散列表(Hash)揭秘:全面解析高效数据结构的核心

一、平衡二叉树
平衡二叉树查找数据采用二分查找,每次查找排除一半。平衡的目的是增删改之后,保证下次搜索能够稳定排除一半的数据。
平衡二叉树增删改查的时间复杂度为O(log2n)。比如,100万个节点,最多比较 20 次;10 亿个节点,最多比较 30 次。
平衡二叉树通过比较保证有序,通过每次排除一半的元素达到快速索引的目的。
二、散列表
在平衡二叉树中,搜索数据时总是对key进行比较,如果在海量数据中使用这种方式,搜索效率会很低。
散列表是一种不比较key,而是根据key计算key在表中的位置的数据结构;是key和其所在存储地址的映射关系。散列表通过此方式达到快速索引的目的。
注意:散列表的节点中key-value是存储在一起的。
struct node {
void *key;
void *val;
struct node *next;
};2.1、散列表的构成
(1)hash函数。hash函数的作用是映射,通过key找到其存储地址。
(2)数组。key通过hash函数找到数组的位置,该位置就是存储value的地方。
2.2、hash的选择
hash的选择遵循两个原则:
(1)计算速度快。
(2)强随机分布(等概率、均匀的分布在整个地址空间)。
满足这两个原则的hash有:murmurhash1、murmurhash2、murmurhash3、siphash、cityhash等。
- murmurhash1:计算速度非常快,但质量一般。
- murmurhash2:计算速度较快,质量也可以。
- murmurhash3:计算速度较慢,但质量很好。
- siphash:redis 6.0中使用,因为redis设置的key非常有规律而且字符串接近,siphash 主要解决字符串接近的强随机分布性。
注意,hash函数可能会把两个或两个以上的不同key映射到同一地址,这种现象称为hash冲突。
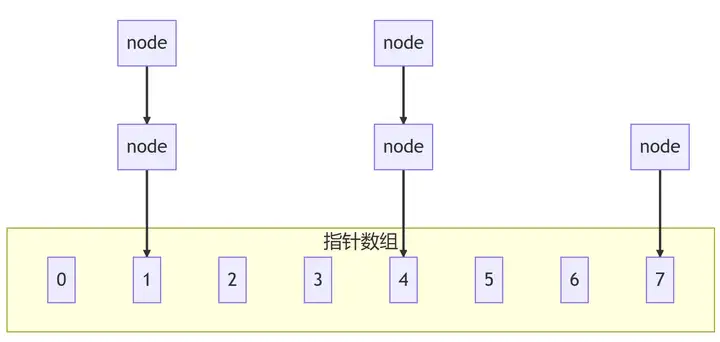
2.3、散列表操作流程
散列表的插入操作和搜索操作都要经过hash函数找到key对应的存储地址。首先,key经过hash函数hash(key得到一个64bit或32bit的值maddr;然后maddr对数组长度取余,得到的值就是存储节点的位置。
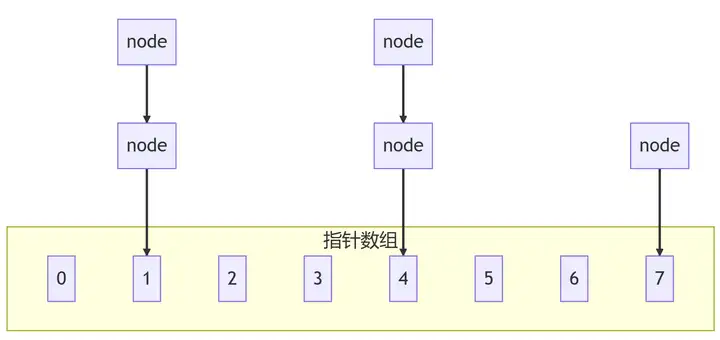
2.4、冲突产生原因
在数组大小不变情况下,随着数据的越来越多,必然产生冲突;而且hash是随机性的,这也可能产生冲突。
比如把n+1个元素放入n大小的数组,势必有一个空间需要存放两个元素,这就是冲突。另外,hash是随机的,产生的数对数组长度取余很可能相同,这也会冲突。
2.5、负载因子
负载因子=数组存储元素的个数 / 数组长度; 负载因子用于描述冲突的激烈程度和存储的密度。负载因子越小,冲突概率越小,负载因子越大,冲突概率越大。
2.6、冲突处理
解决冲突的方法有很多,比较常用的有:链表法 / 拉链法、开放寻址法等。
一般,链表法和开放寻址法适用于负载因子在合理范围内的情况,即数组存储元素的个数小于数组长度的情况。
2.6.1、链表法
链表法是常用的处理冲突的方式。通过引用链表来处理hash冲突,即将冲突元素用链表链接起来。
但可能出现极端情况,冲突元素比较多,该冲突链表过长;这个时候可以考虑将链表转换为红黑树、最小堆;由原来链表时间复杂度 O(n) 转换为红黑树时间复杂度 O(log2n) ;可以采用超过 256(经验得来的值)个节点的时候将链表结构转换为红黑树或堆结构。
2.6.2、开放寻址法
开放寻址法将所有的元素都存放在哈希表的数组中,不使用额外的数据结构。一般使用线性探查的的思路解决:
(1)当插入新元素时,使用hash函数在hash表中定位元素的位置;
(2)检查数组中该槽位索引是否存在元素,如果该槽位为空,则插入数据,否则进入(3)。
(3)在(2)检测的槽位索引上加一定步长接着检查(2);加步长有以下几种:
( a ) i+1,i+2,i+3,i+4,...,i+n
( b ) i-$1^2$,i+$2^2$,i-$3^2$,i+$4^2$,...
