使用BeautifulSoup4解析HTML实战(一)

【摘要】 🍀分析网站本节我们的目标网站是新浪微博的热搜榜,我们的目标是获取热榜的名称和热度值首先通过检查,查看一些标签不难看出,我们想要的数据是包含在class="td-02"的td标签中热搜内容在td标签下的a标签中热度位于td标签下的span标签中🍀爬取前的准备首先导入需要的库# 导入模块import requestsfrom bs4 import BeautifulSoup之后定义url和请...
🍀分析网站
本节我们的目标网站是新浪微博的热搜榜,我们的目标是获取热榜的名称和热度值
首先通过检查,查看一些标签
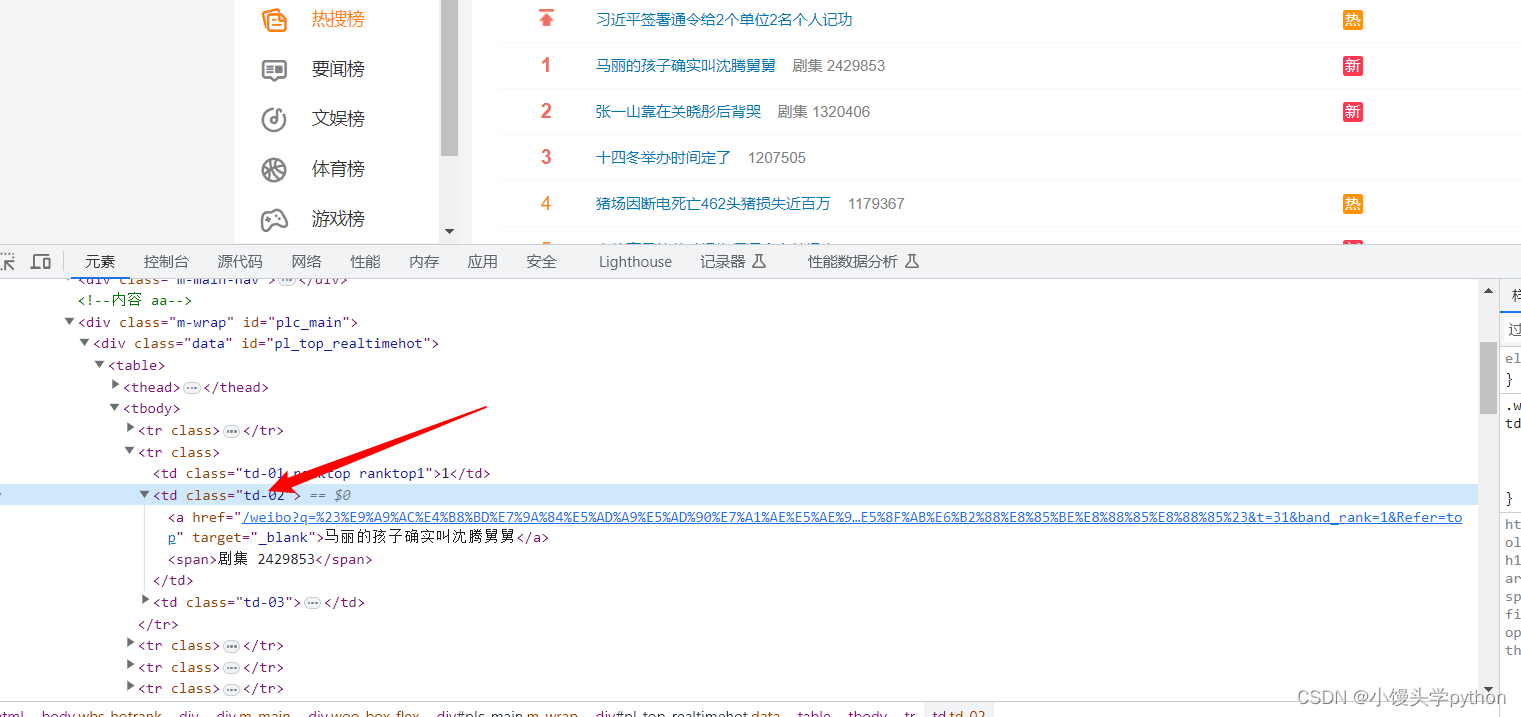
不难看出,我们想要的数据是包含在class="td-02"的td标签中
热搜内容在td标签下的a标签中
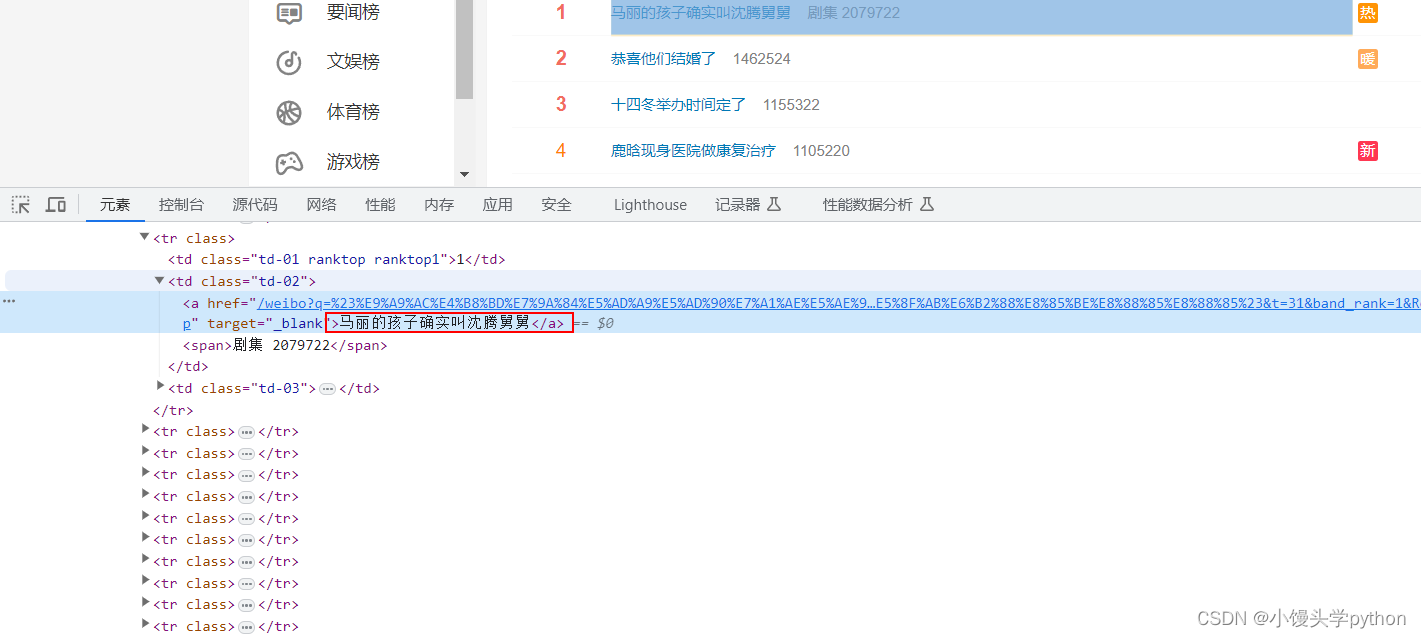
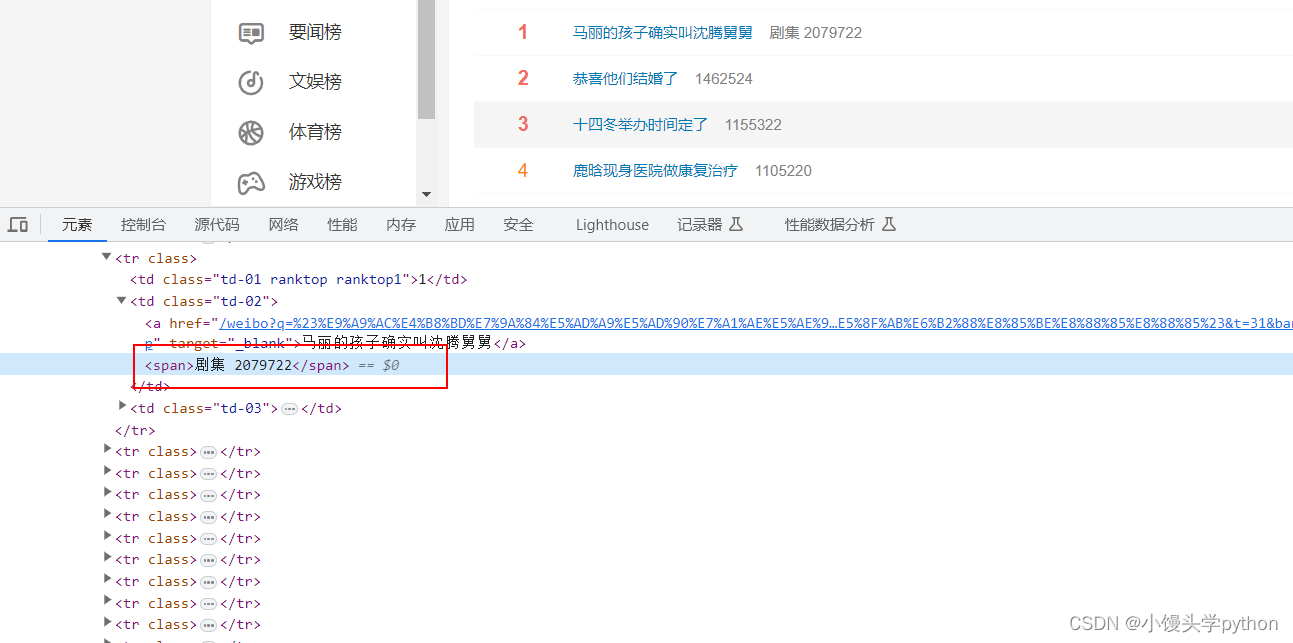
热度位于td标签下的span标签中
🍀爬取前的准备
首先导入需要的库
# 导入模块
import requests
from bs4 import BeautifulSoup
之后定义url和请求头,在请求头这里,寻常的网站或许只需要User-Agent,这里还需要一个Cookie
在这里插入代码片# 定义url和请求头
url = 'https://s.weibo.com/top/summary?display=0&retcode=6102'
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WW2kX-Z46lRbEGNeGGOqQzg; SINAGLOBAL=1879006065688.1335.1674544342950; UOR=,,www.baidu.com; SUB=_2AkMUum_nf8NxqwJRmP8cy2rkbYh1zQ_EieKi5p48JRMxHRl-yT9vqmEptRB6PzpBCFr8Nw9WHg85yXpbEGjv_BB4-91Q; _s_tentry=weibo.com; Apache=5265586173710.342.1689125693519; ULV=1689125693521:3:1:1:5265586173710.342.1689125693519:1675905464675"
