大模型部署手记(18)Windows+JupyterLab+Nemo+Llama2+llama-index+语音对话机器人

【摘要】 大模型部署手记(18)Windows+JupyterLab+Nemo+Llama2+llama-index+语音对话机器人

最近在Nvidia上了一课:《基于 LLM 构建中文场景检索式对话机器人:Llama2+NeMo》
于是张小白很想在Windows GPU上试一试。
打开Jupyter Notebook
系统会弹出以下窗口:
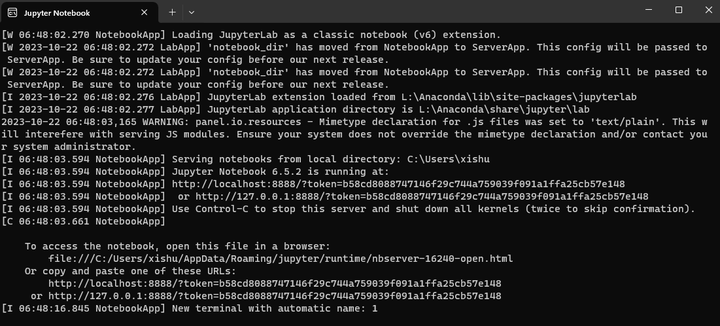
复制上面的链接:
http://127.0.0.1:8888/?token=7779a3c170bdf513646f6e631fc0ee12e7686216eedce604
在浏览器打开:
点击New-》Terminal:

在弹出的窗口中输入conda env list
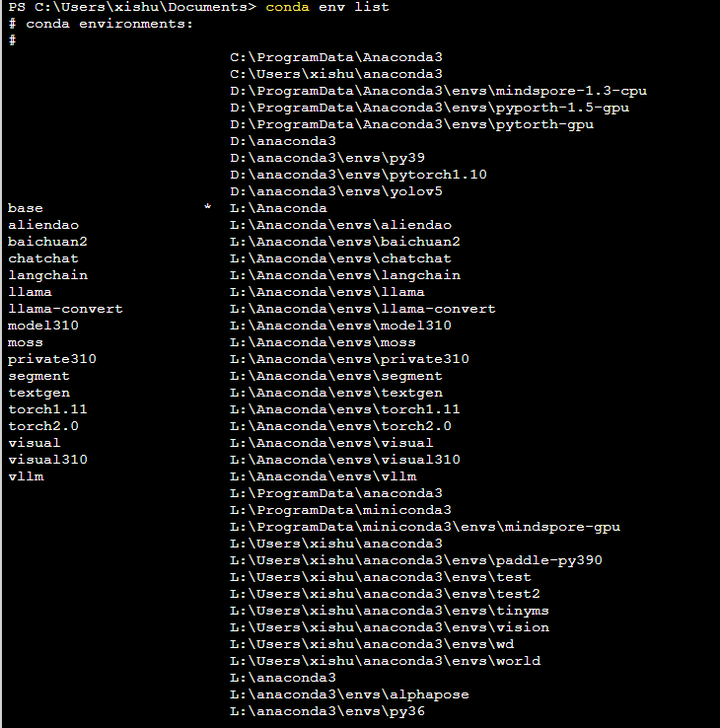
可以看到前面玩转大模型使用的conda环境清单。
new一个notebook:

不过这种方法貌似不好使用conda环境。
换一种方式:
打开 Anaconda Powershell Prompt 创建一个conda环境
conda create -n nemo python=3.10 -y
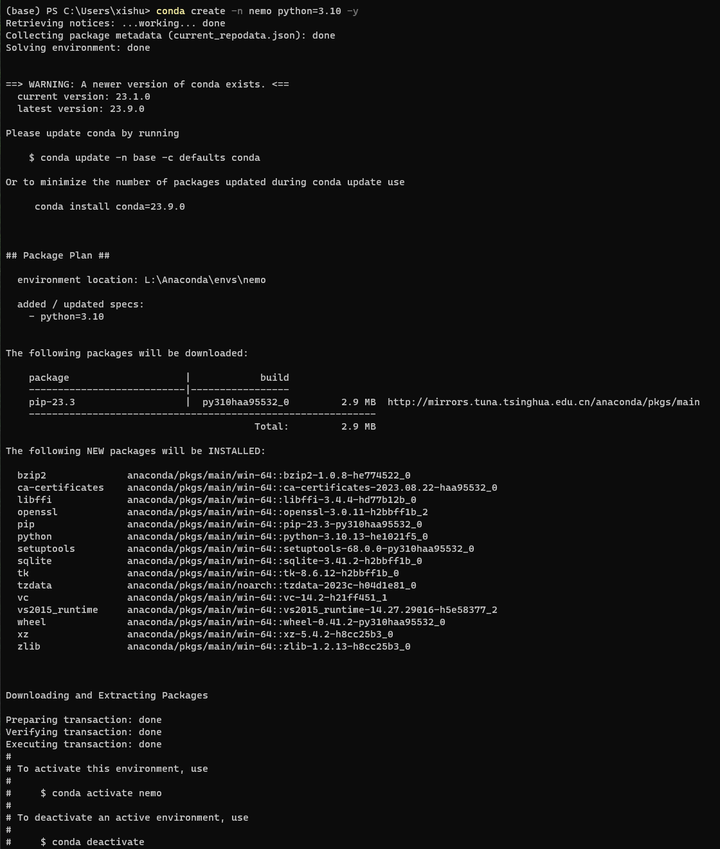
conda activate nemo

