Python实战项目2——自动获取酷狗音乐工具

【摘要】 准备win11pycharmEdge浏览器有了第一个自动获取小说工具项目的经历,今天这个会容易许多。不清楚第一个项目的可以这里去阅读Python实战项目1——自动获取小说工具开始首先打开浏览器,搜素酷狗音乐。接下来我们搜索一首歌,以一首《大鱼》为例,大家根据需求,喜欢什么直接搜索即可。此时相关的音乐列表全部出现,但是现在并没有音乐。接下来点击播放按钮此时这个页面就是我们要爬取的页面,找出UR...
准备
win11
pycharm
Edge浏览器
有了第一个自动获取小说工具项目的经历,今天这个会容易许多。不清楚第一个项目的可以这里去阅读Python实战项目1——自动获取小说工具
首先打开浏览器,搜素酷狗音乐。
接下来我们搜索一首歌,以一首《大鱼》为例,大家根据需求,喜欢什么直接搜索即可。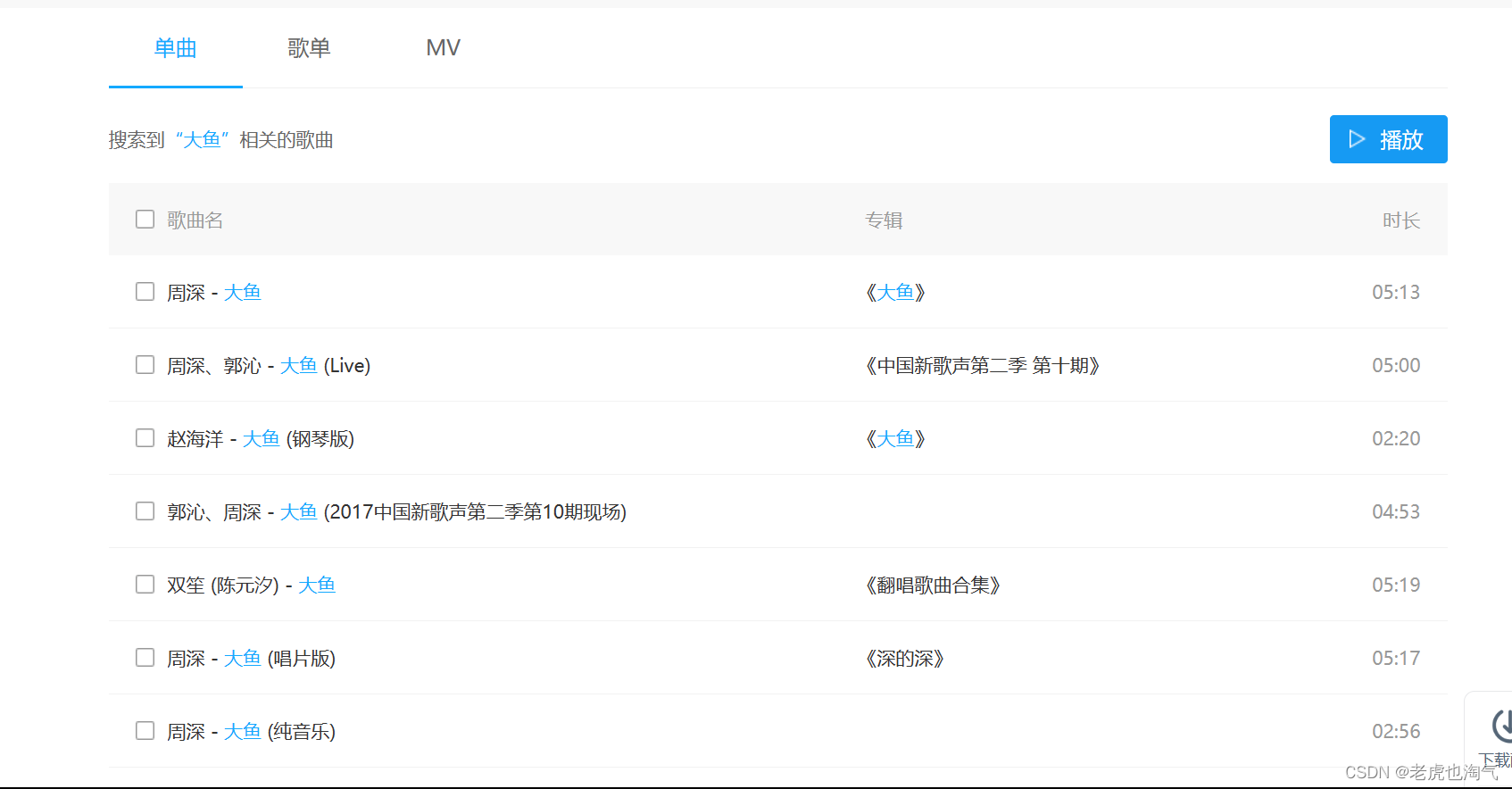
此时相关的音乐列表全部出现,但是现在并没有音乐。接下来点击播放按钮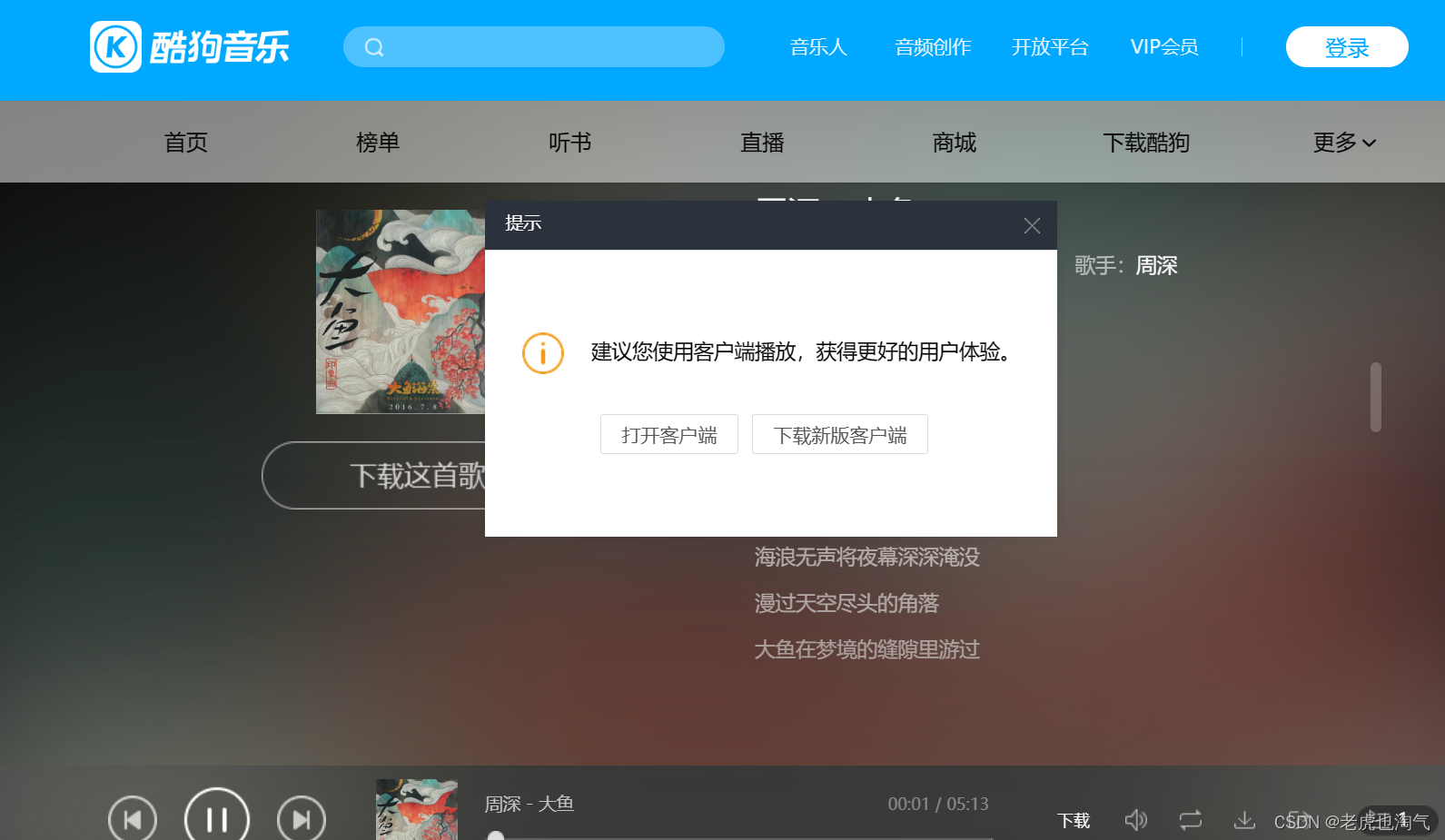
此时这个页面就是我们要爬取的页面,找出URL即可。
右键检查——网络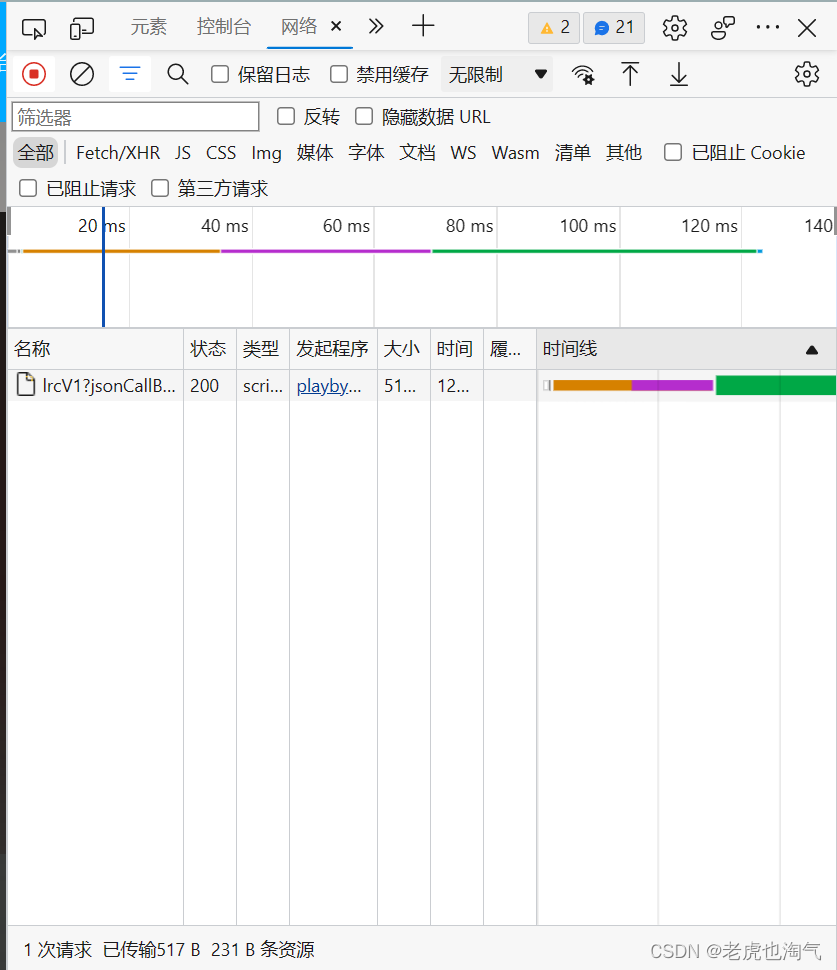
