【深度学习 | LSTM】解开LSTM的秘密:门控机制如何控制信息流


🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍
🙋♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

摘要: 本系列旨在普及那些深度学习路上必经的核心概念,文章内容都是博主用心学习收集所写,欢迎大家三联支持!本系列会一直更新,核心概念系列会一直更新!欢迎大家订阅
该文章收录专栏
[✨— 《深入解析机器学习:从原理到应用的全面指南》 —✨]
@toc
LSTM
原理详解(每个神经元)
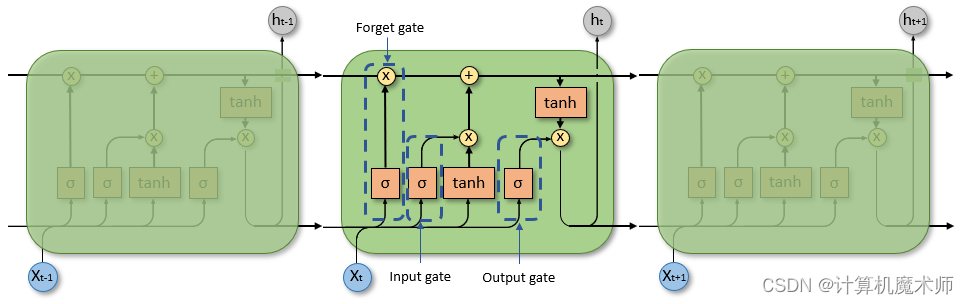
LSTM(Long Short-Term Memory)是一种常用于处理序列数据的循环神经网络模型。LSTM的核心思想是在传递信息的过程中,通过门的控制来选择性地遗忘或更新信息。LSTM中主要包含三种门:输入门(input gate)、输出门(output gate)和遗忘门(forget gate),以及一个记忆单元(memory cell)。
在LSTM层中,有三个门控单元,即输入门、遗忘门和输出门。这些门控单元在每个时间步上控制着LSTM单元如何处理输入和记忆。在每个时间步上,LSTM单元从输入、前一个时间步的输出和前一个时间步的记忆中计算出当前时间步的输出和记忆。
在LSTM的每个时间步中,输入 和前一时刻的隐状态 被馈送给门控制器,然后门控制器根据当前的输入 和前一时刻的隐状态 计算出三种门的权重,然后将这些权重作用于前一时刻的记忆单元 。具体来说,门控制器计算出三个向量:**输入门的开启程度 、遗忘门的开启程度 和输出门的开启程度 ,这三个向量的元素值均在[0,1]**之间。
然后,使用这些门的权重对前一时刻的记忆单元 进行更新,计算出当前时刻的记忆单元 ,并将它和当前时刻的输入 作为LSTM的输出 。最后,将当前时刻的记忆单元 和隐状态 一起作为下一时刻的输入,继续进行LSTM的计算。
如果你对LSTM以及其与反向传播算法之间的详细联系感兴趣,我建议你参考以下资源:
- “Understanding LSTM Networks” by Christopher Olah: https://colah.github.io/posts/2015-08-Understanding-LSTMs/ 强烈推荐!!!
- TensorFlow官方教程:Sequence models and long-short term memory network (https://www.tensorflow.org/tutorials/text/text_classification_rnn)
- PyTorch官方文档:nn.LSTM (https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html)
- 详细讲解RNN,LSTM,GRU https://towardsdatascience.com/a-brief-introduction-to-recurrent-neural-networks-638f64a61ff4
以上资源将为你提供更多关于LSTM及其与反向传播算法结合使用的详细解释、示例代码和进一步阅读材料。
LSTM 的核心概念在于细胞状态以及“门”结构。细胞状态相当于信息传输的路径,让信息能在序列连中传递下去。你可以将其看作网络的“记忆”,记忆门一个控制信号控制门是否应该保留该信息,在实现上通常是乘1或乘0来选择保留或忘记。理论上讲,细胞状态能够将序列处理过程中的相关信息一直传递下去。因此,即使是较早时间步长的信息也能携带到较后时间步长的细胞中来,这克服了短时记忆的影响。信息的添加和移除我们通过“门”结构来实现,“门”结构在训练过程中会去学习该保存或遗忘哪些信息。
LSTM的参数包括输入到状态的权重 ,输入到遗忘门的权重 ,输入到输出门的权重 ,以及输入到记忆单元的权重 ,其中 表示权重矩阵, 表示偏置向量。在实际应用中,LSTM模型的参数通常需要通过训练来获得,以最小化预测误差或最大化目标函数。
a. 遗忘门:Forget Gate
遗忘门的功能是决定应丢弃或保留哪些信息。来自前一个隐藏状态的信息和当前输入的信息同时传递到 sigmoid 函数中去,输出值介于 0 和 1 之间,越接近 0 意味着越应该丢弃,越接近 1 意味着越应该保留。
遗忘门的计算公式
b. 输入门:Input Gate
输入门用于更新细胞状态。首先将前一层隐藏状态的信息和当前输入的信息传递到 sigmoid 函数中去。将值调整到 0~1 之间来决定要更新哪些信息。0 表示不重要,1 表示重要。其次还要将前一层隐藏状态的信息和当前输入的信息传递到 tanh 函数中去,创造一个新的侯选值向量。最后将 sigmoid 的输出值与 tanh 的输出值相乘,sigmoid 的输出值将决定 tanh 的输出值中哪些信息是重要且需要保留下来的
