Hadoop快速入门——第一章、认识Hadoop与创建伪分布式模式(Hadoop3.1.3版本配置)

【摘要】 目录操作位置上传压缩包解压及修改文件夹名称免密配置将秘钥拷贝到本机Java环境配置与Hadoop环境配置执行脚本修改hadoop配置文件1、修改hadoop-env.sh2、修改yarn-env.sh3、修改core-site.xml4、修改hdfs-site.xml5、修改mapred-site.xml6、修改yarn-site.xmlhadoop初始化配置启动Hadoop服务访问服务操...
目录
操作位置
声明,为方便操作,所有内容都在【/opt】文件夹下。
cd /opt上传压缩包
需要两个包,java的和hadoop的,版本是1.8以及3.1.3版本。
下载链接:
上传到/opt

![]()
解压及修改文件夹名称
解压命令
tar -zxvf jdk-8u212-linux-x64.tar.gz
tar -zxvf hadoop-3.1.3.tar.gz
修改文件夹命令
mv 文件夹名 jdk
mv 文件夹名 hadoop

![]()
可以看到文件夹的名称已经更换方便配置系统变量。
免密配置
ssh-keygen -t rsa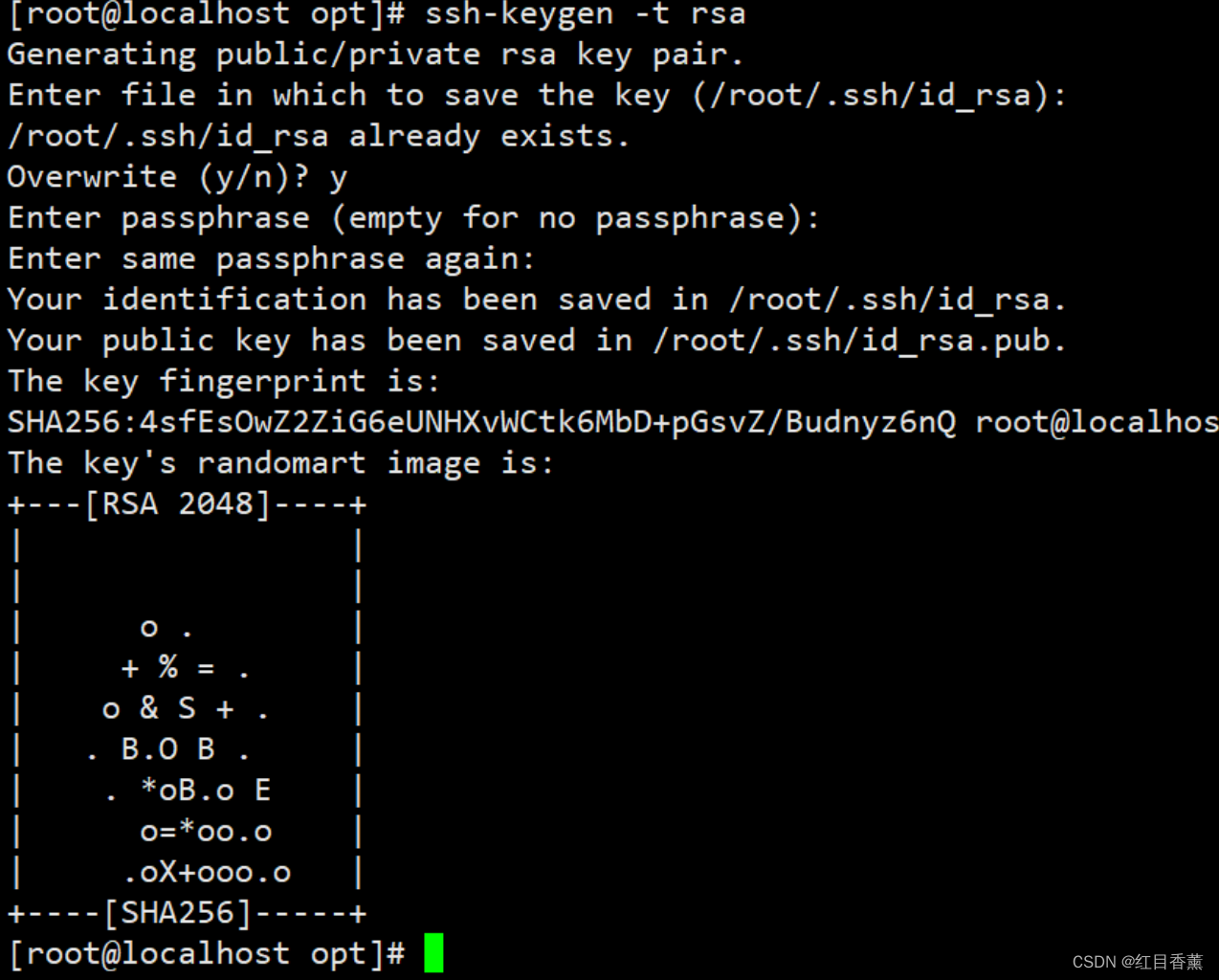
![]()
将秘钥拷贝到本机
ssh-copy-id -i root@localhost需要输入【yes】与【root密码】