进入这个界面,这个什么意思呢,它表示的是,当我们访问这个页面需要加载的资源。点击此处清空一下,然后刷新,重新加载页面资源。
快速定位音乐位置我们直接点击媒体。正如箭头2所指:就是当前页面我们播放的音乐了。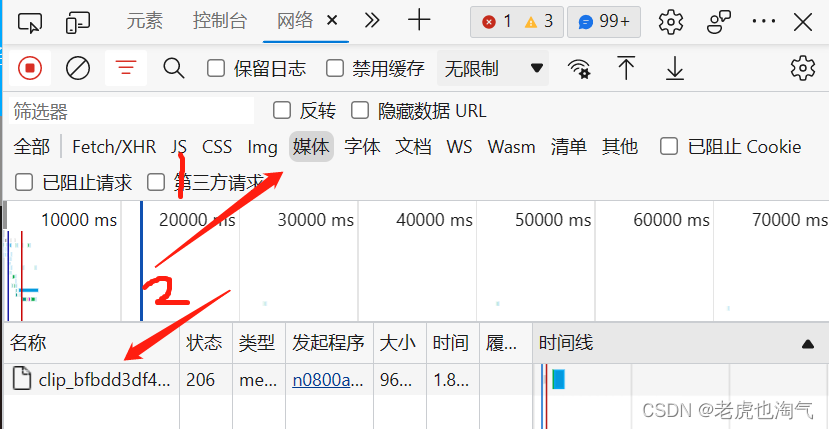
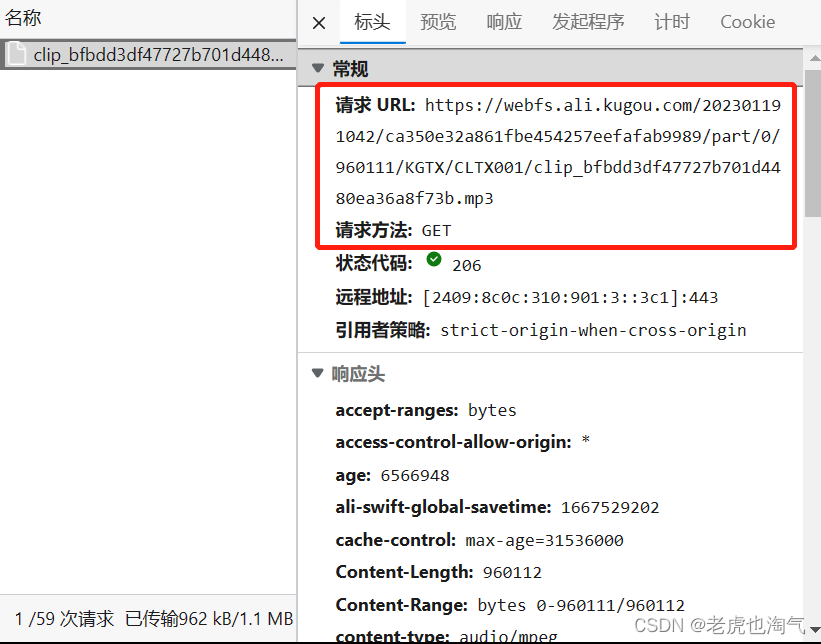
这就是我们要找的URL地址了。选中它复制,然后打开新的浏览器标签,粘贴,回车。出现以下页面说明我们成功找到。
下面开始在pycharm中编写准备代码。必不可少我们依旧需要伪装自己,不会伪装的去看上一篇文章,这里不做介绍。
# pip install requests
import requests # 发送请求的用的模块
import json
# 音乐的url地址
info_url ='https://webfs.ali.kugou.com/202301191042/ca350e32a861fbe454257eefafab9989/part/0/960111/KGTX/CLTX001/clip_bfbdd3df47727b701d4480ea36a8f73b.mp3'
# 伪装自己
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
# 发送请求到服务器,获取音乐资源
m_resp = requests.get(m_url,headers=headers)