使用tanh作为LSTM输入层的激活函数,一定程度上可以避免梯度消失和梯度爆炸的问题。
在LSTM中,如果权重值较大或者较小,那么在反向传播时,梯度值会非常大或者非常小,导致梯度爆炸或者消失的情况。而tanh函数的导数范围在[-1, 1]之间,可以抑制梯度的放大和缩小,从而避免了梯度爆炸和消失的问题(RNN遇到的问题)。此外,tanh函数在输入为0附近的时候输出接近于线性,使得网络更容易学习到线性相关的特征。另外,tanh 函数具有对称性,在处理序列数据时能够更好地捕捉序列中的长期依赖关系。
因此,使用tanh作为LSTM输入层的激活函数是比较常见的做法。
c. Cell State
首先前一层的细胞状态与遗忘向量逐点相乘。如果它乘以接近 0 的值,意味着在新的细胞状态中,这些信息是需要丢弃掉的。然后再将该值与输入门的输出值逐点相加,将神经网络发现的新信息更新到细胞状态中去。至此,就得到了更新后的细胞状态。
d. 输出门:Output Gate
输出门用来确定下一个隐藏状态的值,隐藏状态包含了先前输入的信息。首先,我们将前一个隐藏状态和当前输入传递到 sigmoid 函数中,然后将新得到的细胞状态传递给 tanh 函数。最后将 tanh 的输出与 sigmoid 的输出相乘,以确定隐藏状态应携带的信息。再将隐藏状态作为当前细胞的输出,把新的细胞状态和新的隐藏状态传递到下一个时间步长中去。
在LSTM层中,每个时间步上的计算涉及到许多参数,包括输入、遗忘和输出门的权重,以及当前时间步和前一个时间步的输出和记忆之间的权重。这些参数在模型训练过程中通过反向传播进行学习,以最小化模型在训练数据上的损失函数。总之,LSTM通过门的控制,使得信息在传递过程中可以有选择地被遗忘或更新,从而更好地捕捉长序列之间的依赖关系,广泛应用于语音识别、自然语言处理等领域。
LSTM的输出可以是它的最终状态(最后一个时间步的隐藏状态)或者是所有时间步的隐藏状态序列。通常,LSTM的最终状态可以被看作是输入序列的一种编码,可以被送入其他层进行下一步处理。如果需要使用LSTM的中间状态,可以将return_sequences参数设置为True,这样LSTM层将返回所有时间步的隐藏状态序列,而不是仅仅最终状态。
需要注意的是,LSTM层在处理长序列时容易出现梯度消失或爆炸的问题。为了解决这个问题,通常会使用一些技巧,比如截断反向传播、梯度裁剪、残差连接等
参数详解
layers.LSTM 是一个带有内部状态的循环神经网络层,其中包含了多个可训练的参数。具体地,LSTM层的输入是一个形状为(batch_size, timesteps, input_dim)的三维张量,其中batch_size表示输入数据的批次大小,timesteps表示序列数据的时间步数,input_dim表示每个时间步的输入特征数。LSTM层的输出是一个形状为**(batch_size, timesteps, units)的三维张量,其中units表示LSTM层的输出特征数**。以下是各个参数的详细说明:
units:LSTM 层中的单元数,即 LSTM 层输出的维度。activation:激活函数,用于计算 LSTM 层的输出和激活门。recurrent_activation:循环激活函数,用于计算 LSTM 层的循环状态。use_bias:是否使用偏置向量。kernel_initializer:用于初始化 LSTM 层的权重矩阵的初始化器。recurrent_initializer:用于初始化 LSTM 层的循环权重矩阵的初始化器。bias_initializer:用于初始化 LSTM 层的偏置向量的初始化器。unit_forget_bias:控制 LSTM 单元的偏置初始化,如果为 True,则将遗忘门的偏置设置为 1,否则设置为 0。kernel_regularizer:LSTM 层权重的正则化方法。recurrent_regularizer:LSTM 层循环权重的正则化方法。bias_regularizer:LSTM 层偏置的正则化方法。activity_regularizer:LSTM 层输出的正则化方法。dropout:LSTM 层输出上的 Dropout 比率。recurrent_dropout:LSTM 层循环状态上的 Dropout 比率。return_sequences: 可以控制LSTM的输出形式。如果设置为True,则输出每个时间步的LSTM的输出,如果设置为False,则只输出最后一个时间步的LSTM的输出。因此,return_sequences的默认值为False,如果需要输出每个时间步的LSTM的输出,则需要将其设置为True。
这些参数的不同设置将直接影响到 LSTM 层的输出和学习能力。需要根据具体的应用场景和数据特点进行选择和调整。
tf.keras.layers.LSTM(
units,
activation=“tanh”,
recurrent_activation=“sigmoid”, #用于重复步骤的激活功能
use_bias=True, #是否图层使用偏置向量