安装Pytorch:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
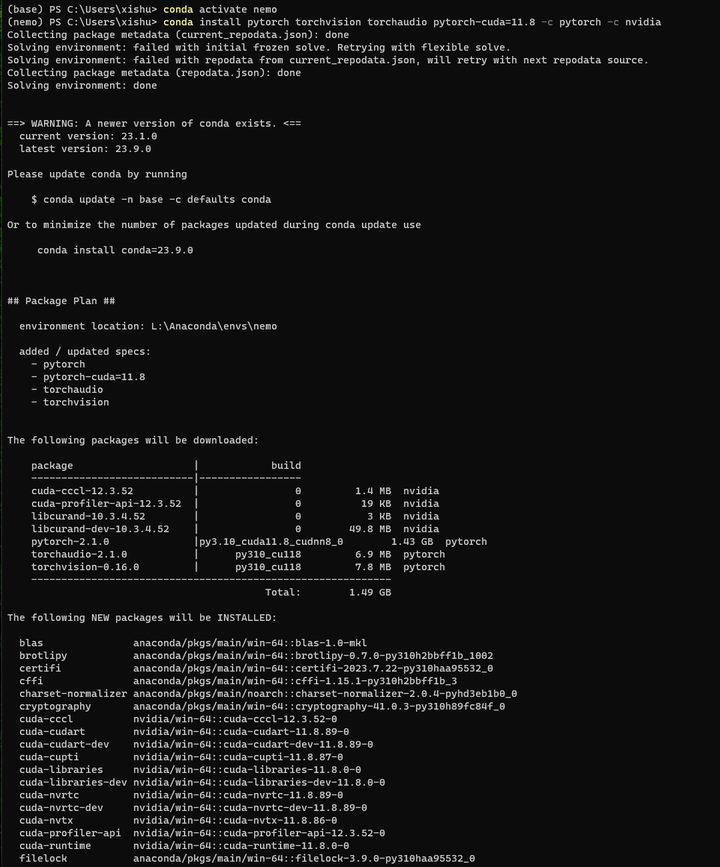
安装Nemo:
#apt-get update && apt-get install -y libsndfile1 ffmpeg pip install Cython
pip install nemo_toolkit['all']
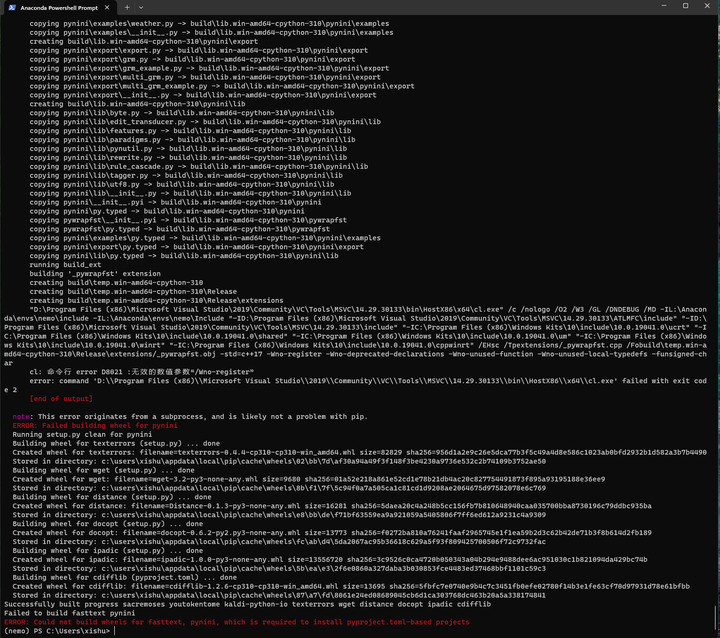
