【自动化实战】(四)时刻关注网络安全,机器人推送每日情报及安全资讯

前言
本篇博文是 《Selenium IDE 自动化实战案例》 系列的第四篇博文,主要内容是使用 requests 库来获取情报星球社区中的每日情报及安全资讯,并通过 XPATH 语法筛选出自己需要的内容,最后设置机器人定时推送,博文中的所有代码全部收集在博主的 GitHub 仓库 中;
严正声明:本博文所讨论的技术仅用于研究学习,任何个人、团体、组织不得用于非法目的,违法犯罪必将受到法律的严厉制裁。
展示


实现
根据自己的需要获取页面内容,这里我们以获取漏洞情报、情报精选和安全资讯为例。
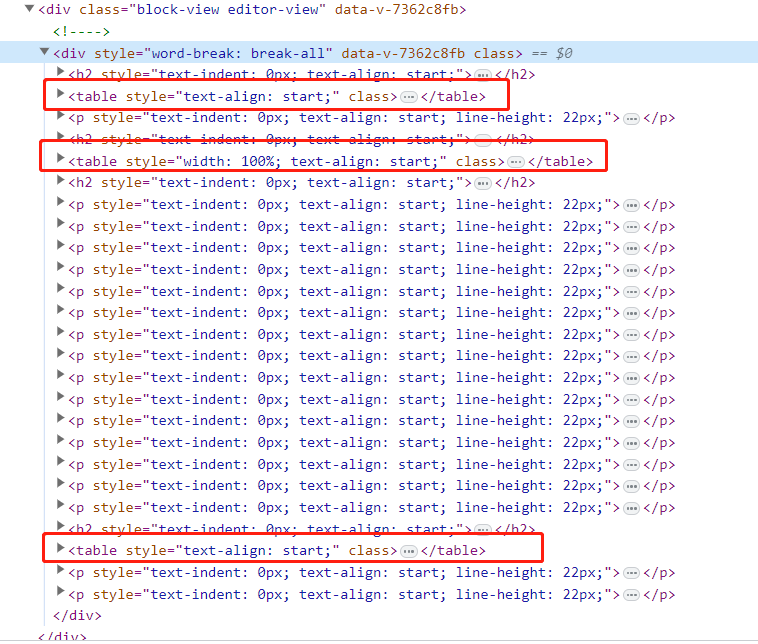
通过观察页面元素,发现我们需要获取的内容刚好在这三个 table 里面,因此,我们先通过 XPATH 语法获取到这些 <table> 标签,代码如下所示:
detail_resp = requests.get(detail_url)
detail_html = etree.HTML(detail_resp.text)
tables = detail_html.xpath('//*[@id="detail-box-view"]/div/div/table')
漏洞情报获取
先通过 F12 查看我们需要获取内容的页面元素:
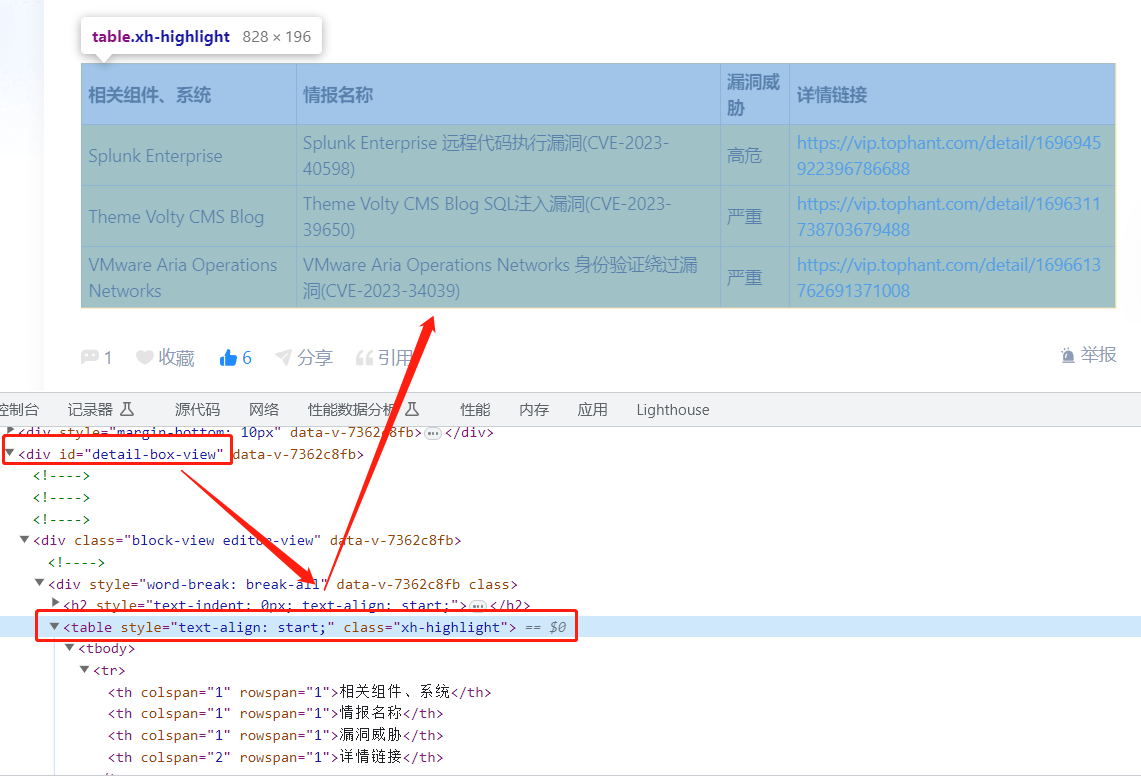
根据 DOM 元素编写相应的 XPATH 语法并进行验证:
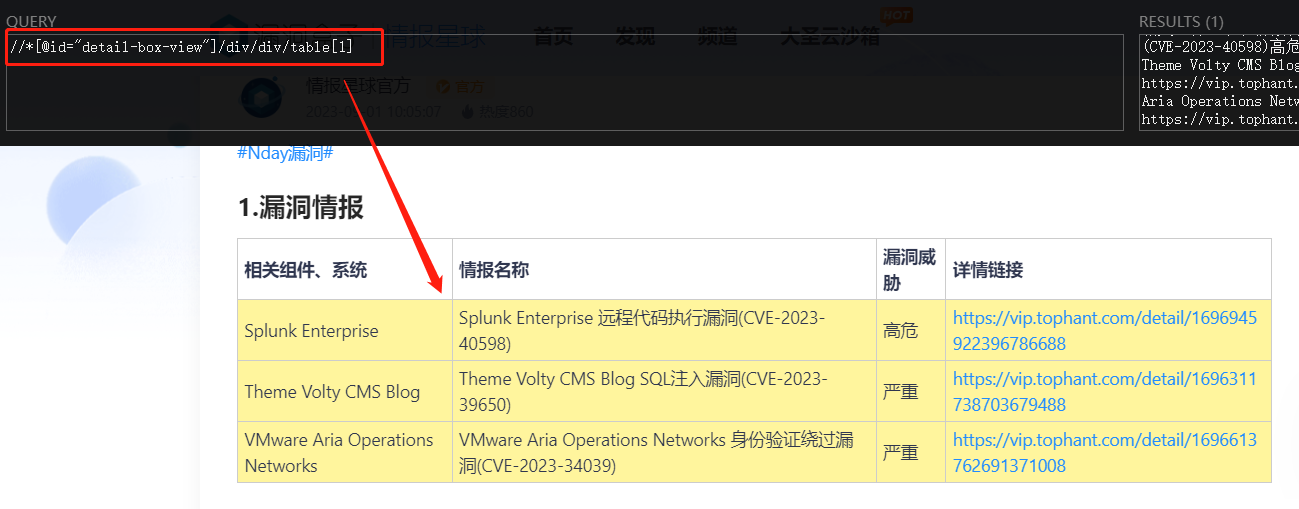
由于标题里用的是 <th> 元素,而内容里用的是 <td> 元素,因此可以使用符号 * 来匹配任何元素节点。
