Spring事务详解 —— 由浅入深彻底搞定 @Transactional注解

前言
@Transactional 注解是我们在使用spring 相关内容时,经常需要使用的,网络上亦容易找到其使用方法和解析。我们在这里结合笔者的使用经验来,深入讨论一下 @Transactional 注解
我们在讨论Spring 的事务前,必须先了解计算机领域的“事务”,代表着什么含义。事务 其实就是一种机制,我们常说某某中间件支持“事务”,那么就代表他能实现事务的几种特性
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
- 原子性(atomicity):一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
- 一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
- 隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
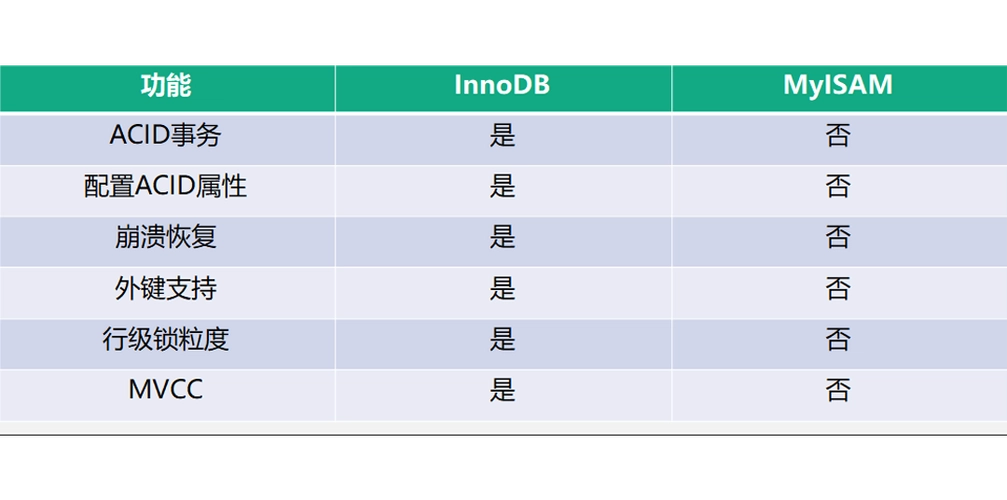
我们在Spring里说的事务,实际指的是在数据库操作上保持事务,然而这种事务的能力是源自于数据库本身,比如我们可以用 Mysql 的 innoDB 引擎,该引擎就支持事务。那么既然Spring本身和事务无关,为什么会谈到Spring事务呢 ?
实际上Spring事务指的是,在数据库支持事务的基础上,Spring可以通过简单的配置来控制事务的各个方面,最终达到我们业务上需要的效果。如果你把Spring去掉,手工使用jdbc去对接数据库,也能达到相同的效果,但是就需要大量额外的控制代码了
我们首先必须要知道这个注解是哪个包提供的,实际上作为开发,我们很多时候使用spring系列都是全家桶,一口气引用了很多包。写代码就直接依赖,往往忽略了这个类或注解是谁提供的,这将模糊我们对开源组件的结构理解,个人认为是个不好的习惯。
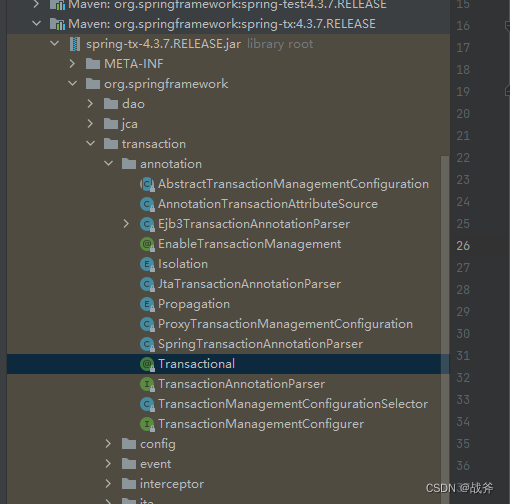
我们可以看到,这个注解来源于Spring框架的 spring-tx 包,这个包的名字就已经说明这个包是专用来完成事务功能的
在使用这个注解前,你必须得有一个spring 或者 springboot 工程,我们在这里以spingboot项目为例,其实因为springboot的自动配置机制,使得如果我们引用了starter-jdbc等包的情况下,会自动向容器中添加事务管理器,所以允许不在主类上标注 @EnableTransactionManagement,此处写是从Spring项目留下的习惯
@SpringBootApplication
//开启事务
@EnableTransactionManagement
public class TransactionalApplication {
public static void main(String[] args) {
SpringApplication.run(TransactionalApplication.class, args);
}
}
然后我们就可以在Spring 的 Bean 上使用@Transactional 注解了,我们来看该注解可以用在什么地方
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
public @interface Transactional {
......