经过漫长的等待和重试之后:
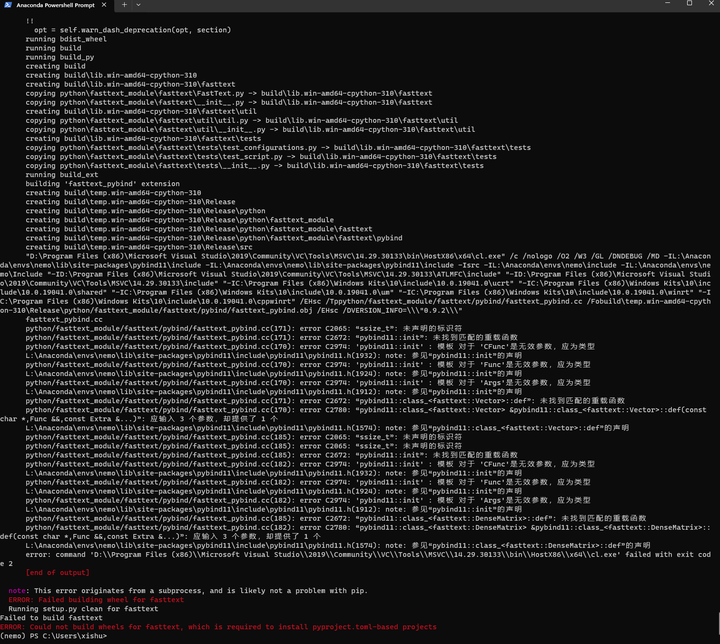
pip install fasttext
打开 https://www.lfd.uci.edu/~gohlke/pythonlibs/
搜索fasttext:
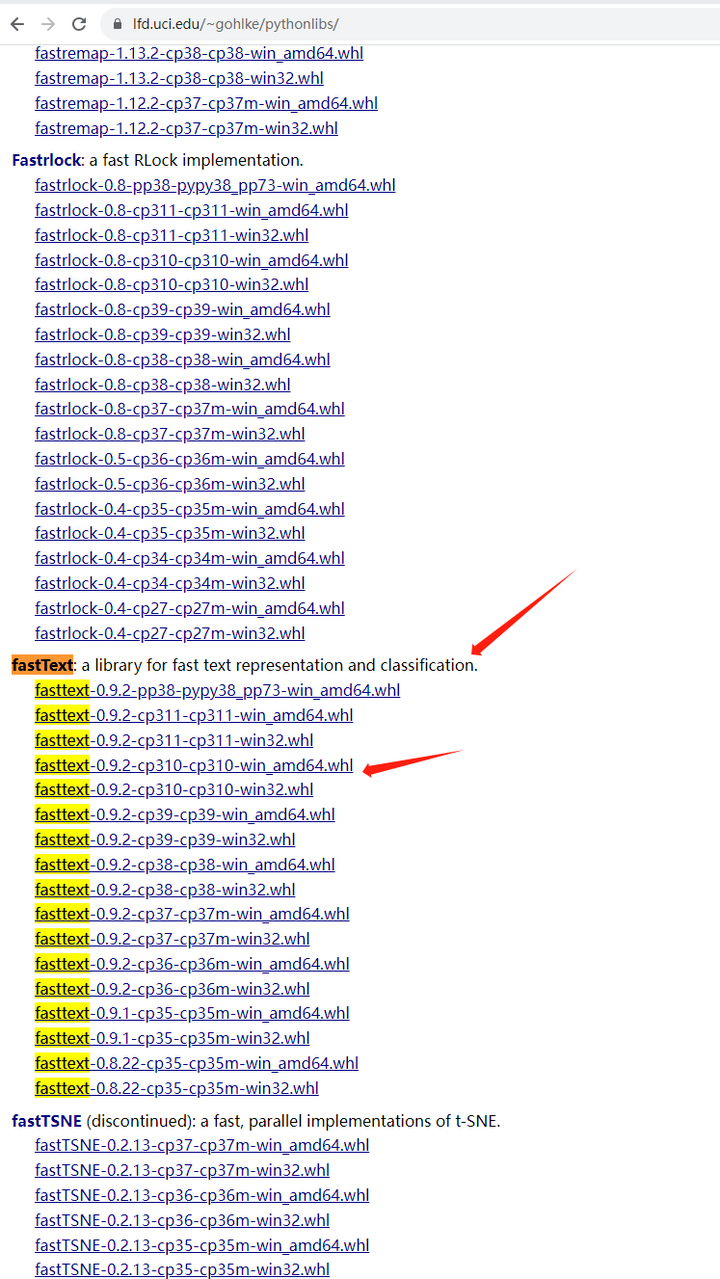
下载python 3.10的win64的版本:fasttext-0.9.2-cp310-cp310-win_amd64.whl