( c ) 双重hash
前两种都会产生同类hash聚集,也就是近似值它的hash值也近似,那么它的数组槽位也靠近,形成 hash 聚集;第一种同类聚集冲突在前,第二种只是将聚集冲突延后; 可以使用双重哈希来解决上面出现hash聚集现象。
比如,在.net HashTable类的hash函数Hk定义如下:
Hk(key) = [GetHash(key) + k * (1 +(((GetHash(key) >> 5) + 1) %(hashsize – 1)))] % hashsize
在此 (1 + (((GetHash(key) >> 5) + 1) %(hashsize – 1))) 与 hashsize互为素数(两数互为素数表示两者没有共同的质因⼦);执⾏了 hashsize 次探查后,哈希表中的每⼀个位置都有且只有⼀次被访问到,即对于给定的 key,对哈希表中的同⼀位置不会同时使⽤Hi 和 Hj;
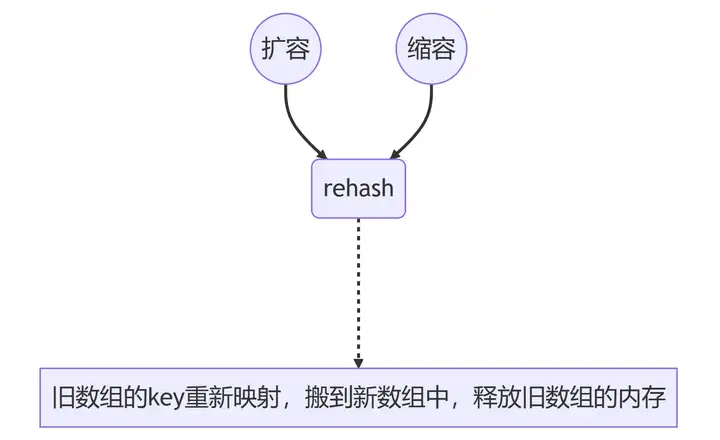
2.7、扩容和缩容
以上两种解决冲突的方式都是负载因子在合理范围内。当负载因子不在合理范围内,如何处理?