}
ElementType.METHOD, ElementType.TYPE 这两个标记表明了该注解可以使用在方法上和类上。我们可以提前说下两者各自的效果
- 用在方法上此方法具有事务属性,只有public修饰的方法才生效。protected,private和default修饰的方法上不生效,也不会抛出任何异常。
- 当作用于类上时,该类的所有 public 方法将都具有该类型的事务属性
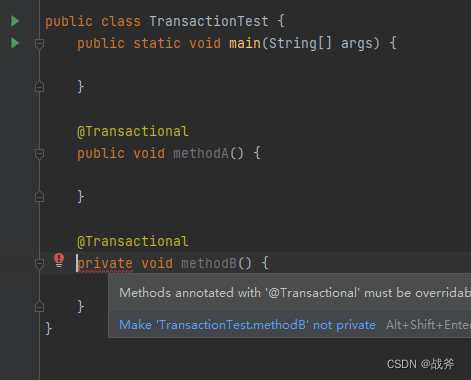
当然,从个人经验来看,两者各有利弊,注解在方法上自然是更灵活,但是如果是注解在接口方法中,又容易出现动态代理的问题,比如Springboot2 默认使用的 CGlib 动态代理,采用的是子类继承的方法,如果你在接口上使用,此时自然会失效乃至报错
要想合理使用这个注解,我们还是得从注解本身的信息入手,我们先看一下这个注解提供了哪些属性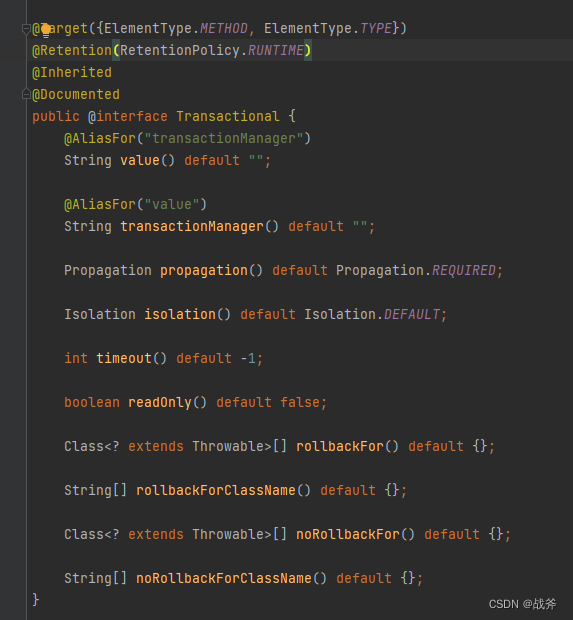
- value 和 transactionManager
它们两个是一样的意思。当配置了多个事务管理器时,可以使用该属性指定选择哪个事务管理器 - propagation
事务的传播行为,默认值为 Propagation.REQUIRED - isolation
事务的隔离级别,默认值为 Isolation.DEFAULT - timeout
事务的超时时间,默认值为-1(不设置)。如果超过该时间限制但事务还没有完成,则自动回滚事务 - readOnly
指定事务是否为只读事务,默认值为 false;为了忽略那些不需要事务的方法,比如读取数据,可以设置 read-only 为 true - rollbackFor
用于指定能够触发事务回滚的异常类型,可以指定多个异常类型。 - noRollbackFor
抛出指定的异常类型,不回滚事务,也可以指定多个异常类型。
那么接下来我将逐一讲解这些属性的作用。
Spring 在事务管理器的处理上,是定义了一个接口 PlatformTransactionManager ,这个接口只有三个方法,也是我们最常用的关于事务的动作:
- getTransaction 获取(创建)一个事务
- commit 事务提交
- rollback 事务回滚
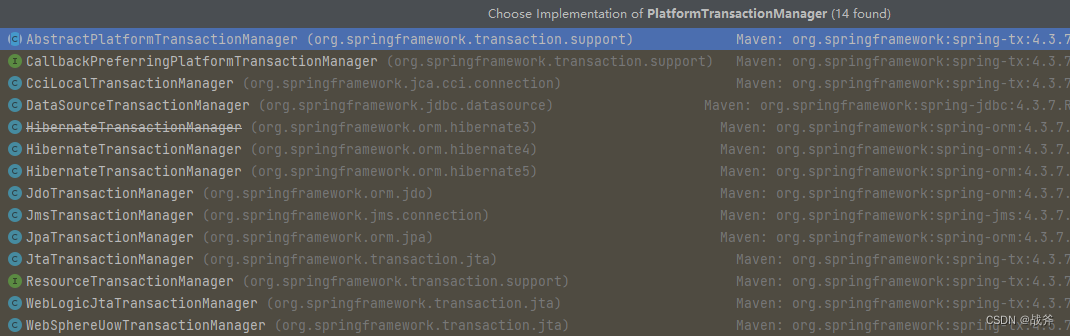
然后 Spring 内置了大量的事务管理器的实现,为什么会有这么多种呢?主要还是不同的数据源情况,不同的传播需要,为了兼顾这些情况,所以此处可以手动去指定。最常用的,也是默认的事务管理器就是DataSourceTransactionManager
事务本身并没有传播概念,所谓的”传播“其实是Spring为了方便开发者管理事务而引入的概念。比如说我们开启了个事务,然后开始执行代码,但是java的代码往往会调用多个对象和方法,那些方法是否需要加入到事务中,或者使用新的事务,其实是需要人规定的。所以传播行为其实就是用来描述事务在多个方法间是怎样流转的