C:\Users\xishu\Downloads
pip install ./fasttext-0.9.2-cp310-cp310-win_amd64.whl

重试:
pip install nemo_toolkit['all']
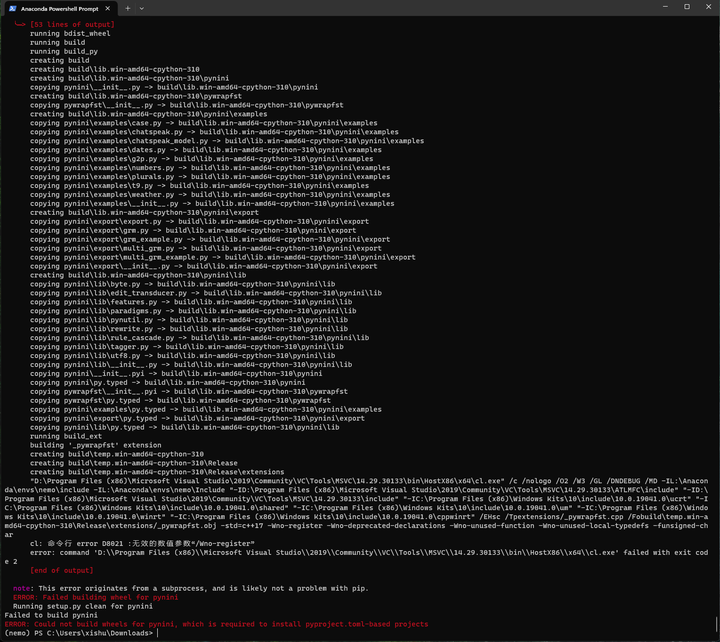
看看第二个pynini在刚才那个链接有没有呢?
并没有。
conda install -c conda-forge pynini
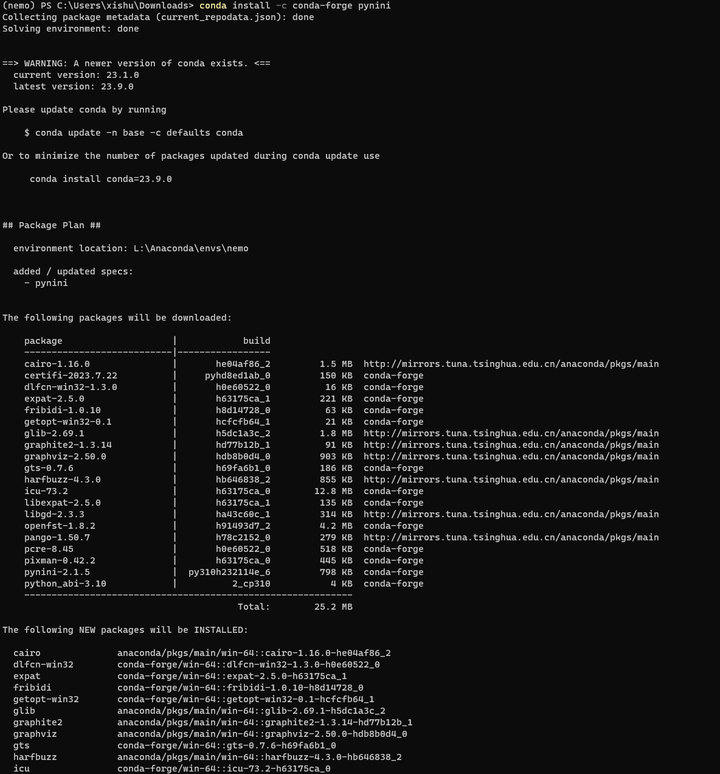
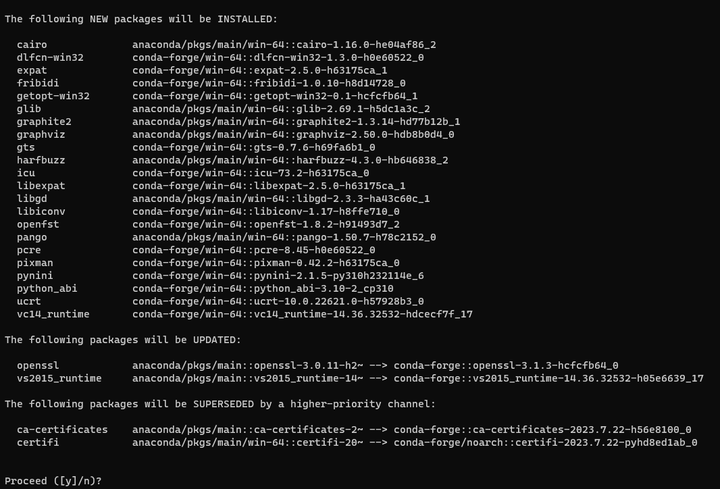
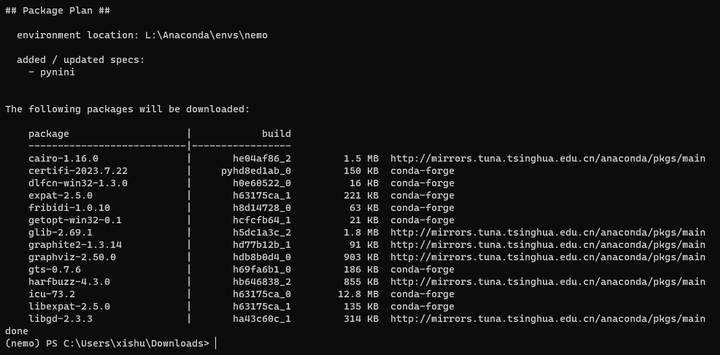
重试:
pip install nemo_toolkit['all']
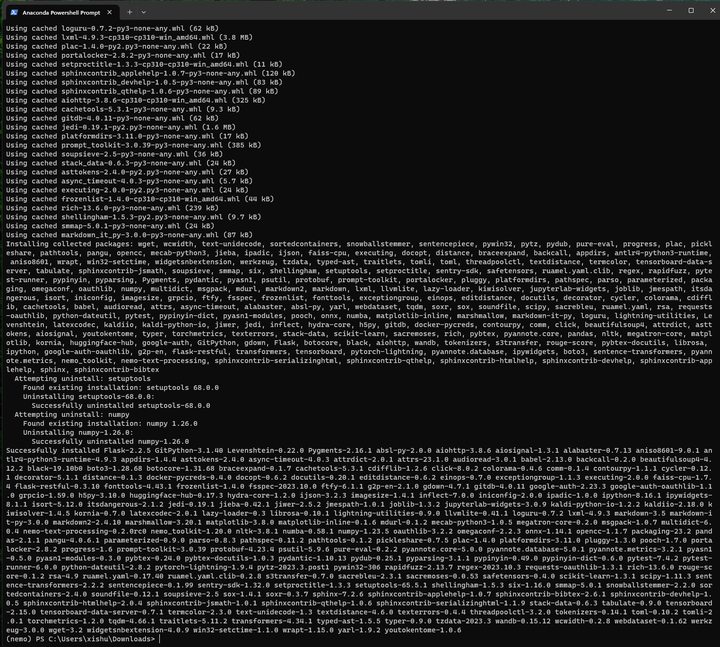
世上无难事,只怕有心人。
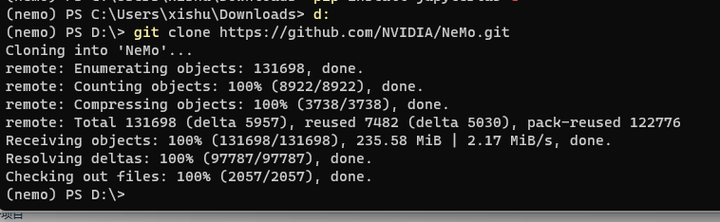
下载Nemo代码仓:
d:
cd \
git clone https://github.com/NVIDIA/NeMo.git
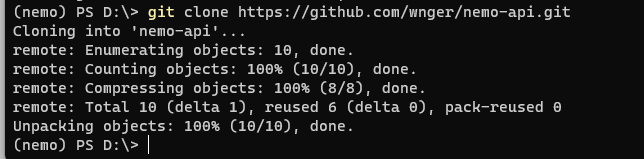
查看Nemo是否安装成功:
git clone https://github.com/wnger/nemo-api.git
cd nemo-api
python test.py

