【自动化批量操作 | 易班课群】自动收集课群作业 & 自动创建课群 & 自动查看课群号


🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍
🙋♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

摘要:
本文介绍了博主在易班技术部研发工作中发现的易班课群收集作业低效麻烦的问题,并且自主研发了三款小工具,分别是自动收集课群作业、自动创建课群和自动查看课群号。接着,文章给出了详细的使用教程,并附有相应的截图。最后,作者还列出了开发过程中的任务列表,并提供了GitHub地址。
易班优课培训 —— 自动化作业下载
在学校中,易班作为一款非常常用的教学平台,经常被老师用来布置作业、上传资料等。然而,在使用易班课群时,我们可能会遇到一些问题,比如课群收集作业的效率低、操作繁琐,无法批量处理等。为了解决这些问题,我在负责易班技术部的研发工作中,自主研发了三款小工具,分别是自动收集课群作业、自动创建课群和自动查看课群号。
使用教程
首先,我们需要登录到易班账号,并进入任意界面(以下以课群页为例)。然后,我们可以通过右键检查或按下F12键打开开发者工具面板。
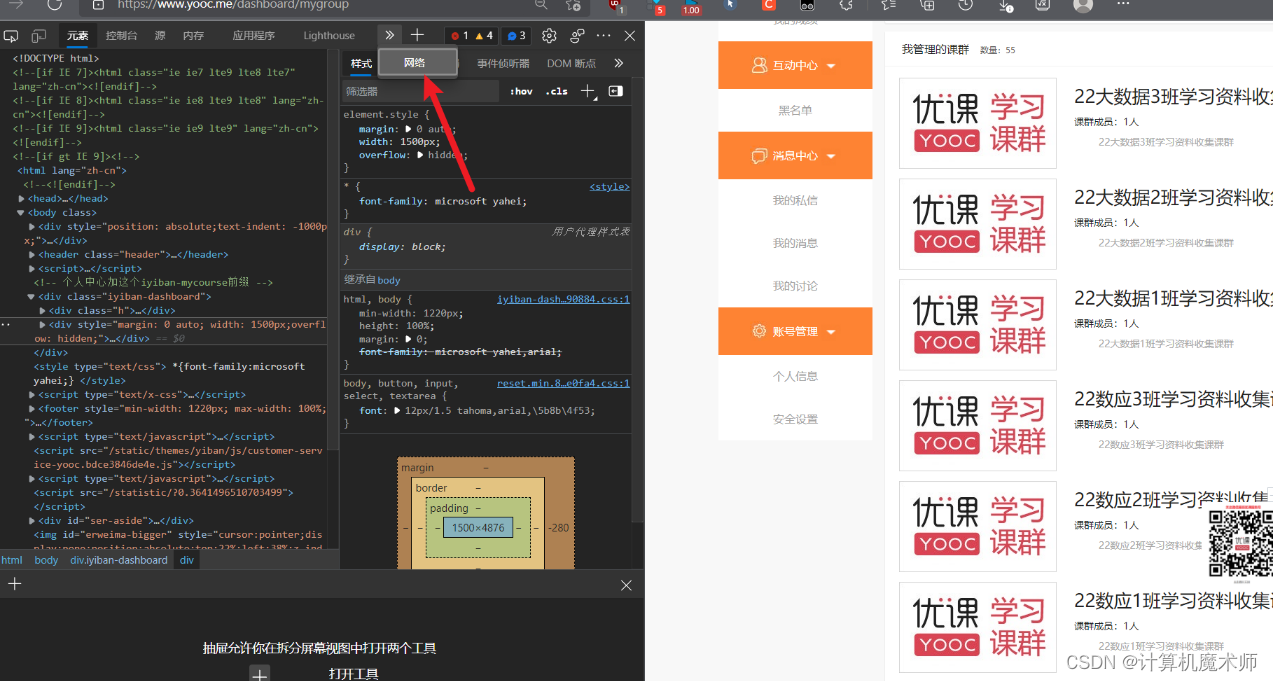
在开发者工具面板中,选择"网络"选项卡,并刷新页面。然后,点击第一个请求,复制其中的Cookie字符串(即账号的Cookie)。
在优课作业截止后,我们需要点击"批改作业页面",并复制该页面的链接。
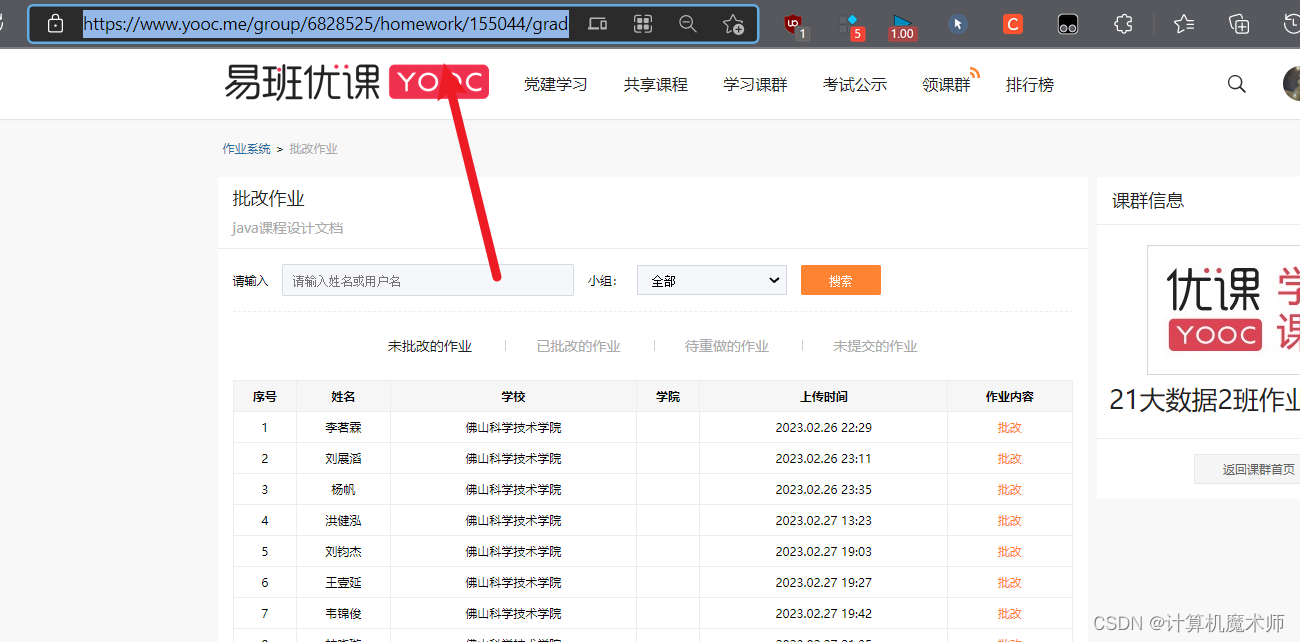
将上述复制的内容输入到相应的工具中即可开始自动化作业下载的过程。
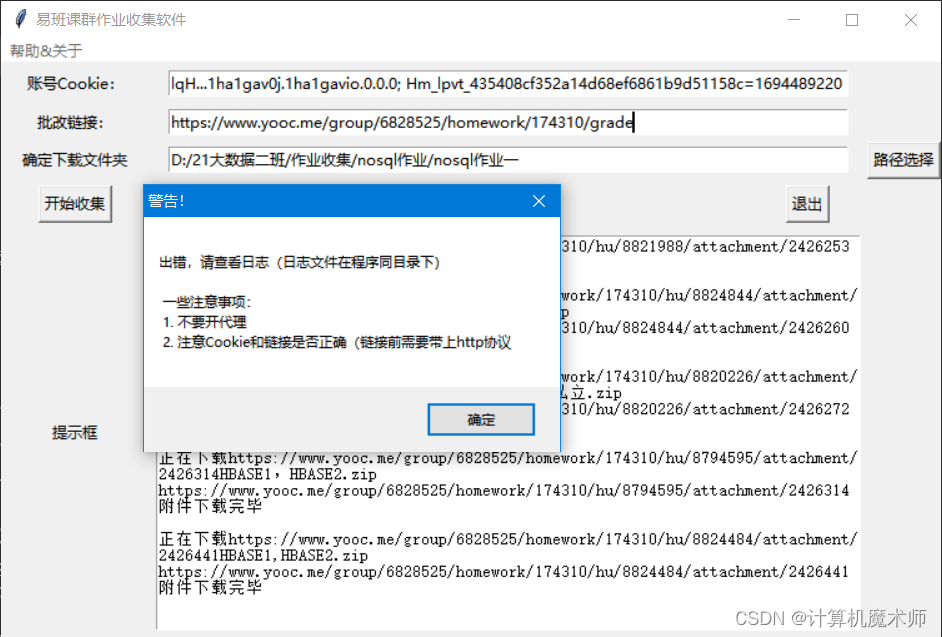
如果在使用过程中遇到报错,请查看日志文件,检查是否开启了代理或链接是否正确。如果遇到文件权限无法下载的问题,需要重新删除对应附件下载或者以管理员身份运行。
开发过程
在开发这些小工具的过程中,我完成了以下任务:
- 添加了日志功能,方便用户查看和排查问题;
- 实现了智能报错功能,能够提示用户出现的错误;
- 对代码进行了重构,提高了代码的可读性和可维护性;
- 正在测试收集作业自动换页功能;
- 正在测试自动创建课群和自动获取课群码功能。
如果你对这些小工具感兴趣,可以访问GitHub地址查看更多详情和下载相关代码:
https://github.com/TobeMagic/automatic-yiban-tools