Spring 定义了7种传播规则,当然,我们需要知道,不是所有的事务管理器都支持7种规则,如HibernateTransactionManager 只支持三种REQUIRE 、 REQUIRE_NEW 、 NOT_SUPPORT
我们先简单介绍下这几种规则:
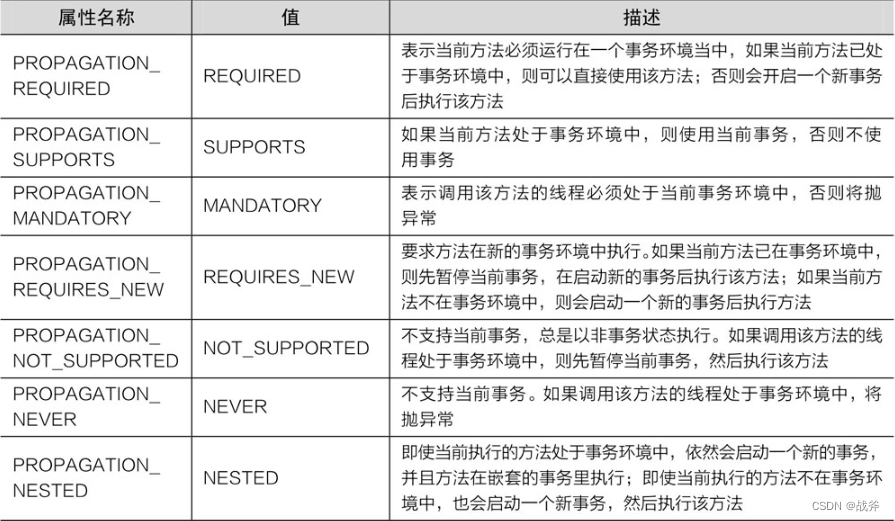
我可以举个例子,
比如我们经常苦恼rabbitMq消息 和 业务代码不构成事务,说发就发出去了,如果后续代码出现异常,发出去的消息却撤不回来。所以想把 “发mq消息” 和 “执行普通代码” 做成事务,策略是要发mq之前先把消息落库,如果普通代码执行成功,再发送消息。如果普通代码执行失败,触发回滚,落库的mq消息自然也会被回滚掉,mq消息取消发送。
不难发现,在这种场景下,就需要发这种mq消息时,必须处在一个事务里,因此,发送这种mq的方法就可以加上@Transactional注解,传播方式则是MANDATORY
不同于”传播规则“是Spring提到的概念。隔离级别这个概念是数据库事务自带的,其目的是当存在多个事务时,如果这些事务访问到了共同的资源,该怎么处理事务间的数据隔离。一般来说数据库存在四种隔离级别,Spring则是定义了五种。它们分别如下
- DEFAULT 用数据库的设置隔离级别,数据库设置的是什么我就用什么
- UNCOMMITTED:读未提交,最低隔离级别、事务未提交前,就可被其他事务读取
- COMMITTED:读已提交,一个事务提交后才能被其他事务读取到
- REPEATABLE_READ:可重复读,本事务会建立快照,在快照建立前其他事务提交的内容可见,快照后提交的内容不可见
- SERIALIZABLE:序列化,事务必须一个执行完才允许建下个事务,隔离级别最高
这里面有两点需说明:
- 数据库事务的隔离级别有两种,一种是全局的,一种是会话的,与数据库建立连接后,可以为本会话设置隔离级别。如果不设置,则会使用数据库的隔离级别。这也就是Spring能指定隔离级别的原因,其实际上指定的是当前会话的隔离级别
- 数据库的隔离级别是数据库事务的重要内容,我们会在后续详解Mysql的时候,仔细说明各隔离级别的实现和其特点
我们前面说到,在@Transactional注解上可以填写超时时间,而它的单位是秒。但关于超时时间的设置有很多问题,或者说陷阱,希望大家通过学习后能够避开。
首先 timeout 的设置只适用于以下两种传播规则: REQUIRED 和 REQUIRES_NEW,其他的传播规则只允许超时默认值 -1 (即永不超时),否则会抛出异常
另外此处的超时时间,其实是在判断最后一个SQL执行前是否超时,我们以一个经典案例来说明
@Transactional(timeout = 2)