看样子是可以的。
安装llama-index
pip install llama-index
创建d:\nemo-llama目录,将 讲座的notebook文件和讲义存到该目录:

安装下jupyterLab
pip install jupyter
pip install jupyterlab

好像这步没装啥。。。
切换到nemo-llama目录,运行:
jupyter lab --no-browser
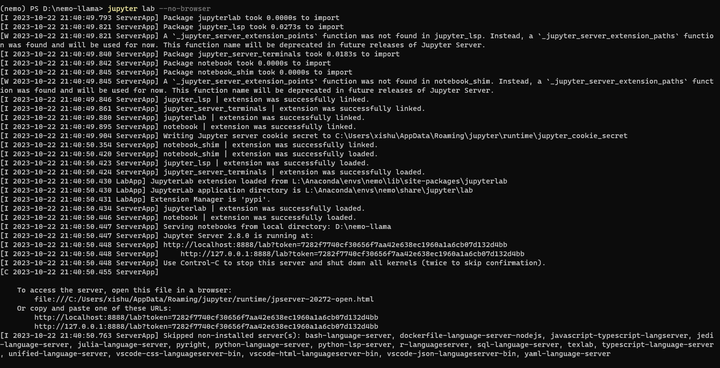
浏览器打开终端显示的地址: http://127.0.0.1:8888/lab?token=7282f7740cf30656f7aa42e638ec1960a1a6cb07d132d4bb
点击Notebook
python -V
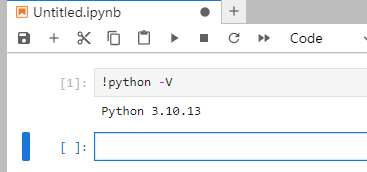
双击打开左边的notebook文件:nemo_llama2.ipynb
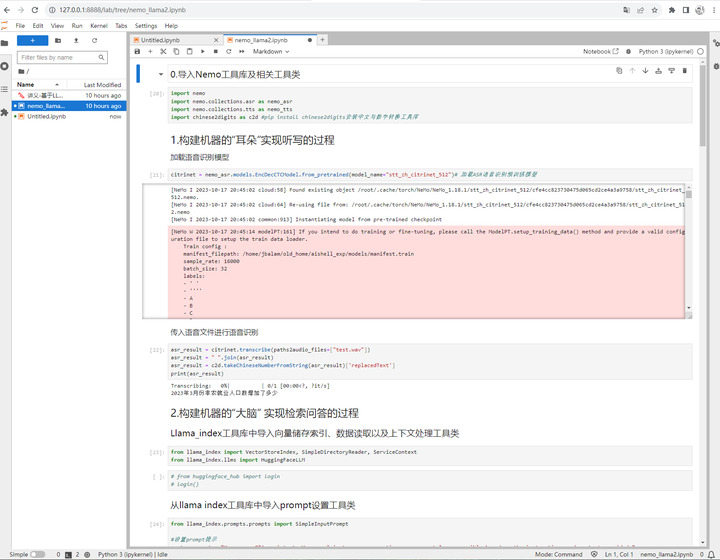
依次执行notebook的cell:导入Nemo工具库及相关工具类
缺包:
增加一个cell安装这个包:!pip install chinese2digits
再来:导入Nemo工具库及相关工具类

