GaussDB(DWS)锁问题全解

一、gaussdb有哪些锁
1、常规锁:常规锁主要用于业务访问数据库对象的加锁,保护并发操作的对象,保持数据一致性;常见的常规锁有表锁(relation)和行锁(tuple)。
表锁:当对表进行DDL、DML操作时,会对操作的对象表加锁,在事务结束释放。
行锁:使用select for share语句时持有该模式锁,后台会对tuple加5级锁;使用select for update, delete, update等操作时,后台会对tuple加7级锁(ExclusiveLock)。
2、轻量级锁:轻量级锁主要用于数据库内部共享资源访问的保护,比如内存结构、共享内存分配控制等。
二、锁冲突矩阵
1、常规锁按照粒度可分为8个等级,各操作对应的锁等级及锁冲突情况参照下表:
锁编号 |
锁模式 |
对应操作 |
冲突的锁编号 |
1 |
ACCESS SHARE |
SELECT |
8 |
2 |
ROW SHARE |
SELECT FOR UPDATE、SELECT FOR SHARE |
7,8 |
3 |
ROW EXCLUSIVE |
INSERT、DELETE、UPDATE |
5,6,7,8 |
4 |
SHARE UPDATE EXCLUSIVE |
VACUUM、ANALYZE |
4,5,6,7,8 |
5 |
SHARE |
CREATE INDEX |
3,4,6,7,8 |
6 |
SHARE ROW EXCLUSIVE |
- |
3,4,5,6,7,8 |
7 |
EXCLUSIVE |
- |
2,3,4,5,6,7,8 |
8 |
ACCESS EXCLUSIVE |
DROP TABLE、ALTER TABLE、REINDEX、CLUSTER、VACUUM FULL、TRUNCATE |
1,2,3,4,5,6,7,8 |
2、几种锁冲突的场景:
ACCESS SHARE与ACCESS EXCLUSIVE锁冲突例子:session 1 在事务内对表进行truncate,且lockwait_timeout参数设置为10s;session 2 查询该表,此时会一直等到session 1 释放锁,直到等锁超时。


ROW SHARE(行锁冲突的例子):并发insert/update/copy;session 1在事务内对有主键约束的行存表进行更新;session 2对同一主键的行进行更新,会一直等待session 1释放锁,直到行锁超时;


并发更新列存表出现等锁超时,该现象一般为并发更新同一CU造成的;

场景构造:session 1在事务内对列存表进行更新,不提交事务;session 2同样对列存表更新,会等锁超时;(只有更新的为同一CU时才会出现此场景)
列存表并发等锁原理:https://bbs.huaweicloud.com/blogs/255895 ;
三、锁相关视图
pg_locks视图存储各打开事务所持有的锁信息,需关注的字段:locktype(被锁定对象的类型)、relation(被锁定对象关系的OID)、pid(持锁或等锁的线程ID)、mode(持锁或等锁模式)、granted(t:持锁,f:等锁)。

pgxc_lock_conflicts视图提供集群中有冲突的锁的信息(适合锁冲突现场还在时使用),目前只收集locktype为relation、partition、page、tuple和transactionid的锁的信息,需要关注的字段nodename(被锁定对象节点的名字)、queryid(申请锁的查询ID)、query(申请锁的查询语句)、pid、mode、granted。
pgxc_deadlock视图获取导致分布式死锁产生的锁等待信息,只收集locktype为relation、partition、page、tuple和transactionid的锁等待信息。
四、锁相关参数介绍
lockwait_timeout:控制单个锁的最长等待时间。当申请的锁等待时间超过设定值时,系统会报错,即等锁超时,一般默认值为20min。
deadlock_timeout:死锁检测的超时时间,当申请的锁超过该设定值仍未获取到时,触发死锁检测,系统会检查是否产生死锁,一般默认值为1s。
update_lockwait_timeout:允许并发更新参数开启时,控制并发更新同一行单个锁的最长等待时间,超过该设定值,会报错,一般默认值为2min。
以上参数的单位均为毫秒,请保证deadlock_timeout的值小于lockwait_timeout,否则将不会触发死锁检测。
五、锁等待超时排查
https://bbs.huaweicloud.com/blogs/280354
六、为什么会死锁(单节点死锁)
1、死锁:两个及以上不同的进程实体在运行时因为竞争资源而陷入僵局,除非外力作用,否则双发都无法继续推进;而数据库事务可针对资源按照任意顺序加锁,就有一定几率因不同的加锁顺序而产生死锁。
2、死锁场景模拟:
锁表顺序不同,常见于存储过程中
session 1 |
session 2 |
begin; |
begin; |
truncate table lock_table2; |
truncate table lock_table1; |
select * from lock_table1; |
select * from lock_table2; |
第一时刻:session 1:先拿到lock_table2的8级锁,此时session 2拿到lock_table1的8级锁;第二时刻:session 1:再尝试申请lock_table1的1级锁; session 2 :尝试申请lock_table2的1级锁;两个会话都持锁并等待对方手里的锁释放。
GaussDB(DWS)会自动处理单点死锁,当单节点死锁发生时,数据库会自动回滚其中一条事务,以消除死锁现象。