通过这些自动化工具,我们可以提高易班课群作业的处理效率,减少了繁琐的操作步骤,让教学更加便捷。希望这些工具能够为广大易班用户带来便利,提升学习和教学的效果。
源码详解
#!user/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/9/11 21:29
# @Author : AI_magician
# @File : dasd.py
# @Project : PyCharm
# @Version : 1.0,
# @Contact : 1928787583@qq.com",
# @License : (C)Copyright 2003-2023, AI_magician",
# @Function:
import tkinter as tk
import traceback
from tkinter import *
from tkinter import messagebox
from tkinter.filedialog import askdirectory
from tkinter.messagebox import *
import pywintypes
import logging
import requests
import time
import win32api
import win32con
from lxml import etree
import os
import sys
DEBUG = 0
if not DEBUG:
if sys.platform.startswith('win'):
# Windows 平台
import ctypes
if not ctypes.windll.shell32.IsUserAnAdmin():
showinfo(title="警示",
message="This software requires administrator privileges.\nPlease run the software as an administrator.(请用管理员打开程序)\n")
logging.info("Please run the script as an administrator.")
sys.exit(1)
else:
# 非 Windows 平台
if os.getuid() != 0:
showinfo(title="警示",
message="This software requires administrator privileges.\nPlease run the software as an administrator.(请用管理员打开程序)\n")