成功了。
执行下一个cell:加载语音识别模型

还好这个模型只是从nvidia下载而不是从Huggingface.co下载。
耐心等待下载完毕。
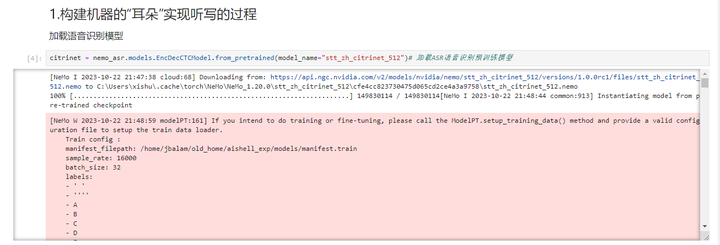
运行成功。
用录音机录一段话:
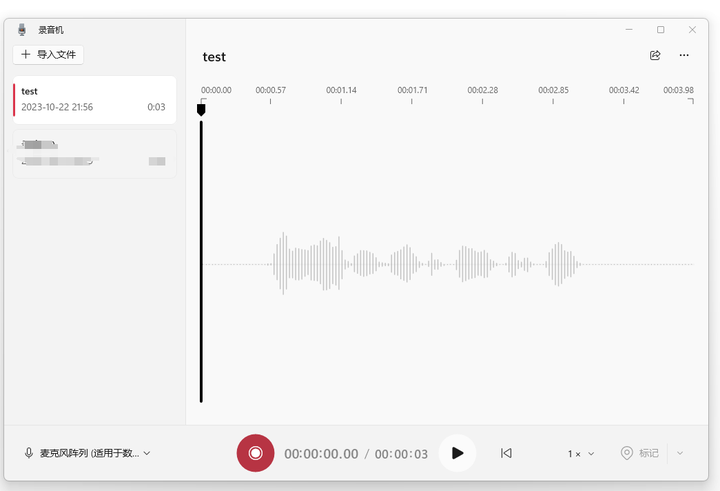
打开文件夹:
这时保存的文件是 test.m4a格式。
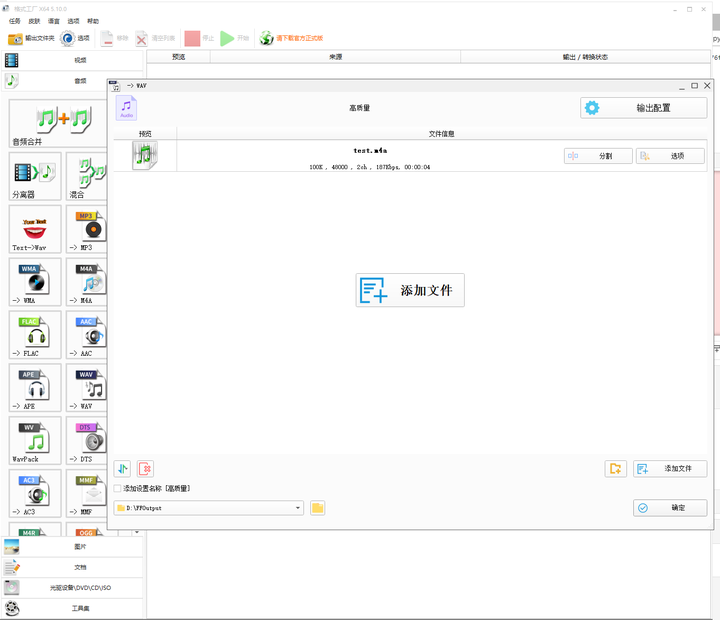
使用格式工厂将其转为wav格式:
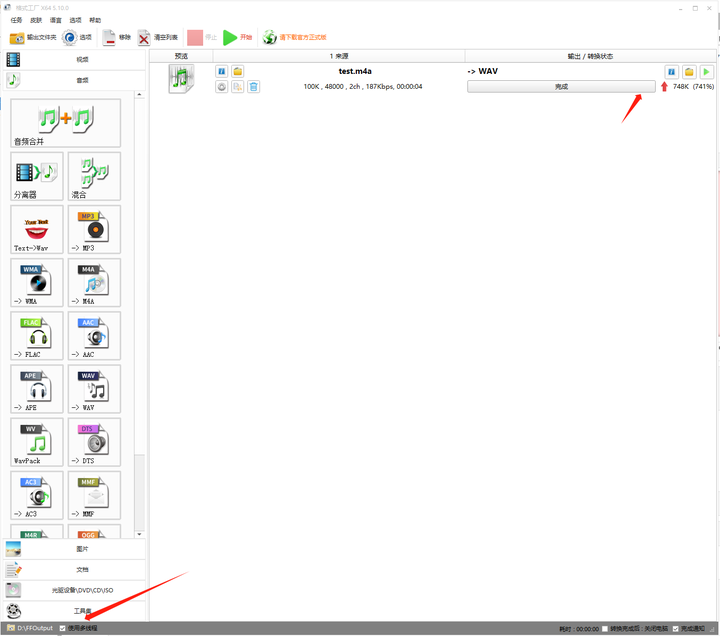
将转换好的文件复制到 d:\nemo-llama目录下:
执行下一个cell:传入语音文件进行语音识别
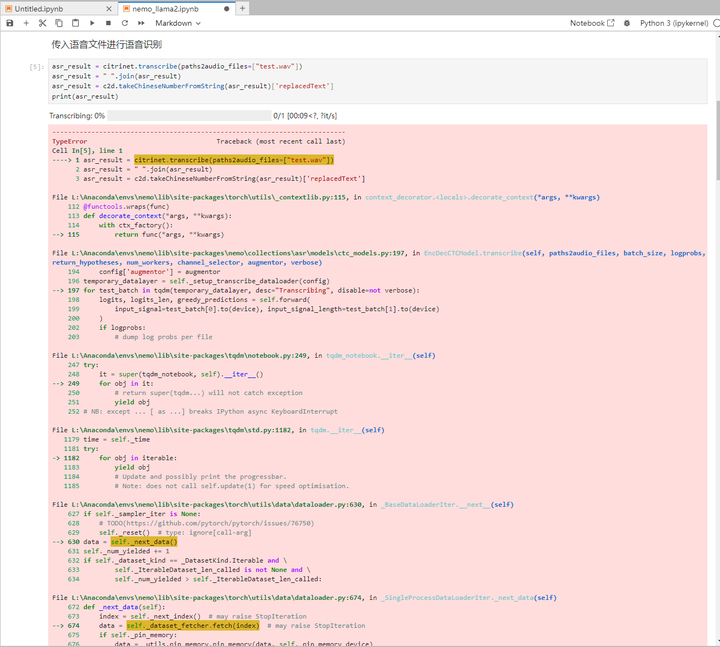
经过咨询专家:
格式转换的时候,需要设置成 单声道输出:
转换成功后,将test.wav文件传到 D:\nemo-llama 目录。
重新执行:
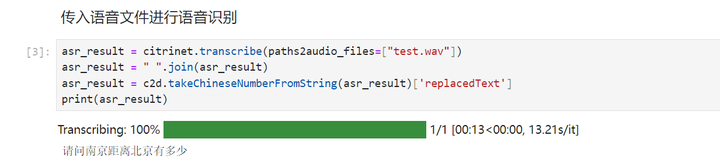
执行下一个cell:Llama_index工具库中导入向量储存索引、数据读取以及上下文处理工具类