public void methodA(UserInfo info) {
userDao.updateInfo(info);
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Transactional(timeout = 2)
public void methodB(UserInfo info) {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
userDao.updateInfo(info);
}
我们不难看出,事务限时2秒,但方法执行至少3秒。那结果会如何呢?这里methodA不会报错,methodB会报错,但是是在第三秒(即线程恢复,开始执行Sql前)才报的错。
其原因是事务开启时,会读取当前时间 和 timeout 的值,并将其相加得到事务“过期时间”,而在每次执行sql前则会获取到statement,此时才会判断当前时间是否已超期,超期才会抛出超时异常。也就是说,通俗的理解,只有在每次执行SQL前,才会判断下是否已超过事务限时。
这里的只读是对开发者的提示,并不意味着你标注只读就真的不能写更新语句。实际上你更新,出错后回滚等功能都还是正常的。甚至该标注也支持 SUPPORTS 传播规则,说明即使没有开启事务也无妨。
我们可以看原文注释
This just serves as a hint for the actual transaction subsystem; it will not necessarily cause failure of write access attempts.A transaction manager which cannot interpret the read-only hint will not throw an exception when asked for a read-only transaction.return
这只是作为实际事务子系统的提示,它不一定会导致写访问尝试失败。不能理解只读提示的事务管理器在请求只读事务时也不会抛出异常
这里就是说你可以显式的指定什么异常需要回滚,什么异常不需要回滚。比方说我们有一种邮件通知异常,代表通知邮件发送失败,但这种异常无伤大雅,只是非核心功能,失败了不需要导致整个业务失败。此时我们可以指定这种异常不需要回滚事务。
我们可以看看提到的默认需要回滚的异常
By default, a transaction will be rolling back on RuntimeException and Error but not on checked exceptions business exceptions
默认情况下,事务将在RuntimeException和Error上回滚,但不会在受检异常(业务异常)上回滚