# 服务器回应的数据--保存数据
with open('zzz.mp3','wb') as f:
f.write(m_resp.content)

运行即可下载我们的资源,做到这里肯定有人疑问。我们完全可以直接点击下载,然后还费气力写十几行代码,你是不是闲的,但是如果我们只是为了获取一首歌,这确实是大材小用了。
所以我们写代码的优势是把列表的所有音乐都下载下来,包括vip歌曲通通实现批量下载。
再次我们来到网站发现找不到MP3的URL,很明显对方进行了反爬技术,没关系我们直接搜索MP3,然后依次点击下图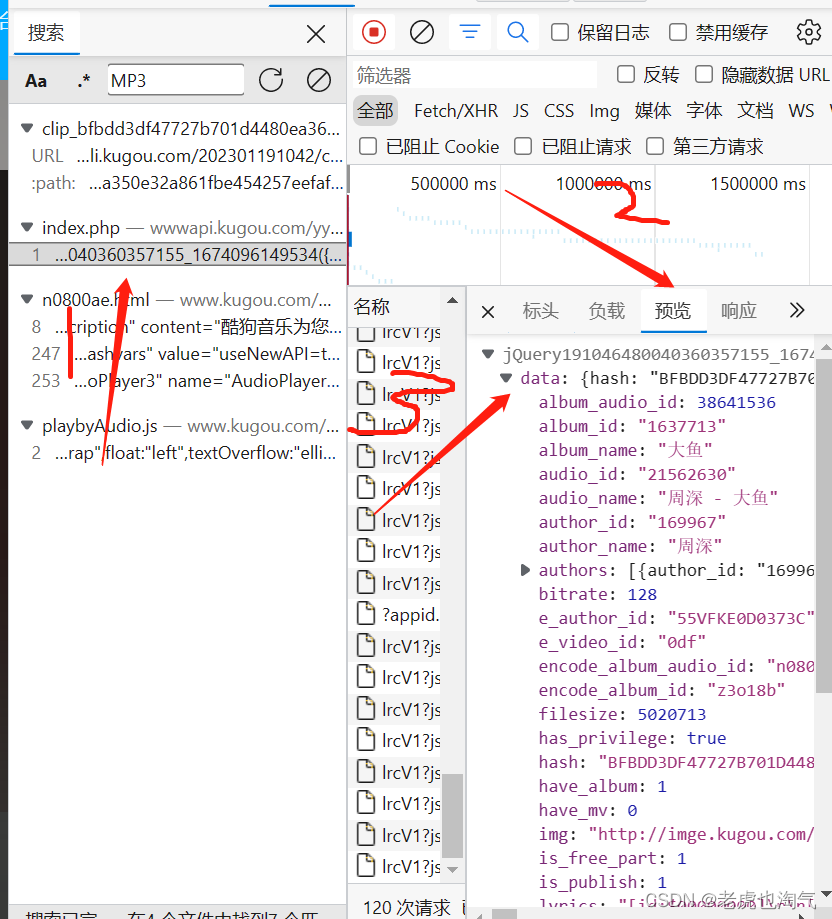
点击标头,我们可以获取音乐播放地址。选中它复制,然后打开新的浏览器标签,粘贴,回车。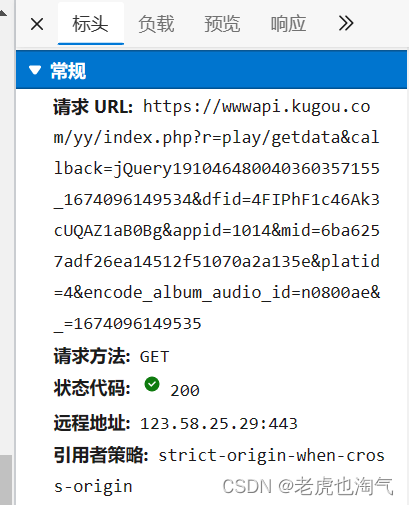
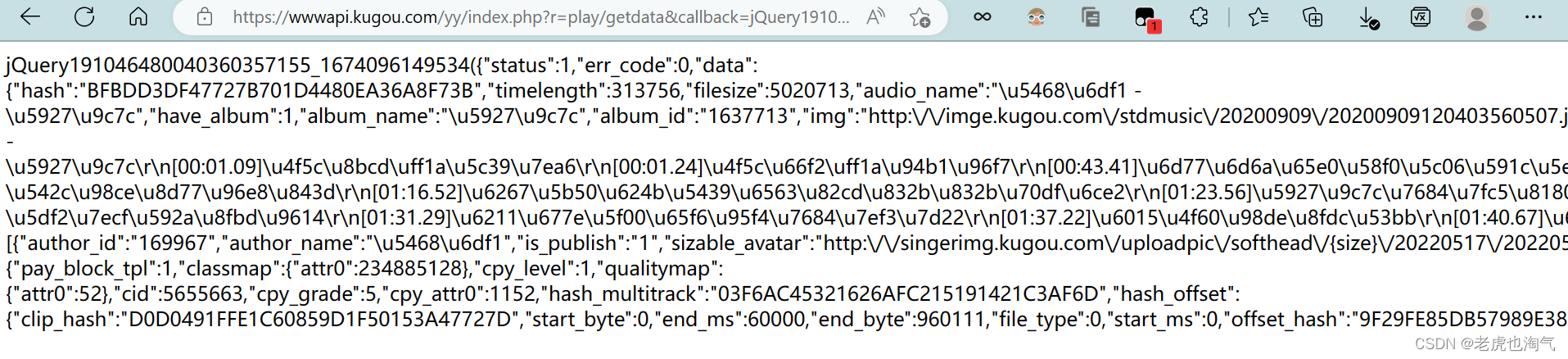
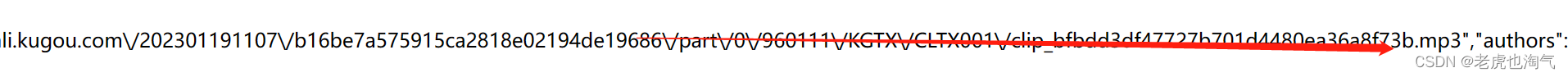
最后一行就是我们要获取的mp3地址
# 音乐信息的url
info_url =f'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery19105573930103029792_1674098129306&dfid=4FIPhF1c46Ak3cUQAZ1aB0Bg&appid=1014&mid=6ba6257adf26ea14512f51070a2a135e&platid=4&encode_album_audio_id=n0800ae&_=1674098129307'

找到hash值,然后在列表页右键检查——搜素hash值
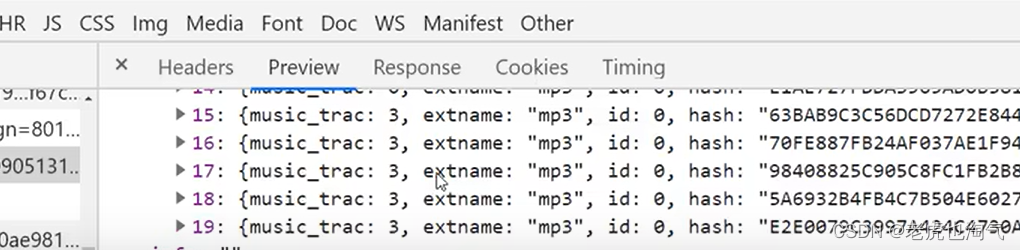
此时我们就获取一个音乐列表。此时基本完成。完整代码如下所示:
# pip install requests
import requests # 发送请求的用的模块
import json
# 伪装自己
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
# 音乐列表
list_url ='https://complexsearch.kugou.com/v2/search/song?callback=callback123&keyword=%E5%A4%A7%E9%B1%BC&page=1&pagesize=30&bitrate=0&isfuzzy=0&tag=em&inputtype=0&platform=WebFilter&userid=-1&clientver=2000&iscorrection