}
之后进行发送请求和实例化对象
# 发送请求
response = requests.get(url,headers=_headers)
content = response.content.decode('utf8')
# 实例化对象
soup = BeautifulSoup(content, 'lxml')
这里我们使用的是lxml HTML解析器,市面上90%的网站都可以用它解析,但是还是有一些漏网之鱼,下面表格中介绍了一些其他的解析器
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | soup = BeautifulSoup(‘html’,‘html.parser’) | 速度适中 | 在Python老版本中文容错力差 |
| lxml HTML解析器 | soup = BeautifulSoup(‘html’,‘lxml’) | 速度快 | 需要安装C语言库 |
| lxml XML解析器 | soup = BeautifulSoup(‘html’,‘xml’) | 速度快 | 需要安装C语言库 |
| html5lib | soup = BeautifulSoup(‘html’,‘html5lib’) | 以浏览器的方式解析文档 | 速度慢 |
介绍完这几种解析器后,我们接下来要做的就是使用bs4来进行获取数据,细心的小伙伴可以用Xpath进行对比一下
🍀获取数据
获取数据的步骤比较简单,根据先前的分析,我们使用find_all进行获取即可,这里注意我们需要使用列表切一下,因为我们想要获取的热榜是从第二个开始的
接下来定义一个列表,使用一个for循环,将想要提取的数据依次提取即可,最后保存到定义好的列表中
# 提取数据
tds = soup.find_all('td',class_="td-02")[1:]
weibos = []
for td in tds:
# 内容
event = td.find_all('a')[0].string # 只把对象里面的内容提取出来
# 热度
hot = td.find_all('span')[0].string
weibo = {
"event": event,
"hot": hot
}
weibos.append(weibo)
print(weibos)
