python之集合、序列、字典类型

【摘要】 一、集合类型及操作1、集合类型定义集合是多个元素的无序组合集合类型与数学中的集合概念一致集合元素之间无序,每个元素唯一,不存在相同元素集合元素不可更改,不能是可变数据类型集合用大括号 {} 表示,元素间用逗号分隔建立集合类型用 {} 或 set()建立空集合类型,必须使用set()>>> A = {"python", 123, ("python",123)} #使用{}建立集合{123, '...
一、集合类型及操作
集合是多个元素的无序组合
- 集合类型与数学中的集合概念一致
- 集合元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型
- 集合用大括号 {} 表示,元素间用逗号分隔
- 建立集合类型用 {} 或 set()
- 建立空集合类型,必须使用set()
>>> A = {"python", 123, ("python",123)} #使用{}建立集合
{123, 'python', ('python', 123)}
>>> B = set("pypy123") #使用set()建立集合
{'1', 'p', '2', '3', 'y'}
>>> C = {"python", 123, "python",123}
{'python', 123}



集合类型的定义
A = {“p”, “y” , 123}
B = set(“pypy123”)
A-B
{123}
A&B
{‘p’, ‘y’}
A^B
{‘2’, 123, ‘3’, ‘1’}
B-A
{‘3’, ‘1’, ‘2’}
A|B
{‘1’, ‘p’, ‘2’, ‘y’, ‘3’, 123}


>>> A = {"p"
,
"y" , 123}
>>> for item in A:
print(item, end="")
p123y
>>> A
{'p', 123, 'y'}
>>> try:
while True:
print(A.pop(), end=""))
except:
pass
p123y
>>> A
set()
包含关系比较
“p” in {“p”, “y” , 123}
True
{“p”, “y”} >= {“p”, “y” , 123}
False
数据去重:集合类型所有元素无重复
>>> ls = ["p"
,
"p"
,
"y"
,
"y", 123]
>>> s = set(ls) # 利用了集合无重复元素的特点
{'p', 'y', 123}
>>> lt = list(s) # 还可以将集合转换为列表
['p', 'y', 123]
序列是具有先后关系的一组元素
- 序列是一维元素向量,元素类型可以不同
- 类似数学元素序列: s0, s1, … , sn-1
- 元素间由序号引导,通过下标访问序列的特定元素




>>> ls = ["python", 123,
".io"]
>>> ls[::-1]
['.io', 123, 'python']
>>> s = "python123.io"
>>> s[::-1]
'oi.321nohtyp'
序列类型通用函数和方法
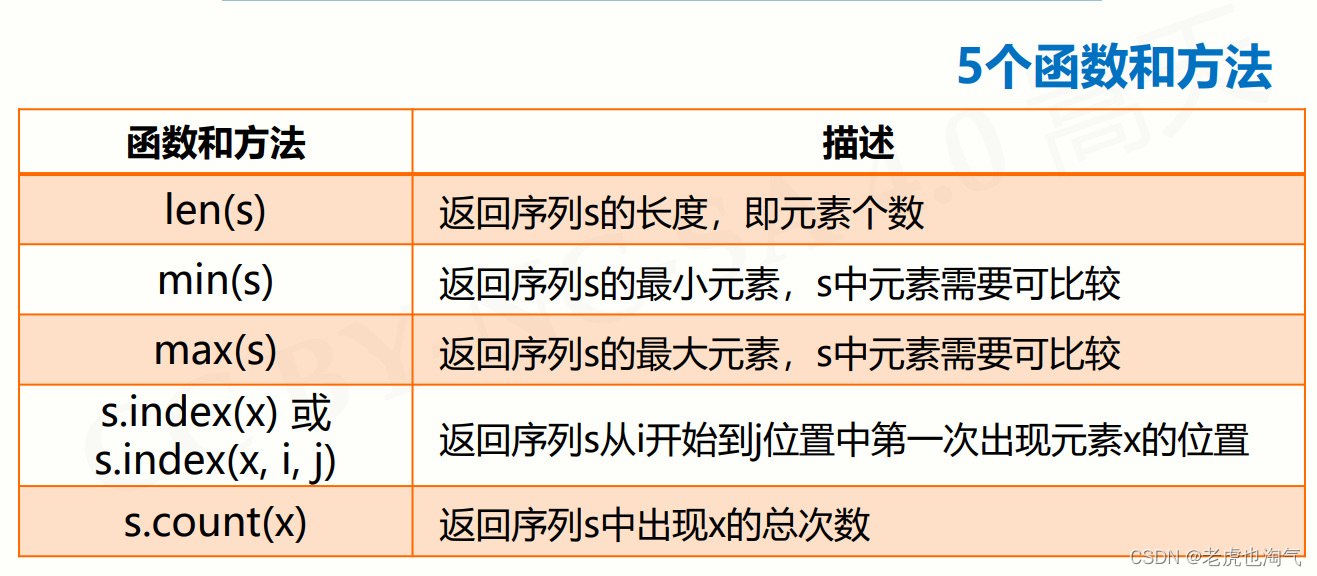
>>> ls = ["python", 123, ".io"]
>>> len(ls)
3
>>> s = "python123.io"
>>> max(s)
'y'
元组类型定义
元组是序列类型的一种扩展
- 元组是一种序列类型,一旦创建就不能被修改
- 使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
- 可以使用或不使用小括号
def func():
return 1,2
>>> creature = "cat"
,
"dog"
,
"tiger"
,
"human"
>>> creature
('cat', 'dog', 'tiger', 'human')
>>> color = (0x001100, "blue", creature)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
元组类型操作
元组继承序列类型的全部通用操作
- 元组继承了序列类型的全部通用操作
- 元组因为创建后不能修改,因此没有特殊操作
- 使用或不使用小括号
>>> creature = "cat"
,
"dog"
,
"tiger"
,
"human"
>>> creature[::-1]
('human', 'tiger', 'dog', 'cat')
>>> color = (0x001100, "blue", creature)
>>> color[-1][2]
'tiger'
列表类型定义
列表是序列类型的一种扩展,十分常用
- 列表是一种序列类型,创建后可以随意被修改
- 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔
- 列表中各元素类型可以不同,无长度限制