@Transactional 注解之所以好用,是因为对开发者来说,不需要写额外的控制代码。然而,我们知道对事务的控制必不可少,而这部分代码其实全都被放进了“代理”中,我们如果把没有代理的Bean比作小鸡,那么普通小鸡,和被代理的小鸡的工作模式如下图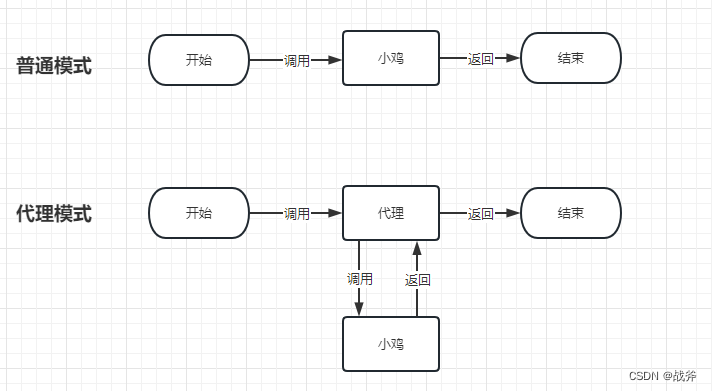
被代理过的小鸡,能够执行代理对象里给定的方法,同时也能继续调用小鸡本身的方法,这就是Spring的重要特性 —— AOP,此处就是利用代理对原有的功能进行了增强,在增强的方法里加入了关于事务管理的内容
我们可以利用@EnableTransactional注解来启用事务,其原因就是使用该注解后,Spring会创建一个针对事务增强的Advisor ,该Advisor可以扫描标注有@Transctional的地方。同时,Spring还启用了一个可以利用Advisor来创建代理的 后置处理器,这样在Bean被创建时,后置处理器发挥作用,开始搜寻所有Advisor(包括我们这个事务的advisor),最终为这个Bean创建出代理对象,这个代理对象,就能进行事务的配置
其具体流程。可以见下图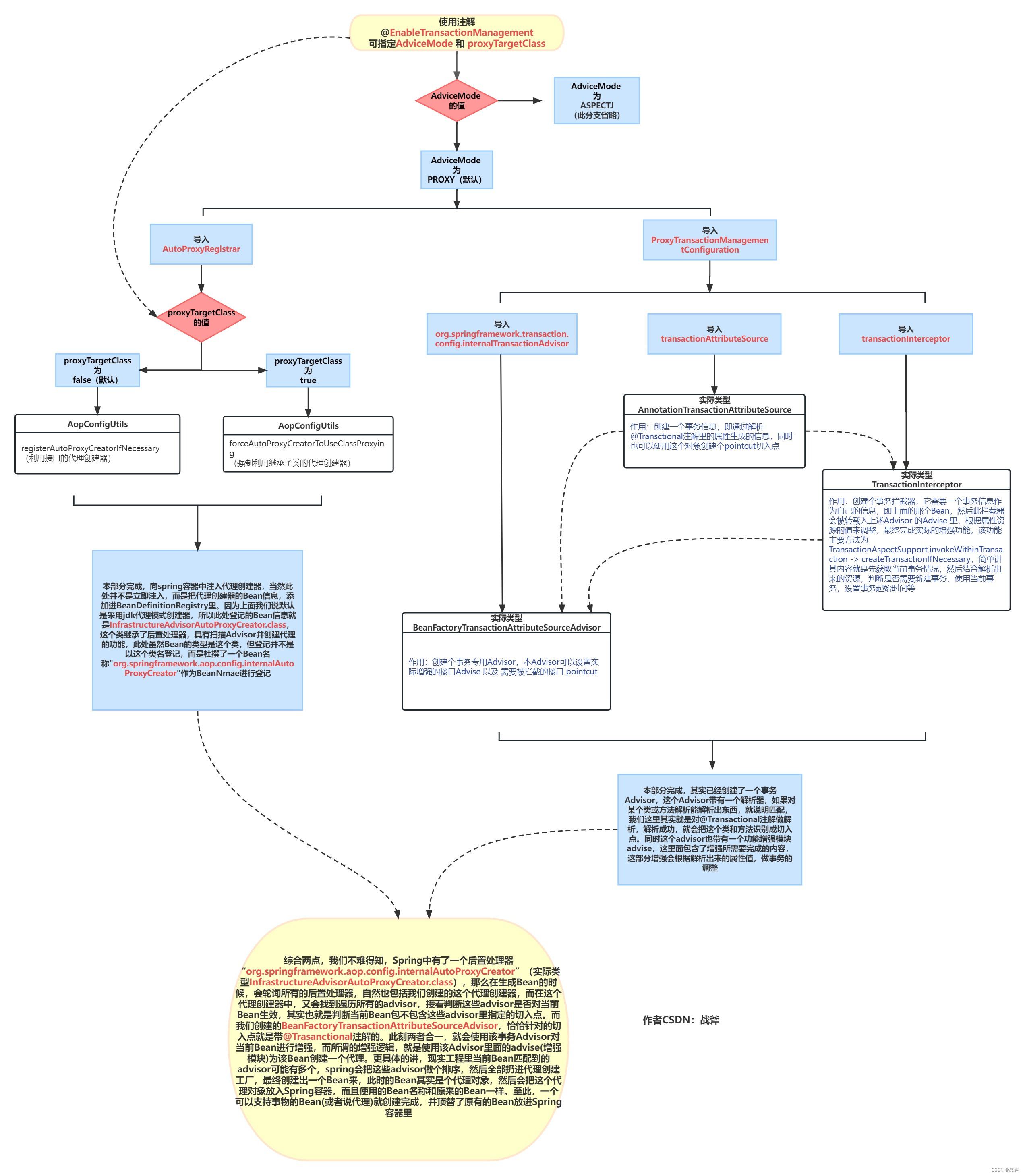
我们上面看了,一个带有事务功能的代理对象被创建,那么这个代理到底干了些什么呢?是怎么管理事务的呢?如果按上面的流程图,此处的拦截器为TransactionInterceptor,其增强部分的方法为TransactionAspectSupport.invokeWithinTransaction
其源码如下:
protected Object invokeWithinTransaction(Method method, Class<?> targetClass, final InvocationCallback invocation)
throws Throwable {
// 如果事务的属性为空,代表这个方法不需要事务
final TransactionAttribute txAttr = getTransactionAttributeSource().getTransactionAttribute(method, targetClass);
// 根据注解里的属性选择事务管理器
final PlatformTransactionManager tm = determineTransactionManager(txAttr);
final String joinpointIdentification = methodIdentification(method, targetClass, txAttr);
if (txAttr == null || !(tm instanceof CallbackPreferringPlatformTransactionManager)) {
// 使用getTransaction和commit/rerollback调用进行标准事务划分。
