汽车分析,随时间变化的燃油效率

【摘要】 简述今天我们来分析一个汽车数据。数据集由以下列组成:名称:每辆汽车的唯一标识符。MPG:燃油效率,以英里/加仑为单位。气缸数:发动机中的气缸数。排量:发动机排量,表示其大小或容量。马力:发动机的功率输出。重量:汽车的重量。加速:提高速度的能力,以秒为单位。车型年份:汽车模型的制造年份。原产地:每辆汽车的原产地国家或地区。总的来看数据内容不是很多,分析起来还是很容易的。目标这个项目的主要目标是...
简述
今天我们来分析一个汽车数据。
数据集由以下列组成:
- 名称:每辆汽车的唯一标识符。
- MPG:燃油效率,以英里/加仑为单位。
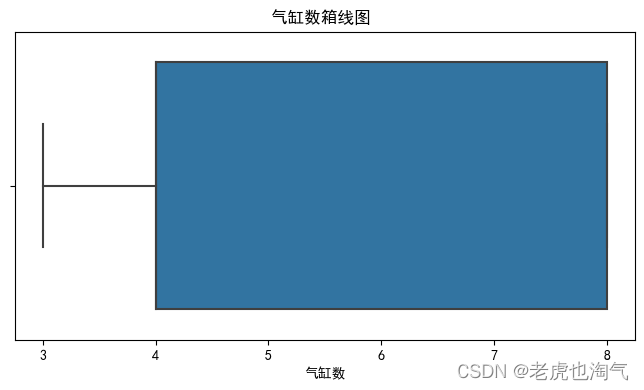
- 气缸数:发动机中的气缸数。
- 排量:发动机排量,表示其大小或容量。
- 马力:发动机的功率输出。
- 重量:汽车的重量。
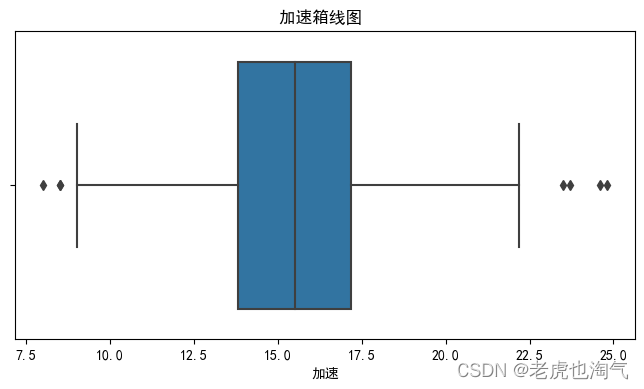
- 加速:提高速度的能力,以秒为单位。
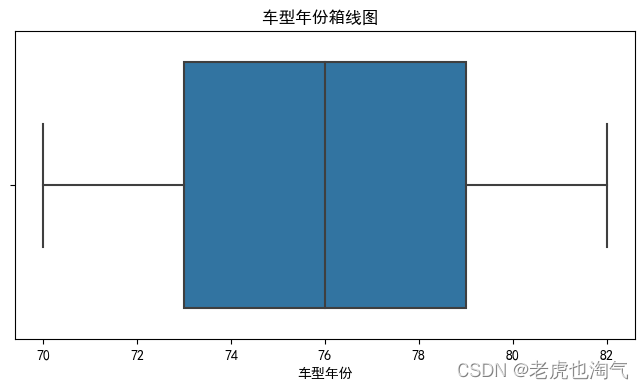
- 车型年份:汽车模型的制造年份。
- 原产地:每辆汽车的原产地国家或地区。
总的来看数据内容不是很多,分析起来还是很容易的。
这个项目的主要目标是了解汽车的不同特性之间的关系,以及它们如何影响燃油效率(MPG -每加仑英里数)。该项目还旨在发现数据中任何有趣的趋势或模式,从而为汽车行业提供见解。
# 导入库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' ## 设置中文显示
from scipy.stats import f_oneway
from scipy.stats import ttest_ind
