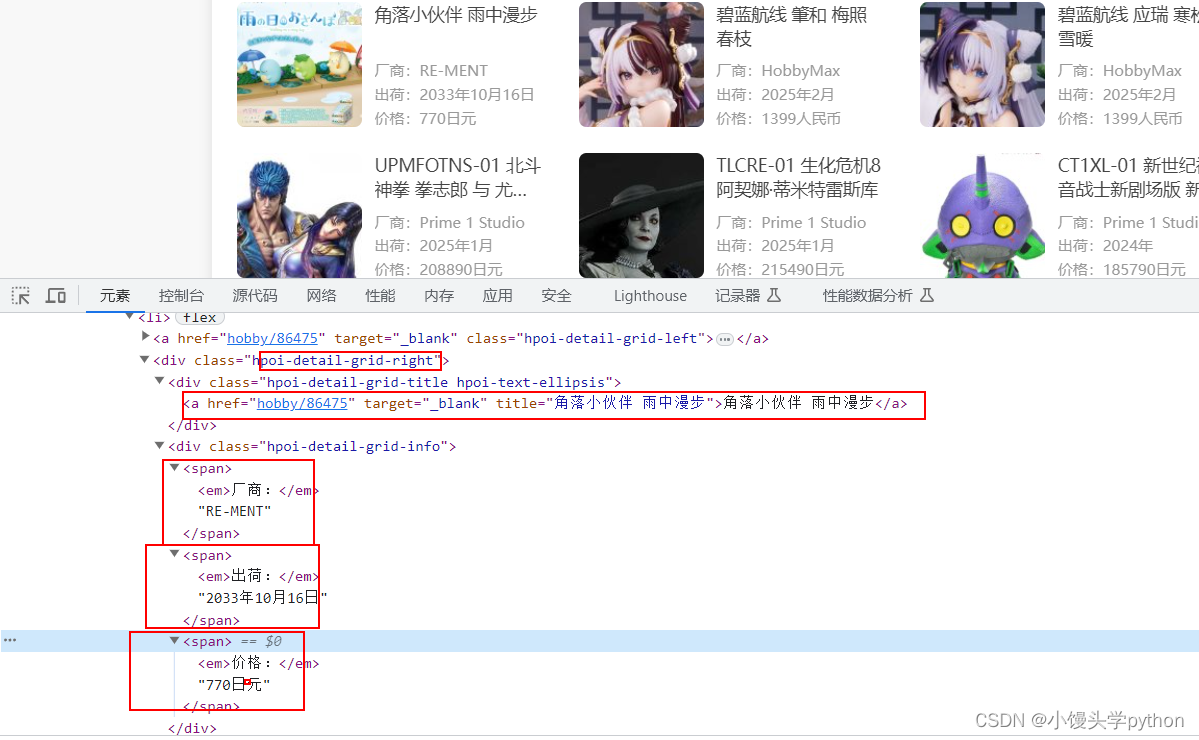
但是我们想要获取的手办数据并不是一个手办,而是一页的手办,那么需要不光要看局部还有看看整体,整体来看,每个手办都存在于li标签中,而所有的手办都被ul标签所包含
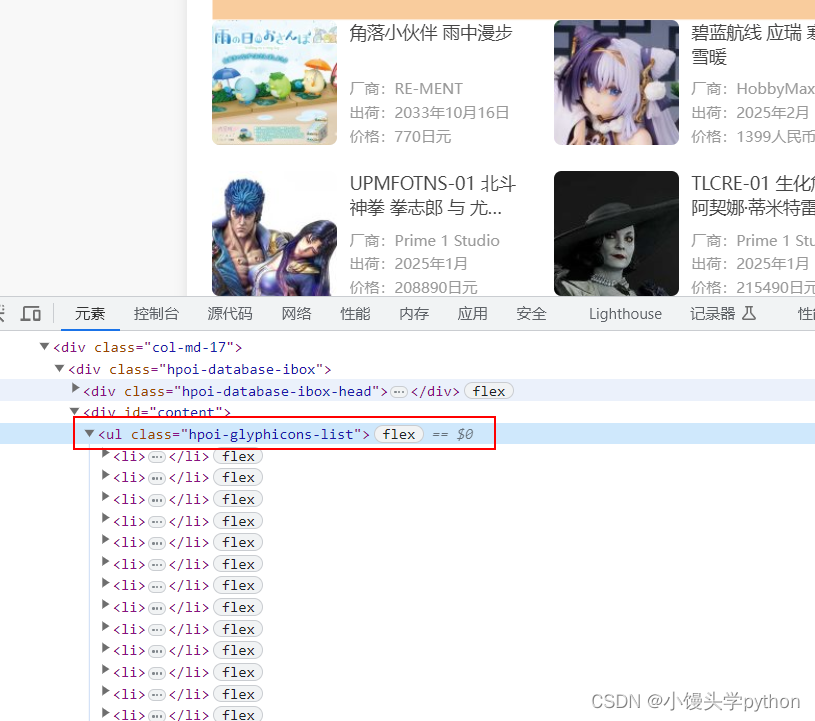
分析完标签的内容,我们再来看看url的规律,不难发现,每个url的最后参数page代表了是第几页
"""
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=1
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=2
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=3
"""
分析的差不多,我们开始真正的实战
🍀爬取前的准备
首先导入需要的库
# 导入模块
import requests
from bs4 import BeautifulSoup
之后定义url和请求头,url的处理,我们需要使用for循环,以及定义一个空列表将每个url添加进去
# 获取前五页的url
urls = []
for i in range(1,5):
url ='https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page={}'.format(i)
urls.append(url)
在这里插入代码片# 定义url和请求头
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105"
}
🍀获取数据
我们首先需要将class="hpoi-glyphicons-list"的ul里的内容提取出来
data = soup.find_all('ul',class_="hpoi-glyphicons-list")
提取完ul标签里的内容,这里我们想将每个li标签拆分出来
data = soup.find_all('ul',class_="hpoi-glyphicons-list")
for i in data:
data_1 = i.find_all('li')
拆分之后的li标签用data_1进行保存,接下来,我们就可以重点提取单个手办的数据了,下面的代码代表提取上面分析得到得出的div标签里的内容
for j in data_1:
data_2 = j.find_all('div',class_="hpoi-detail-grid-right")
最后一步就是提取,我们真正想要的数据了,我们在每条的最后加一个切片,目的是切除无用的数据
for k in data_2:
title = k.find_all('a')[0].string
changshang = k.find_all('span')[0].text[3:]
chuhe = k.find_all('span')[1].text[3:]
price = k.find_all('span')[2].text[3:]
🍀完整代码