执行下一个cell:从llama index工具库中导入prompt设置工具类

在执行下一个cell之前,先去Huggingface下载 LinkSoul/Chinese-Llama-2-7b 模型:
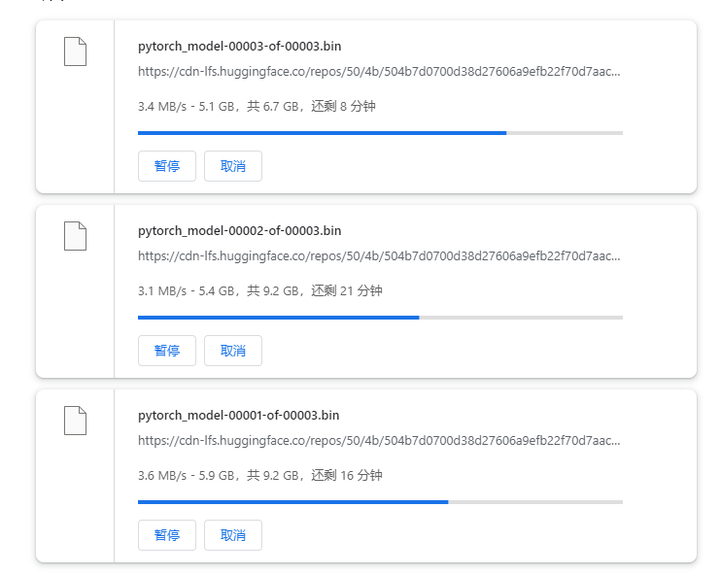
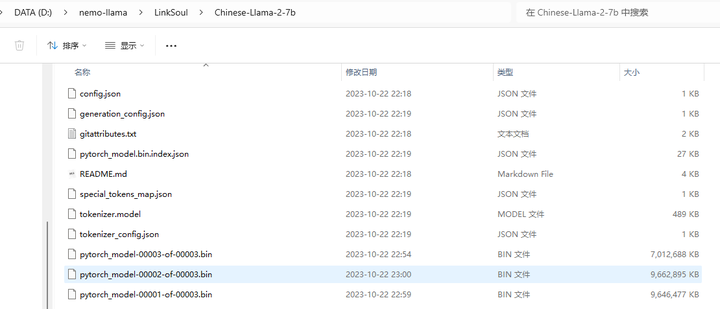
下载完的模型保存在 D:\nemo-llama\LinkSoul\Chinese-Llama-2-7b
同时下载 sentence-transformers/all-mpnet-base-v2 (此处需注意还需要下载1_Pooling子目录)
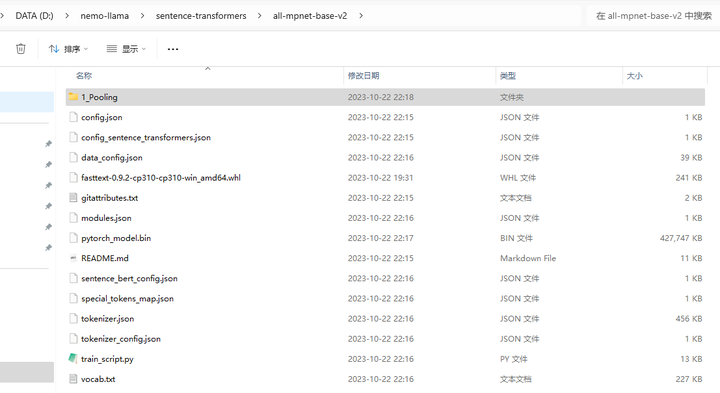
下载完的模型保存在 D:\nemo-llama\sentence-transformers\all-mpnet-base-v2
执行下一个cell:通过HuggingFaceLLM加载并设置大模型相关参数
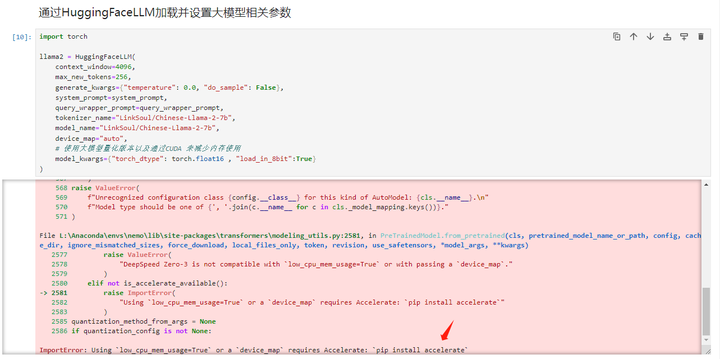
需要安装个加速包:
再来:
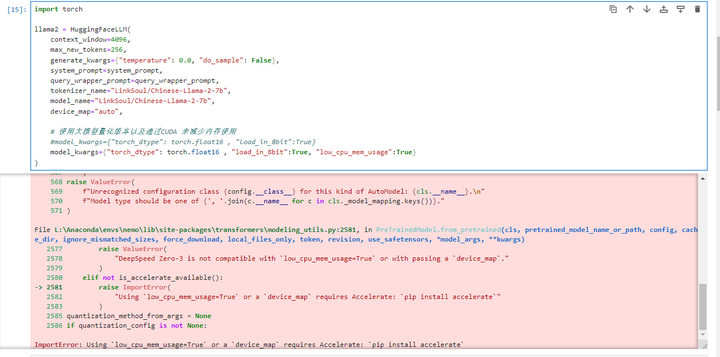
根据专家的提示,试试去掉别的参数: model_kwargs={"torch_dtype": torch.float16 }
终于加载成功!
执行下一个cell:从langchain中导入HuggingFaceEmbeddings以及从llama index中导入langchainEmbeding与serviceContext工具类

