连接池技术:简单而强大的加速数据库访问方法

一、为什么需要连接池?
以操作数据库为例,当一个数据库操作任务到来时,程序需要和数据库建立连接,进行三次握手、数据库用户验证,然后执行SQL语句,最后用户退出、四次挥手关闭连接。每次任务都执行这样的流程,那么整个流程中,真正有效而且变化的只有<执行SQL语句>这一步骤,而且每次建立连接、用户验证、关闭连接都耗费时间。
因此,考虑能不能将连接只创建一次,然后复用长连接执行 SQL 语句呢?这需要连接池技术。
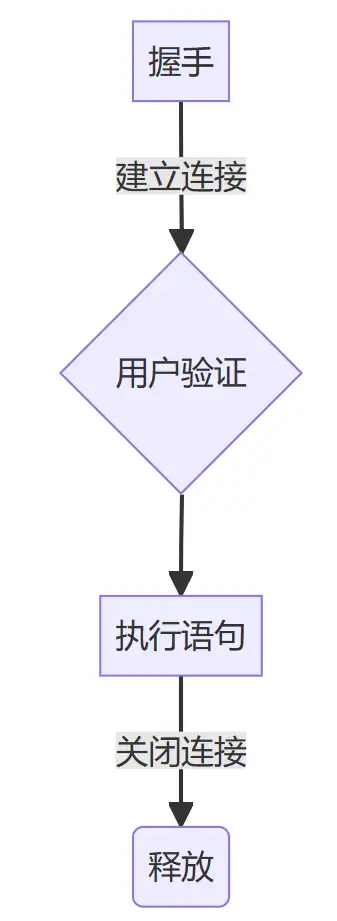
二、池化技术
池化技术可以减少资源对象的创建次数,提高程序的响应性能,特别是对高并发场景下的性能提升非常明显。
适合使用池化技术缓存的资源对象具有如下特点:
(1)对象创建时间长;
(2)对象创建需要大量的资源;
(3)对象创建后可以重复使用。
比如常见的线程池、‘内存池、连接池、对象池等都具有以上的特点。
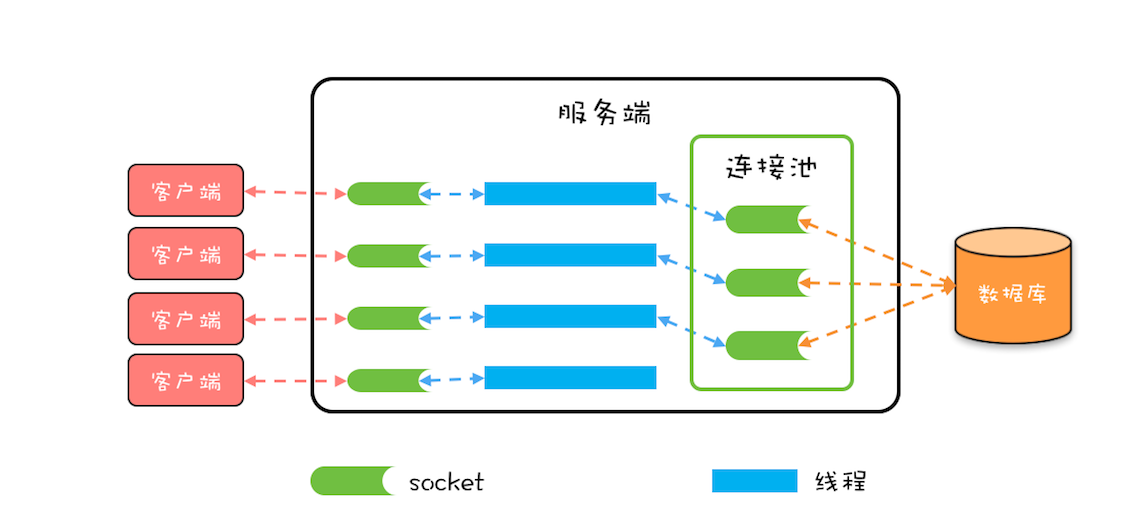
三、数据库连接池
定义:
数据库连接池是程序启动时建立足够的数据库连接,并将这些连接组成一个连接池,由程序动态的对池中的连接进行申请、使用、归还。
创建数据库连接是一个很耗时的操作,而且容易容易对数据库造成安全隐患。因此,程序初始化的时候,创建足够的数据库连接,并把它们集中管理,提供给程序使用,可以保证较快的数据库读写速度。
数据库连接池的优点:
(1)资源复用。避免了频繁的创建、释放连接引起的性能开销,减少系统消耗,增进系统运行环境的稳定(减少内存碎片和数据库临时线程/进程数量)。
(2)更快的系统响应速度。数据库连接池初始化完成后,直接利用现有可用连接,避免了从数据库连接初始化和释放过程的开销,从而缩减了系统整体响应时间。
(3)统一的连接管理,避免数据库连接泄漏。数据库连接池实现中,可根据预先的连接占用超时设定,强制收回被占用连接。从而避免了常规数据库连接操作中可能出现的资源泄露。
3.1、不使用连接池
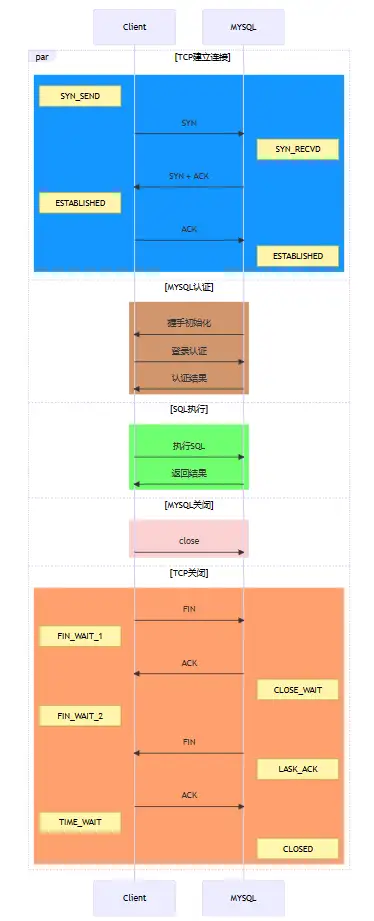