3、一些死锁场景
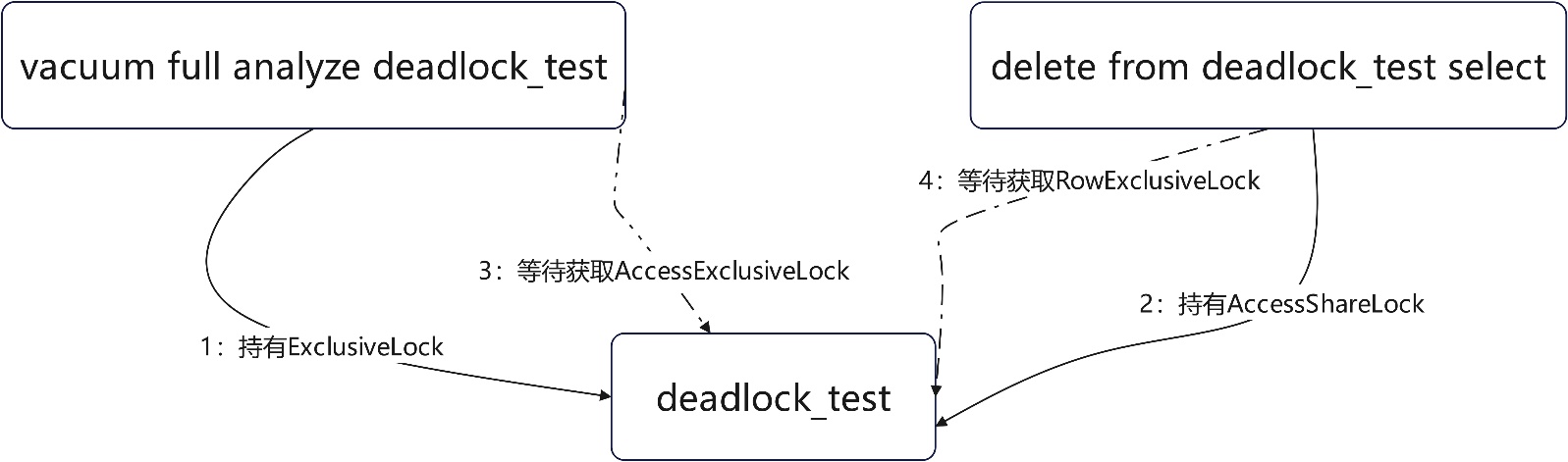
vacuum full 与delete select语句造成的死锁(等同一对象的不同锁);部分业务场景下,存在查询时间窗在白天,而业务跑批删除只能在晚上执行,同样为了保证查询效率降低脏页率,对业务表的vacuum full操作也在晚上,时间窗重合,升锁过程便可能产生死锁;