logging.info("Please run the script as an administrator.")
sys.exit(1)
logger = logging.getLogger(__name__)
# 配置日志记录器
logging.basicConfig(filename='易班课群作业收集软件.log', level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
# 创建GUI
root = tk.Tk()
# 设置标签信息
def show():
def selectPath():
path_ = askdirectory()
path.set(path_)
path = StringVar() # 路径变量(可变字符串)
label1 = tk.Label(root, text='账号Cookie:')
label1.grid(row=0, column=0)
label2 = tk.Label(root, text='批改链接:')
label2.grid(row=1, column=0)
label3 = tk.Label(root, text='确定下载文件夹')
label3.grid(row=3, column=0)
label4 = tk.Label(root, text='提示框')
label4.grid(row=5, column=0)
root.title("易班课群作业收集软件")
# 创建输入框
entry1 = tk.Entry(root)
entry1.grid(row=0, column=1, padx=10, pady=5, ipadx=200)
entry2 = tk.Entry(root)
entry2.grid(row=1, column=1, padx=10, pady=5, ipadx=200)
Entry(root, textvariable=path).grid(row=3, column=1, ipadx=200)
Button(root, text="路径选择", command=selectPath).grid(row=3, column=2)
# 消息提示框
text = Text(root)
# text.pack(fill=X, side=BOTTOM)
def getTask():
"""
1. 尝试用seleunim解决,如何面对登录cookie等
"""