可以看出,为了执行一条SQL语句,需要进行TCP三次握手、MYSQL认证、MYSQL关闭、TCP四次挥手等操作,执行SQL操作在所有的操作中占比非常低。
这种实现方式的缺点:
(1)网络IO较多。
(2)带宽利用率低。
(3)QPS较低。
(4)频繁创建连接和关闭连接,导致临时对象较多,产生更多的内存碎片。
(5)关闭连接后出现大量TIME_WAIT的TCP状态。
这种实现方式的优点:实现简单,不需要设计连接池。
3.2、使用连接池

程序初始化的时候建立连接,之后的访问复用之前创建的连接,直接执行SQL语句。
优点:
(1)降低网络开销。
(2)连接复用。减少连接次数。
(3)提升性能。避免了频繁的创建连接。
(4)没有TIME_WAIT状态问题。
缺点:设计较为复杂。
3.3、长连接和连接池的区别
(1)长连接是一些驱动、驱动架构、ORM(即Object-Relational Mapping)工具的特性,由驱动来保持连接句柄的打开,以便后续的数据库操作可以重用连接,从而减少数据库的连接开销。
(2)连接池是应用服务器的组件,它可以通过参数来配置连接数、连接检查、连接的生命周期等。
(3)连接池内的连接,其实就是长连接。
如果每个任务线程绑定一个连接,而有些任务是不需要操作数据库的,这就不利于参入参数的解耦,降低性能。
3.4、 数据库连接池运行机制
(1)从连接池获取或创建可用连接;
(2)使用完毕,把连接返回给连接池。
(3)系统关闭前,断开所有连接并释放连接占用的系统资源。
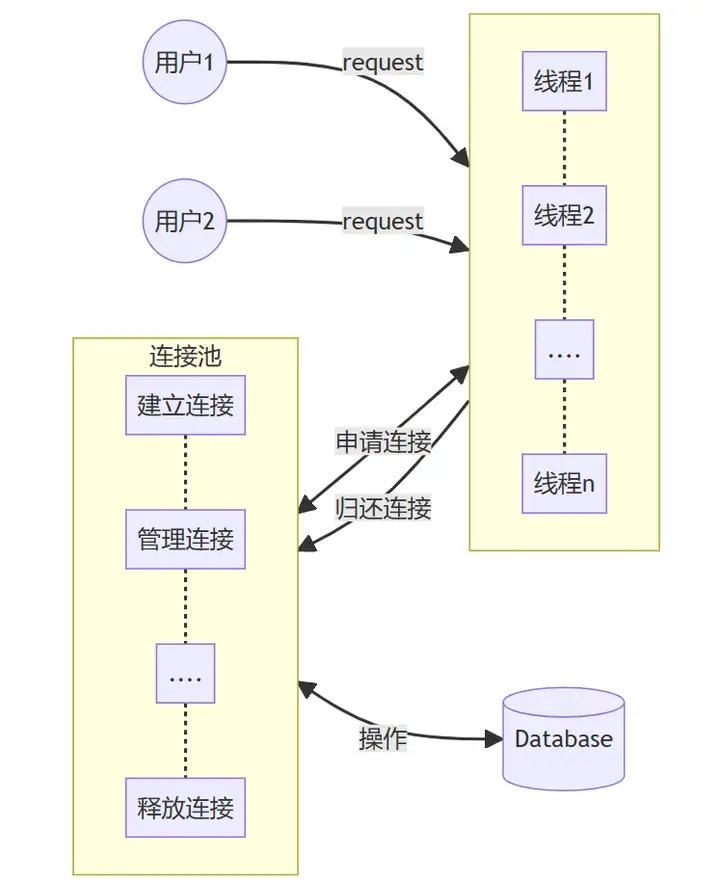
四、连接池和线程池的关系
线程池:主动操作,主动获取任务并执行任务。
连接池:被动操作,池内的对象被任务获取,任务执行完成后归还。
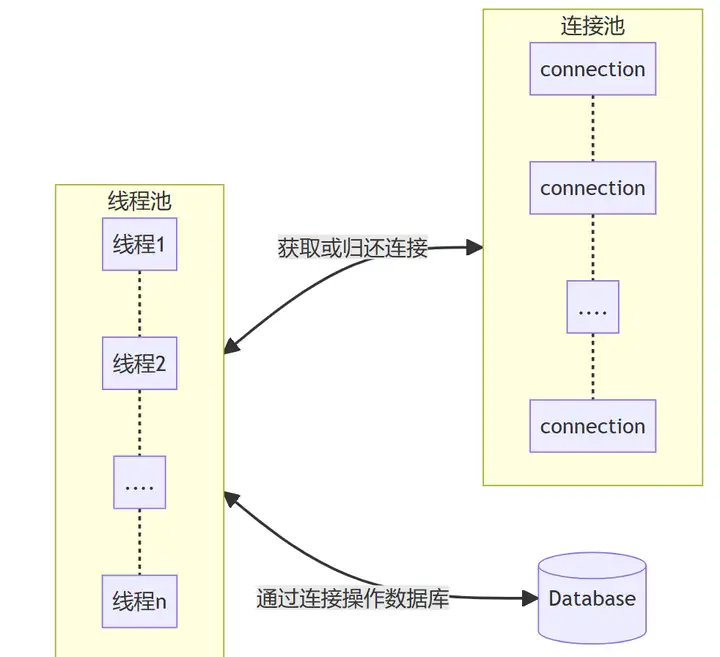
4.1、连接池和线程池的区别
线程池:主动调用任务。当任务队列不为空时从队列取出任务并执行。
连接池:被任务使用,被动取出。当某任务需要操作数据库时从连接池取出一个连接对象;当任务使用完连接对象后,将该连接对象放回到连接池中;如果连接池中没有连接对象可用,那么该任务就必须等待。