>>> ls = ["cat"
,
"dog"
,
"tiger"
, 1024]
>>> ls[1:2] = [1, 2, 3, 4]
['cat', 1, 2, 3, 4, 'tiger', 1024]
>>> del ls[::3]
[1, 2, 4, 'tiger']
>>> ls*2
[1, 2, 4, 'tiger', 1, 2, 4, 'tiger']

>>> ls = ["cat"
,
"dog"
,
"tiger"
, 1024]
>>> ls.append(1234)
['cat', 'dog', 'tiger', 1024, 1234]
>>> ls.insert(3, "human")
['cat', 'dog', 'tiger', 'human', 1024, 1234]
>>> ls.reverse()
[1234, 1024, 'human', 'tiger', 'dog', 'cat']



数据表示:元组 和 列表
- 元组用于元素不改变的应用场景,更多用于固定搭配场景
- 列表更加灵活,它是最常用的序列类型
- 最主要作用:表示一组有序数据,进而操作它们
元素遍历
for item in ls :
<语句块>
for item in tp :
<语句块>
数据保护
- 如果不希望数据被程序所改变,转换成元组类型
>>> ls = ["cat", "dog","tiger", 1024]
>>> lt = tuple(ls)
>>> lt
('cat', 'dog', 'tiger', 1024)
映射是一种键(索引)和值(数据)的对应
键值对:键是数据索引的扩展
字典是键值对的集合,键值对之间无序
采用大括号{}和dict()创建,键值对用冒号: 表示
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}字典类型的用法在字典变量中,通过键获得值
字典类型定义和使用






>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> "中国" in d
True
>>> d.keys()
dict_keys(['中国', '美国', '法国'])
>>> d.values()
dict_values(['北京', '华盛顿', '巴黎'])

>>> d = {"中国":"北京", "美国":"华盛顿", "法国":"巴黎"}
>>> d.get("中国","伊斯兰堡")
'北京'
>>> d.get("巴基斯坦","伊斯兰堡")
'伊斯兰堡'
>>> d.popitem()
('美国', '华盛顿')

映射的表达
- 映射无处不在,键值对无处不在
- 例如:统计数据出现的次数,数据是键,次数是值
- 最主要作用:表达键值对数据,进而操作它们
元素遍历
for k in d :
<语句块>
- 集合使用{}和set()函数创建
- 集合间操作:交(&)、并(|)、差(-)、补(^)、比较(>=<)
- 集合类型方法:.add()、.discard()、.pop()等
- 集合类型主要应用于:包含关系比较、数据去重
- 序列是基类类型,扩展类型包括:字符串、元组和列表
- 元组用()和tuple()创建,列表用[]和set()创建
- 元组操作与序列操作基本相同
- 列表操作在序列操作基础上,增加了更多的灵活性
- 映射关系采用键值对表达
- 字典类型使用{}和dict()创建,键值对之间用:分隔
- d[key] 方式既可以索引,也可以赋值
- 字典类型有一批操作方法和函数,最重要的是.get()

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)