![]()
ssh验证:
ssh 'root@localhost'
![]()
路径上能看出来,opt变成了~。
Java环境配置与Hadoop环境配置
创建一个脚本文件例如:【hadoop3.sh】文件,添加下面的路径配置
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
![]()
执行脚本
source hadoop3.sh配置确认
hadoop version
![]()
修改hadoop配置文件
这里我们逐一进行添加以及修改
1、修改hadoop-env.sh
将下列代码防止到文件的最上行即可。
export JAVA_HOME=/opt/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
![]()
2、修改yarn-env.sh
export JAVA_HOME=/opt/jdk
![]()
3、修改core-site.xml
看好添加位置,在configuration标签内。
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-record/temp</value>
</property>
![]()
4、修改hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-record/nameNode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-record/dataNode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
![]()
5、修改mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
![]()
6、修改yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
![]()
这里我们共计修改了6个文件哦,都要改,别弄错喽。
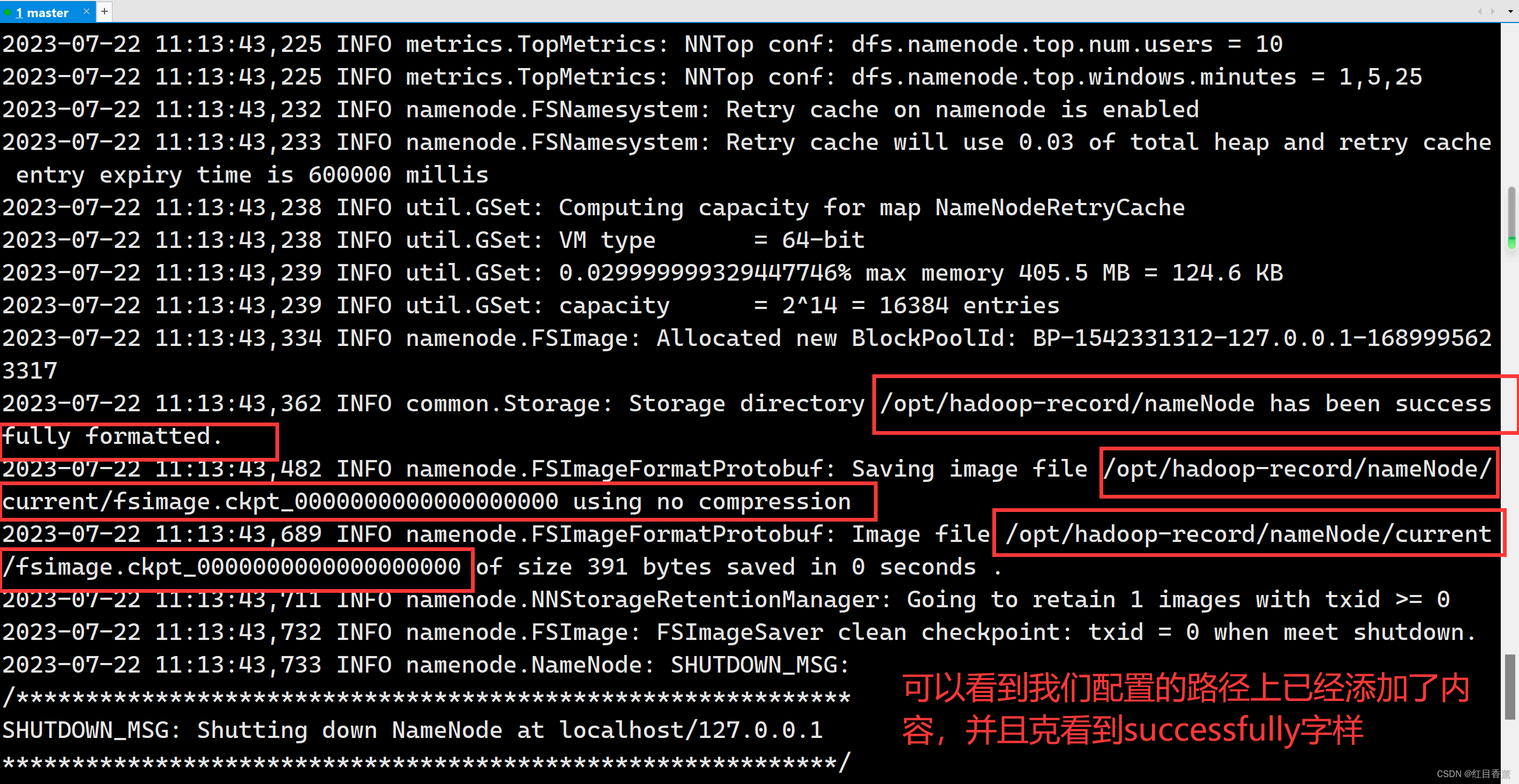
hadoop初始化配置
hdfs namenode -format
这里需要等一会。
![]()
初始化完毕。
启动Hadoop服务
start-all.sh
jps

![]()
访问服务
访问的方式是【ip:9870】,这里的端口号与2.7.3的50070是有区别的,别弄错。
例如:【】
如果出现访问不了是因为没有关闭防火墙【systemctl stop firewalld】
systemctl stop firewalld关闭后访问结果:

说明我们单机的这个已经配置完毕了,后面一主二从的配置也是依托于这种方式,无非就是改一下主从之间关系的配置。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)