# 运行任务
# selenium 下载实现
# web = Chrome(executable_path='chromedriver')
# web.get(attachment) # selenium 模拟浏览器直接下载,该页面下载无需登录权限!
# time.sleep(2) # selenium 问题存在 反复请求之后需要登录,且下载加载缓慢
# web.close()
# options = webdriver.ChromeOptions()
# options.add_argument(
# 'Cookie=""
# # web = Chrome(executable_path='chromedriver')
# web.add_cookie("")
#
# web.get("https://www.yooc.me/group/6507710/homework/145796/grade")
# print(web.title)
"""
2. 可用爬虫实现(附带cookie很简单就登陆进去了),获取附件下载链接到文件中,随后直接下载到对应文件
"""
try:
logging.info('账号Cookie:%s' % entry1.get())
logging.info('批改链接:%s' % entry2.get())
# text.insert(END, '账号Cookie:%s \n' % entry1.get())
# text.insert(END, '批改链接:%s \n' % entry2.get())
# text.see(END)
# text.update()
# cookie = entry1.get()
cookie = entry1.get()
list_url = entry2.get()
# list_url = "https://www.yooc.me/group/6828525/homework/162730/grade"
root_url = "https://www.yooc.me"
headers = {
'Cookie': cookie,
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36"
}
session = requests.Session()
# pages = 5
attachment_url = []
attachment_name = []
student_name = []
homework_url = []
# student_dict = {}
# 爬取每一页list
# for page in range(1, pages + 1):
# list_url = f"https://www.yooc.me/group/6828525/homework/155044/grade?type=1&keyword=&team=&page=2" # todo 注意是批改作业页面
resp = session.get(url=list_url, headers=headers)
html = etree.HTML(resp.text)
student_list = html.xpath("/html/body/section/section/section/div[2]/table/tr") # 获取不到原始信息?(删除掉tbody
# 爬取每位学生作业url 及 name
for student in student_list:
student_name.append(student.xpath("./td[2]/text()")[0])
homework_url.append(student.xpath("./td[6]/a/@href")[0])
# student_dict[homework_url[0]] = student_name[0]
# 爬取附件url
for i, url in enumerate(homework_url):
# homework_resp = session.get(url="https://www.yooc.me/group/6507710/homework/145796/grade/hu/7269658?htype=1",headers=headers)
homework_resp = session.get(url=url, headers=headers)
# print(student_dict)
sub_html = etree.HTML(homework_resp.text)
# logging.info("单个学生页面\n" + str(homework_resp.text))
try:
attachment_url.append(root_url + sub_html.xpath("//a[@class='downl']/@href")[0])
attachment_name.append(
sub_html.xpath("/html/body/section/section/div[2]/div[1]/div[1]/p/text()")[0])
except IndexError as e:
# ("errer: " + student_name[i] + "可能未提交附件")
# showerror("error", student_name[i] + "可能未提交附件")
text.insert(END, student_name[i] + "可能未提交附件 \n")
showinfo(title="警示", message=student_name[i] + "可能未提交附件 \n")
text.see(END)
text.update()
# showinfo(title="提示", message="全部学生:" + " ".join(student_name))
text.insert(END, "全部学生" + str(len(student_name)) + ":" + " ".join(student_name) + "\n\n")
text.see(END)
showinfo(title="警示", message="附件:"
"" + str(len(attachment_url)) + " 学生个数:" + str(len(student_name)) + "" if len(
attachment_url) == len(student_name) else "附件与学生个数不一致,可能有同学未交附件\n")
time.sleep(2)
# 下载附件
for attachment, filename in zip(attachment_url, attachment_name):
# showinfo(title="提示", message=attachment + filename)
text.insert(END, "正在下载" + attachment + filename + "\n")
text.see(END)
text.update()
with open(file=path.get() + "/" + filename, mode="wb") as f:
f.write(requests.get(attachment).content)
text.insert(END, attachment + "附件" + "下载完毕 \n\n")
text.see(END)
text.update()
time.sleep(2)
showinfo(title="提示", message="全部收集完毕")
except Exception as e:
win32api.MessageBox(0, "出错,请查看日志(日志文件在程序同目录下)\n\n 一些注意事项:\n 1. 不要开代理 \n 2. 注意Cookie和链接是否正确(链接前需要带上http协议",
"警告!", win32con.MB_OK)
# e.format_exc()
logging.info(traceback.format_exc())
# logger.warning("all over!!")
text.grid(row=5, column=1, padx=5, pady=5, sticky=N + W + W + E)
button1 = tk.Button(root, text='开始收集', command=getTask).grid(row=4, column=0,
sticky=tk.W, padx=30, pady=5)
button2 = tk.Button(root, text='退出', command=root.quit).grid(row=4, column=1,
sticky=tk.E, padx=30, pady=5)
def about():
github_link = "https://github.com/TobeMagic/automatic-yiban-tools"
personal_info = "The software information goes here"
messagebox.showinfo(title="Help", message=f"GitHub: {github_link}\n\n{personal_info}")
menubar = Menu(root)
helpmenu = Menu(menubar, tearoff=0)
helpmenu.add_command(label="帮助&关于", command=about)
menubar.add_cascade(label="帮助&关于", menu=helpmenu)
#
if __name__ == "__main__":
root.config(menu=menubar)
show()
tk.mainloop()
如果你有任何问题或建议,欢迎在GitHub上留言或与我联系。谢谢!
🤞到这里,如果还有什么疑问🤞
🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩
🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳

- 点赞
- 收藏
- 关注作者
评论(0)