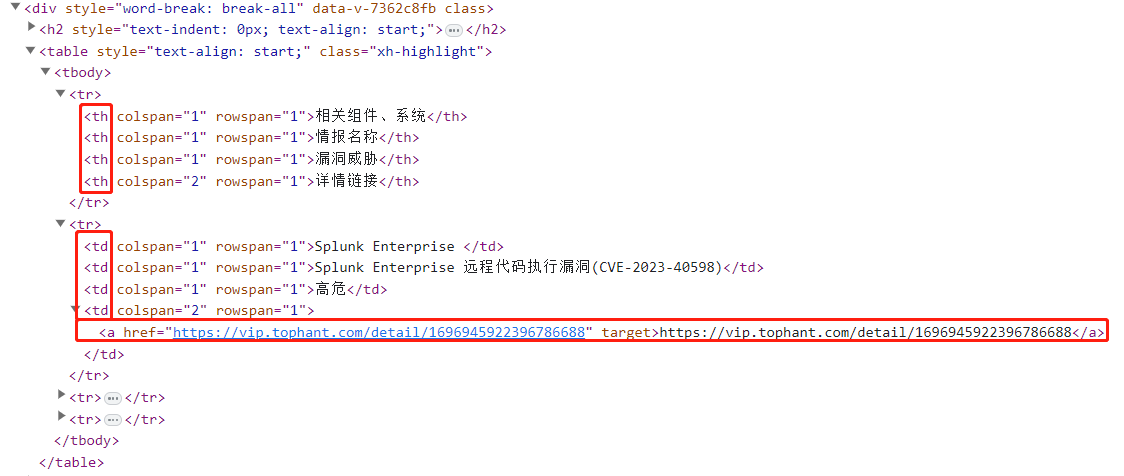
同时出现了 <a> 标签,但是其 text 内容包含了 URL,因此可以不用去获取其 href 属性,代码如下所示:
table0 = tables[0]
trs0 = table0.xpath('tbody/tr')
for tr in trs0:
print("[1]", tr.xpath('*/text() | */a/@href'))
print("[2]", tr.xpath('.//text()'))
在上述代码中,[1] 是从 href 属性中获取的 URL,而 [2] 则是通过文本匹配进行获取,运行结果如下所示:

情报精选获取
先分析一下这一模块的页面元素:
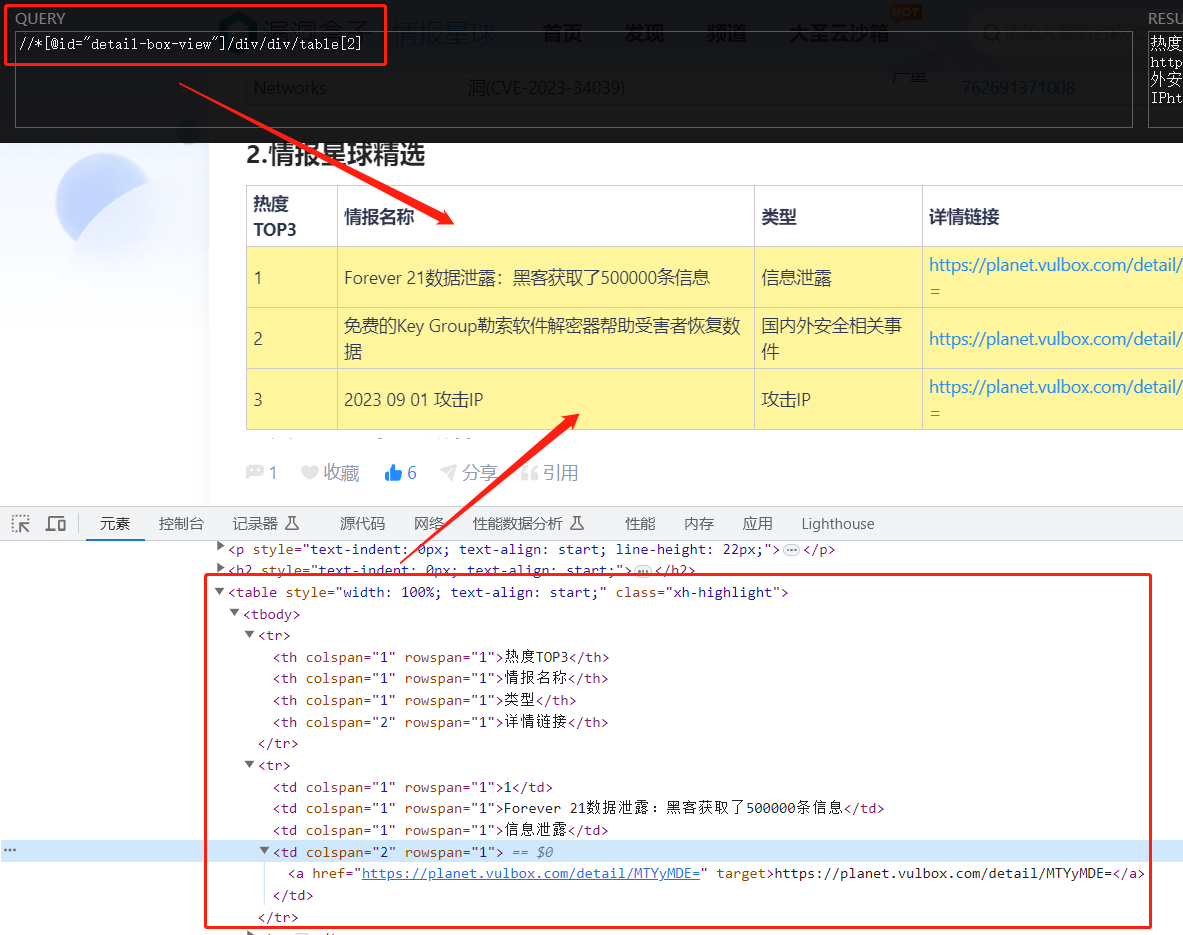