🍀完整代码
# 导入模块
import requests
from bs4 import BeautifulSoup
# 定义url和请求头
url = 'https://s.weibo.com/top/summary?display=0&retcode=6102'
_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",
"Cookie": "SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9WW2kX-Z46lRbEGNeGGOqQzg; SINAGLOBAL=1879006065688.1335.1674544342950; UOR=,,www.baidu.com; SUB=_2AkMUum_nf8NxqwJRmP8cy2rkbYh1zQ_EieKi5p48JRMxHRl-yT9vqmEptRB6PzpBCFr8Nw9WHg85yXpbEGjv_BB4-91Q; _s_tentry=weibo.com; Apache=5265586173710.342.1689125693519; ULV=1689125693521:3:1:1:5265586173710.342.1689125693519:1675905464675"
}
# 发送请求
response = requests.get(url,headers=_headers)
content = response.content.decode('utf8')
# 实例化对象
soup = BeautifulSoup(content, 'lxml')
# 提取数据
tds = soup.find_all('td',class_="td-02")[1:]
weibos = []
for td in tds:
# 内容
event = td.find_all('a')[0].string # 只把对象里面的内容提取出来
# 热度
hot = td.find_all('span')[0].string
weibo = {
"event": event,
"hot": hot
}
weibos.append(weibo)
print(weibos)

🍀find_all()介绍
完成了这次的实战可能有的人对这个方法还是有些不太了解,接下来,针对此方法,我来详细介绍一下