# 导入数据
df = pd.read_csv('D:桌面\\Automobile.csv',encoding='gbk')


df['马力'] = df['马力'].fillna(df['马力'].mean())
# 数字列列表
num_cols = ['mpg', '气缸数', '排量', '马力', '重量', '加速', '车型年份']
for col in num_cols:
plt.figure(figsize=(8, 4))
sns.boxplot(df[col])
plt.title(f'{col}箱线图 ')
plt.show()

Q1_hp = df['马力'].quantile(0.25)
Q3_hp = df['马力'].quantile(0.75)
IQR_hp = Q3_hp - Q1_hp
lower_bound_hp = Q1_hp - 1.5 * IQR_hp
upper_bound_hp = Q3_hp + 1.5 * IQR_hp
df['马力'] = df['马力'].clip(lower=lower_bound_hp, upper=upper_bound_hp)
Q1_weight = df['重量'].quantile(0.25)
Q3_weight = df['重量'].quantile(0.75)
IQR_weight = Q3_weight - Q1_weight
lower_bound_weight = Q1_weight - 1.5 * IQR_weight
upper_bound_weight = Q3_weight + 1.5 * IQR_weight
df['重量'] = df['重量'].clip(lower=lower_bound_weight, upper=upper_bound_weight)
df['hp_to_weight'] = df['马力'] / df['重量']
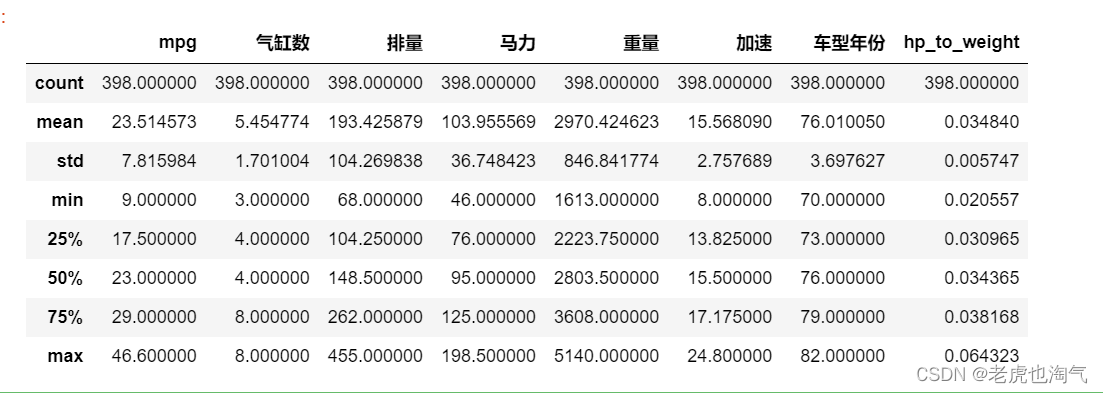
df.head()
df.describe()
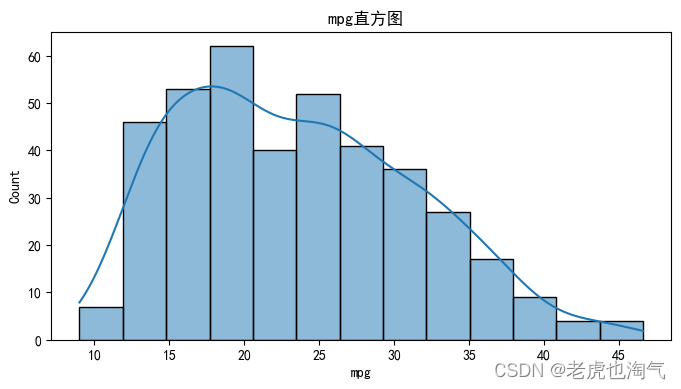
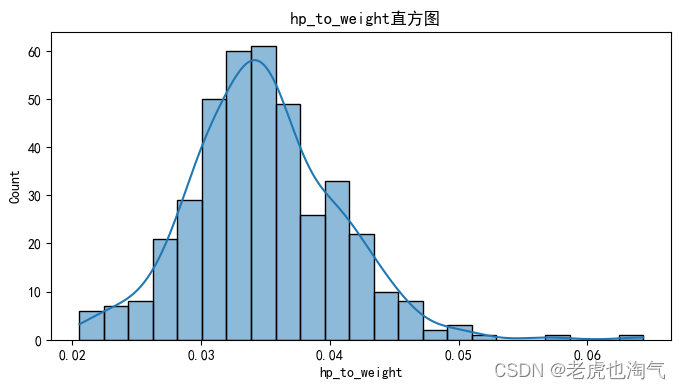
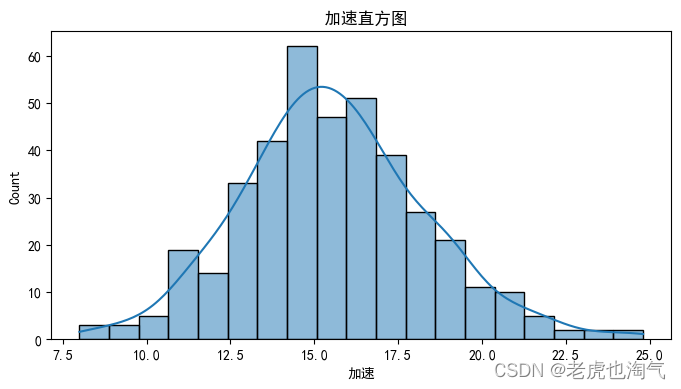
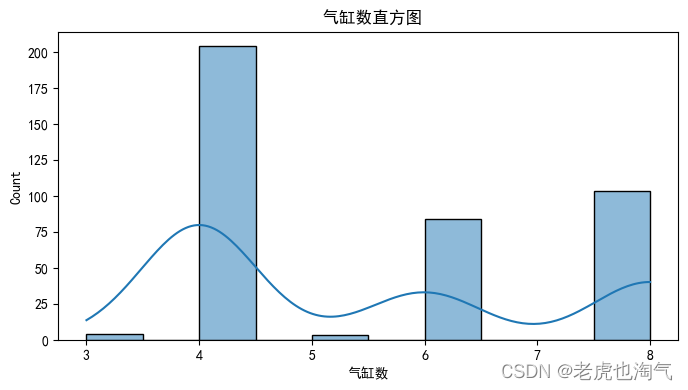
num_cols = ['mpg', '气缸数', '排量', '马力', '重量', '加速', '车型年份', 'hp_to_weight']
for col in num_cols:
plt.figure(figsize=(8, 4))
sns.histplot(df[col], kde=True)
plt.title(f' {col}直方图')
plt.show()
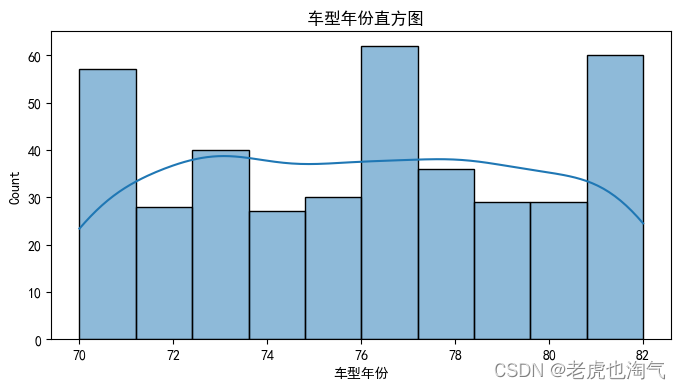
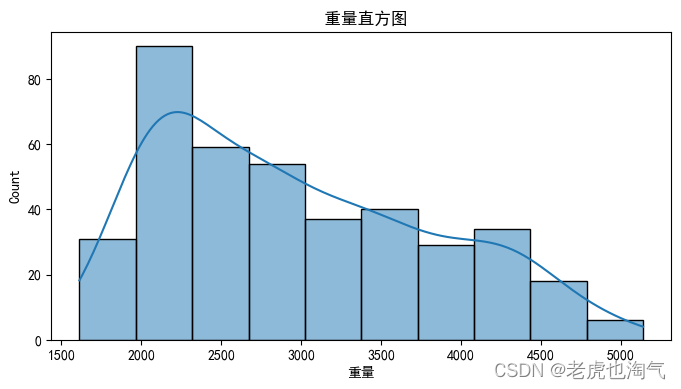
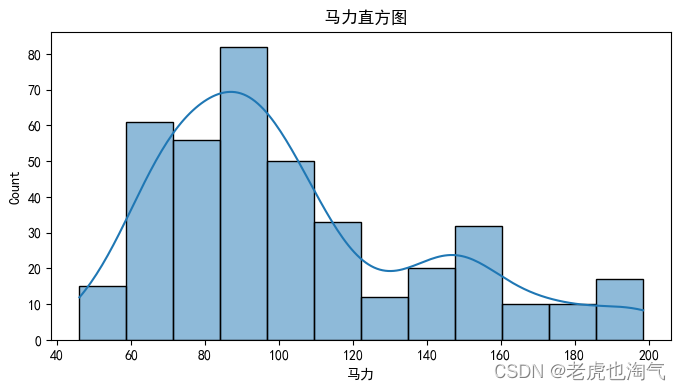
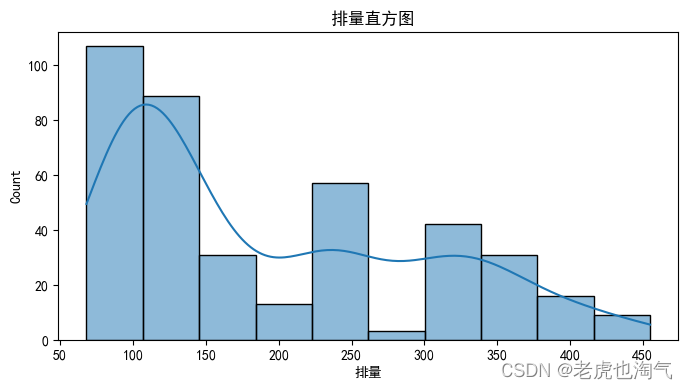
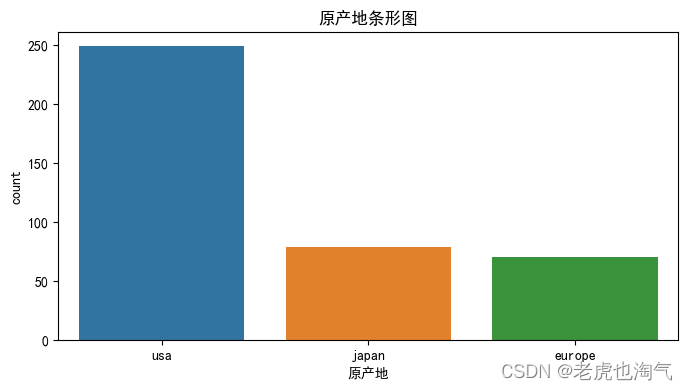
plt.figure(figsize=(8, 4))
sns.countplot(x='原产地', data=df)
plt.title('原产地条形图')
plt.show()
num_cols = ['mpg', '气缸数', '排量', '马力', '重量', '加速', '车型年份', 'hp_to_weight']