4.2、连接池和线程池设置数量的关系
(1)一般,连接池连接对象数量和线程池数量一致。
(2)线程使用完连接对象后归还连接对象到连接池。
五、Ubuntu使用MySQL
(1)安装mysql-server
sudo apt-get install mysql-server(2)初始配置MySQL
使用root账户登录,注意这个账户是默认没有密码的。为了数据库的安全,需要第一时间给root用户设置密码。
# 切换系统账户,$
sudo su
# 进入mysql,#
mysql
# 查看用户表,mysql>
select user, plugin from mysql.user;
# 修改root密码,mysql>
update mysql.user set authentication_string=PASSWORD('123456'), plugin='mysql_native_password' where user='root';
# 刷新,mysql>
flush privileges;
# 退出mysql,mysql>
exit
# 重启服务,#
service mysql restart(3)安装MySQL库,用于编程
sudo apt-get install libmysqlclient-dev(4)创建一个数据库
# 创建mysql_pool_test的数据库,mysql>
create database mysql_pool_test;
# 查看所有数据库,mysql>
show databases;(5)MySQL提示“too many connections“的解决方法
# 查看最大连接数。mysql>
show variables like "max_connections";
# 结果显示如下:
# mysql> show variables like "max_connections";
# +-----------------+-------+
# | Variable_name | Value |
# +-----------------+-------+
# | max_connections | 151 |
# +-----------------+-------+
# 1 row in set (0.00 sec)
#
# 默认连接数量这里只有151,可以根据自己需要修改。比如可以临时设置为1000
set GLOBAL max_connections=1000;六、连接池设计要点
使用连接池,需要预先建立数据库连接。
(1)连接到数据库,涉及数据库IP、端口、用户名、密码、数据库名称等;
a. 连接操作,每个连接对象都是独立的连接通道
b. 配置最小连接数和最大连接数
(2)需要一个队列管理它的连接;
(3)获取连接对象;
(4)归还连接对象;
(5)连接池的名称。不同的业务可以设计不同的连接池,比如聊天工具中的一对一聊天和群组聊天分别对应不同的连接池。
6.1、设计逻辑
(1)构造函数
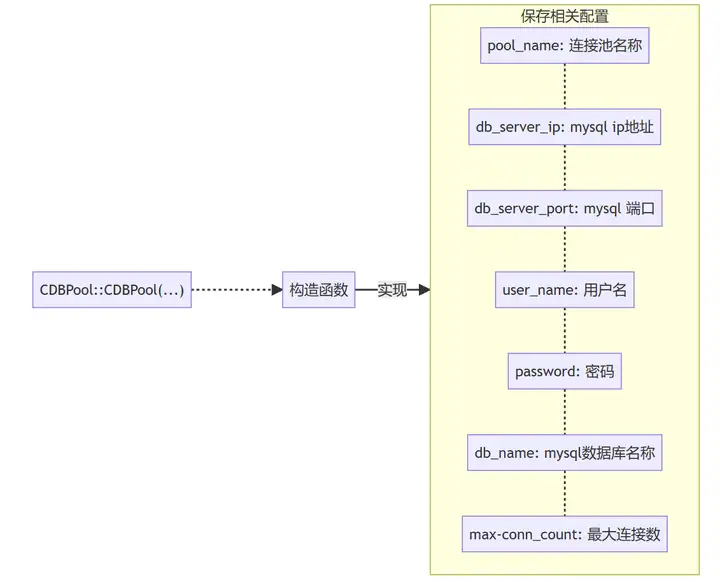
CDBPool::CDBPool(
const char *pool_name,
const char *db_server_ip,
uint16_t db_server_port,
const char *username,
const char *password,
const char *db_name,
int max_conn_cnt)
{
m_pool_name = pool_name;
m_db_server_ip = db_server_ip;
m_db_server_port = db_server_port;
m_username = username;
m_password = password;
m_db_name = db_name;
m_db_max_conn_cnt = max_conn_cnt; //
m_db_cur_conn_cnt = MIN_DB_CONN_CNT; // 最小连接数量
}
(2)初始化