// 如果有需要,则创建事务
TransactionInfo txInfo = createTransactionIfNecessary(tm, txAttr, joinpointIdentification);
Object retVal = null;
try {
// This is an around advice: Invoke the next interceptor in the chain.
// This will normally result in a target object being invoked.
retVal = invocation.proceedWithInvocation();
}
catch (Throwable ex) {
// target invocation exception
completeTransactionAfterThrowing(txInfo, ex);
throw ex;
}
finally {
cleanupTransactionInfo(txInfo);
}
// 方法执行完,返回后提交事务
commitTransactionAfterReturning(txInfo);
return retVal;
}
else {
// It's a CallbackPreferringPlatformTransactionManager: pass a TransactionCallback in.
try {
Object result = ((CallbackPreferringPlatformTransactionManager) tm).execute(txAttr,
new TransactionCallback<Object>() {
@Override
public Object doInTransaction(TransactionStatus status) {
TransactionInfo txInfo = prepareTransactionInfo(tm, txAttr, joinpointIdentification, status);
try {
return invocation.proceedWithInvocation();
}
catch (Throwable ex) {
if (txAttr.rollbackOn(ex)) {
// A RuntimeException: will lead to a rollback.
if (ex instanceof RuntimeException) {
throw (RuntimeException) ex;
}
else {
throw new ThrowableHolderException(ex);
}
}
else {
// A normal return value: will lead to a commit.