sns.pairplot(df[num_cols])
plt.show()

#计算数值变量之间的相关系数。
corr_matrix = df[num_cols].corr()
# 显示相关矩阵
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.title('数值变化的相关矩阵')
plt.show()

group1 = df[df['原产地'] == 'usa']['mpg']
group2 = df[df['原产地'] == 'europe']['mpg']
group3 = df[df['原产地'] == 'japan']['mpg']
# 进行单因素方差分析。
f_stat, p_value = f_oneway(group1, group2, group3)
# 输出 F-statistic 和 p-value
print(f'F-statistic: {f_stat}')
print(f'p-value: {p_value}')

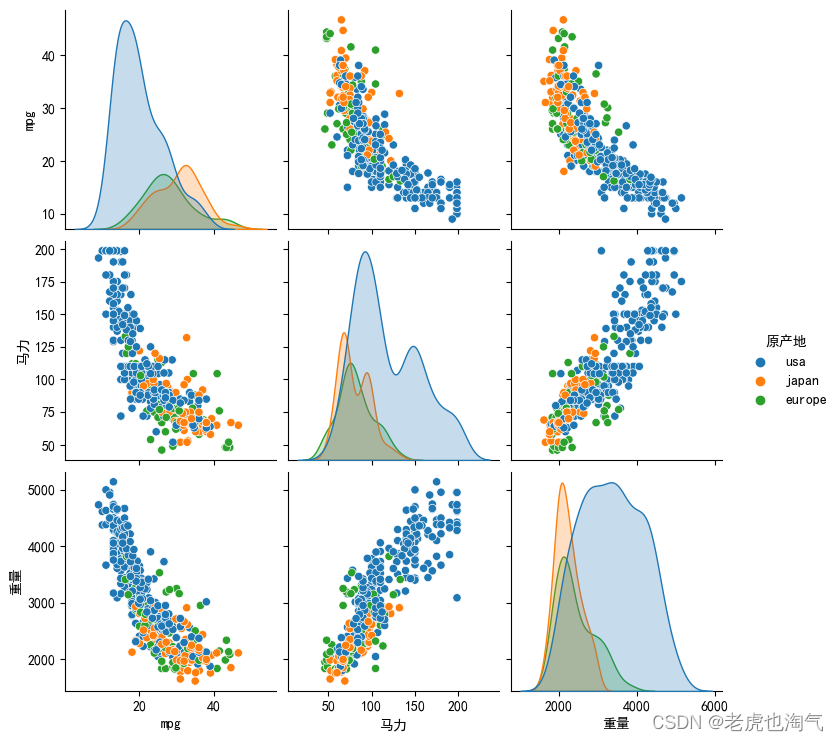
subset_cols = ['mpg', '马力', '重量', '原产地']
sns.pairplot(df[subset_cols], hue='原产地')
plt.show()
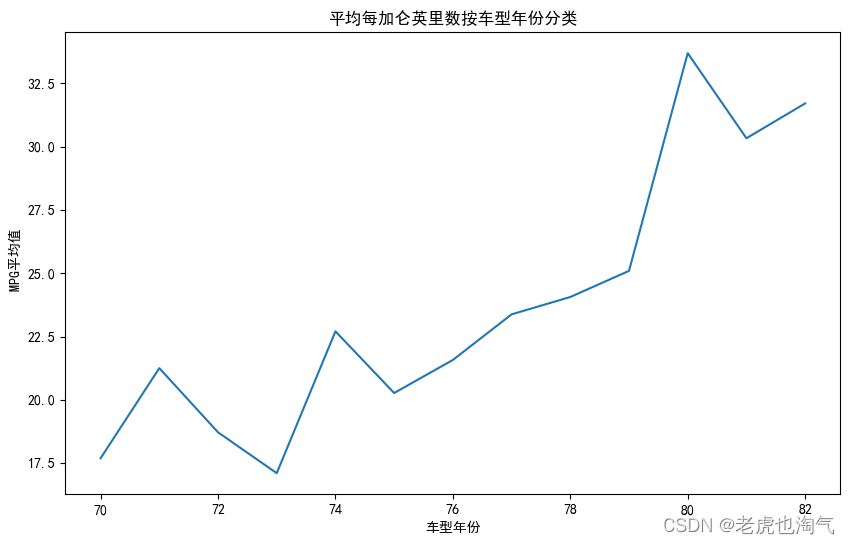
# 计算每个型号年份的平均每加仑英里数。
avg_mpg_by_year = df.groupby('车型年份')['mpg'].mean()
# 绘制随着时间变化的平均每加仑英里数。
plt.figure(figsize=(10, 6))