一般,构造函数和初始化函数分开来,构造函数一般做保存数据这种不会发生错误的操作,而初始化函数做一些比较复杂,可能伴随错误返回的操作(比如申请内存)。因为构造函数不会返回,如果构造函数内有错误产生,需要在外部进行异常捕获,异常捕获的开销是巨大的,所以一般不这么做。
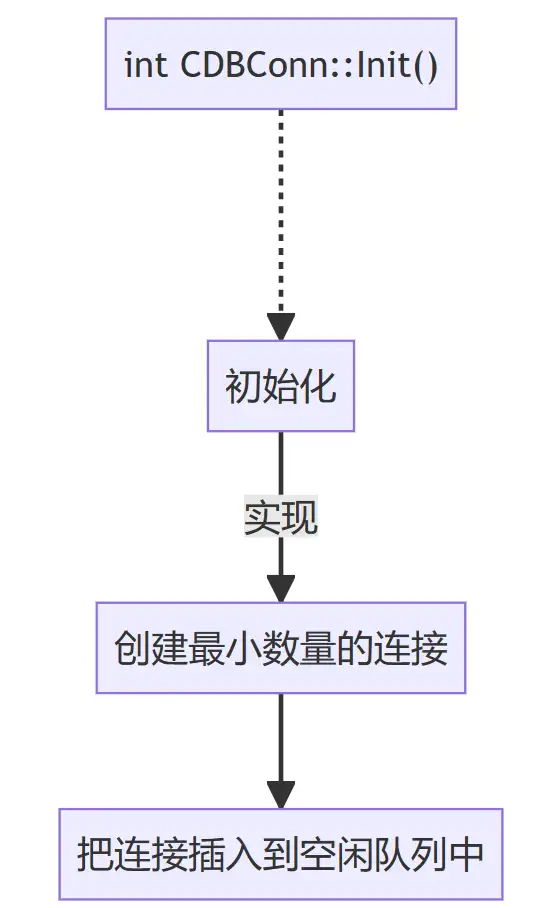
// 连接对象初始化
int CDBConn::Init()
{
m_mysql = mysql_init(NULL); // mysql_标准的mysql c client对应的api
if (!m_mysql)
{
log_error("mysql_init failed\n");
return 1;
}
my_bool reconnect = true;
mysql_options(m_mysql, MYSQL_OPT_RECONNECT, &reconnect); // 配合mysql_ping实现自动重连
mysql_options(m_mysql, MYSQL_SET_CHARSET_NAME, "utf8mb4"); // 设置字符集,utf8mb4和utf8区别
// ip 端口 用户名 密码 数据库名
if (!mysql_real_connect(m_mysql, m_pDBPool->GetDBServerIP(), m_pDBPool->GetUsername(), m_pDBPool->GetPasswrod(),
m_pDBPool->GetDBName(), m_pDBPool->GetDBServerPort(), NULL, 0))
{
log_error("mysql_real_connect failed: %s\n", mysql_error(m_mysql));
return 2;
}
return 0;
}
// 连接对象的构造函数
CDBConn::CDBConn(CDBPool *pPool)
{
m_pDBPool = pPool;
m_mysql = NULL;
}
// 连接对象的析构函数
CDBConn::~CDBConn()
{
if (m_mysql)
{
mysql_close(m_mysql);
}
}
// ......