完整代码如下
# 导入模块
import requests
from bs4 import BeautifulSoup
# 定义url和请求头
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105utoken=UTKbd23efb1729a444898977cf2a91381c0; JSESSIONID=9EF5C8BA4F3C3E29278A9972A946408A; Hm_lvt_05b494824003cbf80b23e846462269d1=1688387237,1688712147,1689130492,1689145041; allOrder=release; Hm_lpvt_05b494824003cbf80b23e846462269d1=1689145105"
}
"""
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=1
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=2
https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page=3
"""
# 获取前四页的url
urls = []
for i in range(1,5):
url ='https://www.hpoi.net/hobby/all?order=release&r18=-1&workers=&view=3&category=100&page={}'.format(i)
urls.append(url)
items = []
for d_url in urls:
# 发送请求
response = requests.get(d_url, headers=_headers)
content = response.content.decode('utf8')
# 实例化对象
soup = BeautifulSoup(content, 'lxml')
# 名称
data = soup.find_all('ul',class_="hpoi-glyphicons-list")
for i in data:
data_1 = i.find_all('li')
for j in data_1:
data_2 = j.find_all('div',class_="hpoi-detail-grid-right")
for k in data_2:
title = k.find_all('a')[0].string
changshang = k.find_all('span')[0].text[3:]
chuhe = k.find_all('span')[1].text[3:]
price = k.find_all('span')[2].text[3:]
data_3 = {
"名称": title,
"厂商":changshang,
"出荷":chuhe,
"价位":price
}
items.append(data_3)
print(items)

