深入了解PyTorch:功能与基本元素操作

🍀简介:
在机器学习和深度学习领域中,PyTorch已经成为一个备受关注和广泛使用的深度学习框架。作为一个用于科学计算的开源库,PyTorch提供了丰富的工具和功能,使得研究人员和开发者能够更加方便地构建、训练和部署深度学习模型。在本篇博客中,我们将深入了解PyTorch的功能以及其基本元素操作,帮助读者更好地了解和使用这一强大的工具。
🍀什么是PyTorch?
PyTorch是一个基于Python的科学计算库,特别适用于构建深度神经网络模型。它具备灵活性和可扩展性,使得用户能够使用自定义的计算图来定义和训练模型。此外,PyTorch提供了丰富的工具和接口,帮助用户进行数据加载、优化、模型保存等常见任务。
🍀PyTorch的功能
动态计算图:
PyTorch使用动态计算图作为其核心概念,这意味着在模型训练过程中可以动态地定义计算图。相比于静态计算图,动态计算图使得模型的构建和调试更加灵活方便。模型构建和训练:
PyTorch提供了简洁高效的API,如nn.Module和nn.Sequential,用于定义和构建深度学习模型。用户可以根据自己的需求,自由地设计和组合不同层和模块。同时,PyTorch还集成了优化器,如SGD、Adam等,方便用户进行模型训练和优化。GPU加速计算:
PyTorch支持在GPU上进行张量计算和模型训练,通过使用CUDA库,可以显著提升计算性能。这对于处理大规模的数据集和复杂的模型非常有帮助。数据处理和加载:
PyTorch提供了强大的工具和函数,用于数据的处理和加载。通过使用torchvision、torchtext、torchaudio等库,用户可以方便地进行图像、文本、音频等数据类型的处理和加载。
🍀基本元素操作
在进行操作之前先引入一个令人头痛的概念张量
张量(Tensor):
张量是PyTorch中最基本的数据结构,相当于多维数组。它可以表示标量、向量、矩阵以及更高维度的数据。张量可以通过torch.tensor函数创建,也可以通过张量操作从已有的数据中创建。
接下来介绍一些基本的操作,首先需要导入库
import torch
# 创建一个没有初始化的矩阵
x = torch.empty(5, 3)
print(x)
# 创建一个有初始化的矩阵
y = torch.rand(5,2) # 遵循标准高斯分布
print(y)
# 创建一个全零矩阵并指定数据元素类型为int
z = torch.zeros(5, 5, dtype=torch.int)
print(z)
# 直接通过数据创建张量
l = torch.tensor([1.1, 2.2])
print(l)
# 通过已有的一个张量创建相同尺寸的新张量
x = x.new_ones(5, 5, dtype=torch.double)
print(x)
# 利用randn_like方法得到相同尺寸的张量,并且采用随机初始化的方法为其赋值
y = torch.randn_like(x, dtype=torch.float)
print(y)
# 采用.size()方法来得到张量的形状
print(x.size()) # 返回的是一个元组,故支持元组的操作
a, b = x.size()
print('a=', a, 'b=', b)

张量和矩阵在数学上是相关的概念,它们都可以用来存储和表示多维数据。下面是它们之间的区别和联系
| 区别 | 联系 |
|---|---|
| 维度:矩阵是二维的,具有行和列的结构,而张量可以是任意维度的,可以具有多个轴。 | 张量可以被看作是矩阵的扩展,矩阵可以被视为特殊的二维张量。 |
| 元素个数:矩阵中的元素数量由行数和列数确定,而张量的元素数量取决于各个维度的长度。 | 在机器学习和深度学习中,矩阵常用于表示权重矩阵和输入特征矩阵,而张量用于表示更高维度的数据和神经网络中的激活值、梯度等。 |
| 张量的灵活性:张量可以表示多种数据结构,包括标量、向量、矩阵以及更高阶的数据。 | – |
总结来说,矩阵是张量的一种特殊情况,张量是对多维数据的通用表示,其中矩阵是二维的特例。张量的概念提供了一种更通用和灵活的数据结构,适用于处理更复杂和高维的数据,而矩阵则是其中的一种常见形式。
🍀基本运算操作
# 第一种加法操作
x = torch.empty(5, 5)
y = torch.randn(5, 5)
print(x+y)
# 第二种加法操作
print(torch.add(x, y))
# 第三种加法操作
# 提前设定一个空的张量
result = torch.empty(5, 5)
# 将空的张量作为加法的结果存储张量
torch.add(x, y, out=result)
print(result)
# 第四种加法方式,原地置换,可以理解为y=y+x
y.add_(x)
print(y)
注意:所有的原地置换,都会在结尾加一个下划线
类似加法的其余运算操作与加法相似,这里就不一一介绍了
# 与numpy的语法几乎无缝衔接
x = torch.rand(5, 5)
print(x[:, 1])
# 改变张量的形状
# tensor.view()操作需要保证数据元素的总数量不变
y = x.view(25)
# -1表示自动匹配个数
z = x.view(-1, 25)
print(x.size(),y.size(),z.size())
运行结果如下
# 如果张量只有一个元素,可以用.item()将值取出,作为一个Python number
x = torch.randn(1)
print(x)
print(x.item())
运行结果如下
那如果是两个元素,是否真的会报错呢???我们来测试一下
x = torch.randn(2)
print(x)
print(x.item())
运行结果如下
🍀类型转换
Torch Tensor和Numpy array共享底层的内存空间,所有改变一个另一个也会改变
# Torch Tensor 转化为 Numpy array
x = torch.ones(5)
print(x)
y = x.numpy()
print(y)
x.add_(1)
print(x)
print(y)
运行结果如下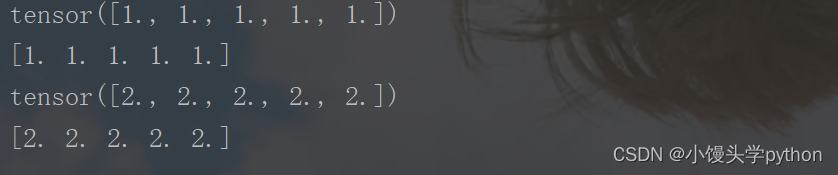
或许有人会提出疑问,进行加法操作的是x,那么y为何会改变呢,这就是因为本节一开始提到的共享
# Numpy array 转化为 Torch Tensor
# 这里需要导入numpy
import numpy as np
x = np.ones(5)
y = torch.from_numpy(x)
np.add(x, 1, out=x)
print(x)
print(y)
运行结果如下
注意:所有运行在内存的Tensors,除了 Char Tensor,都可以转换为Numpy array,并且可以相互转换
# 关于Cuda Tensor可以用.to()方法来将其移动到任意设备上
# 如果服务器已经安装了GPU和CUDA
if torch.cuda.is_available():
# 定义一个设备对象,这里指定为CUDA,就是使用GPU
device = torch.device('cuda')
# 直接在GPU上创建一个Tensor
y = torch.ones_like(x, device=device)
# 将CPU上的张量移动在GPU上
x = x.to(device)
# x和y都在GPU上面,才能支持加法运算
z = x + y
# 这里的张量在GPU上
print(z)
# 这里也可以将z转移到CPU上面
print(z.to('cpu', torch.double))
运行结果如下
🍀总结
本篇文章是在b站学习后完成的,若有人想了解视频可以点击Python人工智能20个小时玩转NLP自然语言处理【黑马程序员】

- 点赞
- 收藏
- 关注作者
评论(0)