// pool 初始化
int CDBPool::Init()
{
// 创建固定最小的连接数量
for (int i = 0; i < m_db_cur_conn_cnt; i++)
{
CDBConn *pDBConn = new CDBConn(this);//新建一个连接
int ret = pDBConn->Init();// 初始化连接
if (ret)
{
delete pDBConn;
return ret;// 失败返回
}
m_free_list.push_back(pDBConn);// 将连接对象放入到容器中管理
}
return 0;
}
注意utf8和utf8mb4的区别。在mysql中utf8不是真正的utf8,它只支持三个字节的Unicode,不支持四字节的Unicode;只有utf8mb4支持复杂的字符。这对乱码的解决很重要。
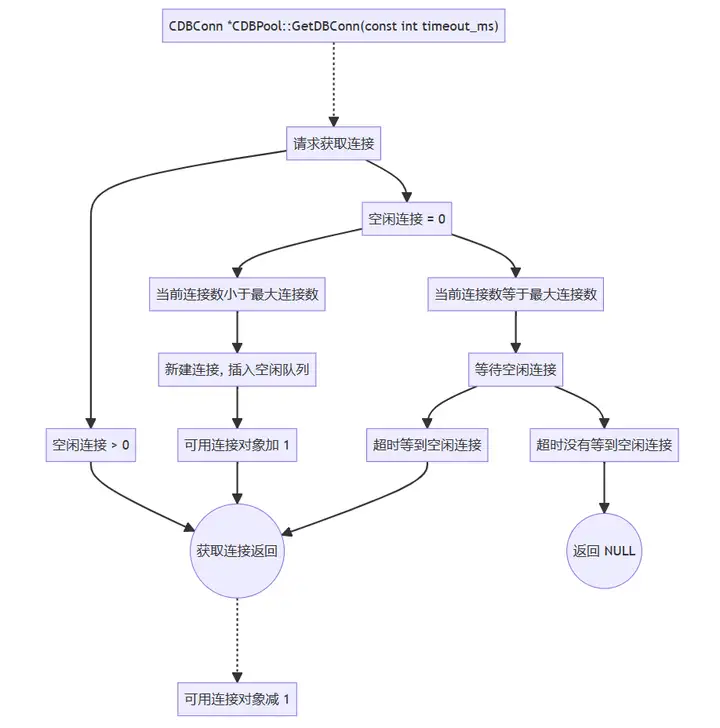
(3)请求获取连接
/*
*TODO: 增加保护机制,把分配的连接加入另一个队列,这样获取连接时,如果没有空闲连接,
*TODO: 检查已经分配的连接多久没有返回,如果超过一定时间,则自动收回连接,放在用户忘了调用释放连接的接口
* timeout_ms默认为 0死等
* timeout_ms >0 则为等待的时间
*/
CDBConn *CDBPool::GetDBConn(const int timeout_ms)
{
std::unique_lock<std::mutex> lock(m_mutex);
if(m_abort_request)
{
log_warn("have aboort\n");
return NULL;
}
if (m_free_list.empty()) // 当没有连接可以用时
{
// 第一步先检测 当前连接数量是否达到最大的连接数量
if (m_db_cur_conn_cnt >= m_db_max_conn_cnt)
{
// 如果已经到达了,看看是否需要超时等待
if(timeout_ms <= 0) // 死等,直到有连接可以用 或者 连接池要退出
{
log_info("wait ms:%d\n", timeout_ms);
m_cond_var.wait(lock, [this]
{
// 当前连接数量小于最大连接数量 或者请求释放连接池时退出
return (!m_free_list.empty()) | m_abort_request;
});
} else {
// return如果返回 false,继续wait(或者超时), 如果返回true退出wait
// 1.m_free_list不为空
// 2.超时退出
// 3. m_abort_request被置为true,要释放整个连接池
m_cond_var.wait_for(lock, std::chrono::milliseconds(timeout_ms), [this] {
// log_info("wait_for:%d, size:%d\n", wait_cout++, m_free_list.size());