return new ThrowableHolder(ex);
}
}
finally {
cleanupTransactionInfo(txInfo);
}
}
});
// Check result: It might indicate a Throwable to rethrow.
if (result instanceof ThrowableHolder) {
throw ((ThrowableHolder) result).getThrowable();
}
else {
return result;
}
}
catch (ThrowableHolderException ex) {
throw ex.getCause();
}
}
}
本文并不会针对源码层层展开,想看源码的上面已经给了具体的类和方法,可以自行阅览。这里只对关键部分进行表述。
我们使用代理来实现事务,那么代理的基本功能或者说基本目的是什么呢?相信大家都明白,是在方法开始前新建一个事务 ,设置自动提交为否,方法结束后手动提交(上面代码已展示)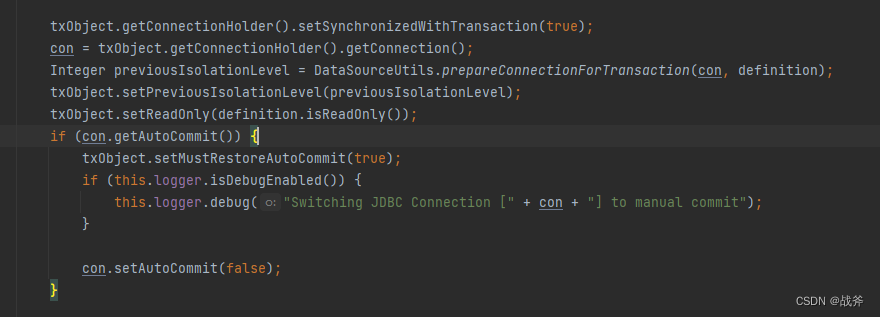
我们看到前述方法 invokeWithinTransaction 中,有一步“如果需要则创建事务”,而这里面第一步就是要获取事务,更准确的说是获取对数据库的连接。
这里面就用到了threadLocal,每一个线程都会去“TransactionSynchronizationManager”(事务同步管理器)中获取连接(内部包含一个对数据库的连接)。因为threadLocal的特性,我们知道,连接对象其实是存储在线程内的。而连接是事务的根基,把连接存于线程内,随着线程去经历不同方法,这是Spring事务能在不同方法间传播的基础保证
关于 Threadlocal 的解析,可以看我的另一篇博文: 图解,深入浅出带你理解ThreadLocal