kernel_initializer=“glorot_uniform”, #kernel权重矩阵的 初始化程序,用于输入的线性转换
recurrent_initializer=“orthogonal”, #权重矩阵的 初始化程序,用于递归状态的线性转换
bias_initializer=“zeros”, #偏差向量的初始化程序
unit_forget_bias=True, #则在初始化时将1加到遗忘门的偏置上
kernel_regularizer=None, #正则化函数应用于kernel权重矩阵
recurrent_regularizer=None, #正则化函数应用于 权重矩阵
bias_regularizer=None, #正则化函数应用于偏差向量
activity_regularizer=None, #正则化函数应用于图层的输出(其“激活”)
kernel_constraint=None,#约束函数应用于kernel权重矩阵
recurrent_constraint=None,#约束函数应用于 权重矩阵
bias_constraint=None,#约束函数应用于偏差向量
dropout=0.0,#要进行线性转换的输入单位的分数
recurrent_dropout=0.0,#为递归状态的线性转换而下降的单位小数
return_sequences=False,#是否返回最后一个输出。在输出序列或完整序列中
return_state=False,#除输出外,是否返回最后一个状态
go_backwards=False,#如果为True,则向后处理输入序列并返回反向的序列
stateful=False,#如果为True,则批次中索引i的每个样本的最后状态将用作下一个批次中索引i的样本的初始状态。
time_major=False,
unroll=False,#如果为True,则将展开网络,否则将使用符号循环。展开可以加快RNN的速度,尽管它通常会占用更多的内存。展开仅适用于短序列。
)
参数计算
对于一个LSTM(长短期记忆)模型,参数的计算涉及输入维度、隐藏神经元数量和输出维度。在给定输入维度为(64,32)和LSTM神经元数量为32的情况下,我们可以计算出以下参数:
输入维度:(64,32)
这表示每个时间步长(sequence step)的输入特征维度为32,序列长度为64。隐藏神经元数量:32
这是指LSTM层中的隐藏神经元数量。每个时间步长都有32个隐藏神经元。输入门参数:
- 权重矩阵:形状为(32,32 + 32)的矩阵。其中32是上一时间步的隐藏状态大小,另外32是当前时间步的输入维度。
- 偏置向量:形状为(32,)的向量。
遗忘门参数:
- 权重矩阵:形状为(32,32 + 32)的矩阵。
- 偏置向量:形状为(32,)的向量。
输出门参数:
- 权重矩阵:形状为(32,32 + 32)的矩阵。
- 偏置向量:形状为(32,)的向量。
单元状态参数:
- 权重矩阵:形状为(32,32 + 32)的矩阵。
- 偏置向量:形状为(32,)的向量。
输出参数:
- 权重矩阵:形状为(32,32)的矩阵。将隐藏状态映射到最终的输出维度。
- 偏置向量:形状为(32,)的向量。
因此,总共的参数数量可以通过计算上述所有矩阵和向量中的元素总数来确定。
实际场景
当使用LSTM(长短期记忆)神经网络进行时间序列预测时,可以根据输入和输出的方式将其分为四种类型:单变量单步预测、单变量多步预测、多变量单步预测和多变量多步预测。
单变量单步预测:
- 输入:只包含单个时间序列特征的历史数据。
- 输出:预测下一个时间步的单个时间序列值。
- 例如,给定过去几天的某股票的收盘价,使用LSTM进行单变量单步预测将预测未来一天的收盘价。
单变量多步预测:
- 输入:只包含单个时间序列特征的历史数据。
- 输出:预测接下来的多个时间步的单个时间序列值。
- 例如,给定过去几天的某股票的收盘价,使用LSTM进行单变量多步预测将预测未来三天的收盘价。
多变量单步预测:
- 输入:包含多个时间序列特征的历史数据。
- 输出:预测下一个时间步的一个或多个时间序列值。
- 例如,给定过去几天的某股票的收盘价、交易量和市值等特征,使用LSTM进行多变量单步预测可以预测未来一天的收盘价。
多变量多步预测:
- 输入:包含多个时间序列特征的历史数据。
- 输出:预测接下来的多个时间步的一个或多个时间序列值。
- 例如,给定过去几天的某股票的收盘价、交易量和市值等特征,使用LSTM进行多变量多步预测将预测未来三天的收盘价。
这些不同类型的时间序列预测任务在输入和输出的维度上略有差异,但都可以通过适当配置LSTM模型来实现。具体的模型架构和训练方法可能会因任务类型和数据特点而有所不同。

🤞到这里,如果还有什么疑问🤞
🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩
🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳
- 点赞
- 收藏
- 关注作者
评论(0)