return (!m_free_list.empty()) | m_abort_request;
});
// 带超时功能时还要判断是否为空
if(m_free_list.empty()) // 如果连接池还是没有空闲则退出
{
return NULL;
}
}
if(m_abort_request)
{
log_warn("have aboort\n");
return NULL;
}
}
else // 还没有到最大连接则创建连接
{
CDBConn *pDBConn = new CDBConn(this); //新建连接
int ret = pDBConn->Init();
if (ret)
{
log_error("Init DBConnecton failed\n\n");
delete pDBConn;
return NULL;
}
else
{
m_free_list.push_back(pDBConn);
m_db_cur_conn_cnt++;
}
}
}
CDBConn *pConn = m_free_list.front(); // 获取连接
m_free_list.pop_front(); // STL 吐出连接,从空闲队列删除
return pConn;
}
(4)归还连接
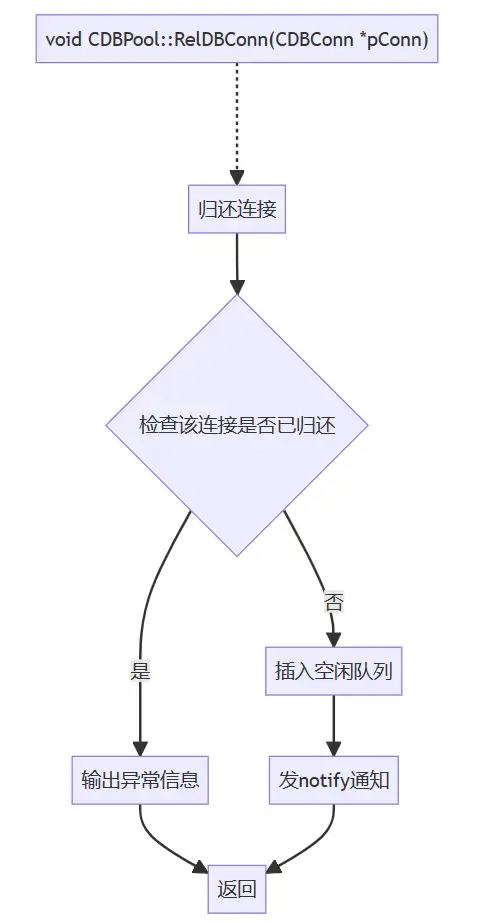
void CDBPool::RelDBConn(CDBConn *pConn)
{
std::lock_guard<std::mutex> lock(m_mutex);
list<CDBConn *>::iterator it = m_free_list.begin();
for (; it != m_free_list.end(); it++) // 避免重复归还
{
if (*it == pConn)
{
break;
}
}
if (it == m_free_list.end())
{
m_free_list.push_back(pConn);
m_cond_var.notify_one(); // 通知取队列
} else
{
log_error("RelDBConn failed\n");
}
}
(5)析构连接池:释放连接
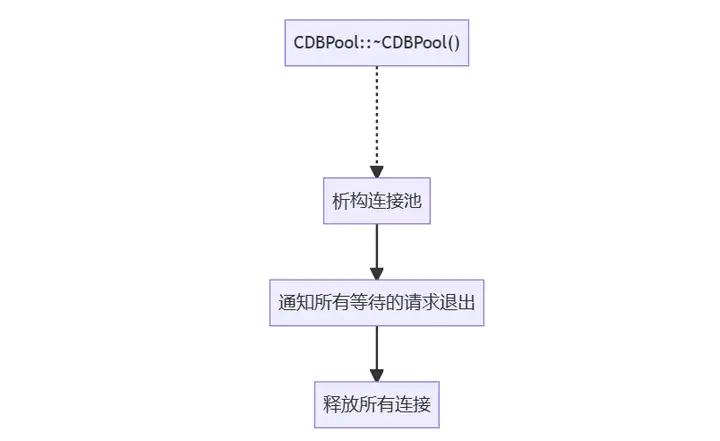
// 释放连接池
CDBPool::~CDBPool()
{
std::lock_guard<std::mutex> lock(m_mutex);
m_abort_request = true;
m_cond_var.notify_all(); // 通知所有在等待的
for (list<CDBConn *>::iterator it = m_free_list.begin(); it != m_free_list.end(); it++)
{
CDBConn *pConn = *it;
delete pConn;
}
m_free_list.clear();
}
6.2、MySQL连接重连机制
(1)设置启用自动重连
连接的时候设置自动重连参数,当发现连接断开时会自动重连。
my_bool reconnect = true;