从里我们知道,线程会先取出自己存着的事务对象(连接)。此处就有三种情况了:
- 没有取到连接,即本线程还未连接数据库
- 有连接但连接并没有开启事务
- 有连接且已经开启事务
从事务角度看,就是两种情况,当前在事务中,或当前不在事务中。因此对于同一个传播属性就有两套逻辑了,举例来说,如果是@Transactional 里设置了传播属性是 REQUIRE,
那么如果当前有事务,则直接在这个事务内运行方法,如果当前没事务,就得新建事务,再在新建的事务内运行了
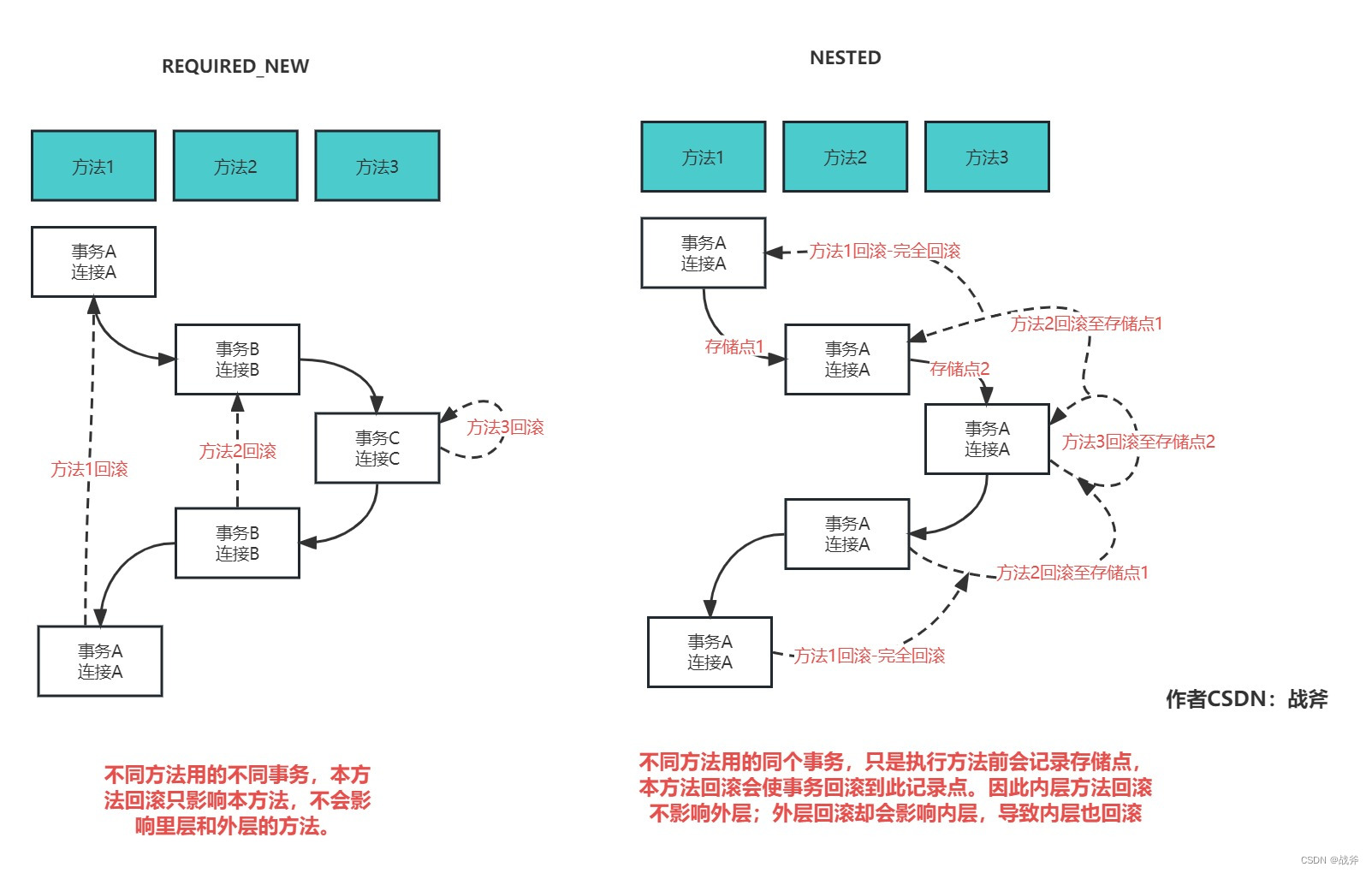
这里面比较特殊的是嵌套 NESTED 和 REQUIRED_NEW,为什么这么说?因为使用 这两种传播形式,即使当前已经有事务(连接),也必须新建一个事务(连接)。但我们说了,连接是以threadLocal的形式存在线程内的,而且只存了一个。那么这种情况,就会出现个问题: 新建事务(连接)后,原连接怎么处理?
对于 QUIRED_NEW 的处理,就是把当前信息的事务信息复制一份存起来并挂起,然后根据@Transacional注解里的属性重新填充当前事务信息,并重新取得一个连接。利用新的事务属性和新的连接去执行接下来的方法。因为是两个独立的连接与事务,所以外层方法和内部方法互不干涉,内部方法回滚,外部会毫无反应(除非你把异常往外抛,导致每层方法都吃到异常,那么每层都会回滚)
对于 NESTED 的处理,则利用了JDBC连接可以创建保存点的特性,会在此setSavePoint创建个保存点并保存下来。因为事实上用的同一个连接,中间有个保存点,所以一旦本方法内需要回滚,Spring会使用 rollback(savepoint) 恢复到本保存点,而不会全部回滚。但是如果是外部方法要回滚,就是全部回滚掉了

- 点赞
- 收藏
- 关注作者
评论(0)