(1)当used > size,即要使用的空间大于数组的空间,这时就需要通过扩容来避免或降低冲突。扩容通常采用翻倍扩容。
(2)当used < 0.1 * size,即要使用的空间远远小于数组的空间,这时就需要缩容;缩容不能解决冲突,只能节约空间,减少内存浪费。
(3)rehash,重新hash。因为容量发生了改变,前面解释过key在数组的位置是通过key % size的方式;所以,需要重新做key % new_size找到key的槽位,然后重新放到新的数组中去。
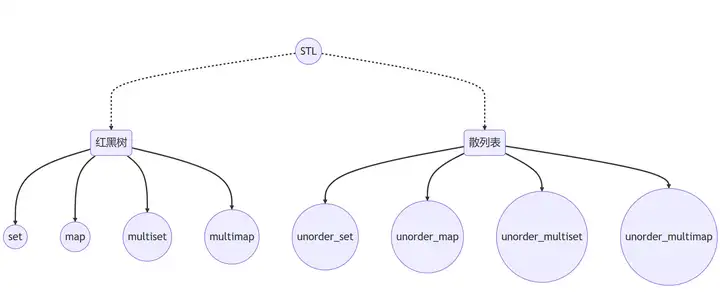
三、STL unordered_* 散列表实现
在 STL 中 unordered_map、unordered_set、unordered_multimap、unordered_multiset 四个容器的底层实现都是散列表。
原理图:
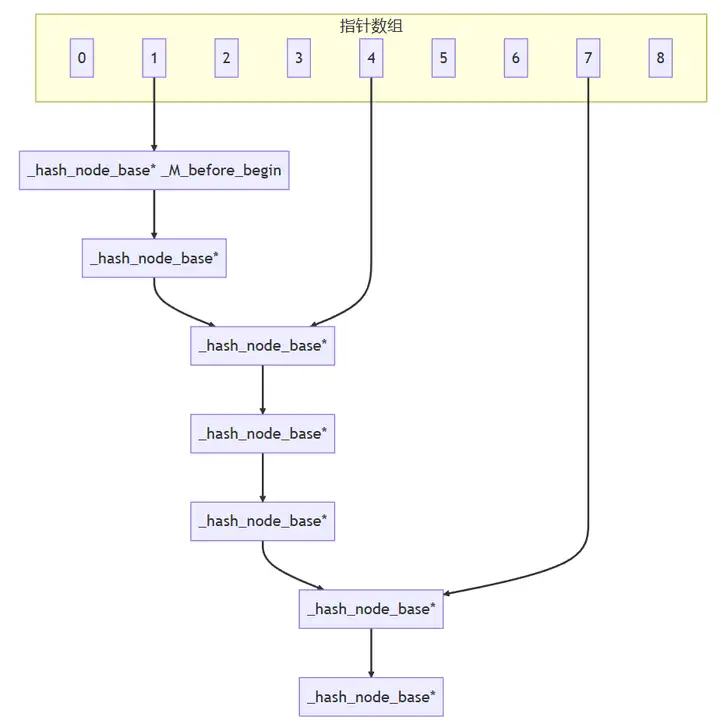
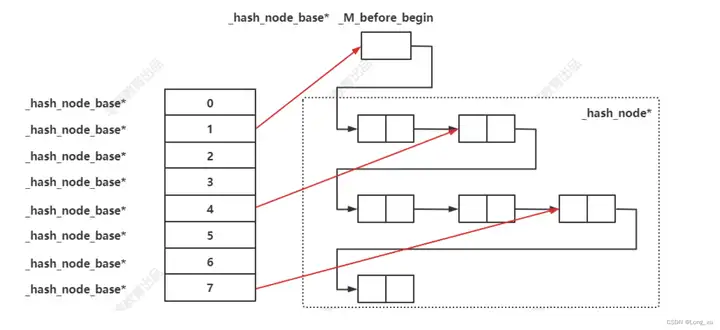
一般,hash table里面的槽位单独通过链表串联所属槽位的数据;STL散列表的槽位指针不再这么做,做了优化,将后面具体结点串成一个单链表,而槽位指针指向上一的结点。
举个例子:
现在的hash table是空的,还没有数据插入,当第一个hash(key) % array_size插入时,假设这个hash(key) % array_size=4,那么4的_hash_node_base*指向头指针_M_before_begin,_M_before_begin.next=新插入的_hash_node_base*;后面又来一个插入,假设hash(key) % array_size=1,那么1的_hash_node_base*指向头结点_M_before_begin,_M_before_begin.next=新插入的_hash_node_base*,新插入的_hash_node_base.next=4的_hash_node_base,4的槽位指针指向新插入的_hash_node_base*。
总结
- 平衡二叉树通过比较,保证结构有序,从而提升搜索效率,稳定时间复杂度是 O(log2n) ;而散列表是通过key与存储位置的映射关系来提高搜索效率,整个散列表是无序的。
- 散列表的组成主要有:hash函数、数组、运算流程(算法是hash(key) % array_size)。
- 散列表hash函数的作用是建立映射关系;选择hash函数要满足计算速度快、强随机分布的要求,比如murmurhash2、siphash、cityhash等使用比较广泛的hash算法。
- 解决hash冲突的方法有链表法、开放寻址法、扩容等;链表法中如果槽位的链表很长(超过256个元素),可以转换为红黑树或最小堆的数据结构,将时间复杂度由O(n)变为 O(log2n)。扩容、缩容后都需要重新hash,即重新映射。
- 散列表的操作流程都是需要经过同样的运算(映射),找到存储位置再插入。
- STL的散列表实现中,为了实现迭代器,将后面具体结点串成一个单链表。
欢迎关注公众号《Lion 莱恩呀》学习技术,每日推送文章。


- 点赞
- 收藏
- 关注作者
评论(0)