mysql_options(m_mysql, MYSQL_OPT_RECONNECT, &reconnect); // 配合mysql_ping实现自动重连
(2)检测连接是否正常
函数原型:
int STDCALL mysql_ping(MYSQL *mysql);
检查与服务器的连接是否正常。连接断开时,如果自动重连功能开启,则尝试重新连接数据库服务器。该函数可被客户端用来检测闲置许久以后,与服务端的连接是否关闭,如有需要,则重新连接。
返回值:
- 连接正常,返回0;
- 如有错误发生,则返回非0值。返回非0值并不意味着服务器本身关闭掉,也有可能是网络原因导致网络不通。
6.3、redis连接重连机制
七、连接池连接数量设置
(1)经验公式,连接数=(核心数*2)+有效磁盘数。
假如服务器CPU是i7的8核,那么连接池连接数大小为 8∗2+1=9 。这仅仅是一个经验公式,具体的还要和线程池数量以及具体业务结合在一起。
- CPU总核数 = 物理CPU个数 * 每颗物理CPU的核数
- 总逻辑CPU数 = 物理CPU个数 * 每颗物理CPU的核数 * 超线程数
(2)IO密集型任务。
如果任务整体上是一个IO密集型的任务。在处理一个请求的过程中(处理一个任务),总共耗时100+5=105ms,而其中只有5ms是用于计算操作的(消耗cpu),另外的100ms等待io响应,CPU利用率为5/(100+5)。
使用线程池是为了尽量提高CPU的利用率,减少对CPU资源的浪费,假设以100%的CPU利用率来说,要达到100%的CPU利用率,对于一个CPU就要设置其利用率的倒数个数的线程数,也即1/(5/(100+5))=21,4个CPU的话就乘以4,即84,这个时候线程池要设置84个线程数,然后连接池也是设置为84个连接。
八、连接池扩展
对连接池进行相关的监控,比较著名的是阿里开源的druid连接池,可以研究下druid连接池的设计理念,扩展对连接池的理解。比如:
(1)最大连接时间=归还时间-请求时间。如果最大连接时间超出的知道时间,打印警告信息等。这需要设计一个结构体,在请求连接的时候记录请求时间,归还的时候记录归还时间。
(2)统计每秒请求连接的次数。
(3)可能连接没有归还,造成程序异常,可以考虑添加定时检测,超时没有归还是打印警告,或者销毁连接重新创建连接放入连接池中;这依赖于业务需求。
总结
(1)使用连接池主要是为了复用连接资源。
(2)连接池是被动的,由任务需要时取,用完之后归还;而线程池是主动的,主动的从任务队列中取出任务并执行。连接池连接数量根据线程池数量设置。
(3)线程池和连接池的数量要考虑IO同步时间问题,要根据IO等待时间和CPU处理时间来计算具体是池内对象数量。
(4)VMware虚拟机对写入性能是有影响的。
(5)异步比同步有更高的吞吐量,但是异步编程比同步编程复杂很多,如果异步过程中发生异常就不好处理,而且等待数据库返回结果也变得复杂起来;所以,如果同步可以满足性能要求,就尽量使用同步的方式。
(6)连接池的扩展功能,比如统计连接池中的最大连接时间(归还时间-请求时间)、每秒连接次数的监控、没有归还连接时的处理等。
欢迎关注公众号《Lion 莱恩呀》学习技术,每日推送文章。


- 点赞
- 收藏
- 关注作者
评论(0)