发现与漏洞情报的页面元素类似,因此直接构造代码如下所示:
table1 = tables[1]
trs1 = table1.xpath('tbody/tr')
for tr in trs1:
if first:
first = False
continue
lst = tr.xpath('.//text()')
print(lst)
运行结果:

安全资讯获取
虽然这个 table 与之前的看着有点不太一样,但是也可以通过 .//text() 去匹配其中的内容:
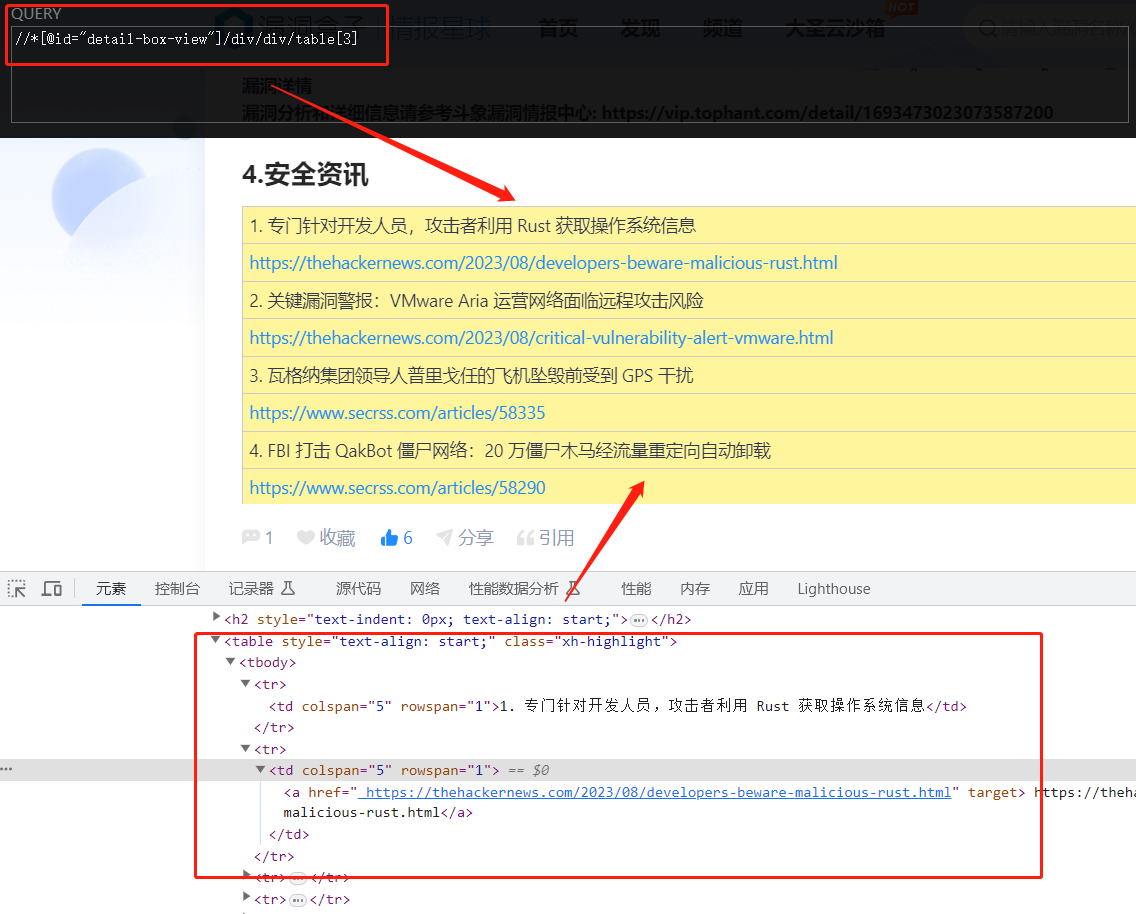
代码如下所示:
table2 = tables[2]
trs2 = table2.xpath('tbody/tr')
for tr in trs2:
lst = tr.xpath('.//text()')