上述场景下vacuum full语句申请1:ExclusiveLock并持有,后续delete from语句申请2:cessShareLock并持有;vacuum full升级锁3:AccessExclusiveLock失败;delete from升级锁4:RowExclusiveLock失败;两个语句形成死锁。
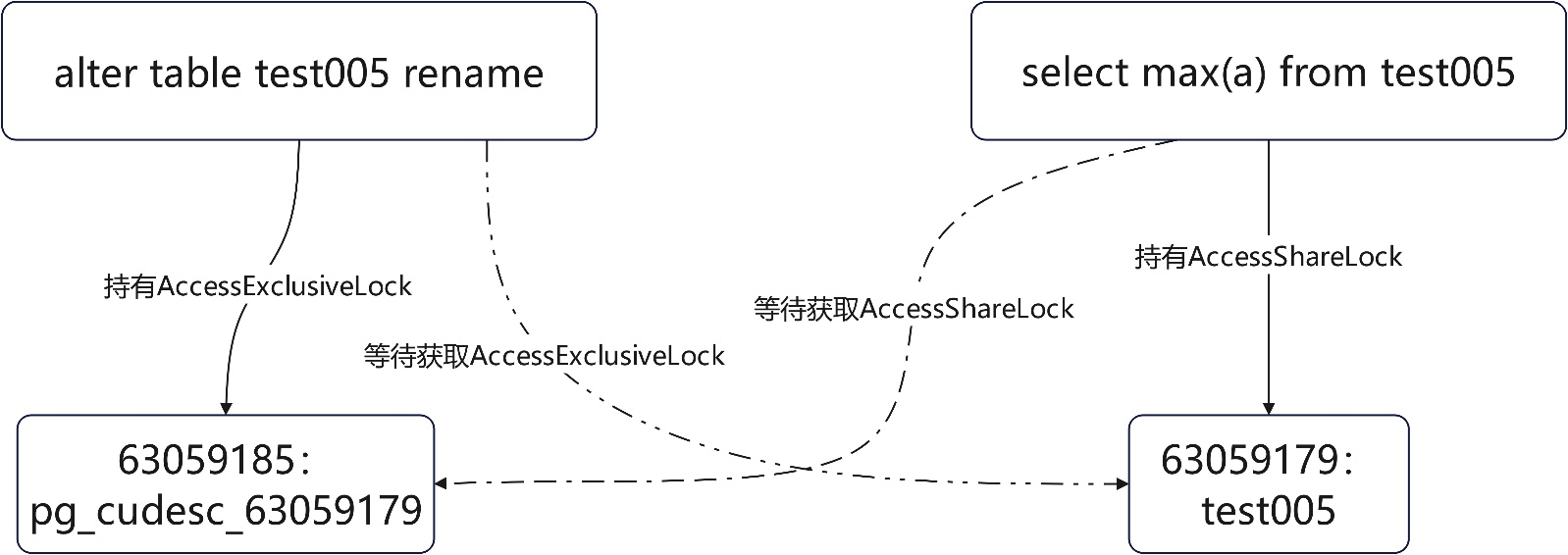
ater列存表与select max(a)的死锁,两条语句只涉及一张表,但仍旧会产生死锁,列存表有CUdesc表及delta表,语句在运行时拿锁顺序不同,便可能产生死锁