执行下一个cell:构建servicecontext服务上下文管道,用来融合大模型和向量化模型



打开一个cell,执行:
import nltk
nltk.download('punkt')

貌似网好像还是不大通畅。。
多试几次,终于成功。
重新执行这个cell:
成功了!
执行下一个cell:使用SimpleDirectoryReader读取数据
准备一本电子书,将其放入 D:\nemo-llama\book 目录·,修改路径:
documents = SimpleDirectoryReader("D:\\nemo-llama\\book").load_data()
执行:


执行下一个cell:依据数据集构建向量化索引知识库

这个执行比较长,要耐心等待执行完毕。
继续执行:

这个也得耐心等待。。。
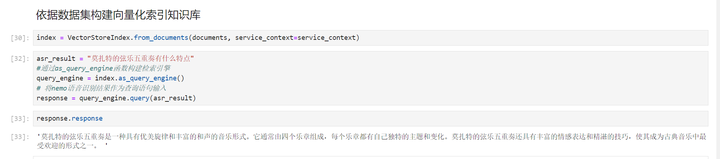
等了好半天,终于出来了。
'莫扎特的弦乐五重奏是一种具有优美旋律和丰富的和声的音乐形式。它通常由四个乐章组成,每个乐章都有自己独特的主题和变化。莫扎特的弦乐五重奏还具有丰富的情感表达和精湛的技巧,使其成为古典音乐中最受欢迎的形式之一。 '
执行下一个cell:构建机器的“嘴巴”将文字用声音说出来
执行下一个cell:加载fastpitch声学模型

耐心等待执行完毕:
执行下一个cell:通过Fastpitch声学模型将文字转换成对应频谱图
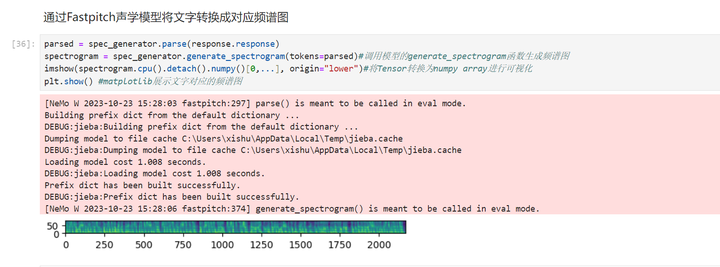
执行下一个cell:加载HiFigan声码器模型
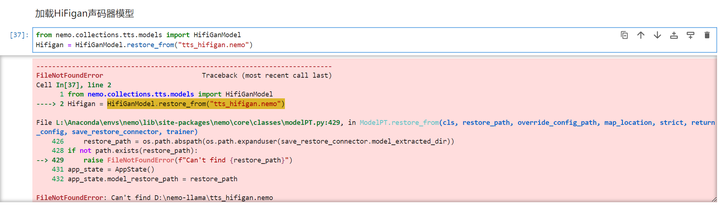
找不到这个文件,于是专家给了一个文件:
重新执行:
执行下一个cell:使用HiFigan声码器将频谱图合成出语音

执行完毕。
但是生成的语音好像有点不大对头。。
现在nemo的版本:

专家提醒,换成 nemo 1.18.1的版本试试:
重新运行:
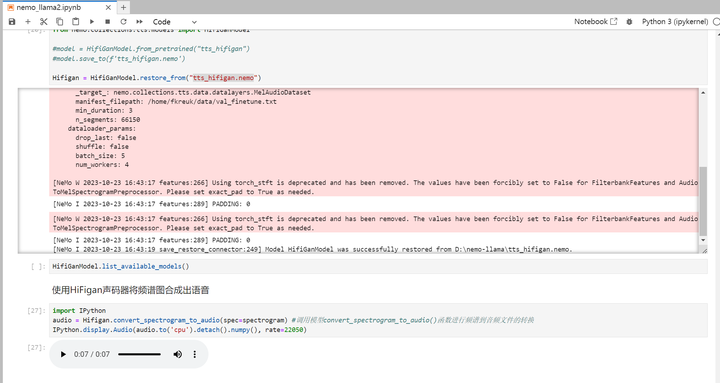
语音文件成功生成了!
另外,还需要回头重新录音,将语音改成 “莫扎特的弦乐五重奏有什么特点”并做单声道输出,然后依次执行所有cell。

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)