print(lst)
运行结果:
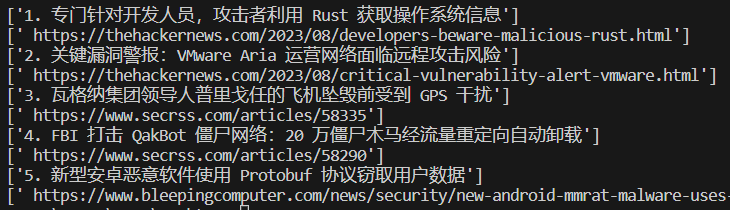
后记
通过使用 requests 库,我们成功地获取到了情报星球社区中的每日情报及安全资讯详情页,再继续分析其中的页面元素并且使用 XPATH 语法筛选出自己需要的内容,最后设置机器人定时推送相关内容。
文中每日情报及安全资讯内容来自于 情报星球 社区。
以上就是 时刻关注网络安全,机器人推送每日情报及安全资讯 的所有内容了,希望本篇博文对大家有所帮助!
严正声明:本博文所讨论的技术仅用于研究学习,任何个人、团体、组织不得用于非法目的,违法犯罪必将受到法律的严厉制裁。
💖 我是 𝓼𝓲𝓭𝓲𝓸𝓽,期待你的关注,创作不易,请多多支持;
👍 公众号:sidiot的技术驿站;

- 点赞
- 收藏
- 关注作者
评论(0)