在BeautifulSoup库(通常作为bs4导入)中,find_all是一个常用的方法,用于在HTML或XML文档中查找符合特定条件的所有元素。
find_all的基本语法是:
find_all(name, attrs, recursive, string, limit, **kwargs)
其中,参数的含义如下:
- name:要查找的元素标签名称或标签列表。可以使用字符串、正则表达式或函数来匹配标签名。
- attrs:要查找的元素的属性值(可选)。可以使用字典或关键字参数来指定多个属性和对应的值。
- recursive:指定是否递归查找子孙节点,默认为 True。
- string:用于查找具有指定文本内容的元素(可选)。
- limit:限制返回的结果数量的最大值(可选)。
下面是一些使用find_all的示例:
- 查找特定标签的所有元素:
soup.find_all("a") # 查找所有 <a> 标签的元素
soup.find_all(["a", "img"]) # 查找所有 <a> 和 <img> 标签的元素
- 查找具有特定属性值的元素:
soup.find_all(attrs={"class": "title"}) # 查找所有 class 属性为 "title" 的元素
soup.find_all(id="content") # 查找所有 id 属性为 "content" 的元素
- 使用正则表达式进行匹配:
import re
soup.find_all(re.compile("^h")) # 查找标签名以 "h" 开头的元素
soup.find_all(href=re.compile("example.com")) # 查找所有href属性包含 "example.com" 的元素
- 查找具有特定文本内容的元素:
soup.find_all(string="Hello") # 查找文本内容为 "Hello" 的元素
soup.find_all(string=re.compile("^H")) # 查找文本内容以 "H" 开头的元素
这些只是find_all方法的一些基本用法示例,我们当然还可以根据具体情况组合和使用不同的参数来实现更复杂的元素查找。

挑战与创造都是很痛苦的,但是很充实。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)