列存表查询max(col)时,尽管并没有开启delta表,也会获取delta表的锁,alter table也一样,此时同一个操作对象变存在两个独立的资源(主表与delta表,其实还应该包含CUdesc表),不同拿锁顺序变产生这种两个语句操作同一张表死锁的现象。
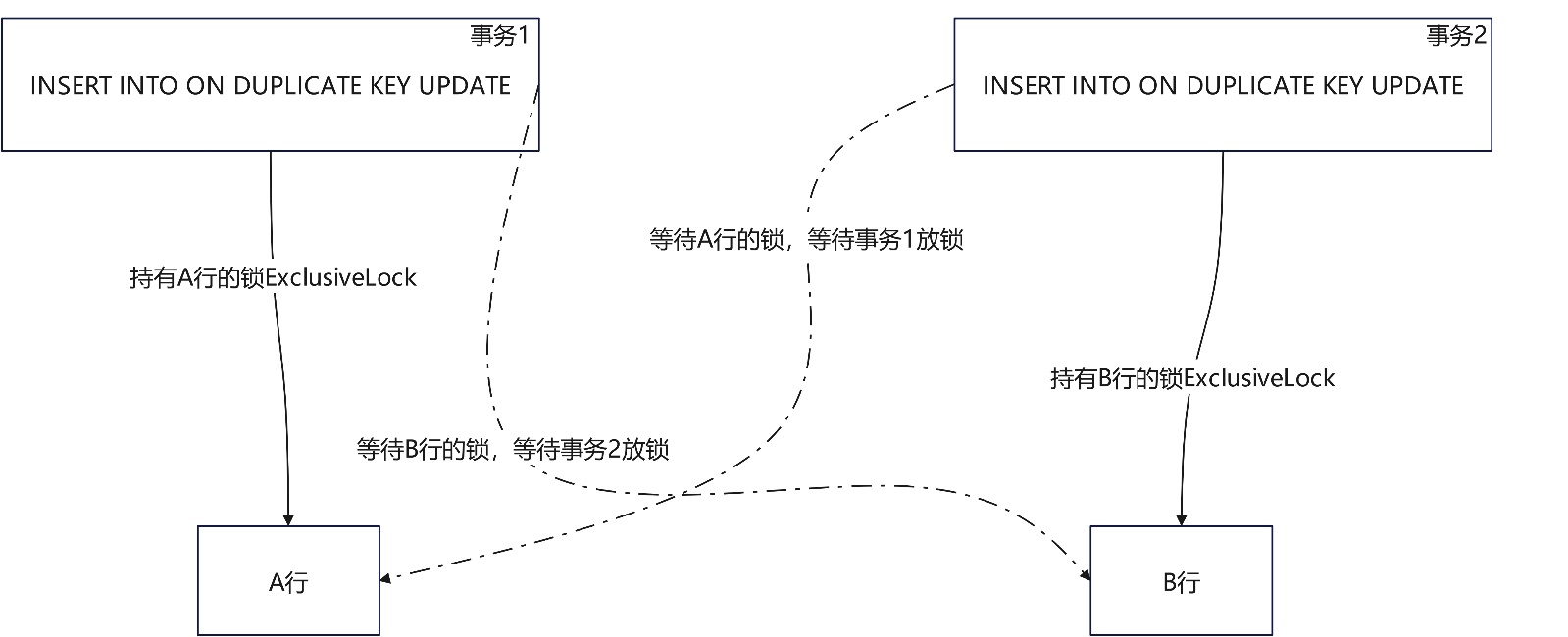
upsert的死锁现象:行存带主键约束或列存表场景下并发upsert,并发更新重复的数据,且不同事务内部更新的相同数据的顺序不同;
该场景主要为分别从两个数据源做并发导数(upsert方式)时,时间窗未区分开,且数据也存在重复的可能性,此时便可能存在以不同的顺序分别更新相同数据(行)的现象,就会引发死锁现象,导致某一次导数任务失败,可选择业务侧将两个任务区分到不同时间窗去执行来规避该死锁现象。
七、分布式死锁
DWS的share nothing结构,使得一条语句可能在不同的节点上执行,在这些节点上都要对操作对象申请锁,且同样存在以不同顺序申请锁的可能,因此便存在分布式死锁的场景
1、如何排查分布式死锁:
先构造一个分布式死锁场景,如下图,session 1 在CN 1上开启事务并先查询lock_table1;此时session 2在CN 2上开启事务并查询lock_table1,然后两个会话分别执行truncate表:
session 1-CN 1 |
session 2-CN 2 |
begin; |
begin; |
select * from lock_table1; |
select * from lock_table1; |
truncate table lock_table1; |
truncate table lock_table1; |
通过查询分布式死锁视图:select * from pgxc_deadlock order by nodename,dbname,locktype,nspname,relname;

根据查询结果,可以看出在构造的该场景下:

CN_5001的truncate语句线程号为:139887210493696;在等待线程号为:139887432832768的truncate语句释放lock_table1的AccessShareLock(事务中select语句持有的锁),同时该线程:139887210493696,持有lock_table1的AccessExclusiveLock;
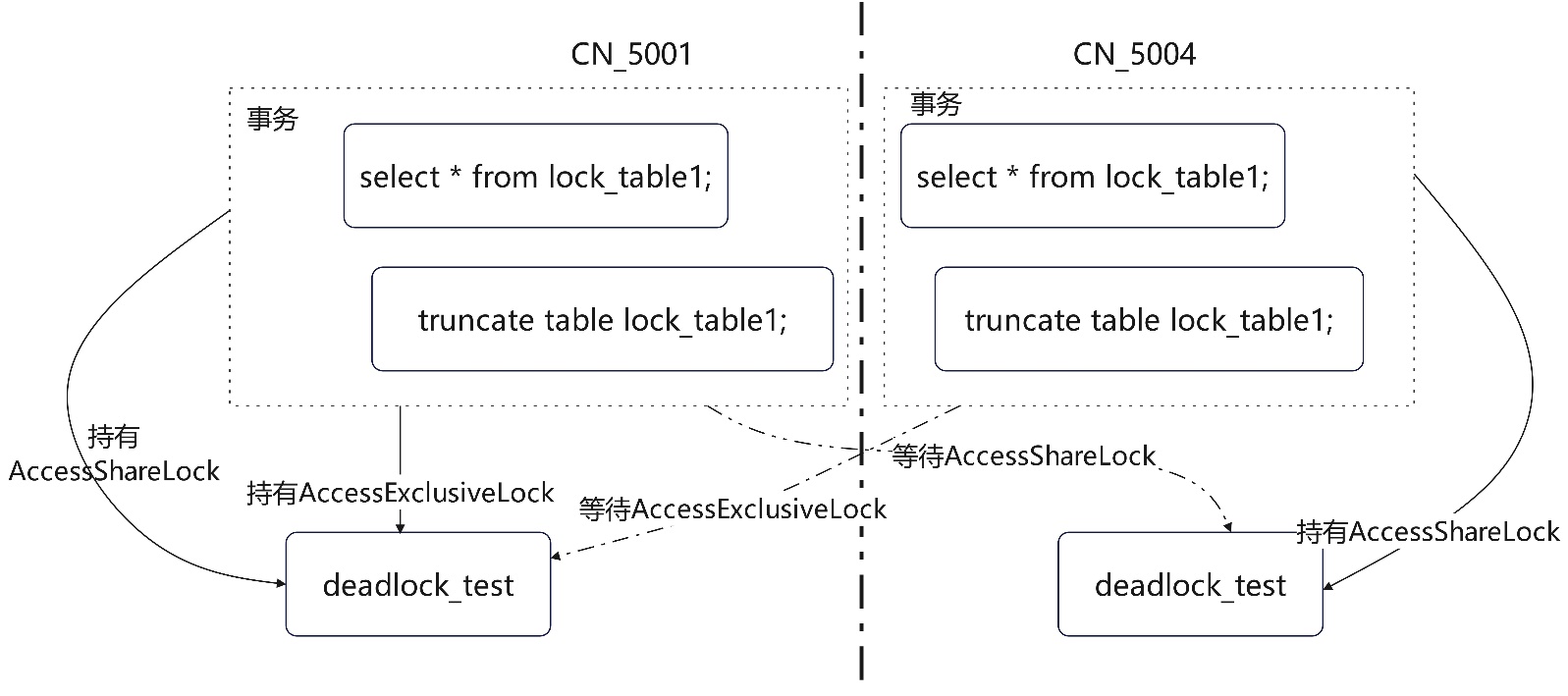
CN_5004的truncate语句线程号为:139887432832768;在等待线程号为:139887210493696的truncate语句释放lock_table1的AccessExclusiveLock;同时该线程:139887432832768持有lock_table1的AccessShareLock;这种 场景下在不同实例上分布式的等待关系,便形成了分布式死锁。
2、消除分布式死锁:
对于分布式死锁的场景,一般在一个事务因为等锁超时后事务回滚,另一个未超时的事务便能继续进行下去;人为干预的情况,则需要调用select pg_terminate_backend(pid),查杀掉一个持锁语句,破坏环形等待条件,便可让另一个事务继续执行下去。
- 点赞
- 收藏
- 关注作者
评论(0)