运行结果如下

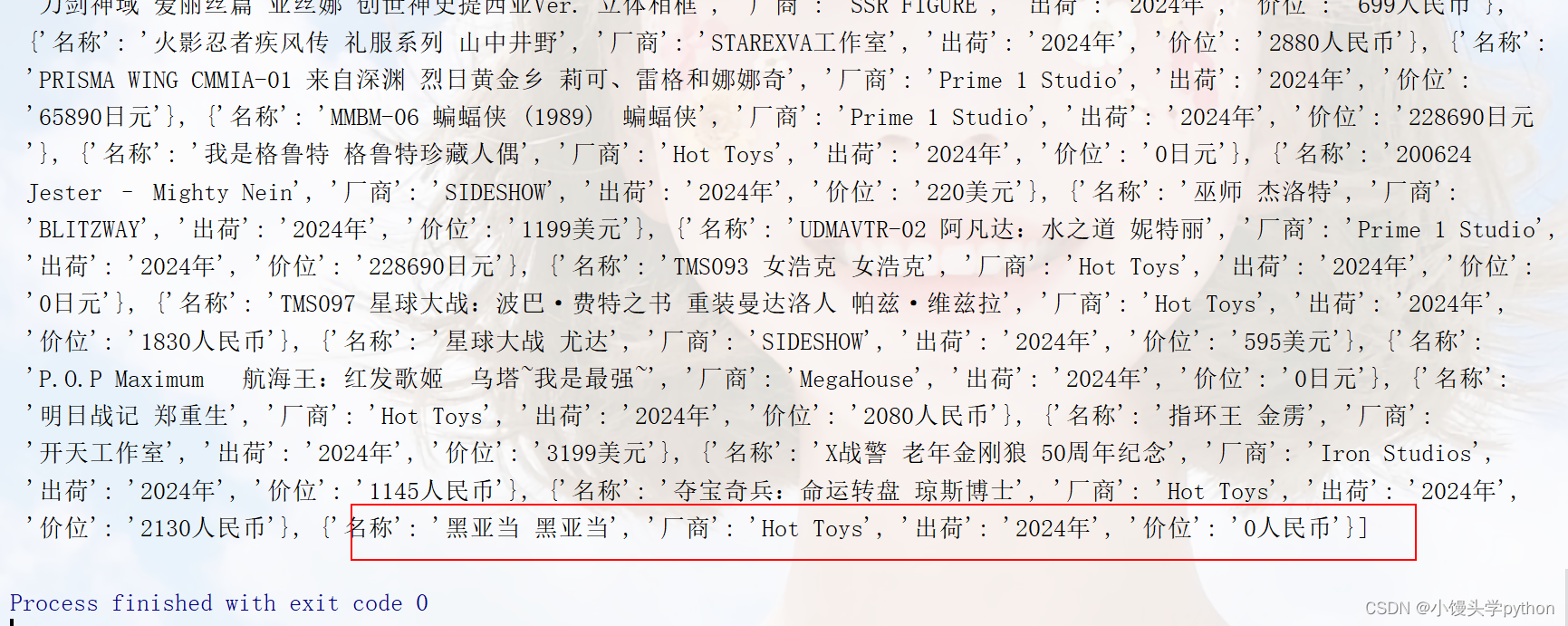
测试一下爬取的对不对,如图所示,正确
如果使用Xpath来进行爬取的话,我感觉能更简单一些,例如手办名称,,只需要改变li标签的下标即可,时间复杂度会大大降低,如果使用bs4会增大开销(也可能我的方法笨~)

🍀.string和.text的区别
在爬虫中,.string和.text是两个常用的属性,用于提取BeautifulSoup解析后的HTML或XML文档中的文本内容
.string属性用于提取单个标签元素的文本内容,例如:
from bs4 import BeautifulSoup
html = "<p>Hello, World!</p>"
soup = BeautifulSoup(html, "html.parser")
text = soup.p.string
print(text) # 输出: Hello, World!
.text属性用于提取标签元素及其子元素中的所有文本内容,例如:
from bs4 import BeautifulSoup
html = "<p>Hello, <b>World!</b></p>"
soup = BeautifulSoup(html, "html.parser")
text = soup.p.text
print(text) # 输出: Hello, World!
需要注意的是,如果使用.text属性提取包含子元素的标签内容时,子元素之间的文本会以空格进行分隔。
综上所述,.string属性用于提取单个元素的文本内容,而.text属性用于提取包括所有子元素的文本内容。
🍀bs4和Xpath之间的微妙联系
这部分留给对其感兴趣的小伙伴
BeautifulSoup4(bs4)和XPath是两种常用的用于解析和提取HTML/XML文档数据的工具。
BeautifulSoup4是一个Python库,用于解析HTML和XML文档,并提供了一种简单而直观的方式来浏览、搜索和操作这些文档。它将HTML/XML文档转换成一个Python对象树,可以使用Python的语法和方法来方便地提取所需的信息。
XPath是一种用于在XML文档中定位和选择节点的语言。它提供了一个简洁而强大的方式来从XML文档中提取数据。XPath使用路径表达式来选择节点或一组节点,这些路径表达式可以在文档层次结构中沿着节点路径导航。
BeautifulSoup4和XPath之间的关系是,可以在BeautifulSoup4中使用XPath表达式来定位和选择节点。虽然BeautifulSoup4本身提供了类似XPath的CSS选择器等方法,但有时XPath的功能更强大,可以更精确地选择和提取所需的数据。
要在BeautifulSoup4中使用XPath,可以使用bs4库的内置方法select(),这个方法接受一个XPath表达式作为参数,并返回匹配该表达式的节点列表。以下是一个示例:
from bs4 import BeautifulSoup
# HTML文档
html = '''
<html>
<body>
<div id="content">
<h1>标题</h1>
<ul>
<li>列表项1</li>
<li>列表项2</li>
<li>列表项3</li>
</ul>
<a href="http://example.com">链接</a>
</div>
</body>
</html>
'''
# 创建BeautifulSoup对象
soup = BeautifulSoup(html, 'html.parser')
# 使用XPath选择节点
nodes = soup.select('//div[@id="content"]/ul/li')
for node in nodes:
print(node.text)
在上面的示例中,使用XPath表达式//div[@id=“content”]/ul/li选择了id为"content"的div节点下的ul节点下的所有li节点,并打印出它们的文本内容。

挑战与创造都是很痛苦的,但是很充实。

- 点赞
- 收藏
- 关注作者
评论(0)