sns.lineplot(data=avg_mpg_by_year)
plt.title('平均每加仑英里数按车型年份分类')
plt.xlabel('车型年份')
plt.ylabel(' MPG平均值')
plt.show()
# 删除具有缺失“mpg”值的行。
df = df.dropna(subset=['mpg'])
# 将数据分成两组。
group1 = df[df['车型年份'] < 75]['mpg'] # 1975年之前制造的汽车
group2 = df[df['车型年份'] >= 75]['mpg'] # 1975年之后制造的汽车
# 进行双样本t检验。
from scipy.stats import ttest_ind
t_stat, p_value = ttest_ind(group1, group2)
# 输出 the t-statistic the p-value
print(f't-statistic: {t_stat}')
print(f'p-value: {p_value}')

随着时间的推移,燃油效率:平均每加仑英里数(mpg)似乎随着时间的推移而增加,这表明汽车变得更加省油。这可能是由于技术的进步和汽车制造业对燃油效率的日益关注。
马力和重量:马力和重量之间似乎存在正相关关系,表明较重的汽车往往拥有更强劲的发动机。然而,马力和重量似乎都与mpg负相关,这表明较重的汽车和发动机功率更大的汽车往往更省油。
产地和燃油效率:我们的假设检验表明,不同产地的汽车平均每加仑汽油行驶里程有显著差异。这表明汽车的生产地区可能会对其燃油效率产生影响。
新功能-马力重量比:我们创造的新功能,马力重量比,可能会为这些变量和mpg之间的关系提供不同的结果

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)