=1&privilege_filter=0&srcappid=2919&clienttime=1599051318654&mid=1599051318654&uuid=1599051318654&dfid=-&signature=1FED2963D7BF17379D7B50F558C23A4E'
list_resp = requests.get(list_url,headers=headers)
song_list = json.loads(list_resp.text[12:-2])['data']['lists']
for i, s in enumerate(song_list):
print(f'{i+1}----{s.get("SongName")}----{s.get("FileHash")}')
num = input('请输入要下载第几首音乐:')
# 音乐信息的url
info_url =f'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash={song_list[int(num)-1].get("FileHash")}'
#
headers2={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Cookie':'kg_mid=a256175cc199d208f8ddb5e3caa0f041; kg_dfid=0QqwxT4aMAGF0vizqf0lYbwW; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1598948948,1599049820; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1599051319'
}
info_resp = requests.get(info_url,headers=headers2)
# 音乐的url地址
m_url = info_resp.json()['data']['play_url']
# 发送请求到服务器,获取音乐资源
m_resp = requests.get(m_url,headers=headers)
# 服务器回应的数据--保存数据
with open('zzz.mp3','wb') as f:
f.write(m_resp.content)
'''
服务器响应的数据结果
.text 代表访问的数据是文字
.content代表访问的数据是多媒体文件(图片,音乐,视频,文件)
.json() 访问的文字是json类型
'''
【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)